Section 5.7. BSD Initialization
5.7. BSD InitializationAs we saw in Figure 511, before becoming the pageout daemon, the kernel bootstrap thread calls bsd_init() [bsd/kern/bsd_init.c], which initializes the BSD portion of the Mac OS X kernel and eventually passes control to user space. Figure 517 shows bsd_init()'s sequence of actions. Figure 517. BSD initialization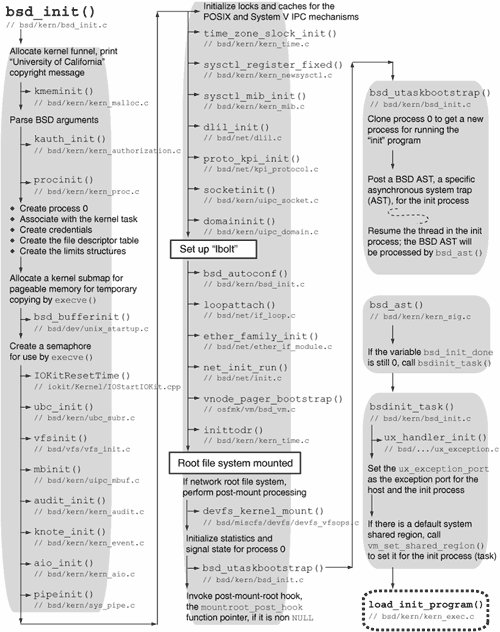 5.7.1. Miscellaneous BSD Initialization (Part 1)bsd_init() allocates the kernel funnel using funnel_alloc() [bsd/kern/thread.c]. It then acquires the kernel funnel. Although the funnel mechanism is deprecated in Mac OS X 10.4, it is still present for backward compatibility.[26]
bsd_init() next prints the well-known BSD copyright message, which is defined in bsd/kern/bsd_init.c. char copyright[] = "Copyright (c) 1982, 1986, 1989, 1991, 1993\n\t" "The Regents of the University of California. " "All rights reserved.\n\n"; kmeminit() [bsd/kern/kern_malloc.c] initializes the BSD-specific kernel memory allocator. This allocator designates each type of memory with a numerical value, where "type" represents the purpose of the memory as specified by the caller. Some types have their own Mach allocator zones from which that type of memory is allocated. Other types either share another type's Mach zone or use an appropriate power-of-2-sized kalloc zone. parse_bsd_args() [bsd/kern/bsd_init.c] retrieves BSD-related arguments from the boot command line. Some of these arguments affect allocation sizes of certain BSD data structures, whereas the others are eventually forwarded to the "init" program started by the kernel. kauth_init() [bsd/kern/kern_authorization.c] initializes the kauth centralized authorization subsystem. It initializes its constituent modules by calling kauth_cred_init() [bsd/kern/kern_credential.c], kauth_identity_init() [bsd/kern/kern_credential.c], kauth_groups_init() [bsd/kern/kern_credential.c], kauth_scope_init() [bsd/kern/kern_authorization.c], and kauth_resolver_init() [bsd/kern/kern_credential.c]. procinit() [bsd/kern/kern_proc.c] initializes the following global process-related data structures: the list of all processes (allproc); the list of zombie processes (zombproc); and hash tables for process identifiers (pidhashtbl), process groups (pgrphashtbl), and user identifiers (uihashtbl). bsd_init() then initializes various aspects of process 0. Unlike subsequent processes, the data structures of process 0such as structures related to its credentials, open files, accounting, statistics, process limits, and signal actionsare statically allocated and never freed. Moreover, process 0 is handcraftedbsd_init() associates it with the already existent kernel task (kernel_task). Its name is explicitly set to kernel_task, and its process ID is set to 0. It is placed at the head of the allproc list. The chgproccnt() [bsd/kern/kern_proc.c] function is called to increment the count of processes owned by root (user ID 0).
