Section 8.4. Resident Memory
8.4. Resident MemoryMach divides an address space into pages, with the page size usually being the same as the native hardware page size, although Mach's design allows a larger virtual page size to be built from multiple physically contiguous hardware pages. Whereas programmer-visible memory is byte addressable, Mach virtual memory primitives operate only on pages. In fact, Mach will internally page-align memory offsets and round up the size of a memory range to the nearest page boundary. Moreover, the kernel's enforcement of memory protection is at the page level.
It is possible that the native hardware supports multiple page sizesfor example, the PowerPC 970FX supports 4KB and 16MB page sizes. Mach can also support a virtual page size that is larger than the native hardware page size, in which case a larger virtual page will map to multiple contiguous physical pages. The kernel variable vm_page_shift contains the number of bits to shift right to convert a byte address into a page number. The library variable vm_page_size contains the page size being used by Mach. The hw.memsize sysctl variable also contains the page size. $ sudo ./readksym.sh _vm_page_shift 4 -d 0000000 00000 000128.4.1. The vm_page StructureThe valid portions of an address space correspond to valid virtual pages. Depending on a program's memory usage pattern and other factors, none, some, or even all of its virtual memory could be cached in physical memory through resident pages. A resident page structure (struct vm_page [osfmk/vm/vm_page.h]) corresponds to a page of physical memory and vice versa. It contains a pointer to the associated VM object and also records the offset into the object, along with information indicating whether the page is referenced, whether it has been modified, whether it is encrypted, and so on. Figure 810 shows an overview of how the vm_page structure is connected to other data structures. Note that the structure resides on several lists simultaneously. Figure 810. The structure of a resident page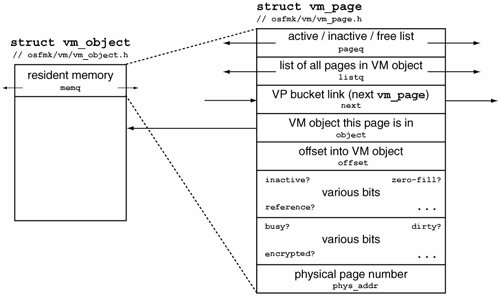 8.4.2. Searching for Resident PagesThe kernel maintains a hash table of resident pages, with the next field of a vm_page structure chaining the page in the table. The hash table, also called the virtual-to-physical (VP) table, is used for looking up a resident page given a { VM object, offset } pair. The following are some of the functions used to access and manipulate the VP table. vm_page_t vm_page_lookup(vm_object_t object, vm_object_offset_t offset); void vm_page_insert(vm_page_t mem, vm_object_t object, vm_object_offset_t offset); void vm_page_remove(vm_page_t mem); Object/offset pairs are distributed in the hash table using the following hash function (the atop_64() macro converts an address to a page): H = vm_page_bucket_hash; // basic bucket hash (calculated during bootstrap) M = vm_page_hash_mask; // mask for hash function (calculated during bootstrap) #define vm_page_hash(object, offset) \ (((natural_t)((uint32_t)object * H) + ((uint32_t)atop_64(offset) ^ H)) & M) Note that the lookup function uses a hint[10] recorded in the memq_hint field of the VM object. Before searching the hash table for the given object/offset pair, vm_page_lookup() [osfmk/vm/vm_resident.c] examines the resident page specified by the hint and, if necessary, also its next and previous pages. The kernel maintains counters that are incremented for each type of successful hint-based lookup. We can use the readksym.sh program to examine the values of these counters.
$ sudo readksym.sh _vm_page_lookup_hint 4 -d 0000000 00083 28675 ... $ sudo readksym.sh _vm_page_lookup_hint_next 4 -d 0000000 00337 03493 ... $ sudo readksym.sh _vm_page_lookup_hint_prev 4 -d 0000000 00020 48630 ... $ sudo readksym.sh _vm_page_lookup_hint_miss 4 -d 0000000 00041 04239 ... $ 8.4.3. Resident Page QueuesA pageable resident page[11] resides on one of the following three paging queues through the pageq field of the vm_page structure.
The top command can be used to display the amounts of memory currently distributed across the active, inactive, and free queues.
Recall that we noted in Section 8.3.5.1 that a VM object can be persistent, in which case its pages are not freed when all its references go away. Such pages are placed on the inactive list. This is particularly useful for memory-mapped files. 8.4.4. Page ReplacementSince physical memory is a limited resource, the kernel must continually decide which pages should remain resident, which should be made resident, and which should be evicted from physical memory. The kernel uses a page replacement policy called FIFO with Second Chance, which approximates LRU behavior.
A specific goal of page replacement is to maintain a balance between the active and inactive lists. The active list should ideally contain only the working sets of all programs. The kernel manages the three aforementioned page queues using a set of page-out parameters that specify paging thresholds and other constraints. Page queue management includes the following specific operations.
