Components of the SQL Server Engine
| Figure 2-1 shows the general architecture of SQL Server, which has four major components (three of whose subcomponents are listed): protocols, the relational engine (also called the Query Processor), the storage engine, and the SQLOS. Every batch submitted to SQL Server for execution, from any client application, must interact with these four components. (For simplicity, I've made some minor omissions and simplifications and ignored certain "helper" modules among the subcomponents.) Figure 2-1. The major components of the SQL Server database engine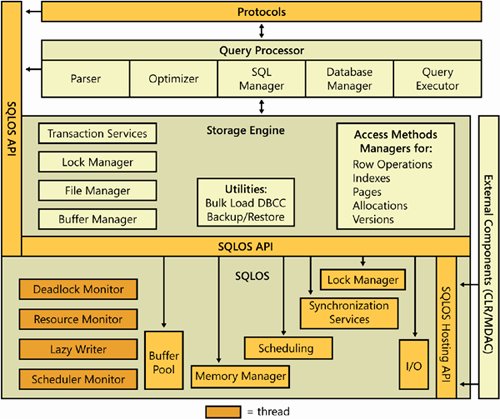 The protocol layer receives the request and translates it into a form that the relational engine can work with, and it also takes the final results of any queries, status messages, or error messages and translates them into a form the client can understand before sending them back to the client. The relational engine layer accepts SQL batches and determines what to do with them. For Transact-SQL queries and programming constructs, it parses, compiles, and optimizes the request and oversees the process of executing the batch. As the batch is executed, if data is needed, a request for that data is passed to the storage engine. The storage engine manages all data access, both through transaction-based commands and bulk operations such as backup, bulk insert, and certain DBCC (Database Consistency Checker) commands. The SQLOS layer handles activities that are normally considered to be operating system responsibilities, such as thread management (scheduling), synchronization primitives, deadlock detection, and memory management, including the buffer pool. Observing Engine BehaviorSQL Server 2005 introduces a suite of new system objects that allow developers and database administrators to observe much more of the internals of SQL Server than before. These metadata objects are called dynamic management views (DMVs) and dynamic management functions (DMFs). You can access them as if they reside in the new sys schema, which exists in every SQL Server 2005 database, but they are not real objects. They are similar to the pseudo-tables used in SQL Server 2000 for observing the active processes (sysprocesses) or the contents of the plan cache (syscacheobjects). However, the pseudo-tables in SQL Server 2000 do not provide any tracking of detailed resource usage and are not always directly usable to detect resource problems or state changes. Some of the DMVs and DMFs do allow tracking of detailed resource history, and there are more than 80 such objects that you can directly query and join with SQL SELECT statements. The DMVs and DMFs expose changing server state information that might span multiple sessions, multiple transactions, and multiple user requests. These objects can be used for diagnostics, memory and process tuning, and monitoring across all sessions in the server. The DMVs and DMFs aren't based on real tables stored in database files but are based on internal server structures, some of which I'll discuss in this chapter. I'll discuss further details about the DMVs and DMFs in various places in this book, where the contents of one or more of the objects can illuminate the topics being discussed. The objects are separated into several categories based on the functional area of the information they expose. They are all in the sys schema and have a name that starts with dm_, followed by a code indicating the area of the server with which the object deals. The main categories I'll address are:
SQL Server 2005 also has dynamic management objects for its functional components; these include objects for monitoring full-text search catalogs, service broker, replication, and the common language runtime (CLR). Now let's look at the major SQL Server engine modules. ProtocolsWhen an application communicates with the SQL Server Database Engine, the application programming interfaces (APIs) exposed by the protocol layer formats the communication using a Microsoft-defined format called a tabular data stream (TDS) packet. There are Net-Libraries on both the server and client computers that encapsulate the TDS packet inside a standard communication protocol, such as TCP/IP or Named Pipes. On the server side of the communication, the Net-Libraries are part of the Database Engine, and that protocol layer is illustrated in Figure 2-1. On the client side, the Net-Libraries are part of the SQL Native Client. The configuration of the client and the instance of SQL Server determine which protocol is used. SQL Server can be configured to support multiple protocols simultaneously, coming from different clients. Each client connects to SQL Server with a single protocol. If the client program does not know which protocols SQL Server is listening on, you can configure the client to attempt multiple protocols sequentially. In Chapter 3, I'll discuss how you can configure your machine to use one or more of the available protocols. The following protocols are available:
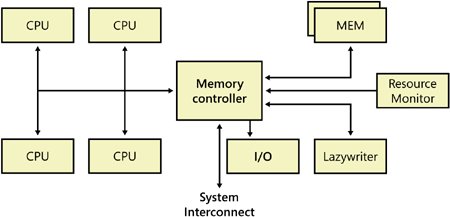
Tabular Data Stream EndpointsSQL Server 2005 also introduces a new concept for defining SQL Server connections: the connection is represented on the server end by a TDS endpoint. During setup, SQL Server creates an endpoint for each of the four Net-Library protocols supported by SQL Server, and if the protocol is enabled, all users have access to it. For disabled protocols, the endpoint still exists but cannot be used. An additional endpoint is created for the dedicated administrator connection (DAC), which can be used only by members of the sysadmin fixed server role. (I'll discuss the DAC in more detail shortly.) The Relational EngineAs mentioned earlier, the relational engine is also called the query processor. It includes the components of SQL Server that determine exactly what your query needs to do and the best way to do it. By far the most complex component of the query processor, and maybe even of the entire SQL Server product, is