Sampling Test Cases
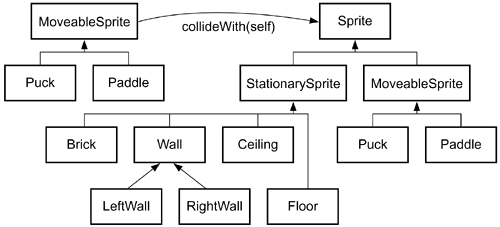
| Exhaustive testing that is, running every possible test case covering every combination of values is obviously a reliable testing approach. However, in many situations the number of test cases is too large to handle reasonably. If there are more possible test cases than there is time to construct and execute them, a systematic technique is needed for determining which ones to actually use. If we have a choice then we would prefer to select the ones that will find the faults in which we are most interested. If we have no prior information, then a random selection is probably as good as we can do. In this section we will consider the general concept of sampling, and then we will apply it to interaction testing. With any testing approach we are interested in ways that the level of coverage can be increased systematically. If a tester simply creates test cases without sufficient analysis, then creating more cases later often repeats some of the functionality already tested. With the techniques presented here, there is a well-defined set of cases and a well-defined technique for increasing coverage. There are a number of possibilities for determining which test cases to select. The technique we will discuss first uses a simple selection process based on a probability distribution. A probability distribution defines, for each data value in a population, a set of allowable values, and the probability that value will be selected. Under a uniform probability distribution, each value in the population is assigned the same selection probability. We define the population of interest to be all possible test cases that could be executed. This includes all preconditions and all possible combinations of input values. A sample is a subset of a population that has been selected based on some probability distribution. One approach is to base the probability distribution on the user profile. If the uses of the system are ranked by frequency, the ranks can be transformed into probabilities. The higher the frequency of use, the larger the probability of selection. But more about this later (see Use Profile on page 313). We can select a stratified sample in which tests are selected from a series of categories. A stratified sample is a set of samples in which each sample represents a specific subpopulation for example, we might select test cases that we are certain exercise each component of the architecture. A population of tests is divided into subsets so that a subset contains all of the tests that exercise a specific component. Sampling occurs on each subset independent of the others. An approach that works well is to use the actors from the use case model as the basis for stratifying the test cases. That is, we select a sample of test cases from the uses of each actor. Each actor uses some subset of the possible uses with some frequency (see Use Profiles, on page 130). Stratifying the test case samples by each actor provides an effective means of increasing the reliability of the system. Running the selected tests uses the system the way that it will be used in typical situations and finds those defects that are most likely to be found in typical use. Removing these defects produces the largest possible increases in reliability with the smallest effort. The sampling technique provides an algorithm for selecting a test suite from a set of possible test cases. This does not mandate how the population of test cases is determined in the first place. The test process is intended to define the population of tests in which we are interested for example, functional test cases and then to define a technique for selecting which of these test cases will be constructed and executed. A test suite for a component may be constructed using a combination of techniques. Consider the Velocity class we used in Chapter 5 in which we did an exhaustive test of direction values, but only a few speed values. We can reduce the number of tests by first using the specification as a source of test cases, and then applying a sampling technique to supplement those tests. The specification of Velocity includes a modifier operation called setDirection(const Direction &newDirection) whose precondition requires newDirection to be in the range 0 through 359, inclusive. The postcondition specifies that the receiver's direction has been modified to the value of newDirection. We first generate test data for this method using the specification as a basis. First, note that Direction is a typedef for int so we are selecting from the set of integers rather than a set of objects. Rather than sample for every test case (0 through 359), we first select values based on boundary values. So we can have three tests around the boundary of zero, perhaps -1, 0, and 1. If this were a "design by contract" project, the -1 value would not be a legitimate test case. There should be a similar set of values around the other boundary, so perhaps 358, 359, and 360. Again, 360 is not legitimate in a contract context. There should be tests in the intervals between 1 and 358 and here is where sampling plays a useful role. The values in the two intervals could be sampled using something like int(random() * 360) and int(-1 * random() * 360). The random() function generates a pseudo random value between 0.0 and 1.0 in accordance with a uniform distribution, so each value is within the interval and