XmlDocument and XmlNavigator
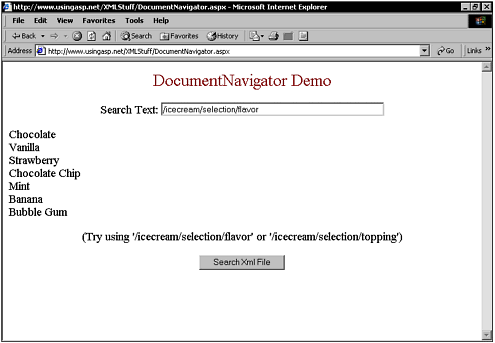
XmlDocument and XmlNavigatorXmlNavigator is an abstract base class that provides the basic functionality of all navigators. XmlNavigator supports selection nodes, looping through the selection, basic navigation routines, and aiding with the selection in more advanced ways (copying, removing, moving, and so on). The XmlDocument class is also able to use the class called XmlNode . Although XmlNode does not provide the generic navigation mechanism as well as an implementation of XPath as does XmlNavigator , it does provide basic methods for navigating the DOM tree (including the ChildNodes() , FirstChild() , LastChild() , ParentNode() , NextSibling() , and PreviousSibling() methods). Document navigation can also be performed using a separate class named XmlNavigator , which provides a generic navigation mechanism as well as an implementation of XPath. As with XmlReader and XmlWriter , XmlNavigator is an abstract base class that defines the common functionality of all navigators. XmlNavigator supports generic navigation routines, selecting nodes, iterating over the selection, and working with the selection in more advanced ways (copying, moving, removing, and so on). XmlNavigator is preferred over the standard DOM API; typical XmlNavigator implementations don't need to load the entire document structure into memory, whereas most DOM implementations do, making XmlNavigator a better-performing alternative. XmlNavigator also seems to provide a more intuitive interface, especially when working with XPath expressions. Select and SelectSingle are the two methods that XmlNavigator provides for choosing node-sets , which are equivalent to the SelectNode() and SelectSingleNode() methods offered by MSXML 3.0. Evaluated to identify a set of nodes, these methods accept an XPath expression in the form of a string or a precompiled expression object. XmlNavigator provides two methods for selecting node-sets, Select() and SelectSingle() , which are equivalent to the SelectNodes() and SelectSingleNode() methods offered by MSXML 3.0. Both methods accept an XPath expression in the form of a string or a precompiled expression object, which is evaluated to identify a set of nodes as follows : public static void EvaluateXPath( XmlNavigator nav ) { // returns a node-set nav.Select( "//Price/text()" ); while( nav.MoveToNextSelected() ) { // process selected nodes here } } If an expression will be used repeatedly, you can improve performance by compiling the expression into a cached object that can be reused as follows: Object cachedExpr = null; cachedExpr = nav.Compile("//Invoice[@id>1000]//Price[.>10]"); // can reuse expression w/out compilation cost nav.Select(cachedExpr); while( nav.MoveToNextSelected() ) { // process selected nodes here } After calling Select() , use the MoveToNextSelected() method to iterate over the selected nodes. Additional methods are available for copying, moving, and removing the selected nodes. For example, the following code fragment illustrates how to copy the selected nodes between XmlNavigators : public static void EvaluateXPath( XmlNavigator in, XmlNavigator out ) { // returns a node-set in.Select( "//Price" ); out.CopySelected( TreePosition.FirstChild, in ); // out navigator now contains selected nodes } And one of my favorite additions is the new Evaluate() method, which evaluates XPath expressions that return XPath types other than node-set (string, number, or Boolean). For example, the following example uses an XPath expression to sum all the Price elements in a document: public static void SumPriceNodes( XmlNavigator nav ) { // in this case, evaluate returns a number Console.WriteLine( "sum=" + nav.Evaluate( "sum(//Price)" ) ); } Without this method, you would have to select all the Price elements and walk through them, performing the arithmetic manually. DocumentNavigator is a concrete class, derived from XmlNavigator , that was designed specifically for navigating DOM trees. When you create an instance of DocumentNavigator , you simply pass it a reference to the XmlDocument that you want to navigate as follows: XmlDocument doc = new XmlDocument(); doc.Load( "person.xml" ); DocumentNavigator nav = new DocumentNavigator( doc ); nav.Select( "/person/name" ); while( nav.MoveToNextSelected() ) { // process selection here... } If you navigate using XmlNavigator , you can access information about the current node through its exposed properties. If you want a complete DOM view of the current node, use the GetNode() method to retrieve a reference to the current XmlNode object. Thanks to this extensible design, other navigator implementations are possible as well. For starters, there is a DataDocumentNavigator class for navigating an ADO.NET dataset just as you would an XML document. I've even heard rumors of a Registry navigator floating around. (And custom implementations of XmlNavigator get XPath support for free.) I have created an example on www.UsingASP.NET. The example allows a user to type in a query. It then searches through XML files to try and find a match or matches for the user 's query. You can see this example running in Figure 8.3. Figure 8.3. You can perform queries in an XML file with the DocumentNavigator class. The source code for this example can be seen in Listing 8.7. To accomplish the query I first created an XmlDocument object. I then loaded the document using the Load() method. And as you can see by the source code listing, the Load() method takes a single argument, which is a string containing the file name. You may want to notice to that once again I used the Request.MapPath() method to provide a fully qualified file name to the method. After loading in the XML file I created a DocumentNavigator object. Then I used the Select() method to do the query. The Select() method takes a single argument, which is the string containing the query that must be used. I then looped through by using MoveToNextSelected() and displayed each match for the query found. Bear in mind that the XML document contains ice cream flavors, so to have a successful query the user needs to enter something like chocolate or vanilla . Listing 8.7 This C# Code Performs a Query on the XML Data public void Button1_Click(System.Object sender, System.EventArgs e) { try { XmlDocument doc = new XmlDocument(); doc.Load(Request.MapPath("IceCream.xml")); DocumentNavigator nav = new DocumentNavigator(doc); nav.Select(TextBox1.Text); bool bFound = false; Label1.Text = ""; while( nav.MoveToNextSelected()) { Label1.Text += ( nav.InnerText + "<br>\n\r" ); bFound = true; } if( !bFound ) { Label1.Text = "No matches found!"; } } catch( Exception ex ) { Label1.Text = ex.Message; } } The XmlDocument and XmlNavigator classes provide you with a rich and powerful capability to perform queries on XML documents. They are easy to use and you will quickly be using them to add powerful functionality to your applications. |
EAN: 2147483647
Pages: 233