10.5 Developing Criteria for Technology Evaluation
10.5 Developing Criteria for Technology Evaluation
In preparation for making technology choices for a network design, we will examine technology characteristics that are important from a design perspective. Input to developing evaluation criteria comes from the design goals for the project, the results of the requirements analysis, along with the service-planning and capacity-planning information from the flowspec.
Design goals can often be used directly as evaluation criteria or can easily be translated into evaluation criteria. Minimizing network deployment and operations costs and maximizing ease of use for users and management lead to choosing technologies that are relatively simple and intuitive to deploy, use, and maintain. This also leads to choosing technologies that are standards based, commonly available, and well documented. Commercial off-the-shelf (COTS) network products often fall into this category.
Maximizing performance leads to choosing technologies that meet or exceed expected capacity, delay, and/or reliability, maintainability, and availability (RMA) requirements (from the requirements analysis). Maximizing RMA will also indicate a need for interconnectivity (redundancy) in the network. Redundancy may be achieved in a number of ways, through the choice of technologies, how each technology is applied in the network, redundancy in routing protocols, or redundancy in the physical infrastructure. Usually redundancy is achieved through applying several of these techniques together in the network. Technologies that maximize performance are likely to be more complex solutions, trading off the criteria of simplicity and costs. Performance may also indicate a need for predictable and/or guaranteed service in the design, which will require technologies and protocols that can support predictable and/or guaranteed service delivery.
Adaptability is acknowledging that the design project will be dynamic and that your technology choices will need to support dynamic behavior, such as rapid reconfiguration of users, user groups, address assignments, routing, and location changes on the network. An example of adaptability in a WAN would be to choose a network service (e.g., virtual private networks) from a service provider instead of building a private WAN infrastructure. Another example is providing virtual LAN capability in a LAN to support the dynamic allocation of resources to users. Many examples of adaptability are related to the concept of virtual networks. Adaptability may also be applied to traffic flows to distinguish between flows and switch or route each flow independently based on the requirements of each flow.
Supportability is a measure of how well the customer can keep the system performing, as designed, over the entire life of the system. Can the support staff operate and maintain the proposed technologies? Does the support staff need to be trained on the new technologies, or should they be replaced or augmented with a more technically qualified staff? Should the customer consider outsourcing part or all of the operations and maintenance to a service organization?
In addition, the reference architecture provides input to the design goals. This input consists of how each proposed technology achieves the reference architecture, made up of the component architectures (e.g., addressing/routing, network management, performance, security).
From the flowspec, we can do service and capacity planning. With service planning, we expect some degree of predictable and/or guaranteed performance from the network. This indicates that one of the important design goals will be to maximize one or more network performance characteristics. Some of the other design goals related to service—ease of use and manageability, optimizing security, or adaptability— may also be important in service planning.
In contrast, capacity planning implies that capacity requirements from multiple sources—users, applications, and devices—will be combined across a common technology. This is one of the considerations when trying to optimize costs for the network. Thus, the design goal of minimizing network deployment or operations costs can be part of capacity planning. This does not mean that service planning excludes cost optimization or that capacity planning excludes services. Rather, service and capacity planning help determine what the design goals should be. Figure 10.4 illustrates this relationship between capacity and service plans (from the flow analysis) with network architecture and design goals.
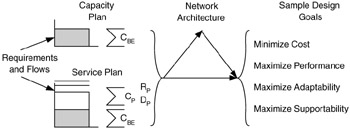
Figure 10.4: Requirements, flows, and network architecture influence design goals.
Once we have decided what the design goals are for the network, we look at the characteristics of technologies that will help us achieve our design goals. There are likely to be characteristics that are important to a particular network, as well as general characteristics that are applicable across most networks. Some general characteristics we will consider here are broadcast and nonbroadcast multiple-access (NBMA) methods, technology functions and features, performance upgrade paths, and flow considerations.
10.5.1 Broadcast and Nonbroadcast Multiple-Access Methods
In developing criteria to evaluate and choose network technologies for your design, we want to look beyond their traditional characteristics—capacities, for example, to find other characteristics that are important from a design perspective. In addition to the capacities of technologies, we can find differences in the design characteristics of broadcast and NBMA technologies, in the types of services that they can support, their upgrade paths, and how they can meet the capacity and service plans of the flow specification.
