5.4 Multi-instance transaction behavior
|
| < Day Day Up > |
|
An instance reads a block from disk when either a user session or a process from another instance based on a similar user request places a request on it. While every single instance could access the block directly from disk (as in the previous version of Oracle), such an access directly from disk could be expensive, especially when another instance is already holding a copy of the block in its buffer and the instance that requires it could get a copy of the block via the cluster interconnect. This operation is as simple as transferring the block via the cluster interconnect to the requesting instance. However, there are other factors involved during this process, for example the block held by the original holder may have been modified and the copy may not have been placed on disk. It could very well be that the instance is holding only a copy of the block, while the original holder is another instance, which means the block has already undergone considerable changes. One of the instances requesting the block could be intending to delete all the rows from the block, while yet another instance is intending to make updates to the block.
How are these changes by multiple instances coordinated? How does Oracle ensure that these blocks are modified and kept track of?
Most of these scenarios are similar to that experienced in a single instance configuration, where Oracle is required to provide read con sistency, ensuring that multiple sessions do not see the in-flight transactions or rows that are being modified and have not been saved, etc. However, as discussed earlier, the data movement across the cluster interconnect that we have discussed is at a block level, while the transactions and modifications at the instance level are on a row-by-row basis.
The interesting thing in this situation is that while block level data is held at the instance in a RAC configuration, only a single row from the block behaves like in a regular single instance configuration.
Before we dive into these interesting discussions, let us once again discuss some basic concepts that are part of communication and messaging mechanisms used in a RAC environment.
5.4.1 Cache fusion
Cache fusion is the new term provided to the new architecture adopted by Oracle for movement or sharing of blocks between instances across the cluster interconnect. To perform a similar activity under OPS, Oracle had to write the block to disk and the requesting instance would read it off the disk. This writing and reading from disk was a performance bottleneck, which has been removed under this release through cache fusion technology.
Under the cache fusion architecture, since all of the data transfers happen via the cluster interconnect, it should be based on fast interconnect technologies with a low latency. For example, high-speed Ethernet, GigaNet, etc., are examples of high-speed cluster interconnect. Based on the amount of transactional activity, if a high-speed interconnect is not supported by the hardware, the expected performance benefits from a RAC implementation will not be obtained.
Cache fusion is handled globally by GCS. It is GCS that controls the sharing of blocks between instances and ensures that the proper previous image of the block is maintained. GCS and GES together maintain the GRD to store information pertaining to the current status of all shared resources. The GRD is used by GCS and GES to manage the global resource activity; it resides in memory and is distributed throughout the cluster to all nodes. Each node participates in managing global resources and manages a portion of the GRD.
GRD takes the place of the lock database used in OPS. However, unlike the lock database, the information contained in the GRD is also used by Oracle, during recovery from an instance failure and cluster reconfigurations.
To cover all possible scenarios of cache fusion and sharing of blocks amongst the instances, the following areas of discussion should provide a complete understanding of this new technology:
-
Read/read behavior
-
Read/write behavior
-
Write/write behavior
While these are just the high-level behaviors, there are quite a few possibilities under each of the above high-level behaviors that will be discussed.
Read/read behavior
Under this behavior there are basically two possibilities:
-
The instance that first requested the block is the only instance holding the block for read purposes.
-
The first instance is holding the block for read purposes; however, other instances also require access to the same block for read-only purposes.
In the first situation there is absolutely no sharing of resources or block information because everything is owned and operated by one instance.
Read/read behavior with no transfer
Figure 5.5 illustrates the steps involved when an instance acquires the block from disk and no other instance currently holds a copy of the same block. In the first situation, instance PRD3 requests for a shared resource on the block for read-only purposes.
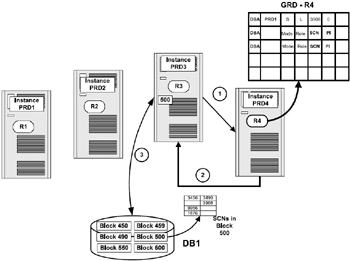
Figure 5.5: Read/read behavior with no transfer.
