Understanding Network Stacks
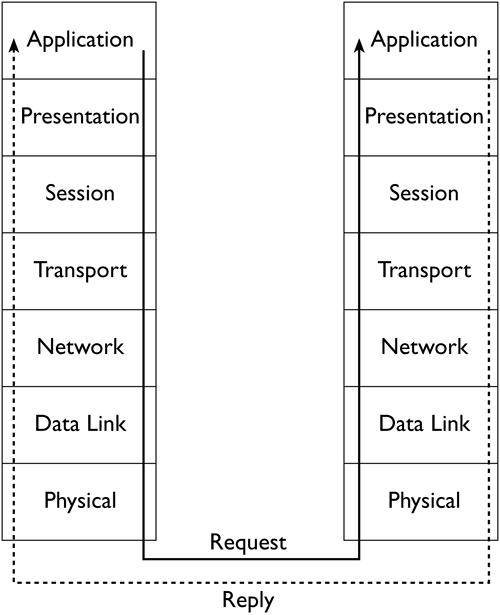
| In discussing network stacks, including their relative merits, it's necessary to understand something about how a network stack is organized, how it works, and what it can accomplish. All network stacks are similar on a broad level of analysis, but the details of how they operate determine some of their important differences. Understanding the theory behind network stacks will help you understand each network stack's features. The OSI Network Stack ModelOne common model of network stacks is the Open System Interconnection (OSI) model. This model consists of seven layers , each of which handles a specific networking task. When a computer sends data, the information originates from a program residing at the top layer of the OSI model (known as the Application layer ). The program passes data to the next layer (the Presentation layer ), and so on down the stack. Each layer processes the data in some way. At the bottom of the OSI model is the Physical layer, which corresponds to the network hardware, such as cables and hubs. Data pass over the Physical layer from the sending computer to the receiving computer. (This transfer may be simple when both computers are on the same network segment, but it can involve many other systems when the two computers are at disparate points on the Internet.) On the destination system, the data pass up the network stack, ultimately reaching the recipient program at the Application layer on that system. This system may then send a reply down its network stack, and that reply passes up the stack of the first system. Figure 3.1 illustrates this process. Figure 3.1. A network stack processes data so that it can be transferred to another computer, or "unwraps" data received from another computer. NOTE
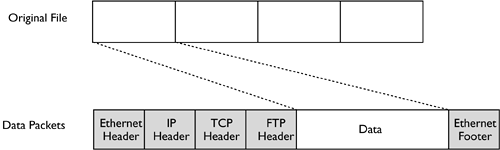
Each layer of the OSI model communicates directly only with the layers immediately above and below it. (In the case of the Application and Physical layers, the chain ends. Applications communicate with users or perform automated network tasks , and the Physical layer links the two computers.) On any given computer, the layers of the network stack must be written to facilitate such communication, using clearly defined interfaces. Sometimes, the components at a given layer must be interchangeable. For instance, the Application layer consists of network applications, such as Web browsers and Web servers. You should be able to swap out one Web browser or Web server for another without causing problems with the network stack. (Any given Web browser or Web server may lack certain important features, such as the ability to handle Secure Sockets Layer [SSL] encryption; however, this isn't really an issue of network stack integration.) Similarly, you should be able to swap out network cables and hubs at the Physical layer, or even replace a network card and its driver, without impacting higher-up layers. Each layer of the network stack corresponds to its counterpart on the opposite computer. In some sense, the recipient computer's network stack undoes whatever the sender computer's network stack did. The ultimate goal is to allow Application-layer programs to communicate. Therefore, any layer should receive from the layer below exactly the data sent by its counterpart layer on the sending system. In some sense, any given layer should work as if it were talking to its counterpart on the other system, not another layer of the local protocol stack. For this reason, network stacks must be very standardized across computers, even if those computers run radically different OSs. For instance, the network stacks of such diverse OSs as Linux, Windows XP, MacOS X, and BeOS must all work in almost precisely the same ways, even if they use entirely independent code bases. Wrapping and Unwrapping DataThe network stack is a useful way to envision the passage of data through a computer's network software, but it doesn't clearly describe what happens to data along the way. This can be thought of as wrapping and unwrapping data. Each layer of the network stack does something to the data it receives. Actions performed during wrapping may include breaking data into chunks (usually called packets or frames , depending on the level of the stack under discussion), adding information to an existing chunk of data, or modifying existing data (data modification is rare, though). Unwrapping reverses these actions. For instance, consider data transfer via the File Transfer Protocol (FTP), which uses the TCP/IP network stack, over an Ethernet network. The data being transferred might be a file, but that single file might be much larger than the data packets or frames that TCP/IP or Ethernet are designed to transfer. Therefore, the file will be broken down into many small chunks. Each of these chunks will have headers added to it by various portions of the network stack. (Some layers may add footers, as well.) Headers and footers begin or end a given chunk of data, and include information to help the system parse and