Prior to Mac OS X 10.4, bsd_init() also allocates the network funnel, which is not used in 10.4. bsd_init() allocates a submap from the kernel map to use for BSD-related pageable memory. The size of this map is BSD_PAGABLE_MAP_SIZE (defined to be 8MB in bsd/kern/bsd_init.c). The map is used by execve() [bsd/kern/kern_exec.c] to allocate a buffer into which it copies in (from user space) the first argument of execve()that is, the path, which is used in the kernel's working set caching mechanism and for supporting the launching of .app applications. bsd_init() also initializes the execve() semaphore, which is used while allocating and freeing space for saved arguments. bsd_init() calls bsd_bufferinit() [bsd/dev/unix_startup.c], which calls bsd_startupearly() [bsd/dev/unix_startup.c]. The latter allocates a submap of the kernel map and then allocates kernel memory into this map using the kernel object (kernel_object). bsd_startupearly() also computes the values of parameters related to buffer management for networking and cluster I/O, making additional adjustments unless the machine's physical memory is less than 64MB. For example, it attempts to scale the values of tcp_sendspace and tcp_recvspace, the default send and receive window sizes for TCP, respectively, up to a maximum. bsd_bufferinit() allocates another submap (mb_map) of the kernel map that is used for allocating mbuf clusters. This map's size is the product of nmbclusters and MCLBYTES, which are initialized to 2048 and 512, respectively, in bsd/ppc/param.h but may be adjusted during kernel startup. Finally, bsd_bufferinit() calls bufinit() [bsd/vfs/vfs_bio.c] to initialize file system buffers and related data structures. bufinit() also initializes bcleanbuf_thread [bsd/vfs/vfs_bio.c], the buffer laundry thread, which removes buffers from the queue containing buffers that need cleaning and performs asynchronous blocking write operations with their contents. This initialization allows the BSD layer to read disk labels. Moreover, bufinit() calls bufzoneinit() [bsd/vfs/vfs_bio.c] to initialize the zone for buffer headers (buf_hdr_zone). IOKitResetTime() [iokit/Kernel/IOStartIOKit.cpp] calls IOService::waitForService() [iokit/Kernel/IOService.cpp] to wait for the IORTC (real-time clock) and IONVRAM (Open Firmware nonvolatile memory) services to be matched and published. It then calls clock_initialize_calendar() [osfmk/ppc/rtclock.c] to initialize the calendar clock based on the platform clock. 5.7.2. File System InitializationAt this point, bsd_init() starts file-system-related initialization. It calls ubc_init() [bsd/kern/ubc_subr.c] to initialize the zone (ubc_info_zone) for the unified buffer cache (UBC), which unifies buffering of vnodes with virtual memory (Mach VM objects, specifically). The zone has 10,000 elements, the size of each being the size of the ubc_info structure [bsd/sys/ubc.h]. bsd_init() then calls vfsinit() [bsd/vfs/vfs_init.c], which initializes the vnode structures and each built-in file system type. The specific actions performed by vfs_init() include the following.
5.7.3. Miscellaneous BSD Initialization (Part 2)bsd_init() calls mbinit() [bsd/kern/uipc_mbuf.c] to initialize mbufs, the memory buffers typically used by the networking subsystem. mbinit() allocates memory and initializes locks, statistics, reference counts, and so on. It also calls IOMapperIOVMAlloc() [iokit/Kernel/IOMapper.cpp], which determines whether the system-wide I/O bus mapper exists and, if it does, registers the number of memory pages assigned to the mbuf cluster pool with it. Moreover, mbinit() starts a kernel thread running mbuf_expand_thread() [bsd/kern/uipc_mbuf.c] in the kernel task, with the purpose of growing the cluster pool if the number of free clusters becomes low. audit_init() [bsd/kern/kern_audit.c] initializes the kernel's audit event table, audit memory zone, associated data structures, and the BSM audit subsystem.[29] It calls kau_init() [bsd/kern/kern_bsm_audit.c] to initialize the latter, which, among other things, calls au_evclassmap_init() [bsd/kern/kern_bsm_klib.c] to set up the initial audit-event-to-event-class mapping for system calls. For example, an event called AUE_OPEN_R (defined in bsd/bsm/audit_kevents.h) is mapped to an event class called AU_FREAD (defined in bsd/sys/audit.h). audit_init() also initializes a zone (audit_zone) for audit records. Note that audit logging is not initiated until the user-space audit daemonauditdis started.