For the purpose of this discussion let us assume that this is the first instance that requested and acquired this block from disk and this block is not currently present in the shared areas of any other instances(PRD1, PRD2, PRD4). The following steps are undertaken by PRD3 to acquire the block from disk:
-
A user session or process makes a request for a specific row of data to GCS. The request is directed to instance PRD4 where the GRD for the data file is maintained. Assuming PRD4 is the resource master for the data file being processed. Oracle allocates a node to be the resource master based on the number of sessions accessing this file on that node. If the file access increases on another node, that node becomes the resource master. The designated master keeps shifting around depending on the node where it is required the most.
-
GCS grants the resource in shared mode with a local role. It makes an entry in the GRD on instance PRD4 and informs PRD3 of the grant. PRD3 converts the NULL status on the resource to shared mode with a local role.
-
Instance PRD3 initiates the I/O request to read the row from disk. Let us assume that this row is contained in block 500. The row that is requested is contained in block 500, which has an SCN 9956. Since Oracle reads a block of data at a time, other rows with different SCNs are also retrieved as part of this read operation. On completion of the I/O operation the block is read into the buffer of instance PRD3. Instance PRD3 now holds the block with SCN 9956 using a shared local with no PI resource status.
Read/read behavior with transfer
Let us continue with the previous example/illustration. The user queried the disk to retrieve a row contained in block 500 via instance PRD3. The block is held in local shared mode, i.e., no other instance has a copy of the block, hence its role is local. Now let us take this illustration further; another user requires access to another row that is part of the same data block 500. This request is made by a user connected to instance PRD2.
Instance PRD2 requests a resource on the block in order to complete the user's query request. In the previous example the block was retrieved by instance PRD3 and is the current holder of the block.
Figure 5.6 illustrates the steps involved when an instance PRD2 requires a block that is currently held by instance PRD3. (To maintain clarity of the figure, steps 1–3 are not repeated. Readers are advised to see Figure 5.5 in conjunction with Figure 5.6.)
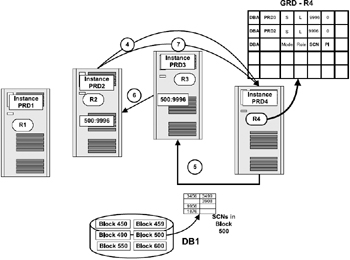
Figure 5.6: Read/read behavior with transfer.
-
Instance PRD2 sends a request for a read resource to the GCS. As discussed in steps 1 and 2 earlier, since we are communicating with the same data file, the GRD for this resource is maintained on instance PRD4. So as expected, PRD2 makes a request to PRD4 where the resource is mastered.
-
Instance PRD4 checks against its GRD regarding the whereabouts of this block and determines that the block is currently held with instance PRD3. GCS in its ultimate wisdom as the global cache manager sends a request to instance PRD3 requesting it to transfer the block for shared access to instance PRD2.
-
Instance PRD3 ships a copy of the block to the requesting instance PRD2. During this copy operation, PRD3 indicates in the header of the message that is sent over the interconnect that instance PRD3 is only sharing the block (which means it is going to retain a copy of the block). It also informs PRD2 that it is supposed to maintain the block at the same resource level.
Oracle 9i New Feature: Under OPS, instance PRD2 would have sent a request for the shared block to the DLM. The DLM would then issue a shared lock for the block and instance PRD2 would then read the block from disk. This entire expensive disk-reading activity is removed with the cache fusion operation.
-
Instance PRD2 receives the block along with the shared resource level transferred via the message header from instance PRD3. To complete the communication cycle, instance PRD2 sends a message to the GCS that it has received a copy of the block. The GCS now updates the GRD that is maintained on instance PRD4 that instance PRD2 is also another holder of the block.