deliver the rest of the data packet. The idealized result of this wrapping is shown in Figure 3.2. In fact, matters can become more complex, because the packets delivered by one layer of the network stack may be even further split by subsequent layers of the stack. For instance, the Ethernet drivers might break down an IP packet into two Ethernet frames. Routers might do the same thing. When this happens, the IP, TCP, and FTP headers of Figure 3.2 are all just part of the data payload; they aren't duplicated in both Ethernet packets, and could wind up in either Ethernet packet. All of this is transparent, though, because each layer of the network stack on the recipient computer reassembles the packets or frames that its counterpart on the sending computer created, even if those packets have been split up en route. Figure 3.2. A network stack splits up a file into chunks and wraps each chunk in data that help the recipient computer reassemble the original file. The details of Figure 3.2 vary from one network stack to another, and even with details of a single stack. For instance, the FTP Header of Figure 3.2 would be a Hypertext Transfer Protocol (HTTP) header for a Web browser data transfer. If the computers used network hardware other than Ethernet, the Ethernet header and footer would be replaced by headers and footers for the particular network hardware used. Indeed, a router that transfers data across network types would, as part of its processing, strip away these headers and footers and replace them with appropriate substitutes. This processing can occur several times during a packet's journey across the Internet, but the goal is to deliver the original data in its original form to the destination. The headers and footers include critical addressing information, such as the sender's and recipient's IP addresses, the port numbers of the originating and destination programs, numbers identifying the place of a packet in a sequence, and so on. Intervening computers use this information to route individual packets, and the recipient uses it to direct the packet to the appropriate program. This program can then use the sender's address and port number to direct a reply to that system and program. The Role of the TCP/IP StackTCP/IP is the most popular network stack. The Internet is built upon TCP/IP, and the stack supports the most popular network protocols, including most of those discussed in this book. In most cases, you can't simply unlink a network application from one stack and tie it to another stack, although a few applications do support multiple network stacks. Part of the reason for TCP/IP's popularity is its flexibility. TCP/IP is a routable network stack, meaning that a computer with multiple network interfaces can partially process TCP/IP packets and pass those packets from one network to another. TCP/IP routing is flexible and allows for routing based on decentralized network maps; there's no need for a centralized database for network routing to occur. Furthermore, TCP/IP supports a large network address (32 bits, with 128-bit addresses coming with IPv6, as described in Chapter 2) and a hierarchical naming structure. All these features make TCP/IP well suited to function as a network stack for a globe-spanning network. On an individual Linux computer, TCP/IP is a good choice because of its support for so many important network protocols. Although many non-Unix platforms developed proprietary protocol stacks in the 1980s, Unix systems helped pioneer TCP/IP, and most Unix network protocols use TCP/IP. Linux has inherited these protocols, and so a Linux-only or Linux/Unix network operates quite well using TCP/IP alone; chances are you won't need to use any other network stack in such an environment. Common protocols supported by TCP/IP include HTTP, FTP, the Simple Mail Transfer Protocol (SMTP), the Network File System (NFS), Telnet, Secure Shell (SSH), the Network News Transfer Protocol (NNTP), the X Window System, and many others. Because of TCP/IP's popularity, tools that were originally written for other network stacks can also often use TCP/IP. In particular, the Server Message Block (SMB)/Common Internet File System (CIFS) file-sharing protocols used by Windows can link to TCP/IP via the Network Basic Input/Output System (NetBIOS), rather than tying to the NetBIOS Extended User Interface (NetBEUI), which is the native DOS and Windows protocol stack. (All versions of Windows since Windows 95 also support TCP/IP.) Similarly, Apple's file-sharing protocols now operate over TCP/IP as well as over AppleTalk. Although it's very popular and can fill many network tasks, TCP/IP isn't completely adequate for all networking roles. For instance, your network might contain some systems that continue to use old OSs that don't fully support TCP/IP. An old Macintosh might only support file sharing over AppleTalk, for instance, or you might have DOS or Windows systems configured to use IPX or NetBEUI. In these situations, Linux's support for alternative network stacks can be a great boon. |

EAN: 2147483647
Pages: 203