In developing evaluation criteria, we can consider two important distinguishing characteristics between broadcast and NBMA technologies: native broadcast support and connection support.
Native Broadcast Support
Broadcast technologies support the ability of a device to communicate simultaneously with all other devices on the network or subnet, through using a well-known broadcast address specific to the network technology. This means that every device on the network or subnet can find and access every other device on that network.
To begin with, let's consider this in the context of IP networking. One fundamental requirement of every IP subnet is that every device must be able to directly communicate with every other device on that subnet. This requires the underlying (layer 2) network technology to provide a mechanism to resolve any layer 3 (IP) address for that subnet into the corresponding layer 2 address.
To accomplish this, the technology must have the ability to reach all devices on the subnet, or broadcast on the subnet. The mechanism that resolves layer 3 addresses into corresponding layer 2 addresses is commonly known as the Address Resolution Protocol (ARP). Whereas this is taken for granted in older, broadcast technologies such as Fast Ethernet, Gigabit Ethernet, 10-Gigabit Ethernet, Token Ring, and fiber distributed data interface (FDDI), it can be an issue for NBMA technologies.
NBMA technologies do not inherently have a broadcast mechanism. This is not necessarily a problem, but it does mean that we will need to consider how IP address resolution will be supported in the NBMA environment. Depending on the technology and how it is used in the network, there are a number of mechanisms for supporting address resolution, including hardwiring layer 3 to layer 2 address bindings in devices, using vendor-specific broadcast support mechanisms, or using one of the evolving standards-based mechanisms. NBMA technologies include ATM, frame relay, switched multimegabit data service (SMDS), and high-performance parallel interface (HiPPI). When a network design incorporates an NBMA technology, the design will need to ensure that broadcast (and multicast) is provided for those services that need them.
Another way to look at the lack of an inherent broadcast mechanism is that we have some flexibility in how we provide broadcast in the network. Since broadcast can be considered a mechanism for local directly connected access, it has been one of the factors coupling logical networks with physical networks. Some NBMA networks can be flexible in their handling of broadcasts, so we can create logical subnets that are not coupled to any physical topology. This is an often-overlooked powerful design option that we will see many times throughout this book. Of course, a trade-off with decoupling logical and physical networks is an ambiguity about the underlying network. When a physical network can contain a variety of logical networks (which may themselves be dynamic), it will require more information and more sophisticated techniques of monitoring and management, as we will see later.
When choosing appropriate technologies for the network, you must understand the nature of broadcast for each technology and what role(s) broadcast will play in your design. There are trade-offs between NBMA and broadcast technologies that will be of interest to us, including scalability and simplicity.
One of the fundamental principles of network design is that hierarchies form in the network as groups become larger. Groups can be of users, devices, applications, or higher-level abstractions of these, such as areas or autonomous systems (ASs). An AS is one way to define an administrative domain (a set of networks that are administered by the same organization), where an AS number identifies the administrating organization. A group may also be thought of as a collection of devices that have direct access to each other (e.g., an IP subnet or broadcast domain). As groups get larger, the broadcast traffic (or other secondary effects) becomes more and more of a burden on the network, until it degrades or disrupts performance. Thus, we want to keep group sizes manageable. As a result, hierarchies form to separate groups.
Group sizes are intertwined with our technology choices and information from the flow specification. We want to size groups so that the steady-state background broadcast traffic is a small percentage (a good guideline is less than 2%) of the capacity of the technology. For a 100 Mb/s Ethernet network, we would expect the background broadcast traffic to be no more than about 2 Mb/s. To turn background broadcast numbers into group sizes, we need to estimate how much broadcast traffic a source is likely to generate.
For a broadcast network, this group size would equate to the number of connections to the physical network (e.g., a shared Ethernet, Token Ring, or FDDI network) or to the number of ports on a switch (as in switched Ethernet, Token Ring, FDDI, or ATM) or hub. We need to keep in mind that there are other sources of background broadcast traffic, such as from routing protocols and that this needs to be taken into account also.