The above discussion is making an optimistic assumption, namely that everything is available as expected, and all instances have what they are expected to have. Now what if this is not the case and instance PRD3 did not have the block? In such a situation, instance PRD3 would continue with the instruction received from the GCS. However, in this copy process, instance PRD3 would send the message that it no longer has a copy of the block and instance PRD2 is free to get the block from disk. On receipt of this message, instance PRD2 will, after confirming/informing the GCS, retrieve the information directly from disk.
What happens if there is a third node or for that matter a fourth, fifth, or sixth node that is requesting access to this read block? In all these situations the behavior and order of operation is exactly the same. In Figure 5.6, instance PRD3 will copy the block to the respective requesting instances and Oracle controls these copies by maintaining the information in the GRD, in this case on instance PRD4.
Read/write behavior
Let us continue with our previous scenario; a block that was read by instance PRD3 and now copied to instance PRD2 is being requested by instance PRD1 for a write operation. A write operation on a block would require that the instance PRD1 have an exclusive lock on this block to perform this operation. However, since there are other instances currently holding a copy of this block, instance PRD1 could only obtain an exclusive global level lock and not a local lock. Let us go through the steps involved in this process before instance PRD1 gets hold of the block:
-
Instance PRD1 sends a request for an exclusive resource on the block to the GCS on the mastering instance PRD4.
-
GCS after referring to the GRD on instance PRD4 ascertains that the block is being held by two instances, PRD3 and PRD2. GCS sends a message to all (instance PRD2 in our example) but one instance (PRD3) requesting transfer of the block to a NULL location. Transferring the block to a NULL location or status changes the resource from shared mode to local mode. This effectively tells the instances to release the buffers holding the block. Once this is done, the only remaining instance holding the block in a shared mode would be instance PRD3.
-
GCS requests instance PRD3 to transfer the block for exclusive access to instance PRD1.
Figure 5.7 illustrates the steps involved when instance PRD1 requires a copy of the block that is currently held by instance PRD2 and instance PRD3 for a write operation.
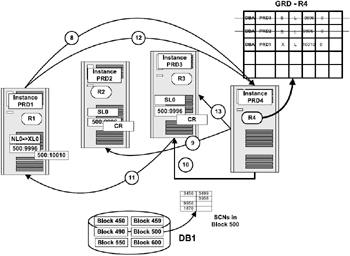
Figure 5.7: Read/write behavior. -
Instance PRD3, based on the request received from the GCS, will:
-
Send the block to instance PRD1 along with an indicator that it is closing its own resource and giving an exclusive resource for use by instance PRD1.
-
After the message has been sent to instance PRD1, it closes its own resource, marking the buffer holding the block image as copy for consistent read (CR) identifying itself that the buffer area is available for reuse.
-
-
Instance PRD1 converts its resource and sends a message to the GCS indicating/confirming the assumption that it has an exclusive resource on the block. Along with its regular message it also transfers the message received from instance PRD3 indicating that it has closed its own resource on this block. GCS now updates the GRD regarding the status of the block and instance PRD1 can now modify the block. Please note that at this point, the copies of blocks on other instances would also be removed from the GRD.
As indicated in Figure 5.7, instance PRD1 has now modified the block, and the SCN after this change becomes 10010.
-
The GCS confirms with instance PRD3 that it has received notification regarding status of the block in its buffer.
| Oracle 9i | New Feature: Under OPS, the read request for instance PRD1 would have been granted by the DLM issuing the exclusive PCM lock to instance PRD1 after forcing instance PRD3 to release the shared lock. However, since the only method to transfer the block to instance PRD1 is to have instance PRD1 read the block from disk, the copy in instance PRD3 would not be used by instance PRD1. |
Write/write behavior
We have looked at read/read and read/write behaviors. These behaviors of cache fusion were introduced in Oracle 8i. Now in Oracle 9i the write/ write operation is added.