the query optimizer, which determines the best execution plan for the queries in the batch. The optimizer is discussed in great detail in Inside Microsoft SQL Server 2005: Query Tuning and Optimization; in this section, I'll give you just a high-level overview of the optimizer, as well as of the other components of the query processor. The relational engine also manages the execution of queries as it requests data from the storage engine and processes the results returned. Communication between the relational engine and the storage engine is generally in terms of OLE DB row sets. (Row set is the OLE DB term for a result set.) The storage engine comprises the components needed to actually access and modify data on disk. The Command ParserThe command parser handles Transact-SQL language events sent to SQL Server. It checks for proper syntax and translates Transact-SQL commands into an internal format that can be operated on. This internal format is known as a query tree. If the parser doesn't recognize the syntax, a syntax error is immediately raised that identifies where the error occurred. However, non-syntax error messages cannot be explicit about the exact source line that caused the error. Because only the command parser can access the source of the statement, the statement is no longer available in source format when the command is actually executed. The Query OptimizerThe query optimizer takes the query tree from the command parser and prepares it for execution. Statements that can't be optimized, such as flow-of-control and DDL commands, are compiled into an internal form. The statements that are optimizable are marked as such and then passed to the optimizer. The optimizer is mainly concerned with the DML statement SELECT, INSERT, UPDATE, and DELETE, which can be processed in more than one way, and it is the optimizer's job to determine which of the many possible ways is the best. It compiles an entire command batch, optimizes queries that are optimizable, and checks security. The query optimization and compilation result in an execution plan. The first step in producing such a plan is to normalize each query, which potentially breaks down a single query into multiple, fine-grained queries. After the optimizer normalizes a query, it optimizes it, which means it determines a plan for executing that query. Query optimization is cost based; the optimizer chooses the plan that it determines would cost the least based on internal metrics that include estimated memory requirements, CPU utilization, and number of required I/Os. The optimizer considers the type of statement requested, checks the amount of data in the various tables affected, looks at the indexes available for each table, and then looks at a sampling of the data values kept for each index or column referenced in the query. The sampling of the data values is called distribution statistics. (I'll discuss this topic further in Chapter 7.) Based on the available information, the optimizer considers the various access methods and processing strategies it could use to resolve a query and chooses the most cost-effective plan. The optimizer also uses pruning heuristics to ensure that optimizing a query doesn't take longer than it would take to simply choose a plan and execute it. The optimizer doesn't necessarily do exhaustive optimization. Some products consider every possible plan and then choose the most cost-effective one. The advantage of this exhaustive optimization is that the syntax chosen for a query will theoretically never cause a performance difference, no matter what syntax the user employed. But with a complex query, it could take much longer to estimate the cost of every conceivable plan than it would to accept a good plan, even if not the best one, and execute it. After normalization and optimization are completed, the normalized tree produced by those processes is compiled into the execution plan, which is actually a data structure. Each command included in it specifies exactly which table will be affected, which indexes will be used (if any), which security checks must be made, and which criteria (such as equality to a specified value) must evaluate to TRUE for selection. This execution plan might be considerably more complex than is immediately apparent. In addition to the actual commands, the execution plan includes all the steps necessary to ensure that constraints are checked. Steps for calling a trigger are slightly different from those for verifying constraints. If a trigger is included for the action being taken, a call to the procedure that comprises the trigger is appended. If the trigger is an instead-of trigger, the call to the trigger's plan replaces the actual data modification command. For after triggers, the trigger's plan is branched to right after the plan for the modification statement that fired the trigger, before that modification is committed. The specific steps for the trigger are not compiled into the execution plan, unlike those for constraint verification. A simple request to insert one row into a table with multiple constraints can result in an execution plan that requires many other tables to also be accessed or expressions to be evaluated. In addition, the existence of a trigger can cause many additional steps to be executed. The step that carries out the actual INSERT statement might be just a small part of the total execution plan necessary to ensure that all actions and constraints associated with adding a row are carried out. The SQL ManagerThe SQL manager is responsible for everything related to managing stored procedures and their plans. It determines when a stored procedure needs recompilation, and it manages the caching of procedure plans so that other processes can reuse them. The SQL manager also handles autoparameterization of queries. In SQL Server 2005, certain kinds of ad hoc queries are treated as if they were parameterized stored procedures, and query plans are generated and saved for them. SQL Server can save and