Connection Support
Another consideration for broadcast and NBMA technologies is their connection support. Connection support is when a connection is established by the technology whenever information is transferred across the network. A connection is an abstraction of mapping addresses (typically layer 2 addresses) across a network. These addresses may have end-to-end significance, if, for example, we use IP source and destination addresses, or they may have local significance, such as virtual circuit address mapping at ATM switch ports. To do this mapping connection, support is tied to the ability of the technology to get state information, or state, about the network. State is information (typically local/end-to-end addresses, routing information, or quality of service) associated with connections and paths in a technology.
In a sense, a connection-oriented technology must be able to get and persistently maintain address configuration and status information about its end-to-end connections. This is one form of providing state. We will examine three forms of state: hard state, soft state, and stateless (or no state).
Hard state is determining and persistently maintaining connection information along the path of a connection, between source and destination. Stateless is not having to determine or maintain any connection or path information between source and destination. Soft state is between hard state and stateless, determining and maintaining state either until the connection is established or for a short period after the connection is established. Thus, although there is state information being kept, this information is not persistent. It may be kept in short-term memory, or cached, on the order of seconds or minutes.
Stateful, either hard or soft state, is often used to describe a connection-oriented technology, and stateless to describe a connectionless technology. Here, we will default to these descriptions, but bear in mind that this does not always have to be the case. For example, state can be determined and maintained by the network or transport protocols, making a "connection" at that layer in the network. A connectionless technology does not itself have connection information and does not need to maintain state information (hard or soft state) within the network to transfer data.
Sometimes a technology or combination of technologies and protocols may allow operation somewhere between connection-oriented and connectionless, treating some traffic as if it were transiting a connectionless path and other traffic a connection-oriented path. Deciding how to handle different traffic flows may be based on source or destination address, on flow information (e.g., estimated amount of flow or flow type), or on some other session-based information.
A trade-off between using a stateful or stateless technology is the amount of overhead required to establish and maintain state versus the control over the end-to-end path enabled by having state. A connection-oriented technology can offer support for services to a session (an instance of one or more concurrent applications, resulting in one or more traffic flows), based on factors such as cost or performance, and may be able to support monitoring and verification of the service for each session. If we are interested in supporting predictable and/or guaranteed flows in the network, a connection-oriented approach is often required.
There are various types of overhead in supporting connections; in network resources (CPU, memory, capacity); and in monitoring, management, and security requirements. There is also a cost in the setup and tear-down times for connections. When traffic flows for a session are short lived, on the order of one or a few packets, frames, or cells, then setup overhead, in terms of time and allocation of resources, can substantially reduce the performance of the connection (and ultimately, that of the applications generating sessions over that connection).
To balance these trade-offs and optimize the use of multiple technologies, some hybrid connection approaches are evolving. They use some state information to make decisions and apply timeouts to eliminate "old" state information. This is what is considered soft state. In Figure 10.5, state is shown being gathered from each device in the end-to-end path of a traffic flow.
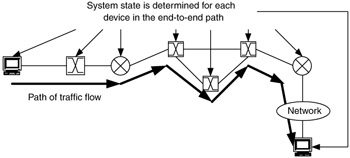
Figure 10.5: System state.
Connection support is important when evaluating technologies on the basis of scalability and flexibility, as well as in how services are offered on the network. Basically, the more control we wish to have over end-to-end services that a network will offer, the greater the tendency toward applying connection-oriented technologies. Of course, there are trade-offs in getting more control over an end-to-end connection, and here we need to consider the overhead with connections, the setup and tear-down times, and the need for greater configuration control and management. For many networks, the gain in end-to-end control is worth the costs of these trade-offs.
Consider a technology in which connections are made for each application session (and thus for each traffic flow). There will be a delay while the connection is being built (setup), and this delay can be significant (up to seconds in duration) depending on how much recent state information is available locally or, if it is not available, how long it takes to get this information (which is based on the signaling capability of the technology). Some applications may not be able to wait for this connection setup time and meet the performance expectations of their users. Network file server (NFS), for example, is a local disk-access utility. Therefore, its total network disk-access delay must approximate local network disk input and output.
