Software Failure Tree Analysis
| Software Failure Tree Analysis (SFTA) is like FMEA in that its purpose is to anticipate failure a priori in a program rather than to prove that it works properly in an a posteriori or testing procedure. In manufacturing it is called Fault Tree Analysis (FTA). Several software reliability experts have used it for software reliability analysis, and it has become known as SFTA.[13], [14] SFTA may begin in the program's detailed design phase, not quite as far upstream as FMEA, because it needs a dynamic expression of the program's function in the form of a flowchart or high-level pseudocode to begin the analysis. The fault tree is a static mapping of the program's flow into a static tree diagram that lists the operational possibilities at each stage of the program's dynamic process. Used at the design phase, it identifies some of the top-level hazards. Used at the coding phase, it identifies some test paths that should be implemented to verify that lower-level hazards will not occur. Like FTA, SFTA begins by identifying potential failures during the design phase. Although it is done during design, the hazards or potential failures in operation and maintenance are also considered and forecast. The term hazard is often used to denote a potential failure, because we cannot call a problem a failure before it actually happens! Although the terminology differs from one author to another, a hazard has three basic characteristics:
Table 13.3 illustrates the fundamental hazard opportunities.
To build a fault tree, you draw a graph whose nodes are hazards of either single components, subsystems, or the entire system. Relationships among the nodes are represented by edges in the graph. Each edge is labeled AND if both components must fail, OR if one or the other must fail, or N of M if N of M redundant components must fail.[15] Each node in the graph must represent an independent event. When the graph is complete, the failure tree can be scanned to identify the following:
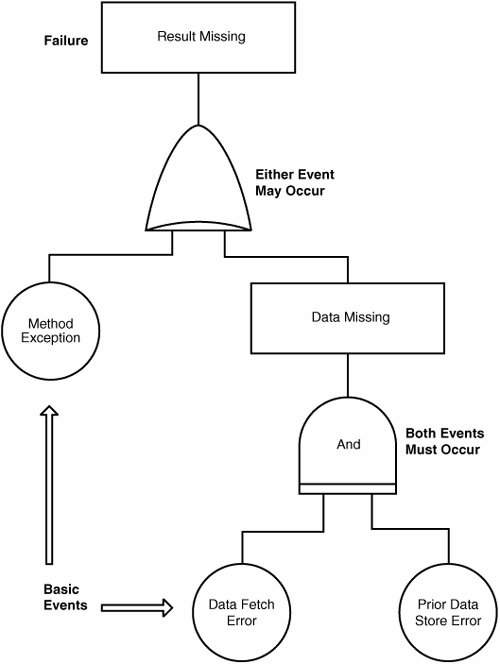
Figure 13.3 shows an example of an SFTA graph with AND and OR connectors for a simple scenario. A method call fails to produce a result because hidden variable or object-state data was not stored properly, resulting in a consequent data read error, or because the method throws an exception. The low-level design changes required to prevent these hazards would start with catching any method exceptions and then would add code to ensure that sequential data is properly stored and recast upon recall. Figure 13.3. A Simple SFTA Graph for a Method Invocation Such an analysis can be applied to any system, whether hardware or software or both, but it's especially suitable for software systems because a software design can be expressed as sequences, decisions or branches, and iterations. As soon as the fault tree for a design is available, we can assume that a certain fault will occur. But if we cannot find a set of events in the tree that will produce it, we may conclude that it cannot occur. However, if points of failure do appear in the design's fault tree, they can be removed, components or conditions can be added to prevent that hazard's enabling conditions to arise, or components can be added to correct the problem if the failure inevitably does arise. Some hazards in computation are inevitable, and modern languages such as Java have exception-handling capability to deal with them. Examples are floating-point underflow or overflow, division by 0, and numbers out of range. Earlier programming languages allowed the programmer to laboriously code avoidance or hazard/exception handling for such events, however unlikely. But modern languages "throw" exceptions automatically and encourage the programmer to "catch" them in code blocks that prevent the program from either halting or producing an incorrect result. Fault trees have been used in mechanical design to calculate the probability that a given fault will occur, but such a practice has not yet been applied to computer software to our knowledge. For large application programs having many dependencies or time and rate dependencies, the failure trees can be very time-consuming to draw, so the analysis may become quite tedious. The research frontier for this methodology is automating the construction of the tree and its graph from a design-level specification of the program, as well as automating the analysis of the graph for potential hazards. As soon as the failure points are identified, redesign to correct them is neither difficult nor costly. In fact, it occurs so far upstream in the development process that it is essentially part of the first-level design review. |
EAN: 2147483647
Pages: 394