reuse plans in several other ways, but in some situations using a saved plan might not be a good idea. For details on autoparameterization and reuse of plans, see Inside Microsoft SQL Server 2005: Query Tuning and Optimization. The Database ManagerThe database manager handles access to the metadata needed for query compilation and optimization, making it clear that none of these separate modules can be run completely separately from the others. The metadata is stored as data and is managed by the storage engine, but metadata elements such as the datatypes of columns and the available indexes on a table must be available during the query compilation and optimization phase, before actual query execution starts. The Query ExecutorThe query executor runs the execution plan that the optimizer produced, acting as a dispatcher for all the commands in the execution plan. This module steps through each command of the execution plan until the batch is complete. Most of the commands require interaction with the storage engine to modify or retrieve data and to manage transactions and locking. The Storage EngineThe SQL Server storage engine has traditionally been considered to include all the components involved with the actual processing of data in your database. SQL Server 2005 separates out some of these components into a module called the SQLOS, which I'll describe shortly. In fact, the SQL Server storage engine team at Microsoft actually encompasses three areas: access methods, transaction management, and the SQLOS. For the purposes of this book, I'll consider all the components that Microsoft does not consider part of the SQLOS to be part of the storage engine. Access MethodsWhen SQL Server needs to locate data, it calls the access methods code. The access methods code sets up and requests scans of data pages and index pages and prepares the OLE DB row sets to return to the relational engine. Similarly when data is to be inserted, the access methods code can receive an OLE DB row set from the client. The access methods code contains components to open a table, retrieve qualified data, and update data. The access methods code doesn't actually retrieve the pages; it makes the request to the buffer manager, which ultimately serves up the page in its cache or reads it to cache from disk. When the scan starts, a look-ahead mechanism qualifies the rows or index entries on a page. The retrieving of rows that meet specified criteria is known as a qualified retrieval. The access methods code is employed not only for queries (selects) but also for qualified updates and deletes (for example, UPDATE with a WHERE clause) and for any data modification operations that need to modify index entries. The Row and Index OperationsYou can consider row and index operations to be components of the access methods code because they carry out the actual method of access. Each component is responsible for manipulating and maintaining its respective on-disk data structuresnamely, rows of data or B-tree indexes, respectively. They understand and manipulate information on data and index pages. The row operations code retrieves, modifies, and performs operations on individual rows. It performs an operation within a row, such as "retrieve column 2" or "write this value to column 3." As a result of the work performed by the access methods code, as well as by the lock and transaction management components (discussed shortly), the row is found and appropriately locked as part of a transaction. After formatting or modifying a row in memory, the row operations code inserts or deletes a row. There are special operations that the row operations code needs to handle if the data is a Large Object (LOB) datatypetext, image, or ntextor if the row is too large to fit on a single page and needs to be stored as overflow data. We'll look at the different types of page storage structures in Chapter 6. The index operations code maintains and supports searches on B-trees, which are used for SQL Server indexes. An index is structured as a tree, with a root page and intermediate-level and lower-level pages (or branches). A B-tree groups records that have similar index keys, thereby allowing fast access to data by searching on a key value. The B-tree's core feature is its ability to balance the index tree. (B stands for balanced.) Branches of the index tree are spliced together or split apart as necessary so the search for any given record always traverses the same number of levels and therefore requires the same number of page accesses. Page Allocation OperationsThe allocation operations code manages a collection of pages as named databases and keeps track of which pages in a database have already been used, for what purpose they have been used, and how much space is available on each page. Each database is a collection of 8-kilobyte (KB) disk pages that are spread across one or more physical files. (In Chapter 4, you'll find more details about the physical organization of databases.) SQL Server uses eight types of disk pages: data pages, LOB pages, index pages, Page Free Space (PFS) pages, Global Allocation Map and Shared Global Allocation Map (GAM and SGAM) pages, Index Allocation Map (IAM) pages, Bulk Changed Map (BCM) pages, and Differential Changed Map (DCM) pages. All user data is stored on data or LOB pages, and all index rows are stored on index pages. PFS pages keep track of which pages in a database are available to hold new data. Allocation pages (GAMs, SGAMs, and IAMs) keep track of the other pages. They contain no database rows and are used only internally. Bulk Changed Map pages and Differential Changed Map pages are used to make backup and recovery more efficient. I'll explain these types of pages in Chapter 6 and Chapter 7. Versioning OperationsAnother type of data access new to SQL Server 2005 is access through the version store. Row versioning allows SQL Server to maintain older versions of changed rows SQL Server's row versioning technology supports snapshot isolation