In addition, each network device for a technology in the path of a connection will keep some state information, local or global, about that connection. This requires memory and CPU usage that could otherwise be made available to other processes. In Figure 10.6, connection state information such as device, resource, and network addresses is requested by the application or device that is establishing the connection, as part of determining whether the connection can be set up, the required resources can be allocated, and the connection maintained.
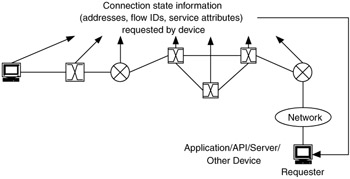
Figure 10.6: System state as part of network connections.
The benefits of greater control over end-to-end connections can be substantial in some networks. When predictable or guaranteed services are required, a connection-oriented technology with its state information may be the only viable solution. If a network is being designed for mission-critical, real-time, and/or interactive-burst applications (such as the visualization application for medical imaging shown in Figure 10.7), it is well worth the overhead cost to design for connections in the network, as long as the connection overhead does not result in delays that are greater than the requirements for that application.
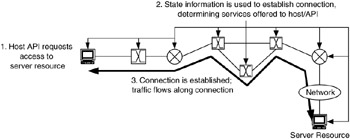
Figure 10.7: Example of connection establishment.
A compromise can be made between these trade-offs, and the resulting orientation (either a combination of connection and connectionless or somewhere between connection and connectionless, depending on traffic type, destination address, etc.) may be optimized for the types of flows in the network. There are other trade-offs here, including ambiguity in the routing of flows in the network, as well as a requirement for greater knowledge of flow types within the network.
10.5.2 Technology Functions and Features
Another important design consideration is the set of functions and features that a technology will offer to users, applications, and devices on a network. Some technologies can be used to help the network adapt to specific users, applications, or devices. Examples include adapting to a lack of communications infrastructure, such as in underdeveloped countries, in remote areas where terrestrial access is not easily available, or in environments where traditional access is not possible or is prohibitively expensive; adapting to the portability or mobility requirements of users; or adapting to specific user, application, and/or device requirements, such as in medical, military, or high-end commercial environments.
Whereas some of the adaptability will be provided by the various protocols operating within the network, the technology can also support or enhance this adaptability. Where a communications infrastructure or terrestrial access is not readily available, the use of wireless network technologies, by themselves or in addition to other network technologies, should be considered. In most cases it will be obvious that a communications infrastructure is not feasible and that a nonstandard method of network access is required. Some extreme environments where nonstandard methods of access have been deployed are on research vessels for real-time telemetry, command and control; at disaster areas, such as forest fires, earthquakes, and floods; and at remote, inhospitable places, such as in Antarctica, near active volcanoes, even on the surface of distant planets (in the case of NASA's Sojourner rover).
These examples indicate that network access is possible for a variety of environments, given the right combination of network technologies, services, and protocols, and of course enough funding to deploy and maintain such access.
Similarly, wireless networks can provide support for user portability and mobility, possibly in addition to having multiple network access points available to users. For example, to support users who want access to their network from multiple locations both at work and at home and who also want access from any location within their workplace (via portable computers or personal digital assistants), wireless access would likely be a part of the overall design. Such portability or mobility also affects how users establish connections to the network, as in the dynamic allocation of network addresses or in authenticating users.
When applications and their traffic flows have performance requirements that are predictable, guaranteed, or well understood, we may be able to map their requirements to service levels offered by the technology. We would be able to use the service plan of a flow specification to identify any such requirements and then use these requirements to evaluate candidate technologies. In this case, the technology must be capable of supporting these requirements, which, as we will see, is much more complicated than most people recognize. Such support may range from frame relay committed information rates; SMDS access classes, or their equivalents, to ATM classes of service or IP type of service levels, to combinations of these with resource reservation or allocation mechanisms.