Previous discussions centered around shareable scenarios like mul tiple instances having read copies of the same block. Now let us look at how cache fusion operates when multiple instances require write access to the same block. Please note from our previous scenario in Figure 5.7 that the block has been modified by instance PRD1 (new SCN value is 10010); the SCN for the block on disk remains the same at 9996.
In a continuous operation, where there are multiple requests made between instances for different blocks, the GCS is busy with the specific resource documenting all the block activities amongst the various instances. The GCS activity is sequential in the sense that unless it has recorded the information pertaining to previous requests, it does not accept or work on another request. If such a situation occurs, the new request is queued and has to wait for its turn.
GCS activity could be monitored by querying the data dictionary view V$SYSSTAT. For example,
SELECT NAME, VALUE FROM V$SYSSTAT WHERE NAME LIKE '%global cache%'
will give a list of tasks that GCS is currently performing.
Figure 5.8 illustrates the steps involved when an instance has acquired a block for write activity and another instance also requires access to the same block for a similar write operation.
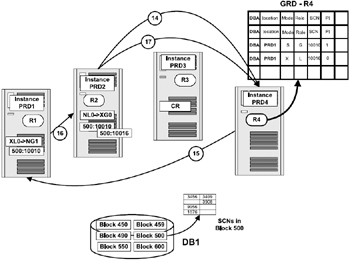
Figure 5.8: Write/write behavior.
-
Instance PRD2, which originally had a read copy of the block, and based on the write request from instance PRD1, received instructions from the GCS to clear the block buffer (marked as CR). Instance PRD2 makes a request to the GCS for an exclusive resource on the block.
-
Assuming that the GCS has completed all previous activities pertaining to other requests, the GCS makes a request to instance PRD1 (the current holder of the block) to give exclusive resource on the block and to transfer the current image of the block to instance PRD2.
-
Instance PRD1 transfers the block over to the requesting instance (PRD2) after ensuring that all activities against this block have been completed. This involves:
-
Logging any changes to the block and forcing a log flush if this has not already occurred.
-
Converting its resource to NULL with PI status of 1, indicating that the buffer now contains a PI copy of the block.
-
Sending an exclusive-keep copy of the block buffer to instance PRD2. This indicates the block image is at SCN 10010, information that the instance PRD1 is holding a PI of the block, and notification that the exclusive resource is available in global mode.
-
| Note | If instance PRD1 had made no changes to the block's content when the message was received, it would send the block image to instance PRD2 and release its resources. |
GCS resource conversions and cache fusion block transfers occur completely outside transaction boundaries. That is, an instance does not have to wait for a pending transaction to be completed before releasing an exclusive block resource.
-
After receipt of the message from instance PRD1, instance PRD2 will send a resource assumption message to the GCS. This message informs the GCS that instance PRD2 now has the resource with an exclusive global status and that the previous holder instance PRD1 now holds a PI version of the block SCN 10010. The GCS will update the GRD with the latest status of the block.
Once the GCS has been informed of the status, instance PRD2 can modify the block. The new SCN for the block is 10016.
Instance PRD1 no longer has an exclusive resource on this block and hence cannot make any modifications to the block.
| Note | Despite multiple changes to the block made by the various instances, it should be noted that the block's SCN on disk still remains at 9996. |
Write/read behavior
We have looked at read/write behavior before; what would be the difference in the opposite situation? That is, when a block is held by an instance after modification and another instance requires the latest copy of the block for a read operation. Unlike the previous read/write scenario, the block has undergone considerable modification and the SCN held by the current holder of the block is different from what is on disk. In a single stand-alone configuration, a query looks for a read consistent image of the row, and clustered configuration is no different; Oracle has to provide a consistent read version of the block. In this example the latest copy of the block is held by instance PRD2 (based on our previous scenario as illustrated in Figure 5.8).