knote_init() [bsd/kern/kern_event.c] initializes a zone (knote_zone) for the kqueue kernel event notification mechanism. It also allocates kqueue-related locks. aio_init() [bsd/kern/kern_aio.c] initializes the asynchronous I/O (AIO) subsystem. This includes initialization of locks, queues, statistics, and an AIO work queue zone (aio_workq_zonep) for AIO work queue entries. aio_init() creates AIO worker threads by calling _aio_create_worker_threads() [bsd/kern/kern_aio.c]. The number of threads created is contained in the variable aio_worker_threads [bsd/conf/param.c], which is initialized to the constant AIO_THREAD_COUNT (defined to be 4 in bsd/conf/param.c). An AIO worker thread runs the function aio_work_thread() [bsd/kern/kern_aio.c]. pipeinit() [bsd/kern/sys_pipe.c] initializes a zone (pipe_zone) for pipe data structures and allocates locking data structures. bsd_init() now initializes locks for the POSIX and System V IPC mechanisms. Moreover, it calls pshm_cache_init() [bsd/kern/posix_shm.c] and psem_cache_init() [bsd/kern/posix_sem.c] to initialize hash tables for storing hash values of looked-up names of POSIX shared memory and semaphores, respectively. bsd_init() then calls time_zone_slock_init() [bsd/kern/kern_time.c] to initialize tz_slock, a simple lock used for accessing the global time zone structure, tz, which is defined in bsd/conf/param.c. The lock is used by the gettimeofday() and settimeofday() calls. Next, bsd_init() calls sysctl_register_fixed() [bsd/kern/kern_newsysctl.c] to register sysctl object IDs from the statically defined sysctl lists, such as newsysctl_list [bsd/kern/sysctl_init.c] and machdep_sysctl_list (bsd/dev/ppc/sysctl.c). This includes creating and populating top-level sysctl nodes such as kern, hw, machdep, net, debug, and vfs. bsd_init() then calls sysctl_mib_init() [bsd/kern/kern_mib.c] to populate optional sysctls. 5.7.4. Networking Subsystem InitializationAt this point, bsd_init() starts initialization of the networking subsystem. dlil_init() [bsd/net/dlil.c] initializes the data link interface layer (DLIL). This includes initializing queues for data link interfaces, interface families, and protocol families. dlil_init() also starts the DLIL input thread (dlil_input_thread() [bsd/net/dlil.c]) and another thread for invoking delayed detachment[30] of protocols, protocols filters, and interface filters (dlil_call_delayed_detach_thread() [bsd/net/dlil.c]).
The input thread services two input queues of mbufs: one for the loopback[31] interface and the other for nonloopback interfaces. For each packet, it invokes dlil_input_packet() [bsd/net/dlil.c] with three arguments: the interface the packet was received on, an mbuf pointer for the packet, and a pointer to the packet header. Finally, the input thread calls proto_input_run() [bsd/net/kpi_protocol.c], which first handles any pending attachment or detachment[32] of protocol input handler functions and then iterates over all existing protocol input entries, looking for those with a nonempty chain of packets. It calls proto_delayed_inject() [bsd/net/kpi_protocol.c] on entries that have packets to input.
proto_kpi_init() [bsd/net/kpi_protocol.c] allocates locking data structures used by the protocol code in bsd/net/kpi_protocol.c. socketinit() [bsd/kern/uipc_socket.c] allocates locking data structures and initializes a zone (so_cache_zone) for the kernel's socket-caching mechanism. It also arranges for so_cache_timer() [bsd/kern/uipc_socket.c] to run periodically. The latter frees cached socket structures whose timestamps are older than the current timestamp by SO_CACHE_TIME_LIMIT [bsd/sys/socketvar.h] or more. This caching mechanism allows process control blocks to be reused for sockets cached in the socket layer. domaininit() [bsd/kern/uipc_domain.c] first creates a list of all available communications domains. It then calls init_domain() [bsd/kern/uipc_domain.c] on each available domain. Figure 518 depicts the domain and protocol initialization performed by these functions. Figure 518. Domain and protocol initialization
