Collection Classes
Symbian OS does not support the Standard Template Library (STL) for a number of reasonsprimarily because of STL's large footprint. However, Symbian OS does provide a number of templated collection classes, so that developers do not need to write their own arrays, linked lists and so on.
This section will concentrate on dynamic arrays, as these are the most commonly used collection classes in Symbian OS. There are two basic types of array: CArray and RArray . CArray s are perhaps the most flexible in some respects, but while RArray s do impose some limitations, they are more efficient and often easier to use.
| | See the SDK documentation for a full discussion of other collection classes such as TSglQue ( singly -linked lists), tdblQue (doubly-linked lists), CCirBuf (circular buffers) and TBtree (balanced trees). Note, however, that these are rarely used as Symbian OS applicatons generally store only a ( fairly small) fixed amount of data and so have little need for complex data structures. Usually an array will do. |
RArray and RPointerArray Types
Since RArray s are easier to use than CArray s, they will be discussed first. An RArray is a simple array of fixed-length objects, while an RPointerArray is an array of pointers to objects. It is worth noting from the outset that RArray s impose a limitation of 640 bytes on the size of their elements. Usually this is not an issue, since most objects are likely to be smaller than this limit, and RPointerArray can be used to point to arbitrarily large objects anyway. Generally, therefore, owing to their greater efficiency, flexibility and ease of use, RArray s are recommended over CArray types.
Basic APIs
RArray s and RPointerArray s tend to be constructed on the stack or simply nested directly into other heap-based objects. They are templated, and therefore require a template argument in their declarations and constructors. In the case of an RArray , this template argument should be a simple type or an R -type or T -type object; for RPointerArray s it may be any type.
Note that as these arrays are R -classes, they must be closed before they go out of scope.
| | If you create a local (stored on the stack) RArray , then you need to use the Cleanup Stack to make sure that there are no memory leaks if a function leaves before the array is closed. Rather than the usual CleanupStack::PushL() , you need to use CleanupClosePushL(myArray) to push your array onto the stack. This will ensure that if a leave occurs, Close() will be called on your array, freeing up all of the memory allocated to the array. If you are using a local RPointerArray that owns the data it points to, then either this data must also be pushed onto the Cleanup Stack, or you should consider making the array a member of the class and calling RPointerArray::ResetAndDestroy() in its destructor. |
Here is the declaration of the RPointerArray used in the Elements example application:
class CElementRArray : public CElementList { ... private: RPointerArray<CChemicalElement> iElementArray; }; CElementList is an abstract base class that defines a common interface for manipulating a list of elements; regardless of what array type is used.
Since the array is nested within the CElementRArray class, and no other data is owned on the heap, there is no need for a second-phase constructor. The C++ constructor for the CElementRArray class is implemented like this:
CElementRArray::CElementRArray() : iElementArray(KElementListGranularity) { } This simply invokes the only non-default RPointerArray constructor, specifying the granularity of the arraythe number of elements that can be appended to the array before reallocation needs to occur (see the subsection on CArray Types for a fuller discussion of granularity).
Regardless of the granularity, all newly constructed dynamic arrays have no members . The easiest way to add them is to use the Append() function. Here is CElementRArray::AppendL() , which simply acts as a proxy and leaves if Append() fails (an error code is returned):
void CElementRArray::AppendL(const CChemicalElement* aElement) { User::LeaveIfError(iElementArray.Append(aElement)); } Note that, since this is a pointer array, the Append() function takes a pointer to the templated class. It is also worth considering the issue of ownershipthe array is generally considered to take ownership of the object passed by pointer, and so it may be necessary to pop any locally scoped pointer off of the Cleanup Stack once it has been appended:
[View full width]// Construct a new element from the mixed data. // Remember NewLC leaves element on the Cleanup Stack CChemicalElement* newElement = CChemicalElement::NewLC(aName, aSymbol, atomicNumber,relativeAtomicMass, type, radioactive); // Append new element to the element array AppendL(newElement); // Remove the element pointer from the cleanup stack CleanupStack::Pop(newElement); // Now owned by array
Failure to do this may result in a double-deletion, should a leave occur.
In addition to append, it is also possible to insert a new element at a specified position. The prototype for this is:
TInt Insert(const T* anEntry, TInt aPos);
where T is the templated class and aPos is the insertion positionin other words, the index into the array. The return code indicates whether the insertion was successful or not (perhaps due to lack of memory, for instance).