each value has an equal chance of being selected. The advantage of using the random value generator in the test case is that over iterations and reapplications of test cases, many values in the intervals will be tested rather than the same ones over time. The disadvantage is that now the test cases are not being reproduced since a different value is used every time. By having the test driver record the generated values as part of the test log, we can re-create any failed test case. Any randomly chosen value that causes a failure is explicitly added to the test suite and is used to test the repaired software. After the fault has been repaired, those values can be used to validate the repair. The regression suite consists mainly of those tests that originally produced failures but were ultimately passed by the software. Now let us consider the interaction between two classes: Sprite and MoveableSprite in the collideInto() operation (see Figure 6.5). Both Sprite and MoveableSprite classes are abstract, so we have an opportunity to design tests that can be reused by their subclasses. The precondition places no restriction on the parameter so we need to find some other way to determine the population from which we will sample. There are three dimensions along which we can sample. Figure 6.5. Specification for operation collideInto()
First, Sprite is the base class in a very large class family, which is a set of classes related by inheritance. An object from any one of the classes in the family can be substituted for the sprite parameter. Therefore, we should sample from this set for possible parameters. This is one of the problems we mentioned earlier about testing object-oriented systems. At some time in the future, a new member of the family can be created and passed to this routine without any recompilation of the MoveableSprite class. Traditional techniques for triggering regression tests do not work in this environment. They should be controlled in the configuration management tool or perhaps the development environment. Each new class definition stimulates a round of regression testing. Usually however only the overridden methods will need to be tested if most of the methods are inherited. Tip Use the class diagram to identify the classes that should be involved in a regression test resulting from the creation of a new class. Examine the parent classes for this new class and identify interactions in which those classes participate. Execute the tests that interact those parents with other classes, but substitute the new class for the parent class in the test. The second dimension for sampling is to consider that each member of the family may have different states that can cause two objects from the same class to behave differently. Obviously the Puck and Wall classes probably have some interesting differences in their states. In the case of families of classes, the state machines are related along the lines of the inheritance hierarchy. Our experience and a number of published papers have shown that as we look down the inheritance hierarchy, there will be the same number of states or more states in the derived class as there are in the base class. We should cover the states defined for each class with special emphasis on the new states added at that level in the inheritance hierarchy. A third dimension relates to the class family associated with MoveableSprite. This is a subset of the Sprite family. Once these tests are designed, they can be applied to any of the classes in the family, assuming the substitution principle has been followed during design. Given these three dimensions, we have the possibility of a combinatorial explosion in the number of test configurations. In this scenario, a test case would have a member of the MoveableSprite family sending a message to a member of the Sprite family, which may be in any one of its states. Orthogonal Array TestingOrthogonal arrays provide a specific sampling technique that seeks to limit the explosion by defining pair-wise combinations of a set of interacting objects. Most of the faults resulting from interactions are due to two-way interactions. One specific technique for selecting a sample is orthogonal array testing system (OATS). An orthogonal array is an array of values in which each column represents a factor, which is a variable in an experiment. In our case it will represent a specific class family[5] in the software system. Each variable can take on a certain set of values called levels. In our testing work, each level will be a specific class in the family. There will also be a parallel factor and set of levels that correspond to the states of these classes. The value entered into a particular cell in the array is an instance of the specific class or is a specific state of an object.
Figure 6.6. Explosion of test cases
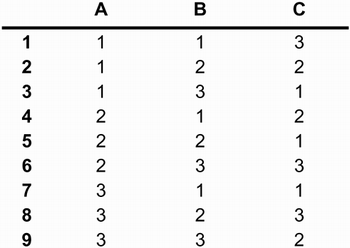
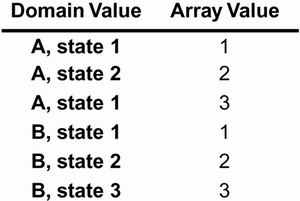
In an orthogonal array, the factors are combined pair-wise rather than representing all possible combinations of the levels for the factors. For example, suppose that we have three factors say, A, B, and C each with three levels say, 1, 2, and 3. There are 27 possible combinations of these values 3 for A times the 3 for B times the 3 for C. If pair-wise combinations are used instead that is, if we consider only those combinations in which a given level appears exactly twice then there are only 9 combinations as shown in Figure 6.7. Figure 6.7. Pair-wise combinations of three factors that have three levels each