init_domain() calls the initialization routineif one existsfor the domain. It then uses the domain structure's dom_protosw field to retrieve the chain of protocol switch structures supported for the address family represented by the domain. It iterates over the list of protosw structures [bsd/sys/protosw.h], calling each installed protocol's initialization routine (the pr_init field of the protosw structure). init_domain() also looks at the domain's protocol header length (the dom_protohdrlen field of the domain structure), and, if needed, updates the values of the following global variables: max_linkhdr (largest link-level header systemwide), max_protohdr (largest protocol header systemwide), max_hdr (largest system/protocol pair systemwide), and max_datalen (the difference of MHLEN and max_hdr, where MHLEN is computed in bsd/sys/mbuf.h). 5.7.5. Miscellaneous BSD Initialization (Part 3)bsd_init() sets process 0's root directory and current directory pointers to NULL. Note that the root device has not been mounted yet. bsd_init() then calls thread_wakeup() to wake threads sleeping on lbolt, the global once-a-second sleep address. Next, it calls timeout() [bsd/kern/kern_clock.c] to start running lightning_bolt() [bsd/kern/bsd_init.c], which will continue to call thread_wakeup() on lbolt every second. lightning_bolt() also calls klogwakeup() [bsd/kern/subr_log.c], which checks whether any log entries are pending, and if so, it calls logwakeup() [bsd/kern/subr_log.c] to notify any processes (such as system loggers) that may be waiting for log output. // bsd/kern/bsd_init.c void lightning_bolt() { boolean_t funnel_state; extern void klogwakeup(void); funnel_state = thread_funnel_set(kernel_flock, TRUE); thread_wakeup(&lbolt); timeout(lightning_bolt, 0, hz); klogwakeup(); (void)thread_funnel_set(kernel_flock, FALSE); }bsd_init() calls bsd_autoconf() [bsd/kern/bsd_init.c], which first calls kminit() [bsd/dev/ppc/km.c] to tell BSD's keyboard (input) and monitor (output) module to flag itself initialized. It then initializes the pseudo-devices by iterating over the pseudo_inits array of pseudo_init structures [bsd/dev/busvar.h] and calling each element's ps_func function. The pseudo_inits array is generated at compile time by the config utility: // build/obj/RELEASE_PPC/bsd/RELEASE/ioconf.c #include <dev/busvar.h> extern pty_init(); extern vndevice_init(); extern mdevinit(); extern bpf_init(); extern fsevents_init(); extern random_init(); struct pseudo_init pseudo_inits[] = { 128, pty_init, 4, vndevice_init, 1, mdevinit, 4, bpf_init, 1, fsevents_init, 1, random_init, 0, 0, };bsd_autoconf() finally calls IOKitBSDInit() [iokit/bsddev/IOKitBSDInit.cpp], which publishes the BSD kernel as a resource named "IOBSD". bsd_init() attaches the loopback interface by calling loopattach() [bsd/net/if_loop.c], which calls lo_reg_if_mods() [bsd/net/if_loop.c] to register the PF_INET and PF_INET6 protocol families by calling dlil_reg_proto_module() [bsd/net/dlil.c]. loopattach() then calls dlil_if_attach() [bsd/net/dlil.c] to attach the loopback interface, followed by a call to bpfattach() [bsd/net/bpf.c], which attaches the loopback interface to the Berkeley Packet Filter (BPF)[33] mechanism. The link layer type used in this attachment is DLT_NULL.
ether_family_init() [bsd/net/ether_if_module.c] initializes the Ethernet interface family by calling dlil_reg_if_modules() [bsd/net/dlil.c]. This is followed by calls to dlil_reg_proto_module() [bsd/net/dlil.c] to register the PF_INET and PF_INET6 protocol families for the Ethernet interface family. ether_family_init() also initializes support for IEEE 802.Q Virtual LANs (VLANs) by calling vlan_family_init() [bsd/net/if_vlan.c]. This creates a VLAN pseudo-devicea device in softwarethat uses much of the Ethernet interface family's functionality. Finally, ether_family_init() calls bond_family_init() [bsd/net/if_bond.c] to initialize support for IEEE 802.3ad Link Aggregation, which allows multiple Ethernet ports to be bonded, or aggregated, into a single virtual interface, with automatic load balancing across the ports. The kernel provides an interfacethe net_init_add() functionto register functions that will be called when the network stack is being initialized. This is useful for kernel extensions that wish to register network filters before any sockets are created or any network activity occurs in the kernel. After initializing the Ethernet interface family, bsd_init() calls net_init_run() [bsd/net/init.c] to run any such registered functions. vnode_pager_bootstrap() [osfmk/vm/bsd_vm.c] initializes a zone (vnode_pager_zone) for the vnode pager's data structures. This zone has an allocation size of one page and an element size the same as that of a vnode_pager structure [osfmk/vm/bsd_vm.c]. The zone can use a maximum memory that allows for as many as MAX_VNODE such structures. MAX_VNODE is defined to be 10,000 in osfmk/vm/bsd_vm.c. inittodr() [bsd/kern/kern_time.c] calls microtime() [bsd/kern/kern_time.c] to retrieve the calendar time value in a timeval structure [bsd/sys/time.h]. If either of the seconds or microseconds components of the structure is negative, inittodr() resets the calendar clock by calling setthetime() [bsd/kern/kern_time.c]. 