4.3 Placing Storage Intelligence
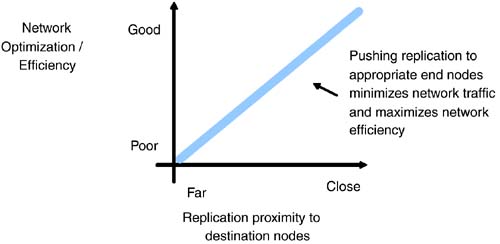
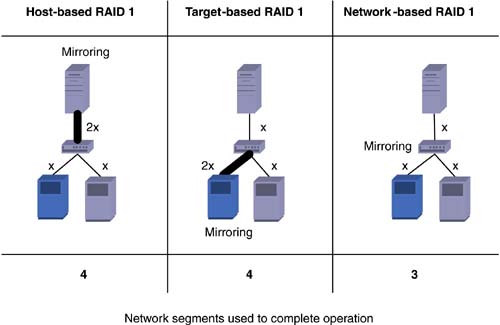
| Placing storage intelligence and accompanying services depends upon application requirements, cost points, network utilization, and preferences. For each service category, certain implementations might work better in one area than another. While the rapid pace of change makes hard and fast guidelines challenging, certain storage services location make more sense than others. Using a few implementation examples across services categories, we show how host, fabric, and subsystem methods differ . 4.3.1 Intelligent Storage DeliveredThe first storage subsystems provided a relatively simple means of protecting data on nonvolatile media. Demand for storage beyond what could be effectively delivered by tape spurred the introduction of plain vanilla disk systems. The invention of RAID algorithms dramatically changed the picture and launched both performance and intelligence improvements in storage functionality. In the case of RAID 0, performance improvements resulted from striping data across multiple disks and generating higher overall throughput that any single disk could generate independently. With RAID 1, mirroring functionality enabled intelligent redundancy mechanisms to boost overall system availability. With DAS, host and target implementations competed with one another to offer additional RAID services. Depending on the cost/performance tradeoffs, location of RAID functionality varied between hosts and targets. While all RAID functionality could be accomplished via host-based software, RAID 0 and 5 (striping and striping with parity) were best placed in the target due to the compute- intensive nature of these algorithms. Even though RAID 0 and 5 could run in host-based software, the required CPU processing cycles were likely to take away from application performance. Today, even with many host-based volume management software packages offering RAID 5 functionality, this feature is almost never turned on due to the performance impact. RAID striping functions have therefore found a comfortable and largely uncontested home within the storage subsystems themselves . Staying with the direct-attach model, RAID 1 (mirroring) could reside in either location ”host or target. However, when the host has to maintain two copies, it must generate twice the I/Os, and the application waits for both to complete. A three-way mirror would triple the I/O traffic. The same applies for target-based RAID 1 ”it must handle twice the I/Os. Host-based RAID 1 does offer a tight coupling with applications and can easily control the behavior of the service, but at the penalty of handling double the traffic. The build-out of a storage network changes the optimal location of RAID 1 services. Fortunately, many scenarios in storage networking can benefit directly from longstanding techniques applied in traditional data networking. For example, multicasting protocols ” essentially an n -way mirror ”attempt to replicate data as close as possible to the receiving end nodes. A host-based mirroring implementation in a storage network would therefore be the worst implementation when applying multicasting techniques. Replicating data at the source is the most inefficient use of network connections. By pushing the replication closer to the end nodes, the total amount of network traffic decreases, maximizing network efficiency. This basic effect is shown in Figure 4-8. Figure 4-8. Optimizing network efficiency by pushing replication towards destination nodes. A network implementation of mirroring minimizes the number of copies in the network, thereby maximizing network efficiency. The overall goal focuses on optimizing the host to network to target connections. In the case of the cost per port, a server-based HBA or subsystem-based controller port is typically far more expensive than a network port. Reducing the load on an HBA or controller implies less need for additional end-node ports that can be more economically substituted with network ports. Simplifying the model, Figure 4-9 shows how both host-based and target-based mirroring applications require twice the amount of HBA or controller traffic, leading to the use of additional network segments to complete the operation. A network-based RAID 1 implementation, however, is optimized to push the replication to the midpoint between the receiving end nodes, thereby minimizing the overall network traffic. While the difference in this model may appear negligible, consider a storage network with dozens of switches and hundreds of end nodes. The ability to migrate mirroring functionality to the optimal midpoint between receiving end nodes can have a dramatic effect on network efficiency. Figure 4-9. Simplifying network usage models with network-based storage services. 4.3.2 Managing Attribute-Based StorageIn complex, heterogeneous storage environments, customers increasingly want to manage storage based on storage attributes. Rather than identifying a storage device based on its manufacturer and model number, the attributes more relevant from a management perspective include type of storage, protection level, access paths, and recovery capability. This approach to storage management becomes a reality when those attributes are managed within the network, as the network has the best mechanisms to deliver storage attributes to management packages. These mechanisms include the following:
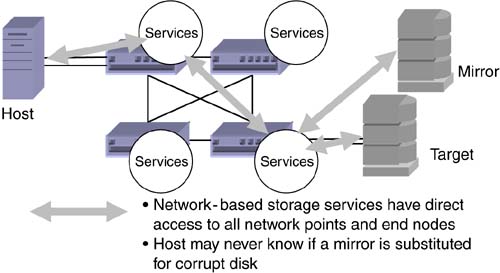
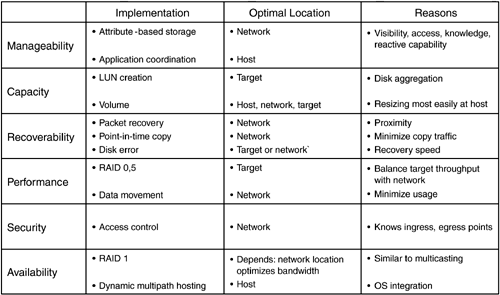
Take the example of a storage target that isn't responding to a host request. Without network-based storage services, the host has no knowledge of why the target didn't respond. It doesn't know if the link went down, or the disk was corrupt, or if something else happened within the network. The recovery action can be timely and expensive waiting for an HBA to time out before responding with an error to the application. That error might provide little knowledge of the condition besides "no response." With an intelligent storage network, the network knows how to identify the problem immediately. For example, it can separate disk errors from network errors, and coupled with intelligent services such as RAID 1, it could substitute a mirrored disk for a corrupt disk without the application's knowledge. Figure 4-10 shows how distributed network services provide "one-hop" access to all nodes in the configuration. Figure 4-10. Network-based services provide full access to storage attributes. 4.3.3 Locations for Additional Storage ServicesThe emergence of sophisticated networking devices for storage provides a new platform for storage services. Some services, such as dynamic multipath hosting and application coordination, will likely remain as host-based for the foreseeable future. Others, such as LUN creation through disk aggregation and RAID 0/5 will likely remain target-based due to CPU requirements and network optimization. But the majority of storage services can be well served via distributed network locations. Figure 4-11 outlines the categories of storage services, implementations, optimal locations, and reasons. Figure 4-11. Optimal locations for storage services. The gravitational pull of storage services into the network is taking place for a number of reasons. In many cases, the increasing size of storage network configurations makes the network location an optimal delivery point. Additionally, new market entrants can offer the same functionality as host-based and target-based implementations at a fraction of the cost. As industry margins continue to shift towards value-added software, we are likely to witness a free-for-all across host, fabric, and target implementations to capture a larger portion of the overall storage services spectrum. With vendors chasing after the same IT storage budget, each will need to capture as much of the pie as possible. |
EAN: 2147483647
Pages: 108