Figure 5.9 illustrates the steps involved when instance PRD3 requires a block for read purposes. From our previous scenario, it is understood that the latest version of the block is currently held by instance PRD2 in exclusive mode.
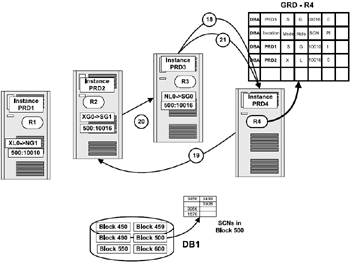
Figure 5.9: Write/read behavior.
-
Instance PRD3 once had a read copy of the block; however, based on a request from the GCS it had converted it into a NULL resource. Based on a new query request from a user, it now once again requires a read access to the block. To satisfy this request, instance PRD3 makes a request to GCS for the necessary shared resource.
-
Instance PRD2 is the current holder of the latest copy of the block. To satisfy the request from instance PRD3, the GCS requests instance PRD2 to transfer a shared resource. As discussed before, if there are no resource transactions in progress, this request is immediately processed, or else it is placed in queue and has to wait for its turn.
-
Instance PRD2, on receipt of the message request, completes all required work on the block and sends a copy of the block image to instance PRD3. The block is to be transferred in a shared status with no exclusive rights, hence instance PRD2 has to downgrade its resources to shared mode before transferring the block across to instance PRD3. While the transfer happens, instance PRD2 retains the block's PI.
Instance PRD1 and instance PRD2 have a PI of their respective blocks with different SCNs.
-
Instance PRD3 now acknowledges receipt of the requested block, informs the GCS the current status of the block. This includes the SCN of the PI currently retained by instance PRD2. The GCS makes the required updates to the GRD. I
nstance PRD3 now has the most recent copy of the block and is now in a global mode.
Write to disk behavior
It is time to discuss what happens when a block needs to be written to disk. Before we step into the mechanics of this, let us recap the current state of the environment:
-
Instance PRD4 continues to be the master of the resource and holds the GRD for the block.
-
Instance PRD1 had once modified the block and currently holds block SCN 10010, with a global null resource and a PI of the block.
-
Instance PRD2 also contains a modified copy of the block with a block SCN 10016. The current status of the block held by instance PRD2 is in exclusive resource mode. This instance also holds a PI copy of the block.
-
Instance PRD3 holds the latest consistent read image version of the block (in shared global mode) received from instance PRD2, which means it is a copy of a block held by instance PRD2.
-
The disk, as we have discussed many times, contains the original block SCN 9996.
What could force or stimulate the write activity in a RAC environment? Transactional behavior in a RAC environment is no different when compared to a single instance configuration. All normal rules of single instance, ''flushing dirty blocks to disk'' apply in this situation also. For example, as discussed in Chapter 3 (Oracle Database Concepts), writing to disk could happen under the following circumstances:
-
The number of dirty buffers reaches a threshold value: This value is reached when there is not sufficient room in the database buffer cache for more data. In this situation, Oracle writes the dirty buffers to disk, freeing up space for new data.
-
A process is unable to find free buffers in the database buffer cache while scanning for blocks: When a process reads data from the disk and does not find any free space in the buffer, this triggers the least recently used data in the buffer cache to be pushed down the stack and finally written to disk.
-
A timeout occurs: The timeout is configured by setting the required timeout interval (LOG_CHECKPOINT_TIMEOUT) through a parameter defined in the parameter file. On every preset interval, the timeout is triggered to cause the DBWR to write the dirty buffers to disk. This mechanism is used by Oracle for transaction recoverability in case of failure. In an ideal system, where the data is occasionally modified but not written to disk (due to not having sufficient activity that would cause other mechanisms to trigger the write operation), the timeout is helpful.
-
The checkpoint process: During a predefined interval defined by LOG_CHECKPOINT_INTERVAL parameter, when the CKPT process is triggered, it causes the DBWR and LGWR processes to write the data from their respective buffer cache to disk. However, in a RAC environment, any of the participating instances could trigger this write activity.