In some instances, some of the behavior patterns of the users and/or applications may be well understood or predictable. When this occurs, the design may be able to take advantage of this by mapping network performance levels to flow characteristics, directions, or patterns. Many flow patterns are asymmetric, with much more information flowing in one direction than the other. This was seen in the client-server, hierarchical client-server, and distributed-computing flow and architectural models discussed in Chapters 4 and 5. When it is expected that a flow will be asymmetric, as in Figure 10.8, we can design the network to optimize the directionality of that flow.
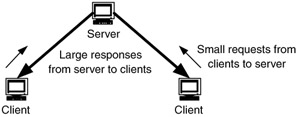
Figure 10.8: Example of asymmetric flows.
Many good examples of this are seen in the usage patterns on the Internet. Web access and use, for example, is predominately asymmetric, with flows toward users. Services are being developed to take advantage of such flow patterns in the Internet, using the asymmetric broadcast capabilities inherent in cable, satellite, and metropolitanarea wireless networks. Hybrid fiber-cable system and xDSL also allow users, both residential and small-to medium-size business, to take advantage of asymmetry in network flows.
When considering the functions and features of various technologies, we need to understand the requirements of the network and how a technology's functions or features will support these requirements, as well as those technologies that will provide a value-added service to the network. In particular, we want to consider distance limitations, locations without infrastructure, users who need portability or mobility, or any way that the environment complicates or constrains the network design.
Distance limitations may force constraints on the delay or RMA characteristics of the network. For example, it will be impossible to guarantee a 40-ms round-trip delay for a flow if the distance is trans-Pacific. This will affect the design in how the communication is provided (e.g., satellite versus cable) or how the flow is modeled (e.g., changing from a hierarchical client-server model to a local client-server model with data migration between regions). We want to look for designs that have long-distance, high-delay communications paths; such designs will create high bandwidth delay products (which describe how much information can be in transit across a network at any given time). Since a high bandwidth delay product means that there can potentially be a lot of information in transit, this requires either large amounts of buffering on the sending side, high reliable connections, good error and flow control, or all of these in the network.
Many designs face infrastructure constraints. If the design includes access to isolated or restricted areas or if mobility is required, use of a wireless technology should be considered.
Value-added services include support services, such as accounting, security, or network management, or may be value added for that particular environment.
10.5.3 Performance Upgrade Paths
Part of the function and feature set of a technology is its upgradability, particularly from a performance perspective. Most, it not all, technologies have evolutionary paths that upgrade performance over time. Typically, performance upgrades focus on capacity but should also include RMA and delay (often in terms of hardware and software latency) when possible. The design process includes considering these upgrade paths and how they may be related to where each technology is located in the network and when they should be upgraded or replaced.
Performance upgrades can be considered from two perspectives: in capacity planning for best-effort flows and in service planning for predictable and/or guaranteed flows. In many networks, both perspectives are taken.
When a technology supports a variety of capacity levels, such as Ethernet at 10, 100, and 1000 Mb/s, and plans to support greater capacity (e.g., 10 Gb/s Ethernet), this information can be used in capacity planning to upgrade areas of the network as individual and composite flows are expected to increase in capacity. As a guideline, capacity increases as flows are aggregated; therefore, the core areas of a network usually require more capacity than the distribution areas, which usually require more capacity than the access areas.
As the numbers of individual and composite flows increase and as flows in general increase in capacity, the capacity requirements of access, distribution, and core networks increase based on the degree of hierarchy in the network. Therefore, upgrade paths are dependent on where they are applied. Often, upgrades are considered in one part of the network (e.g., core) before another in preparation for an upgrade downstream (closer to the users).
Performance upgrades are also applied when predictable and/or guaranteed flows are added to the network. When users, applications, or devices require network resources to be allocated per flow, capacity requirements can increase dramatically with added flows.