To find the number of elements stored, simply invoke the Count() method as shown below:
TInt CElementRArray::NumberOfElements() const { return iElementArray.Count(); } Accessing elements is achieved via operator[] . Two overloads are provided, one of which returns a const pointer, the other a non- const pointer. Again, CElementRArray provides a proxy for both of these overloads:
const CChemicalElement& CElementRArray::At(TInt aPosition) const { return *iElementArray[aPosition]; // Const overload } CChemicalElement& CElementRArray::At(TInt aPosition) { return *iElementArray[aPosition]; // Non-const overload } | | In Symbian OS, passing an object by pointer generally denotes transfer of ownership. Rather than return a pointer, the method returns a reference, and the pointer is dereferenced to obtain the value pointed to. Ownership is not passed out, but remains with the array. |
In common with most arrays, Symbian OS dynamic arrays are zero indexed, and so the value of aPosition must not be negative or greater than the number of elements minus one ( N - 1 ). A panic will occur if these conditions are not met.
Once an array is finished with, it must be reset before being allowed to go out of scope (or before the object in which it is nested is deleted). Both RArray and RPointerArray implement a Reset() method that frees all of the memory allocated for storing the elements. RPointerArray also implements an additional method, ResetAndDestroy() . Since the elements are pointers to heap cells , simply calling Reset() would deallocate the pointers themselves but not the objects to which they point. That is fine if the array does not own the data, but in the Elements example it does. CElementRArray implements a method DeleteAllElements() as a proxy for ResetAndDestroy() :
void CElementRArray::DeleteAllElements() { // Deletes all the elements iElementArray.ResetAndDestroy(); } CElementRArray 's destructor is then simply:
CElementRArray::~CElementRArray() { DeleteAllElements(); } Sorting and Finding
RArray provides powerful and flexible finding and sorting APIs. The simpler of these is sorting, so that will be discussed first.
Sorting
The general procedure to sort an RArray (or RPointerArray ) is:
-
Define a comparison function that returns if the two objects are identical, -1 if the first is smaller or +1 if the first is bigger. This function may be implemented as a static member function, a global function or a member of a namespaceyou will need a pointer to it for the next step.
-
Construct a TLinearOrder object, using a pointer to the desired comparison function in its constructor.
-
Invoke Sort() on the array, passing in the TLinearOrder object.
The Elements application demonstrates how to use the sorting API. The function CElementRArray::SortByAtomicNumberL() is implemented to sort the elements of iElementArray into an order determined by their atomic number. The comparison function here would simply need to take two integers (atomic numbers ) and decide which was the biggest.
Here is the implementation of CElementRArray::SortByAtomicNumberL() :
using namespace NElementComparisonFunctions; void CElementRArray::SortByAtomicNumberL() { // Wrap up a function pointer to the comparison function TLinearOrder<CChemicalElement> order(CompareElementsAtomicNumber); iElementArray.Sort(order); } The actual sort API is very simple, but it is the TLinearOrder object that introduces the power and complexity behind the process.
The constructor of TLinearOrder takes, in addition to the template parameter, a function pointer to a comparison function. For the sake of tidiness, all of the comparison functions (a few of which are shown below) have been wrapped up into a namespace:
[View full width]namespace NElementComparisonFunctions { TInt CompareElementsName(const CChemicalElement& aElement1, const CChemicalElement&
Of interest in this example is NElementComparisonFunctions::CompareElementsAtomicNumber() . Here is the implementation:
[View full width]TInt NElementComparisonFunctions::CompareElementsAtomicNumber(const CChemicalElement&
The effect of this code is simply to return zero if the atomic numbers are equal, -1 (less than zero) if aElement1 's atomic number is less than aElement2 's, and +1 (greater than zero) if aElement1 's atomic number is greater than aElement2 's.
This function can then be called by the TLinearOrder object, as it is used by the RArray::Sort() (or RPointerArray::Sort() ) method to determine if two elements are in the correct order or not. This is the basis of how the sorting algorithm works.
As a matter of interest, here is how the equivalent name comparison function works. It is actually simpler, because tdesC provides a CompareF() method that does exactly what is required:
[View full width]TInt NElementComparisonFunctions::CompareElementsName(const CChemicalElement& aElement1,
Finding
Finding is slightly more complex, but it builds on the sort process outlined above. The basic steps are:
- Define a comparison function that returns Etrue if the objects are identical, EFalse otherwise . Again it must be a static, global or function of a namespace.
- Construct a TIdentityRelation object, using a pointer to the desired equality function in its constructor.
- Construct a new object, which contains the data you are looking for.