as well as other features of SQL Server 2005, including online index builds and triggers, and it is the versioning operations code that maintains row versions for whatever purpose they are needed. Chapters 4, 6, and 7 deal extensively with the internal details of the structures that the access methods code works with: databases, tables, and indexes. Transaction ServicesA core feature of SQL Server is its ability to ensure that transactions are atomicthat is, all or nothing. In addition, transactions must be durable, which means that if a transaction has been committed, it must be recoverable by SQL Server no matter whateven if a total system failure occurs 1 millisecond after the commit was acknowledged. There are actually four properties that transactions must adhere to, called the ACID properties: atomicity, consistency, isolation, and durability. I'll discuss all four of these properties in Chapter 8, when I discuss transaction management and concurrency issues. In SQL Server, if work is in progress and a system failure occurs before the transaction is committed, all the work is rolled back to the state that existed before the transaction began. Write-ahead logging makes it possible to always roll back work in progress or roll forward committed work that has not yet been applied to the data pages. Write-ahead logging ensures that the record of each transaction's changes are captured on disk in the transaction log before a transaction is acknowledged as committed and that the log records are always written to disk before the data pages where the changes were actually made are written. Writes to the transaction log are always synchronousthat is, SQL Server must wait for them to complete. Writes to the data pages can be asynchronous because all the effects can be reconstructed from the log if necessary. The transaction management component coordinates logging, recovery, and buffer management. These topics are discussed later in this book; at this point, we'll just look briefly at transactions themselves. The transaction management component delineates the boundaries of statements that must be grouped together to form an operation. It handles transactions that cross databases within the same SQL Server instance, and it allows nested transaction sequences. (However, nested transactions simply execute in the context of the first-level transaction; no special action occurs when they are committed. And a rollback specified in a lower level of a nested transaction undoes the entire transaction.) For a distributed transaction to another SQL Server instance (or to any other resource manager), the transaction management component coordinates with the Microsoft Distributed Transaction Coordinator (MS DTC) service using operating system remote procedure calls. The transaction management component marks save pointspoints you designate within a transaction at which work can be partially rolled back or undone. The transaction management component also coordinates with the locking code regarding when locks can be released, based on the isolation level in effect. It also coordinates with the versioning code to determine when old versions are no longer needed and can be removed from the version store. The isolation level in which your transaction runs determines how sensitive your application is to changes made by others and consequently how long your transaction must hold locks or maintain versioned data to protect against those changes. SQL Server 2005 supports two concurrency models for guaranteeing the ACID properties of transactions: optimistic concurrency and pessimistic concurrency. Pessimistic concurrency guarantees correctness and consistency by locking data so that it cannot be changed; this is the concurrency model that every earlier version of SQL Server has used exclusively. SQL Server 2005 introduces optimistic concurrency, which provides consistent data by keeping older versions of rows with committed values in an area of tempdb called the version store. With optimistic concurrency, readers will not block writers and writers will not block readers, but writers will still block writers. The cost of these non-blocking reads and writes must be considered. To support optimistic concurrency, SQL Server needs to spend more time managing the version store. In addition, administrators will have to pay even closer attention to the tempdb database and the extra maintenance it requires. Five isolation-level semantics are available in SQL Server 2005. Three of them support only pessimistic concurrency: Read Uncommitted (also called "dirty read"), Repeatable Read, and Serializable. Snapshot Isolation Level supports optimistic concurrency. The default isolation level, Read Committed, can support either optimistic or pessimistic concurrency, depending on a database setting. The behavior of your transactions depends on the isolation level and the concurrency model you are working with. A complete understanding of isolation levels also requires an understanding of locking because the topics are so closely related. The next section gives an overview of locking; you'll find more detailed information on isolation, transactions, and concurrency management in Chapter 8. Locking OperationsLocking is a crucial function of a multi-user database system such as SQL Server, even if you are operating primarily in the snapshot isolation level with optimistic concurrency. SQL Server lets you manage multiple users simultaneously and ensures that the transactions observe the properties of the chosen isolation level. Even though readers will not block writers and writers will not block readers in snapshot isolation, writers do acquire locks and can still block other writers, and if two writers try to change the same data concurrently, a conflict will occur that must be resolved. The locking code acquires and releases various types of locks, such as share locks for reading, exclusive locks for writing, intent locks taken at a higher granularity to signal a potential "plan" to perform some operation, and extent locks for space allocation. It manages compatibility between the lock types, resolves deadlocks, and escalates locks if needed. The locking code controls table, page, and row locks as well as system data locks. Concurrency, with locks or row versions, is an important aspect of SQL Server. Many developers are keenly interested in it because of its potential effect on application performance. Chapter 8 is devoted to the subject, so I won't go into it further here. Other OperationsAlso included in the storage engine are components for controlling utilities such as bulk load, DBCC commands, and backup and restore operations. There is a component to control sorting operations and one to physically manage the files and backup devices on disk. These components are discussed in Chapter 4. The log manager makes sure that log records are written in a manner to guarantee transaction durability and recoverability; I'll go into detail about the transaction log in Chapter 5. Finally, there is the buffer manager, a component that manages the distribution of pages within the buffer pool. I'll discuss the buffer pool in much more detail later in the chapter. The SQLOSWhether the components of the SQLOS layer are actually part of the storage engine depends on whom you ask. In addition, trying to figure out exactly which components are in the SQLOS layer can be rather like herding cats. I have seen several technical presentations on the topic at conferences and have exchanged e-mail and even spoken face to face with members of the product team, but the answers vary. The manager who said he was responsible for the SQLOS layer defined the SQLOS as everything he was responsible for, which is a rather circular definition. Earlier versions of SQL Server have a thin layer of interfaces between the storage engine and the actual operating system through which SQL Server makes calls to the OS for memory allocation, scheduler resources, thread and worker management, and synchronization objects. However, the services in SQL Server that needed to access these interfaces can be in any part of the engine. SQL Server requirements for managing memory, schedulers, synchronization objects, and so forth have become more complex. Rather than each part of the engine growing to support the increased functionality, all services in SQL Server that need this OS access have been grouped together into a single functional unit called the SQLOS. In general, the SQLOS is like an operating system inside SQL Server. It provides memory management, scheduling, IO management, a framework for locking and transaction management, deadlock detection, general utilities for dumping, exception handling, and so on. Another member of the product team described the SQLOS to me as a set of data structures and APIs that could potentially be needed by operations running at any layer of the engine. For example, consider various operations that require use of memory. SQL Server doesn't just need memory when it reads in data pages through the storage engine; it also needs memory to hold query plans developed in the query processor layer. Figure 2-1 (shown earlier) depicts the SQLOS layer in several parts, but this is just a way of showing that many SQL Server components use SQLOS functionality. The SQLOS, then, is a collection of structures and processes that handles many of the tasks you might think of as being operating system tasks. Defining them in SQL Server gives the Database Engine greater capacity to optimize these tasks for use by a powerful relational database system. NUMA ArchitectureSQL Server 2005 is Non-Uniform Memory Access (NUMA) aware, and both scheduling and memory management can take advantage of NUMA hardware by default. You can use some special configurations when you work with NUMA, so I'll provide some general background here before discussing scheduling and memory. The main benefit of NUMA is scalability, which has definite limits when you use symmetric multiprocessing (SMP) architecture. With SMP, all memory access is posted to the same shared memory bus. This works fine for a relatively small number of CPUs, but problems appear when you have many CPUs competing for access to the shared memory bus. The trend in hardware has been to have more than one system bus, each serving a small set of processors. NUMA limits the number of CPUs on any one memory bus. Each group of processors has its own memory and possibly its own I/O channels. However, each CPU can access memory associated with other groups in a coherent way, and I'll discuss this a bit more later in the chapter. Each group is called a NUMA node and the nodes are connected to each other by means of a high speed interconnection. The number of CPUs within a NUMA node depends on the hardware vendor. It is faster to access local memory than the memory associated with other NUMA nodes. This is the reason for the name Non-Uniform Memory Access. Figure 2-2 shows a NUMA node with four CPUs. Figure 2-2. A NUMA node with four CPUs SQL Server 2005 allows you to subdivide one or more physical NUMA nodes into smaller NUMA nodes, referred to as software NUMA or soft-NUMA. You typically use soft-NUMA when you have many CPUs and do not have hardware NUMA because soft-NUMA allows only for the subdividing of CPUs but not memory. You can also use soft-NUMA to subdivide hardware NUMA nodes into groups of fewer CPUs than is provided by the hardware NUMA. Your soft-NUMA nodes can also be configured to listen on its own port. Only the SQL Server scheduler and SQL Server Network Interface (SNI) are soft-NUMA aware. Memory nodes are created based on hardware NUMA and are therefore not affected by soft-NUMA. TCP/IP, VIA, Named Pipes, and shared memory can take advantage of NUMA round-robin scheduling, but only TCP and VIA can affinitize to a specific set of NUMA nodes. See Books Online for how to use the SQL Server Configuration Manager to set a TCP/IP address and port to single or multiple nodes. The SchedulerPrior to SQL Server 7.0, scheduling was entirely dependent on the underlying Windows operating system. Although this meant that SQL Server could take advantage of the hard work done by the Windows engineers to enhance scalability and efficient processor use, there were definite limits. The Windows scheduler knew nothing about the needs of a relational database system, so it treated SQL Server worker threads the same as any other process running on the operating system. However, a high-performance system such as SQL Server functions best when the scheduler can meet its special needs. SQL Server 7.0 was designed to handle its own scheduling to gain a number of advantages, including the following:
The scheduler in SQL Server 7.0 and SQL Server 2000 was called the User Mode Scheduler (UMS) to reflect the fact that it ran primarily in user mode, as opposed to kernel mode. SQL Server 2005 calls its scheduler the SOS Scheduler and improves on UMS even more. One major difference between the SQL Server scheduler, whether UMS or SOS, and the Windows scheduler is that the SQL Server scheduler runs as a cooperative rather than preemptive scheduler. This means it relies on the workers threads or fibers to voluntarily yield often enough so one process or thread doesn't have exclusive control of the system. The SQL Server product team has to make sure that its code runs efficiently and voluntarily yields the scheduler in appropriate places; the reward for this is much greater control and scalability than is possible with the Windows generic scheduler. SQL Server WorkersYou can think of the SQL Server scheduler as a logical CPU used by SQL Server workers. A worker can be either a thread or a fiber that is bound to a logical scheduler. If the Affinity Mask Configuration option is set, each scheduler is affinitized to a particular CPU. (I'll talk about configuration in the next chapter.) Thus, each worker is also associated with a single CPU. Each scheduler is assigned a worker limit based on the configured Max Worker Threads and the number of schedulers, and each scheduler is responsible for creating or destroying workers as needed. A worker cannot move from one scheduler to another, but as workers are destroyed and created, it can appear as if workers are moving between schedulers. Workers are created when the scheduler receives a request (a task to execute) and there are no idle workers. A worker can be destroyed if it has been idle for at least 15 minutes, or if SQL Server is under memory pressure. Each worker can use at least half a megabyte of memory on a 32-bit system and at least 2 gigabytes (GB) on a 64-bit system, so destroying multiple workers and freeing their memory can yield an immediate performance improvement on memory-starved systems. SQL Server actually handles the worker pool very efficiently, and you might be surprised to know that even on very large systems with hundreds or even thousands of users, the actual number of SQL Server workers might be much lower than the configured value for Max Worker Threads. In a moment, I'll tell you about some of the dynamic management objects that let you see how many workers you actually have, as well as scheduler and task information (discussed next). SQL Server SchedulersIn SQL Server 2005, each actual CPU (whether hyperthreaded or physical) has a scheduler created for it when SQL Server starts up. This is true even if the affinity mask option has been configured so that SQL Server is set to not use all of the available physical CPUs. In SQL Server 2005, each scheduler is set to either ONLINE or OFFLINE based on the affinity mask settings, and the default is that all schedulers are ONLINE. Changing the affinity mask value can set a scheduler's status to OFFLINE, and you can do this without having to restart SQL Server. Note that when a scheduler is switched from ONLINE to OFFLINE due to a configuration change, any work already assigned to the scheduler is first completed and no new work is assigned. SQL Server TasksThe unit of work for a SQL Server worker is a request, or a task, which you can think of as being equivalent to a single batch sent from the client to the server. Once a request is received by SQL Server, it is bound to a worker, and that worker processes the entire request before handling any other request. This holds true even if the request is blocked for some reason, such as while it waits for a lock or for I/O to complete. The particular worker will not handle any new requests but will wait until the blocking condition is resolved and the request can be completed. Keep in mind that a SPID (session ID) is not the same as a task. A SPID is a connection or channel over which requests can be sent, but there is not always an active request on any particular SPID. In SQL Server 2000, each SPID is assigned to a scheduler when the initial connection is made, and all requests sent over the same SPID are handled by the same scheduler. The assignment of a SPID to a scheduler is based on the number of SPIDs already assigned to the scheduler, with the new SPID assigned to the scheduler with the fewest users. Although this provides a rudimentary form of load balancing, it doesn't take into account SPIDs that are completely quiescent or that are doing enormous amounts of work, such as data loading. In SQL Server 2005, a SPID is no longer bound to a particular scheduler. Each SPID has a preferred scheduler, which is the scheduler that most recently processed a request from the SPID. The SPID is initially assigned to the scheduler with the lowest load. (You can get some insight into the load on each scheduler by looking at the load_factor column in the DMV dm_os_schedulers.) However, when subsequent requests are sent from the same SPID, if another scheduler has a load factor that is less than a certain percentage of the average of all the scheduler's load factor, the new task is given to the scheduler with the smallest load factor. There is a restriction that all tasks for one SPID must