Figure 5.10 illustrates the various steps involved during a write to disk activity. In the current scenario instances PRD1 and PRD2 both have a modified version of the blocks.
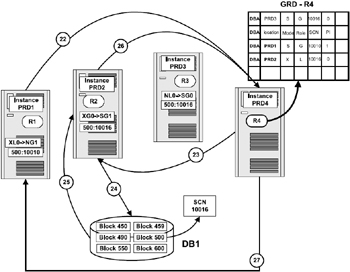
Figure 5.10: Write to disk behavior.
Let us make the assumption in our scenario that instance PRD1, due to a checkpoint activity during a redo log switch, determines that it needs to write the block information to disk. The following are the steps taken to accomplish this activity:
-
Instance PRD1 sends a write request to the GCS with the necessary SCN. The GCS, after determining from the GRD the list of instances that currently contains PI copies, marks them as requiring modification.
-
The GCS initiates the write operation by requesting instance PRD2, which holds the latest modified block SCN, to perform this operation. During this process, while a write operation is outstanding, the GCS will not allow another write to be initiated until the current operation is completed.
Note The GCS in its ultimate wisdom as the controller of resources determines which instance will actually perform the write operation. In our scenario, in spite of the fact that instance PRD1 made the request, PRD2 is holding the latest block SCN. The GCS could pick either of the instances to perform the write operation.
-
Instance PRD2 initiates the I/O with a write to disk.
-
Once the I/O operation is complete, a notification message is sent back to instance PRD2. On completion of the write operation, instance PRD2 logs the fact that such an operation has completed and the version is written with a BWR. This activity advances the checkpoint, which in turn forces a log write.
-
Instance PRD2 informs the GCS of the successful completion of the write operation. This notification also informs the GCS of the current resource status of the block, that the resource is going to a local role because the DBWR has written the current image to disk.
-
On receipt of the write notification, the GCS sends to each instance holding a PI an instruction to flush the PI. After completion of this process or if no PI remains, the instance holding the current exclusive resource is told to switch to the local role. In the scenarios discussed above, PRD1 and PRD2 are the two instances holding a PI. When instance PRD2 receives a flush request from the GCS, it logs a BWR that the block has been written, without flushing the log buffer. Once this completes, instance PRD2 will hold the block with an exclusive local resource with no PIs and all other PIs to this block held across various instances are purged.
After the dirty block has been written to disk, any subsequent operation will follow similar steps to complete any requests from users. For example, if an instance requires read access to a block after the block has been written to disk, the instance would check with the GCS and, based on the instruction received from the GCS, would either retrieve the block SCN from disk or retrieve it from another instance that currently has a copy of the block.
The write/write behavior and write to disk behavior are possible behaviors during a DML operation. Similarly, the behavior of the RAC resources will be identical whether it is a single, double or a four-instance configuration.
In all the scenarios it should be noted that, unless absolutely necessary, no write activity to the disk happens. Every activity or state of the block is maintained as a resource in the instance where it was utilized last and reused umpteen number of times from this location.
Now the obvious question that should come to mind is, what happens to all these blocks in memory when a system crashes or a node failure happens? This is a fair question. While we have discussed, in brief, cache fusion recovery, we will discuss this recovery part of the cache fusion technology in more detail in Chapter 12 (Backup and Recovery) later in this book.
| Oracle 9i | New Feature: One new feature introduced in Oracle 9i is the ability to resume a transaction or a database operation in case of a failure. The feature is called resumable space allocation. This functionality allows the database administrators to make the necessary adjustment or correction to the problem and continue the operation from the point where it failed. |
Oracle can manage the transactions across instances efficiently only if the statements contained or participating in the transactions are written efficiently. Efficiency of a statement depends on various factors, like efficient SQL statements, tuned SQL statements, structured formats, etc.