- Invoke Find() on the array, passing in the TIdentityRelation object and the example object. This function will return the ( zero-based ) index of the matching element, or KErrNotFound .
In the example application, CElementRArray::FindElementByAtomicNumberL() , enables an array to be searched for an element with a particular element number. This function creates the TIdentityRelation object and then calls CElementRArray::DoFindL() where RArray::Find() is called.
The Find() API takes two arguments:
TInt foundAt = iElementArray.Find(example, aRelation);
In this case, example is an object that contains values matching those being sought, and aRelation is a TIdentityRelation that is used to equate two objects. Like TLinearOrder it is constructed with a pointer to the equality function:
TIdentityRelation<CChemicalElement> relation(ElementsHaveSameAtomicNumber);
Here is the ElementsHaveSameAtomicNumber function (also defined in the NElementComparisonFunctions namespace):
TBool NElementComparisonFunctions::ElementsHaveSameAtomicNumber( const CChemicalElement& aElement1, const CChemicalElement& aElement2) { return aElement1.AtomicNumber() == aElement2.AtomicNumber(); } Some of CElementRArray 's find process is factored into one common function that is invoked by FindElementByAtomicNumberL() . Both functions are shown below:
[View full width]using namespace NElementComparisonFunctions; TInt CElementRArray::FindElementByAtomicNumberL(TInt aAtomicNumber) const { // Wrap up a function pointer to the identity function TIdentityRelation<CChemicalElement> relation(ElementsHaveSameAtomicNumber); // Find the element using the given atomic number only return DoFindL(relation, KNullDesC, KNullDesC, aAtomicNumber); } TInt CElementRArray::DoFindL(const TIdentityRelation<CChemicalElement>& aRelation, const
FindElementByAtomicNumberL constructs the TIdentityRelation from the appropriate function pointer. It then invokes DoFindL , passing dummy values for all but aAtomicNumber (since ElementsHaveSameAtomicNumber() will ignore them anyway).
DoFindL() first of all constructs a new CChemicalElement from its arguments. In this example the new CChemicalElement will have the atomic number that is being sought. It then invokes Find() , passing the example CChemicalElement and the TIdentityRelation that is to be used for the equality check. Once the find has completed, the CChemicalElement may be destroyed . If the value returned by Find() , indicates an error ( KErrNotFound ), the function leaves; otherwise the index of the CChemicalElement with atomic number aAtomicNumber is returned.
It is perhaps worth stressing that both the comparison and equality functions may be as complex as you like for the particular problem in hand. The equality function, for instance, might return ETRue if the relative atomic masses are identical to within a given accuracy (say, two decimal places).
CArray Types
All of the CArray types use buffers to store their data. Buffers (derived from CBufBase ) provide access to regions of memory and are in some ways similar to descriptors in that respect. However, while descriptors are intended to store data objects whose maximum size is not expected to alter much, buffers are expected to grow and shrink dynamically during the lifetime of the program. There are two buffer typesflat and segmentedand these two types give rise to two basic subtypes of CArray .
Flat buffers store their entire data within a single heap cell . Once full, any subsequent append operation requires a new heap cell to be allocated that is large enough to contain the original and new data. Once the allocation has completed, all of the old data is copied to the new cell, and the old cell is released back to the global heap.
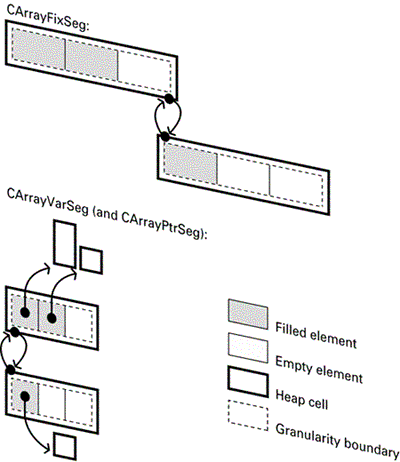
Segmented buffers store their data in a doubly-linked list of smaller segments , each of which is a separate heap cell of fixed size. Once all of the segments have been allocated, a new segment will be allocated and added into the list, with the old data remaining in place, and without the need for copying. While this can reduce the memory thrashing associated with frequent reallocation, accessing data is less efficient than flat buffers, since the list of segments must be traversed, plus more memory is consumed by the need to store linked list pointers. It can also lead to memory fragmentation.
Note that inserting into the middle of a segmented buffer may also result in the creation and insertion of a new segment into the middle of the segment list. This can also require some moving of data if it causes a segment to be effectively "split."