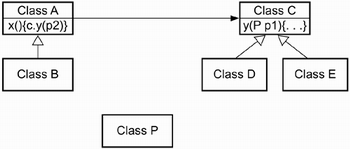
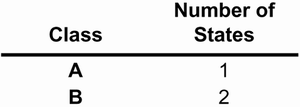
OATS uses a balanced design. Every level of a factor will appear exactly the same number of times as every other level of that factor. If we think of the rows of a table as test cases, then 18 of the possible 27 tests are not being conducted. This is a systematic way of reducing the number of test cases. If we later decide that additional tests should be run, we will know exactly which combinations have not been tested. This is also a logical way of doing the reduction. Most of the errors that are encountered are between pairs of objects rather than among several objects. In this way, we are testing those situations that are most likely to reveal faults. To demonstrate OATS, we will work through a general example and then a Brickles-specific example. The general example comprises interactions between senders in a class family A, receivers in a class family C, and parameters in a class family P (see Figure 6.8). Each class has a state transition diagram associated with it. The details are not important. The number of states that we are assuming each class has is shown in Figure 6.9. Figure 6.8. A general example of applying OATS
Figure 6.9. The number of states associated with classes in the general OATS example
The major activity in this technique is to map the problem of testing the interaction of two inheritance hierarchies with respect to a parameter object. To identify test cases using orthogonal arrays, observe the following five steps:
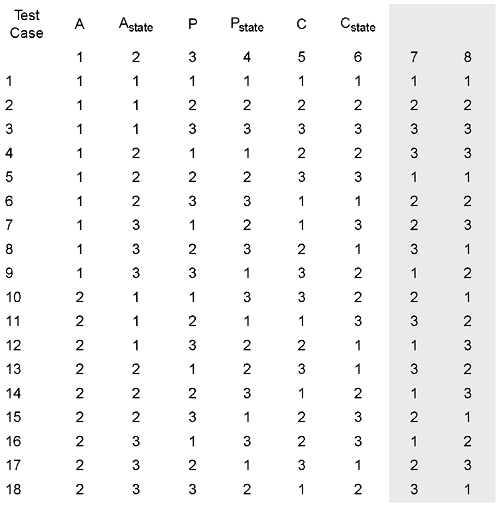
Each row in the orthogonal array, Figure 6.16, specifies one specific test case. The orthogonal array is interpreted back into test cases by decoding the level numbers for a row in the array back to the individual lists for each factor. Thus, for example, the 10th row of L18 is interpreted as test case number 10 in which an instance of class B in state 1 is to send the message by passing an instance of class P in state 3 to an instance of class E in state 2. The last two values in the row are ignored since we did not use those factors. Adequacy Criteria for OATSOne of the useful things about OATS is the ability to vary how completely the software under test is covered. Here are some possible levels that can be used:
Once all the test cases have been run, look at the results to see if failure can be associated with one or more specific factor levels for example, perhaps most of the test cases associated with instances of class A, state 2 fail. This information is useful for developers to track down bugs, and it is useful for testers to indicate that additional test cases might be warranted. Another ExampleNow let us return to the MoveableSprite::collideInto() example from page 227. A MoveableSprite object may be passed to any Sprite object when it is sent the collideInto() message. In the present design, the Sprite class family includes MoveableSprite, StationarySprite, Puck, Paddle, Brick, Wall, RightWall, LeftWall, Floor, and Ceiling. We make the following analysis and observations:
The possible values for each attribute of the test case are shown in Figure 6.17. Figure 6.17. Test attribute values
If we tested all possible combinations, the number of possible tests is 2 x 9 x 8 x 9 = 1296. Some of these can be eliminated because nonmoveable sprites do not have the direction states. The total now appears to be 2 x 9 x 2 x 9 + 2 x 9 x 6 x 1, = 432 test cases still quite a few. By using OATS, we can further reduce the number of test cases and still be effective. For example, these are the selected combinations from Figure 6.17:
OATS would allow case #4 to be eliminated because in #3 Paddle is tested while moving DueEast; in #5 Puck is tested moving DueWest; in #3 Paddle is tested colliding with Puck. The complete OATS analysis would reduce considerably the number of tests required. Another Application of OATSConsider the need to test a collection class such as Stack, in which the class is implemented as a C++ template (see Figure 6.18). Figure 6.18. A C++ class template for Stack
The developer's intention is for template parameter T to be replaced by any class when Stack is instantiated. Obviously, we cannot test the Stack class definition with all possible substitutions. The Stack, like any collection class, does not invoke any methods on the objects that it contains. Therefore, the interface implemented by the parameter class does not matter. To test the template code, we would select a stratified sample of classes from all of the classes that are available including vendor libraries, language libraries, and application code. Depending on the exact programming language used and other factors, the categories in the stratification will include the amount of memory used by each instance, the number of associations, and whether the objects placed in a collection are persistent. Then we would select a subset of this set of classes each time a collection class needs to be tested. This second sampling can be guided by OATS. For more complex templates, sets of possible substitutes for each parameter are created. Then OATS creates tests that involve combinations of parameter substitutions. These tests provide the maximum search for interactions among the parameters with the minimum number of tests. |








EAN: 2147483647
Pages: 126