be processed by schedulers on the same NUMA node. The exception to this restriction is when a query is being executed as a parallel query across multiple CPUs. The optimizer can decide to use more CPUs that are available on the NUMA node processing the query, so other CPUs (and other schedulers) can be used. Threads vs. FibersThe User Mode Scheduler, as mentioned earlier, was designed to work with workers running on either threads or fibers. Windows fibers have less overhead associated with them than threads do, and multiple fibers can run on a single thread. You can configure SQL Server to run in fiber mode by setting the Lightweight Pooling option to 1. Although using less overhead and a "lightweight" mechanism sounds like a good idea, you should carefully evaluate the use of fibers. Certain components of SQL Server don't work, or don't work well, when SQL Server runs in fiber mode. These components include SQLMail and SQLXML. Other components, such as heterogeneous and CLR queries, are not supported at all in fiber mode because they need certain thread-specific facilities provided by Windows. Although it is possible for SQL Server to switch to thread mode to process requests that need it, the overhead might be greater than the overhead of using threads exclusively. Fiber mode was actually intended just for special niche situations in which SQL Server reaches a limit in scalability due to spending too much time switching between threads contexts or switching between user mode and kernel mode. In most environments, the performance benefit gained by fibers is quite small compared to benefits you can get by tuning in other areas. If you're certain you have a situation that could benefit from fibers, be sure to do thorough testing before you set the option on a production server. In addition, you might even want put in a call to Microsoft Customer Support Services just to be certain. NUMA and SchedulersWith a NUMA configuration, every node has some subset of the machine's processors and the same number of schedulers. When a machine is configured for hardware NUMA, each node has the same number of processors, but for soft-NUMA that you configure yourself, you can assign different numbers of processors to each node. There will still be the same number of schedulers as processors. When SPIDs are first created, they are assigned to nodes on a round-robin basis. The scheduler monitor then assigns the SPID to the least loaded scheduler on that node. As mentioned earlier, if the spid is moved to another scheduler, it stays on the same node. A single processor or SMP machine will be treated as a machine with a single NUMA node. Just like on an SMP machine, there is no hard mapping between schedulers and a CPU with NUMA, so any scheduler on an individual node can run on any CPU on that node. However, if you have set the Affinity Mask Configuration option, each scheduler on each node will be fixed to run on a particular CPU. Every NUMA node has its own lazywriter, which I'll talk about later. Every node also has its own Resource Monitor, which are managed by a hidden scheduler. The Resource Monitor has its own spid, which you can see by querying the sys.dm_exec_requests and sys.dm_os_workers DMVs, as shown here: SELECT session_id, CONVERT (varchar(10), t1.status) AS status, CONVERT (varchar(20), t1.command) AS command, CONVERT (varchar(15), t2.state) AS worker_state FROM sys.dm_exec_requests AS t1 JOIN sys.dm_os_workers AS t2 ON t2.task_address = t1.task_address WHERE command = 'RESOURCE MONITOR' Every node has its own Scheduler Monitor, which can run on any SPID and runs in a preemptive mode. The Scheduler Monitor checks the health of the other schedulers running on the node, and it is also responsible for sending messages to the schedulers to help them balance their workload. Every node also has its own I/O Completion Port (IOCP), which is the network listener. Dynamic AffinityIn SQL Server 2005 (in all editions except SQLExpress), processor affinity can be controlled dynamically. When SQL Server starts up, all scheduler tasks are started on server startup, so there is one scheduler per CPU. If the affinity mask has been set, some of the schedulers are then marked as offline and no tasks are assigned to them. When the affinity mask is changed to include additional CPUs, the new CPU is brought online. The Scheduler Monitor then notices an imbalance in workload and starts picking workers to move to the new CPU. When a CPU is brought offline by changing the affinity mask, the scheduler for that CPU continues to run active workers, but the scheduler itself is moved to one of the other CPUs that is still online. No new workers are given to this scheduler, which is now offline, and when all active workers have finished their tasks, the scheduler stops. Binding Schedulers to CPUsRemember that normally schedulers are not bound to CPUs in a strict one-to-one relationship, even though there is the same number of schedulers as CPUs. A scheduler is bound to a CPU only when the affinity mask is set. This is true even if you set the affinity mask to use all of the CPUs which is the default. For example, the default Affinity Mask Configuration value is 0, which means to use all CPUs, with no hard binding of scheduler to CPU. In fact, in some cases when there is a heavy load on the machine, Windows can run two schedulers on one CPU. For an eight-processor machine, an affinity mask value of 3 (bit string 00000011) means that only CPUs 0 and 1 will be used and two schedulers will be bound to the two CPUs. If you set the affinity mask to 255 (bit string 11111111), all the CPUs will be used, just like with the default. However, with the affinity mask set, the eight CPUS will be bound to the eight schedulers. In some situations, you might want to limit the number of CPUs available but not bind a particular scheduler to a single CPUfor example, if you are using a multiple-CPU machine for server consolidation. Suppose you have a 64-processor machine on which you