Table 3-4. Summary of CArray Types
| Name | Element Size | Buffer Type | Use |
|---|---|---|---|
| CArrayFixFlat | Fixed | Flat | Use for fixed- sized T or R type objects when infrequent allocation is expected |
| CArrayVarFlat | Variable | Flat | Use for variable-sized T or R type objects when infrequent allocation is expected |
| CArrayPtrFlat | Pointer | Flat | Use for pointers to objects when infrequent allocation is Expected |
| CArrayPakFlat | Variable (packed) | Flat | Use to store an array of variable sized T or R type objects within one heap cell when infrequent allocation is expected |
| CArrayFixSeg | Fixed | Segmented | Use for fixed-sized T or R type objects when frequent allocation is expected |
| CArrayVarSeg | Variable | Segmented | Use for variable-sized T or R type objects when frequent allocation is expected |
| CArrayPtrSeg | Pointer | Segmented | Use for pointers to objects when frequent allocation is expected |
| Arrays of variable sized elements are internally managed as an array of pointers, but with an interface that works with objects by value. Packed arrays are managed by value and contain length information. How the length of a T or R class object varies is not really defined! | |||
All CArray types have an associated granularity. This specifies how many elements can be added before the array must grow. For flat buffer arrays with a granularity of N , the initial allocation will be large enough to hold N elements. Subsequent expansion will see the buffer size increase by N elementseven to just add a single element. For segmented buffers with a granularity of N , each segment is large enough to hold N elements. If the granularity is too large, then considerable amounts of memory may go unused. If it is too small, then reallocation of the buffer may occur frequently, or there will be a large number of small segments.
An outline of all of the available CArray types is provided in Table 3-4.
Figures 3-4 and 3-5 illustrate how each of the different CArray types is arranged and stores its data. In each case the granularity shown is 3 .
Figure 3-4. Flat arrays.
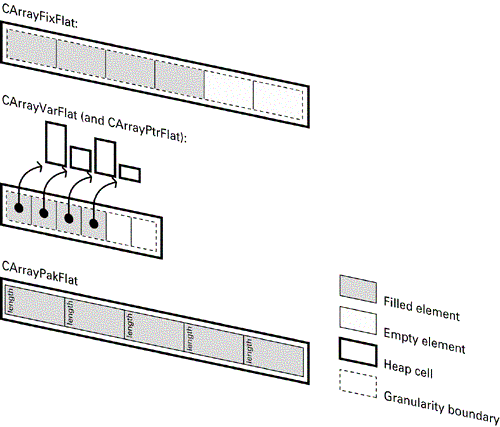
Figure 3-5. Segmented arrays.
Regardless of the of the array type, the APIs remain much the same, although there are, of course, some differences. In the Elements example application, the class CElementCArray (derived from CElementList ) uses a CArrayPtrFlat array to store the elements. This is a replacement for the RPointerArray used by CElementRArray , which was covered previously.
Basic APIs
Since CArray s are CBase derived, they should always be constructed on the heap. Like RArray s, they are templated, and pretty much the same rules apply for the type of objects they can contain: simple types for CArrayFix , CArrayVar or CArraySeg arrays, and pointers to objects of any type in the case of CArrayPtr arrays, as used in the example application.
Here is a declaration taken from the Elements example:
class CElementCArray : public CElementList { private: CArrayPtrFlat<CChemicalElement>* iElementArray; }; Naturally, CElementCArray will require two-phase construction because of the array being owned on the heap. Here is the second-phase constructor:
void CElementCArray::ConstructL() { iElementArray = new (ELeave) CArrayPtrFlat<CChemicalElement>(KElementListGranularity); } CArray s contain no elements when they are constructed and they implement an AppendL() functionnote the trailing L , it leaves rather than returning an error code. This makes the CElementCArray::AppendL() proxy even simpler:
void CElementCArray::AppendL(const CChemicalElement* aElement) { // Cast away pointer const-ness iElementArray->AppendL( const_cast<CChemicalElement* const>(aElement)); } Or at least it would be simpler were it not necessary to cast away the const -ness of aElement . This is because CArrayPtrFlat::AppendL() requires a const pointer to a modifiable object, not a (modifiable) pointer to a const object, as would be the case here. A const*const pointer ( const pointer to a const object) in the function prototype would not help, either!