5.7.6. Mounting the Root File Systembsd_init() now initiates mounting of the root file system. As shown in Figure 519, it goes into an infinite loop that breaks when the root file system is successfully mounted. Within the loop, bsd_init() calls setconf() [bsd/kern/bsd_init.c], which determines the root device, including whether it is to be accessed over the network. bsd_init() then calls vfs_mountroot() [bsd/vfs/vfs_subr.c] to attempt to mount the root device. Figure 519. Mounting the root file system
As shown in Figure 520, setconf() calls IOFindBSDRoot() [iokit/bsddev/IOKitBSDInit.cpp]an I/O Kit functionto determine the root device. On success, IOFindBSDRoot() populates the rootdev variable that is passed to it as an argument. If IOFindBSDRoot() fails, setconf() may explicitly set the root device to /dev/sd0a as a debugging aid. setconf() also checks the value of the flags variable, because IOFindBSDRoot() sets its lowest bit in the case of the root being a network boot device. If so, setconf() sets a global function pointermountroot [bsd/vfs/vfs_conf.c]to point to the function netboot_mountroot() [bsd/kern/netboot.c]. If the value of flags is 0, the mountroot pointer is set to NULL. Later, vfs_mountroot() checks whether mountroot is a valid pointer; if so, it invokes the corresponding function to attempt to mount the root file system. Figure 520. Finding the root device with help from the I/O Kit
Let us look at the working of IOFindBSDRoot(). Since setconf() is called in a loop, IOFindBSDRoot() may be called more than once. As Figure 521 shows, IOFindBSDRoot() keeps track of the number of times it has been called and sleeps for 5 seconds on the second and subsequent invocations. It checks for the presence of the rd and rootdev (in that order) boot arguments. If it finds either, it retrieves its value. Figure 521. Doing the core work of finding the root device
Next, IOFindBSDRoot() queries the I/O Registry as follows.
IOFindBSDRoot() then checks for the property named RAMDisk in the /chosen/memory-map node. If the property is found, its data specifies the base address and size of a RAM disk. IOFindBSDRoot() calls mdevadd() [bsd/dev/memdev.c] to find a free RAM disk slot and add a pseudo disk device whose path is of the form /dev/mdx, where x is a single-digit hexadecimal number. Note that if IOFindBSDRoot() is called multiple times, it builds the RAM disk only oncethe first time it is called. For a RAM disk to be used as the root device, the root device specification in the boot arguments must contain the BSD name of the RAM disk device to use. IOFindBSDRoot() then checks whether the contents of rdBootVar are of the form /dev/mdx, and if so, it calls mdevlookup() [bsd/dev/memdev.c] to retrieve the device numbera dev_t data type that encodes the major and minor numbersfrom the device ID (the x in mdx). If a RAM disk device is found, IOFindBSDRoot() sets the outgoing flags (oflags) value to 0, indicating that this is not a network root device, and returns success. If the look pointer is nonzero, that is, if IOFindBSDRoot() had previously found content in either rootpath (/chosen) or boot-file (/options), IOFindBSDRoot() checks the content to see if it begins with the string "enet". If so, it deems the root as a network device; otherwise, it defaults to a disk device. However, if forceNet is true, IOFindBSDRoot() also treats the content as a network device. In the case of a network device, IOFindBSDRoot() calls IONetworkNamePrefixMatching() [iokit/bsddev/IOKitBSDInit.cpp] to retrieve the matching dictionary for the device. In the case of a disk, it calls IODiskMatching() [iokit/bsddev/IOKitBSDInit.cpp] instead. If this retrieval fails, it tries a few other alternativessuch as the followingto construct a matching dictionary for the root device.
