The Monte Carlo Process
| One characteristic of some systems that makes them difficult to solve analytically is that they consist of random variables represented by probability distributions. Thus, a large proportion of the applications of simulations are for probabilistic models. The term Monte Carlo has become synonymous with probabilistic simulation in recent years . However, the Monte Carlo technique can be more narrowly defined as a technique for selecting numbers randomly from a probability distribution (i.e., "sampling") for use in a trial (computer) run of a simulation. The Monte Carlo technique is not a type of simulation model but rather a mathematical process used within a simulation. Monte Carlo is a technique for selecting numbers randomly from a probability distribution . The name Monte Carlo is appropriate because the basic principle behind the process is the same as in the operation of a gambling casino in Monaco. In Monaco such devices as roulette wheels, dice, and playing cards are used. These devices produce numbered results at random from well-defined populations. For example, a 7 resulting from thrown dice is a random value from a population of 11 possible numbers (i.e., 2 through 12). This same process is employed, in principle, in the Monte Carlo process used in simulation models. The Monte Carlo process is analogous to gambling devices . The Use of Random NumbersThe Monte Carlo process of selecting random numbers according to a probability distribution will be demonstrated using the following example. The manager of Computer-World, a store that sells computers and related equipment, is attempting to determine how many laptop PCs the store should order each week. A primary consideration in this decision is the average number of laptop computers that the store will sell each week and the average weekly revenue generated from the sale of laptop PCs. A laptop sells for $4,300. The number of laptops demanded each week is a random variable (which we will define as x ) that ranges from 0 to 4. From past sales records, the manager has determined the frequency of demand for laptop PCs for the past 100 weeks. From this frequency distribution, a probability distribution of demand can be developed, as shown in Table 14.1. Table 14.1. Probability distribution of demand for laptop PCs
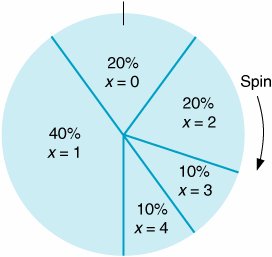
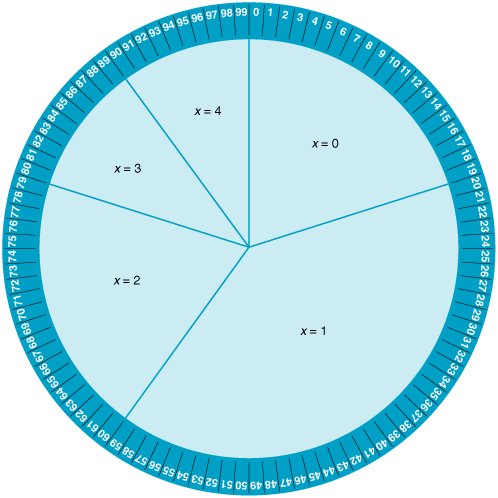
The purpose of the Monte Carlo process is to generate the random variable, demand, by sampling from the probability distribution, P ( x ). The demand per week can be randomly generated according to the probability distribution by spinning a wheel that is partitioned into segments corresponding to the probabilities, as shown in Figure 14.1. Figure 14.1. A roulette wheel for demand In the Monte Carlo process, values for a random variable are generated by sampling from a probability distribution . Because the surface area on the roulette wheel is partitioned according to the probability of each weekly demand value, the wheel replicates the probability distribution for demand if the values of demand occur in a random manner. To simulate demand for 1 week, the manager spins the wheel; the segment at which the wheel stops indicates demand for 1 week. Over a period of weeks (i.e., many spins of the wheel), the frequency with which demand values occur will approximate the probability distribution, P ( x ). This method of generating values of a variable, x , by randomly selecting from the probability distributionthe wheelis the Monte Carlo process. By spinning the wheel, the manager artificially reconstructs the purchase of PCs during a week. In this reconstruction, a long period of real time (i.e., a number of weeks) is represented by a short period of simulated time (i.e., several spins of the wheel). A long period of real time is represented by a short period of simulated time . Now let us slightly reconstruct the roulette wheel. In addition to partitioning the wheel into segments corresponding to the probability of demand, we will put numbers along the outer rim, as on a real roulette wheel. This reconstructed roulette wheel is shown in Figure 14.2. Figure 14.2. Numbered roulette wheel(This item is displayed on page 614 in the print version) There are 100 numbers from 0 to 99 on the outer rim of the wheel, and they have been partitioned according to the probability of each demand value. For example, 20 numbers from 0 to 19 (i.e., 20% of the total 100 numbers) correspond to a demand of no (0) PCs. Now we can determine the value of demand by seeing which number the wheel stops at as well as by looking at the segment of the wheel. When the manager spins this new wheel, the actual demand for PCs