Technologies that can use the SONET hierarchy, such as ATM or HiPPI, have a capacity growth path based on selected SONET levels. Each SONET optical carrier (OC) level is a multiple of the base rate, OC-1, at 51.84 Mb/s. This comes from the size of a SONET frame (9 rows by 90 columns) and the clock rate (125 μs), resulting in 8000 frames/s:
(9 rows) (90 columns) (1 Byte/row-column) (8000 frames/s) (8 bits/Byte) = 51.84 Mb/s
Following are commonly used (or expected) SONET OC levels. When "c" is included in OC-Nc, it refers to a concatenated service, where N SONET payloads are combined in a common frame and transmitted across a common path. Some redundant overhead is removed, resulting in more efficient transmission.
| SONET Level | Rate |
|---|---|
| OC-3 | 155.52 Mb/s |
| OC-12 | 622 Mb/s |
| OC-48 | 2.488 Gb/s |
| OC-192 | 9.953 Gb/s |
| OC-768 | 39.812 Gb/s |
Many factors need to be considered when deciding on an upgrade path for your network. Some of these factors are how dynamic your NICs are (e.g., whether they can support multiple rates, such as 10/100 Mb/s Ethernet), the types and distances of cable runs planned for your infrastructure, and the types of optics (e.g., short-, medium-, or long-reach) optics in your network elements. In addition, some upgrade paths can be accomplished by configuration changes or software upgrades in the network elements, simplifying the upgrade process.
Common upgrade paths include Ethernet from 10 Mb/s to 10 Gb/s, FDDI from 100 Mb/s to 1 Gb/s, ATM and PoS from 1.5 Mb/s to 2.5 Gb/s, and frame relay from 56 Kb/s to 45 Mb/s. Some of these are shown in Figure 10.9.
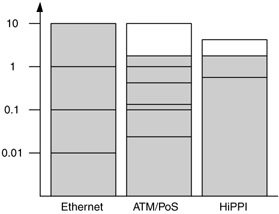
Figure 10.9: Capacity ranges for selected technologies.
There are also expansions into both higher and lower performance for some technologies. For example, with ATM, frame relay, and SMDS, the capacity range of each technology overlaps that of the others (Figure 10.10). This has had a positive effect on ATM and frame relay and a negative effect on SMDS.
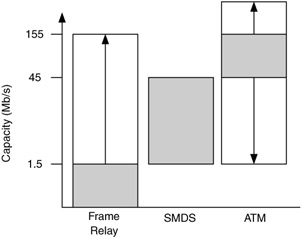
Figure 10.10: Overlap in frame relay/SMDS/ATM capacity ranges.
Performance upgrades should also include any applicable delay and RMA improvements. Delay improvements are likely to be the latency within an individual device that applies the proposed technology—for example, the latency of a switch or router with Gigabit Ethernet interfaces. The latency of individual devices will affect the overall one-way or round-trip delay in the network.
RMA improvement may be either within individual devices or across all devices that apply the technology within the network. For example, RMA may be improved within a device, such as the reliability of a switch or router with a particular technology. RMA may also be improved across all devices of a particular technology, for example, through a protocol or capability that enhances the technology (e.g., technology-specific redundancy software or hardware). For delay and RMA, as with capacity, graphs such as those shown in Figures 10.9 and 10.10 can be useful to make technology comparisons.
As a criteria for technology selection, performance upgrade paths affect the scalability of a network design, based on growth in the numbers of users, applications, and devices, as well as growth in the numbers and capacities of individual and composite flows.
Backbone Flows
Capacity upgrades are particularly important to consider for backbone flows. Backbone flows are the result of aggregating individual and composite flows and are generated where hierarchies are established (e.g., at distribution and core areas of the network). They are more susceptible to growth in capacity, and areas of the network that support backbone flows usually need to be more scalable than areas without backbone flows.
10.5.4 Flow Considerations
Our last evaluation criterion is based on the requirements from existing or expected flows in the network. The flow specification is used as the starting point in evaluating candidate technologies based on the performance requirements of each individual and composite flow.
Flow considerations are any technology-specific capabilities that support or enhance the performance requirements of traffic flows. Such considerations include the ability to recognize and differentiate between flows and apply performance mechanisms identified in the performance architecture component of the reference architecture.
Capacity planning is used to determine the required capacities of candidate technologies. In the next section, we will discuss how to estimate usage and modify flow capacities to reflect this usage. The result will be baseline capacities that we can compare against the available capacities of technologies.
Service planning is also used to evaluate candidate technologies. Each candidate technology will be evaluated on its ability to provide the types and degrees of service support required by the flow specification.
EAN: 2147483647
Pages: 161