IOFindBSDRoot() then goes into a loop, calling IOService::waitForService() with the matching dictionary it has constructed. It waits for the matching service to be published with a timeout of ROOTDEVICETIMEOUT (60 seconds). If the service fails to get published, or if this is the tenth time IOFindBSDRoot() is being called, a failed boot icon is displayed, followed by a "Still waiting for root device" log message. If an Apple_HFS "child" was explicitly requested, such as in the case of a CD-ROM device, IOFindBSDRoot() waits for child services to finish registering and calls IOFindMatchingChild() [iokit/bsddev/IOKitBSDInit.cpp] on the parent service to look for a child service whose Content property is Apple_HFS. Alternatively, if the boot volume was specified via its UUID, IOFindBSDRoot() looks for the boot-uuid-media property of the service it has found. IOFindBSDRoot() checks whether the matched service corresponds to a network interfacethat is, whether it is a subclass of IONetworkInterface. If so, it calls IORegisterNetworkInterface() [iokit/bsddev/IOKitBSDInit.cpp] on the service to name and register the interface with the BSD portion of the kernel. Specifically, the IONetworkStack service is published, and the network device's unit number and path are set as properties of this service. In the case of a non-network root device, such device registration is done later and is triggered from user space. At this point, if IOFindBSDRoot() has a successfully matched service, it retrieves the BSD name, the BSD major number, and the BSD minor number from the service. If there is no service, IOFindBSDRoot() falls back to using en0the primary network interfaceas the root device and sets the oflags (outgoing flags) parameter's lowest bit to 1, indicating a network root device. As shown in Figure 520, before setconf() returns to bsd_init(), it sets the mountroot function pointer to netboot_mountroot if a network root device was indicated, and to NULL otherwise. bsd_init() calls vfs_mountroot() [bsd/vfs/vfs_subr.c] to actually mount the root file system. // bsd_init() in bsd/kern/bsd_init.c ... setconf(); ... if (0 = (err = vfs_mountroot())) break; #if NFSCLIENT if (mountroot == netboot_mountroot) { printf("cannot mount network root, errno = %d\n", err); mountroot = NULL; if (0 = (err = vfs_mountroot())) break; } #endif ...vfs_mountroot() first calls the function pointed to by the mountroot function pointer (if the pointer is not NULL) and returns the result. // vfs_mountroot() ... if (mountroot != NULL) { error = (*mountroot)(); return (error); } ...vfs_mountroot() creates a vnode for the root file system's block device. It then iterates over the entries in vfsconf [bsd/vfs/vfs_conf.c]the global list of configured file systems. // bsd/vfs/vfs_conf.c ... static struct vfsconf vfsconflist[] = { // 0: HFS/HFS Plus { &hfs_vfsops, ... }, // 1: FFS { &ufs_vfsops, ... }, // 2: CD9660 { &cd9660_vfsops, ... }, ... }; ... struct vfsconf *vfsconf = vfsconflist; ... vfs_mountroot() looks at each entry of the vfsconflist array and checks whether that vfsconf structure has a valid vfc_mountroot field, which is a pointer to a function that mounts the root file system for that file system type. Since vfs_mountroot() goes through the list starting from the beginning, it attempts the HFS/HFS Plus file system first, followed by FFS,[34] and so on. In particular, for the typical case of a local, HFS Plus root file system, vfs_mountroot() will call hfs_mountroot() [bsd/hfs/hfs_vfsops.c].
// vfs_mountroot() in bsd/vfs/vfs_subr.c ... for (vfsp = vfsconf; vfsp; vfsp = vfsp->vfc_next) { if (vfsp->vfc_mountroot == NULL) continue; ... if ((error = (*vfsp->vfc_mountroot)(...)) == 0) { ... return (0); } vfs_rootmountfailed(mp); if (error != EINVAL) printf("%s_mountroot failed: %d\n", vfsp>vfc_name, error); } ...In the case of a network root device, netboot_mountroot() [bsd/kern/netboot.c] is called. It first determines the root devicethe network interface to useby calling find_interface() [bsd/kern/netboot.c]. Unless the rootdevice global variable contains a valid network interface name, the list of all network interfaces is searched for the first device that is not a loopback or a point-to-point device. If such a device is found, netboot_mountroot() brings it up. It then calls get_ip_parameters() [bsd/kern/netboot.c], which looks for the dhcp-response and bootp-response propertiesin that orderof the /chosen entry in the I/O Registry. If one of these properties has any data, get_ip_parameters() calls dhcpol_parse_packet() [bsd/netinet/dhcp_options.c] to parse it as a DHCP or BOOTP packet and to retrieve the corresponding options. If successful, this provides the IP address, netmask, and router's IP address to be used for the boot. If no data was retrieved from the I/O Registry, netboot_mountroot() calls bootp() [bsd/netinet/in_bootp.c] to retrieve these parameters using BOOTP. If there is no router, netboot_mountroot() enables proxy ARP. netboot_mountroot() then calls netboot_info_init() [bsd/kern/netboot.c] to set up root file system information, which must come from one of the following sources (in the given order):