will be determined by a number. For example, if the number 71 comes up on a spin, the demand is 2 PCs per week; the number 30 indicates a demand of 1. Because the manager does not know which number will come up prior to the spin and there is an equal chance of any of the 100 numbers occurring, the numbers occur at random; that is, they are random numbers . Obviously, it is not generally practical to generate weekly demand for PCs by spinning a wheel. Alternatively, the process of spinning a wheel can be replicated by using random numbers alone. First, we will transfer the ranges of random numbers for each demand value from the roulette wheel to a table, as in Table 14.2. Next, instead of spinning the wheel to get a random number, we will select a random number from Table 14.3, which is referred to as a random number table . (These random numbers have been generated by computer so that they are all equally likely to occur , just as if we had spun a wheel. The development of random numbers is discussed in more detail later in this chapter.) As an example, let us select the number 39, the first entry in Table 14.3. Looking again at Table 14.2, we can see that the random number 39 falls in the range 2059, which corresponds to a weekly demand of 1 laptop PC. Table 14.2. Generating demand from random numbers(This item is displayed on page 614 in the print version) Table 14.3. Random number table
Random numbers are equally likely to occur . By repeating this process of selecting random numbers from Table 14.3 (starting anywhere in the table and moving in any direction but not repeating the same sequence) and then determining weekly demand from the random number, we can simulate demand for a period of time. For example, Table 14.4 shows demand for a period of 15 consecutive weeks. Table 14.4. Randomly generated demand for 15 weeks
From Table 14.4 the manager can compute the estimated average weekly demand and revenue: The manager can then use this information to help determine the number of PCs to order each week. Although this example is convenient for illustrating how simulation works, the average demand could have more appropriately been calculated analytically using the formula for expected value. The expected value or average for weekly demand can be computed analytically from the probability distribution, P ( x ): where
Therefore,
Simulation results will not equal analytical results unless enough trials of the simulation have been conducted to reach steady state . The analytical result of 1.5 PCs is close to the simulated result of 2.07 PCs, but clearly there is some difference. The margin of difference (0.57 PCs) between the simulated value and the analytical value is a result of the number of periods over which the simulation was conducted. The results of any simulation study are subject to the number of times the simulation occurred (i.e., the number of trials ). Thus, the more periods for which the simulation is conducted, the more accurate the result. For example, if demand were simulated for 1,000 weeks, in all likelihood an average value exactly equal to the analytical value (1.5 laptop PCs per week) would result.
Once a simulation has been repeated enough times that it reaches an average result that remains constant, this result is analogous to the steady-state result, a concept we discussed previously in our presentation of queuing. For this example, 1.5 PCs is the long-run average or steady-state result, but we have seen that the simulation might have to be repeated more than 15 times (i.e., weeks) before this result is reached. Comparing our simulated result with the analytical (expected value) result for this example points out one of the problems that can occur with simulation. It is often difficult to validate the results of a simulation modelthat is, to make sure that the true steady-state average result has been reached. In this case we were able to compare the simulated result with the expected value (which is the true steady-state result), and we found there was a slight difference. We logically deduced that the 15 trials of the simulation were not sufficient to determine the steady-state average. However, simulation most often is employed whenever analytical analysis is not possible (this is one of the reasons that simulation is generally useful). In these cases, there is no analytical standard of comparison, and validation of the results becomes more difficult. We will discuss this problem of validation in more detail later in the chapter. It is often difficult to validate that the results of a simulation truly replicate reality . |

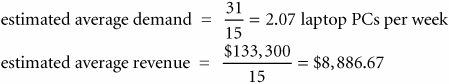
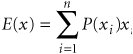
EAN: 2147483647
Pages: 358