are running eight SQL Server instances and you want each instance to use eight of the processors. Each instance will have a different affinity mask that specifies a different subset of the 64 processors, so you might have affinity mask values 255 (0xFF), 65280 (0xFF00), 16711680 (0xFF0000), and 4278190080 (0xFF000000). Because the affinity mask is set, each instance will have hard binding of scheduler to CPU. If you want to limit the number of CPUs but still not constrain a particular scheduler to running on a specific CPU, you can start SQL Server with traceflag 8002. This lets you have CPUs mapped to an instance, but within the instance, schedulers are not bound to CPUs. Observing Scheduler InternalsSQL Server 2005 has several dynamic management objects that provide information about schedulers, work, and tasks. These are primarily intended for use by Microsoft Customer Support Services, but you can use them to gain a greater appreciation for the information SQL Server keeps track of. Note that all these objects require a SQL Server 2005 permission called View Server State. By default, only an administrator has that permission, but it can be granted to others. For each of the objects, I will list some of the more useful or interesting columns and provide the description of the column taken from SQL Server 2005 Books Online. For the full list of columns, most of which are useful only to support personnel, you can refer to Books Online, but even then you'll find that some of the columns are listed as "for internal use only." sys.dm_os_schedulersThis view returns one row per scheduler in SQL Server. Each scheduler is mapped to an individual processor in SQL Server. You can use this view to monitor the condition of a scheduler or to identify runaway tasks. Interesting columns include the following:
sys.dm_os_workersThis view returns a row for every worker in the system. Interesting columns include the following:
sys.dm_os_threadsThis view returns a list of all SQLOS threads that are running under the SQL Server process. Interesting columns include the following:
sys.dm_os_tasksThis view returns one row for each task that is active in the instance of SQL Server. Interesting columns include the following:
sys.dm_os_waiting_tasksThis view returns information about the queue of tasks that are waiting on some resource. Interesting columns include the following:
The Dedicated Administrator Connection
Under pathological conditions such as a complete lack of available resources, it is possible for SQL Server to enter an abnormal state in which no further connections can be made to the SQL Server instance. In SQL Server 2000, this situation means that an administrator cannot get in to kill any troublesome connections or even begin to diagnose the possible cause of the problem. SQL Server 2005 introduces a special connection called the dedicated administrator connection (DAC) that is designed to be accessible even when no other access can be made. Access via the DAC must be specially requested. You can also connect to the DAC using the command-line tool SQLCMD, by using the /A flag. This method of connection is recommended because it uses fewer resources than the graphical interface method but offers more functionality than other command-line tools, such as osql. Through SQL Server Management Studio, you can specify that you want to connect using DAC by preceding the name of your SQL Server with ADMIN: in the Connection dialog box. For example, to connect to the default SQL Server instance on my machine, TENAR, I would enter ADMIN:TENAR. To connect to a named instance called SQL2005 on the same machine, I would enter ADMIN:TENAR\SQL2005. DAC is a special-purpose connection designed for diagnosing problems in SQL Server and possibly resolving them. It is not meant to be used as a regular user connection. Any attempt to connect using DAC when there is already an active DAC connection will result in an error. The message returned to the client will say only that the connection was rejected; it will not state explicitly that it was because there already was an active DAC. However, a message will be written to the error log indicating the attempt (and failure) to get a second DAC connection. You can check whether a DAC is in use by running the following query. If there is an active DAC, the query will return the SPID for the DAC; otherwise, it will return no rows. SELECT t2.session_id FROM sys.tcp_endpoints as t1 JOIN sys.dm_exec_sessions as t2 ON t1.endpoint_id = t2.endpoint_id WHERE t1.name='Dedicated Admin Connection' You should keep the following in mind about using the DAC:
You might not always be able to accomplish your intended tasks using the DAC. Suppose you have an idle connection that is holding on to a lock. If the connection has no active task, there is no thread associated with it, only a connection ID. Suppose further than many other processes are trying to get access to the locked resource, and that they are blocked. Those connections still have an incomplete task, so they will not release their worker. If 255 such processes (the default number of worker threads) try to get the same lock, all available workers might get used up and no more connections can be made to SQL Server. Because the DAC has its own scheduler, you can start it, and the expected solution would be to kill the connection that is holding the lock but not do any further processing to release the lock. But if you try to use the DAC to kill the process holding the lock, the attempt will fail. SQL Server would need to give a worker to the task in order to kill it, and there are no workers available. The only solution is to kill several of the (blameless) blocked processes that still have workers associated with them. Note
The DAC is not guaranteed to always be usable, but because it reserves memory and a private scheduler and is implemented as a separate node, a connection will probably be possible when you cannot connect in any other way. |
EAN: 2147483647
Pages: 115