If none of these sources provides valid information, booting fails. A root file system for network booting can be a traditional NFS mount, or it can be a remote disk image mounted locally. The latter can use one of two mechanisms: the BSD vndevice interface (a software disk driver for vnodes) and Apple's Disk Image Controller (also called hdix). Even when a remote disk image is mounted locally, the image must still be accessed remotely, either using NFS (both vndevice and hdix) or HTTP (hdix only). The kernel prefers to use hdix, but you can force it to use vndevice by specifying vndevice=1 as a boot argument. The following are some examples of root file system specifiers for network booting (note that a literal colon character in the specifier must be escaped using a backslash character): nfs:<IP>:<MOUNT>[:<IMAGE PATH>] nfs:10.0.0.1:/Library/NetBoot/NetBootSP0:Tiger/Tiger.dmg nfs:10.0.0.1:/Volumes/SomeVolume\:/Library/NetBoot/NetBootSP0:Tiger/Tiger.dmg http://<HOST><IMAGE URL> http://10.0.0.1/Images/Tiger/Tiger.dmg
BSD uses an I/O Kit hookdi_root_image() [iokit/bsddev/DINetBootHook.cpp]to use the services of the Apple Disk Image Controller driver. This hook causes the com.apple.AppleDiskImageController resource to explicitly load by setting its load property to true. Once the root file system is successfully mounted, there is exactly one entry on the list of mounted file systems. bsd_init() sets the MNT_ROOTFS bit (defined in bsd/sys/mount.h) of this entry to mark it as the root file system. bsd_init() also calls the file system's VFS_ROOT operation to retrieve its root vnode, a pointer to which is thereafter held in the global variable rootvnode. If the VFS_ROOT operation fails, there is a kernel panic. An additional reference to this vnode is added so that it is always busy, and consequently, cannot be normally unmounted. bsd_init() sets process 0's current directory vnode pointer to rootvnode. If the root file system is being mounted over the network, additional setup may be required at this point in certain scenarios. The netboot_setup() [bsd/kern/netboot.c] function is called for this purpose. For example, if the root file system image is being mounted using vndevice, netboot_mountroot() does not actually mount the file system contained in the vndevice nodenetboot_setup() mounts it. 5.7.7. Creating Process 1bsd_init() performs the following actions after mounting the root file system.
bsd_utaskbootstrap() clones a new process from process 0 by calling cloneproc() [bsd/kern/kern_fork.c], which in turn calls procdup() [bsd/kern/kern_fork.c]. Since procdup() is a BSD-level call, creating a new process results in the creation of a new Mach task with a single thread. The new process, which has a process ID of 1, is marked runnable by cloneproc(). bsd_utaskbootstrap() points the initproc global variable to this process. It then calls act_set_astbsd() [osfmk/kern/thread_act.c] on the new thread to post an asynchronous system trap (AST), with the "reason" for the trap being AST_BSD (defined in osfmk/kern/ast.h). An AST is a trap delivered to a thread when it is about to return from an interrupt context, which could have been due to an interrupt, a system call, or another trap. act_set_astbsd() calls thread_ast_set() [osfmk/kern/ast.h] to set the AST by atomically OR'ing the reason bits with the thread structure's one or more pending ASTs [osfmk/kern/thread.h]. bsd_utaskbootstrap() finishes by calling thread_resume() [osfmk/kern/thread_act.c] on the new thread, which awakens the thread. ast_check() [osfmk/kern/ast.c] is called to check for pending ASTsfor example, in thread_quantum_expire() [osfmk/kern/priority.c], after the quantum and priority for a thread are recomputed. It propagates the thread's ASTs to the processor. Before the thread can execute, a pending AST causes ast_taken() [osfmk/kern/ast.c]the AST handlerto be called. It handles AST_BSD as a special case by clearing the AST_BSD bit from the thread's pending ASTs and calling bsd_ast() [bsd/kern/kern_sig.c]. AST_BSD is used for other purposes besides kernel startup; therefore, bsd_ast() is called in other scenarios too. bsd_ast() maintains a Boolean flag to remember whether BSD initialization has completed and calls bsdinit_task() [bsd/kern/bsd_init.c] the first time it is called. // bsd/kern/kern_sig.c void bsd_ast(thread_act_t thr_act) { ... static bsd_init_done = 0; ... if (!bsd_init_done) { extern void bsdinit_task(void); bsd_init_done = 1; bsdinit_task(); } ... }bsdinit_task() [bsd/kern/bsd_init.c] performs the following key operations in the given order.