Since the active queue is a FIFO, the oldest pages are removed first. If an inactive page is referenced, it is moved back to the active queue. Thus, the pages on the inactive queue are eligible for a second chance of being referencedif a page is referenced frequently enough, it will be prevented from moving to the free queue and therefore will not be reclaimed. The so-called cleaning of dirty pages is performed by the page-out daemon, which consists of the following kernel threads:
The "internal" and "external" threads both use the vm_pageout_iothread_continue() [osfmk/vm/vm_pageout.c] continuation, but they use separate page-out (laundry) queues: vm_pageout_queue_internal and vm_pageout_queue_external, respectively. vm_pageout_iothread_continue() services the given laundry queue, calling memory_object_data_return()if necessaryto send data to the appropriate pager. vm_pageout_garbage_collect() frees excess kernel stacks and possibly triggers garbage collection in Mach's zone-based memory allocator module (see Section 8.16.3). The page-out daemon also controls the rate at which dirty pages are sent to the pagers. In particular, the constant VM_PAGE_LAUNDRY_MAX (16) limits the maximum page-outs outstanding for the default pager. When the laundry count (the current count of laundry pages in queue or in flight) exceeds this threshold, the page-out daemon pauses to let the default pager catch up. 8.4.5. Physical Memory Bookkeepingvm_page_grab() [osfmk/vm/vm_resident.c] is called to remove a page from the free list. If the number of free pages in the system (vm_page_free_count) is less than the number of reserved free pages (vm_page_free_reserved), this routine will not attempt to grab a page unless the current thread is a VM-privileged thread. $ sudo readksym.sh _vm_page_free_count 4 -d 0000000 00001 60255 ... $ sudo readksym.sh _vm_page_free_reserved 4 -d 0000000 00000 00098 ... As shown in Figure 811, vm_page_grab() also checks the current values of free and inactive counters to determine whether it should wake up the page-out daemon. Figure 811. Grabbing a page from the free list
Note in Figure 811 that vm_page_grab() also compares the current value of the free counter with vm_page_inactive_target. The latter specifies the minimum desired size of the inactive queueit must be large enough so that pages on it get a sufficient chance of being referenced. The page-out daemon keeps updating vm_page_inactive_target according to the following formula: vm_page_inactive_target = (vm_page_active_count + vm_page_inactive_count) * (1/3) Similarly, vm_page_free_target specifies the minimum desired number of free pages. The page-out daemon, once started, continues running until vm_page_free_count is at least this number. $ sudo readksym.sh _vm_page_inactive_target 4 -d 0000000 00003 44802 ... $ sudo readksym.sh _vm_page_active_count 4 -d 0000000 00001 60376 ... $ sudo readksym.sh _vm_page_inactive_count 4 -d 0000000 00009 04238 ... $ sudo readksym.sh _vm_page_free_target 4 -d 0000000 00000 09601 ... $ sudo readksym.sh _vm_page_free_count 4 -d 0000000 00000 11355 ... The vm_page_free_reserved global variable specifies the number of physical pages reserved for VM-privileged threads, which are marked by the TH_OPT_VMPRIV bit being set in the options field of the thread structure. Examples of such threads include the page-out daemon itself and the default pager. As shown in Figure 812, vm_page_free_reserve() allows the value of vm_page_free_reserved to be adjusted, which also results in vm_page_free_target being recomputed. For example, thread_wire_internal() [osfmk/kern/thread.c], which sets or clears the TH_OPT_VMPRIV option for a thread, calls vm_page_free_reserve() to increment or decrement the number of reserved pages. Figure 812. Reserving physical memory
8.4.6. Page FaultsA page fault is the result of a task attempting to access data residing in a page that needs the kernel's intervention before it can be used by the task. There can be several reasons for a page fault, such as those listed here.
The page-fault handler is implemented in osfmk/vm/vm_fault.c, with vm_fault() being the master entry point. Let us look at the sequence of steps involved in handling a typical page fault. As we saw in Table 51, a page fault or an erroneous data memory access on the PowerPC corresponds to a data access exception. To handle the exception, the kernel calls TRap() [osfmk/ppc/trap.c] with the interrupt code set to T_DATA_ACCESS. TRap() can handle this exception in several ways, depending on whether it occurred in the kernel or in user space, whether the kernel debugger is enabled, whether the faulting thread's tHRead structure contains a valid pointer to a "recover" function, and so on. In general, TRap() will call vm_fault() to resolve the page fault. vm_fault() first searches the given VM map for the given virtual address. If successful, it finds a VM object, the offset into the object, and the associated protection value. Next, it must be ensured that the page is resident. Either the page will be found in physical memory by looking up the virtual-to-physical hash table, or a new resident page will be allocated for the given object/offset pair and inserted into the hash table. In the latter case, the page must also be populated with data. If the VM object has a pager, the kernel will call memory_object_data_request() to request the pager to retrieve the data. Alternatively, if the VM object has a shadow, the kernel will traverse the shadow chain to look for the page. New pages corresponding to internal VM objects (anonymous memory) will be zero-filled. Moreover, if the VM object has an associated copy object and the page is being written, it will be pushed to the copy object if it hasn't already been. Eventually, the page fault handler will enter the page into the task's pmap by calling PMAP_ENTER() [osfmk/vm/pmap.h], which is a wrapper around pmap_enter(). Thereafter, the page is available to the task. |
EAN: 2147483647
Pages: 161