Why are these important? As part of getting an understanding of transaction management, it would be beneficial to understand what happens inside an instance once a user executes a statement. This insight will provide a need to write efficient SQL, providing performance benefits and effective transaction management by Oracle. The most important part of any transaction is the parsing of the statement within Oracle.
5.4.2 Oracle's parse operation
The best approach to understanding the parse operation is to understand its internal operation. Figure 5.11 explains the internals of the parse operation, illustrating the various stages or steps taken, beginning with the time that the cursor is opened by the processes. A similar parse operation (not illustrated) is followed, when a PL/SQL procedure and the SQL statements are embedded inside the PL/SQL code. The steps taken by a DML statement, beginning with the point that a query is executed and opened, to the point that it is completed and the results returned, could be broadly grouped into the following nine steps. It should be noted that only the DML statements are required to perform all these steps. DDL statements like create, alter, and drop operations are performed in two steps, namely create and parse.
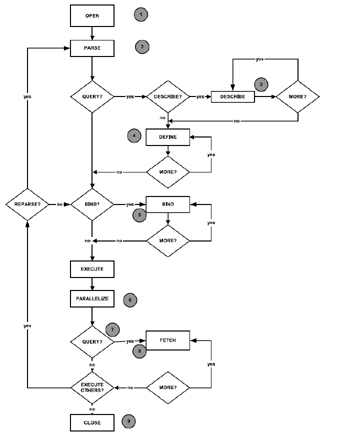
Figure 5.11: Parse operation flow diagram.
Step 1: Create a cursor
A cursor can be considered as an association between the data area in a client program and the Oracle server's data structures. When a program is required to process an SQL statement, it is required to open a cursor. The cursor contains a pointer to the current row, and, as the rows get fetched, the pointer moves to the next row until all the rows specified by the condition in the statement have been processed. While the cursor contains the statement, it operates independently of the statement. The cursor is created by a program interface call (OCI) in expectation of an SQL statement. SQL statement processing in general is complex in nature. It has to iterate through various areas of the memory and disk before the results are collected and returned to the user. The various physical components that the SQL statement has to iterate through are:
-
Client-side runtime memory
-
Server-side runtime memory
-
Server-side private SQL area
-
Server-side shared SQL area, or the library cache
Step 2: Parse the statement
This is the most complicated and expensive phase of the operation. During this phase the statement is passed from the user's process to Oracle and is loaded into the shared SQL area. Before loading into this area, the following steps have to be completed: the SQL statement is translated and verified, the table and columns checks are performed, and Oracle places a parse lock to prevent definitions from changing. While verifying the definitions, Oracle also checks the user privileges against the referenced objects. Oracle generates the query plan to determine the optimal execution path, followed by loading of the statement into the shared SQL area.
During this phase of operation, Oracle has to determine if the statement being executed is not identical to a previously executed statement. Based on the findings, Oracle will determine whether to use the previous parse information from a previous execution or if the statement has to be parsed before being executed. This is the advantage of the library cache feature. The library cache feature was introduced in Version 7.0 of Oracle, which brought about the concept of sharing SQL statements.
There are two types of parses, soft parse and hard parse. Based on the repeated usage of the statement and Oracle finding the parse information in the library cache, it determines if this is a hard parse or a soft parse.
Hard parse When a statement is executed for the first time and Oracle is not able to find any information pertaining to this statement in the library cache, Oracle has to do a complete parse operation, which is also referred to as the hard parse. During this initial operation Oracle has to perform these several steps:
-
Syntax checks on the statement
-
Semantic checks on the statement
-
Data dictionary validation for the objects and columns
-
Name translation of the objects (with reference to synonyms)
-
User privileges for the objects referenced in the SQL statement
-
Generation of an execution plan, with the help of the optimizer
-
Loading of the statement into the library cache
Even after all of these steps have been completed and the statement has been loaded into the library cache/shareable area, it actually may not be in a shareable state. This is because Oracle has to place a lock on the cursor/ statement header (cursors created by Oracle have two parts; the cursor header and the cursor body). The lock is placed on the header when the cursor is initially opened, and released when the cursor is closed. Once the cursor is closed, the cursor obtains the shareable state (i.e., other sessions could see this statement in the library cache).