5.7.8. Shared Memory RegionsThe kernel can maintain one or more shared memory regions that can be mapped into each user task's address space. The shared_region_task_mappings structure [osfmk/vm/vm_shared_memory_server.h] is used for tracking a shared-region task mapping. The kernel keeps track of these regions by environment, where an environment is a combination of a file system base (the fs_base field), and a system identifier (the system field). The global variable that holds the default environment's shared regions is defined in osfmk/vm/vm_shared_memory_server.c. // osfmk/vm/vm_shared_memory_server.h struct shared_region_task_mappings { mach_port_t text_region; vm_size_t text_size; mach_port_t data_region; vm_size_t data_size; vm_offset_t region_mappings; vm_offset_t client_base; vm_offset_t alternate_base; vm_offset_t alternate_next; unsigned int fs_base; unsigned int system; int flags; vm_offset_t self; }; ... typedef struct shared_region_task_mappings *shared_region_task_mappings_t; typedef struct shared_region_mapping *shared_region_mapping_t; ... // Default environment for system and fs_root #define SHARED_REGION_SYSTEM 0x1 ... #define ENV_DEFAULT_ROOT 0 ... // osfmk/vm/vm_shared_memory_server.c shared_region_mapping_t default_environment_shared_regions = NULL; ... bsdinit_task() defines the system region to be the one whose fs_base and system fields are equal to ENV_DEFAULT_ROOT and the processor type, respectively. The processor typeas contained in the cpu_type field of the per-processor structureis retrieved by calling cpu_type() [osfmk/ppc/cpu.c]. bsdinit_task() looks for the system region on the list of default environment shared regions. If it fails to find the region, it calls shared_file_boot_time_init() [osfmk/vm/vm_shared_memory_server.c] to initialize the default system region. Recall that shared_file_boot_time_init() would previously have been called by kernel_bootstrap_thread(). We saw that shared_file_boot_time_init() calls shared_file_init() [osfmk/vm/vm_shared_memory_server.c] to allocate two 256MB shared regionsone for text and the other for datafor mapping into task address spaces. shared_file_init() also sets up data structures for keeping track of virtual address mappings of loaded shared files. osfmk/mach/shared_memory_server.h defines the addresses of the shared text and data regions in a client task's address space.[37]
// osfmk/mach/shared_memory_server.h #define SHARED_LIBRARY_SERVER_SUPPORTED #define GLOBAL_SHARED_TEXT_SEGMENT 0x90000000 #define GLOBAL_SHARED_DATA_SEGMENT 0xA0000000 #define GLOBAL_SHARED_SEGMENT_MASK 0xF0000000 #define SHARED_TEXT_REGION_SIZE 0x10000000 #define SHARED_DATA_REGION_SIZE 0x10000000 #define SHARED_ALTERNATE_LOAD_BASE 0x90000000You can use the vmmap command to display the virtual memory regions allocated in a process and thus see the entities that may be mapped at the shared addresses. $ vmmap -interleaved $$ ... __TEXT 90000000-901a7000 [ 1692K] r-x/r-x SM=COW ...libSystem.B.dylib __LINKEDIT 901a7000-901fe000 [ 348K] r--/r-- SM=COW ...libSystem.B.dylib __TEXT 901fe000-90203000 [ 20K] r-x/r-x SM=COW ...libmathCommon.A.dylib __LINKEDIT 90203000-90204000 [ 4K] r--/r-- SM=COW ...libmathCommon.A.dylib __TEXT 92c9b000-92d8a000 [ 956K] r-x/r-x SM=COW ...libiconv.2.dylib __LINKEDIT 92d8a000-92d8c000 [ 8K] r--/r-- SM=COW ...libiconv.2.dylib __TEXT 9680f000-9683e000 [ 188K] r-x/r-x SM=COW ...libncurses.5.4.dylib __LINKEDIT 9683e000-96852000 [ 80K] r--/r-- SM=COW ...libncurses.5.4.dylib __DATA a0000000-a000b000 [ 44K] rw-/rw- SM=COW ...libSystem.B.dylib __DATA a000b000-a0012000 [ 28K] rw-/rw- SM=COW ...libSystem.B.dylib __DATA a01fe000-a01ff000 [ 4K] r--/r-- SM=COW ...ibmathCommon.A.dylib __DATA a2c9b000-a2c9c000 [ 4K] r--/r-- SM=COW ...libiconv.2.dylib __DATA a680f000-a6817000 [ 32K] rw-/rw- SM=COW ...libncurses.5.4.dylib __DATA a6817000-a6818000 [ 4K] rw-/rw- SM=COW ...libncurses.5.4.dylib ... |
EAN: 2147483647
Pages: 161