Before storing the statement in the library cache, Oracle computes a hash value and stores it on the hash table. This hash value is compared against a similar query from another user. It should be noted that Oracle, as a first attempt to process an SQL statement, generates a hash value and compares that with the ones in the library cache to determine if any matches exist before the parse operation.
While normally there is only one copy of the header that could be found in the library cache, there could be many copies of the cursor body existing in the library cache. The reason for duplicate cursors, or many cursor bodies for the same cursor header, is due to variations on the SQL statements. Variations in spacing, formatting, non-consistent usage of case, etc., could cause variations, because from Oracle's perspective when it performs a comparison it is going to compare character for character.
After the initial header and body creation, subsequent bodies are created for the same header under the following conditions:
-
The threshold of the bind variables changes because the string length of the contents of the bind variable has changed.
-
For example, if the books table is initially checked with ''Oracle,'' and the next query checked the books table with ''Oracle 9i Real Application Clusters New features and Administration,'' Oracle notices that the length of the bind value has changed and cannot reuse the existing cursor body, therefore it creates another one. The initial space allocation for a bind value is 50 bytes; anything over that requires a new body.
-
SQL statements using literals instead of bind variables.
To overcome the difficulties faced by most applications that use literals, Oracle has introduced a new parameter called CURSOR_SHARING = FORCE. This parameter creates bind variables for all literals, thus forcing cursor sharing.
Soft parse Before parsing the SQL statement, Oracle ensures generation of a hash value and compares the hash value with the statements already in the library cache. To ensure that nothing has changed between the previous execution and now, when the match is found, Oracle may have to do a simpler parse, depending on certain conditions. This parse is a soft parse and could be one of these kinds:
-
If the user is accessing the SQL statement for the first time and finds it in memory, Oracle has to ensure that the statement is exactly the same as the one that the user has requested and to ensure that the user has authentication to use the objects referenced in the SQL statement.
-
If the user is accessing the SQL statement for the second time and finds it in the library cache, Oracle still has to validate to ensure that the grants for the objects referenced in the SQL statement have not changed.
The parse operation consumes memory and CPU cycles to complete the query, but reduces the response time considerably.
Step 3: Describe the results
In this step of the process, DESCRIBE provides information about the select list items. This step is more relevant when using dynamic queries using an OCI application.
Step 4: Define query output
While the statement is executed and data is retrieved, appropriate memory variables are required to hold the output information. This step takes care of defining this memory area for the variables.
Step 5: Bind variables
If bind variables are used, Oracle is required to bind them. This gives the Oracle server the address where bind values will be stored in memory. Usage of bind variables is another important factor for efficient usage of memory and the overall performance of the system. Bind variables help in repeated execution of the same statement. Usage of literals (alternative to bind variables) causes statements to be unique and does not allow sharing of SQL statements. The non-shared statements consume memory and cause excessive parse operation.
Step 6: Parallelize the statement
This step is performed only when parallelism is required and configured. When parallelism is chosen, the work of a query is divided among a number of slave processors. If this is required for parsing or if the query is eligible for parallel execution, it is determined during the parse step and the appropriate execution plan has to be defined. The plan is executed during this step of the process.
Step 7: Execute the statement
This step executes the SQL statement and retrieves rows from disk or memory and places the values into the bind variables. This ensures the completion of the statement to produce the desired results.
Step 8: Fetch rows for a query
From the bind variables defined in step 5, the values that are obtained as a result of the statement execution and the placement of values in the bind variables are moved into the output variables of the process. These results are returned in a table format to the calling interface.
Step 9: Close the cursor
Once the data is returned to the calling interface, the cursor is closed.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 174