| | It is worth mentioning that CArrays also have an ExtendL() function. This function returns a non-const reference to a newly constructed object of the templated type. This is often simpler to use than constructing a new object and then appending itsimply use ExtendL() and modify the reference it returns directly. Note that this operation uses the class's default constructor, so it should be used only with simple types. |
CArray classes also implement an InsertL() method, which operates just like RArray::Insert() (other than it leaves on failure), and a Count() method. They also have two overloaded operator[] s for accessing members, and two At() overloads that work just the same as the operator[] . It is a matter of preference, but using At() with a pointer to a CArray can be cleaner than having to dereference the pointer to be able to use operator[] :
const CChemicalElement& CElementCArray::At(TInt aPosition) const { return *(*iElementArray)[aPosition]; // Const overload } CChemicalElement& CElementCArray::At(TInt aPosition) { return *iElementArray->At(aPosition); // Non-const overload } As with RArray s, CArray s must be Reset() before being deleted to deallocate all of their elements. And as with RPointerArrays , CArrayPtrFlat implements a ResetAndDestroy() method to delete all of the objects pointed to as the pointers themselves are deallocated. Again, CElementCArray::DeleteAllElements() is called by the destructor in the example application, and is implemented like this:
void CElementCArray::DeleteAllElements() { // Deletes all the elements iElementArray->ResetAndDestroy(); } The destructor must invoke this function and then delete the array itself :
CElementCArray::~CElementCArray() { DeleteAllElements(); delete iElementArray; } Sorting and Finding
The sorting and finding APIs provided by CArray s are a little less flexible than those of RArray s, but they are correspondingly easier to use.
Sorting
The sorting of a CArray consists of just two steps:
- Construct an instance of the appropriate key, specifying the field offset, the sort type and (for char arrays) the text length.
- Invoke Sort() on the array, passing in the key.
These steps will be explained by examining CElementCArray::SortByAtomicNumberL() from the example application. Here is the implementation:
void CElementCArray::SortByAtomicNumberL() { TKeyArrayPtr key(_FOFF(CChemicalElement, iAtomicNumber), ECmpTInt); User::LeaveIfError(iElementArray->Sort(key)); } Notice that, unlike the CElementRArray implementation, this method is self-contained. It does not need to refer to other functions to sort the elements into order. All that is needed is a key.
Table 3-5 shows the correct key type for the different CArray types.
Table 3-5. Key and Array Types
| Name | Key Type | Notes |
|---|---|---|
| CArrayFixFlat | TKeyArrayFix | |
| CArrayVarFlat | TKeyArrayVar | |
| CArrayPtrFlat | TKeyArrayFix -derived | Requires special implementation (see example code) |
| CArrayPakFlat | TKeyArrayVar | |
| CArrayFixSeg | TKeyArrayFix | |
| CArrayVarSeg | TKeyArrayVar | |
| CArrayPtrSeg | TKeyArrayFix -derived | Requires special implementation (see example code) |
Note the need for a special implementation for pointer arrays. Using a TKeyArrayFix instance on a CArrayPtr will compile but will not produce meaningful results ! This is because the key's At() implementation expects the array to contain instances of the data, not pointers to instances . (In effect, you are sorting addresses rather than values.)
The solution is to define a new TKeyArrayFix -derived key that overrides the implementation of TKeyArrayFix::At() . The implementation of the private nested class TKeyArrayPtr in the Elements application demonstrates how to do this, and for reference, the overridden function is shown here:
TAny* CElementCArray::TKeyArrayPtr::At(TInt aIndex) const { if (aIndex == KIndexPtr) { return *(TUint8**)iPtr + iKeyOffset; } return *(TUint8**)iBase->Ptr(aIndex * sizeof(TUint8**)).Ptr() + iKeyOffset; } You do not need to understand this, but feel free to copy it in your own code should you ever need to sort a CArrayPtr class. Naturally it does not necessarily have to be a private nested classit is merely implemented this way, since it is not needed elsewhere in the Elements example.
Once you have chosen the right key class for your array type, the next step is to instantiate it. The constructors for all of the keys are pretty much the same. Here are the ones for TKeyArrayFix :
TKeyArrayFix(TInt aOffset, TKeyCmpText aType); TKeyArrayFix(TInt aOffset, TKeyCmpText aType, TInt aLength); TKeyArrayFix(TInt aOffset, TKeyCmpNumeric aType);
All of them take an integral offset value, aOffset . This is simply the offset of the "field" (or data member) within the class. How can you work this out? The macro _FOFF(c,f) , where c is the class and f is the field, will calculate it for you. The first line of the CElementCArray::SortByAtomicNumberL() shows its use:
TKeyArrayPtr key(_FOFF(CChemicalElement, iAtomicNumber), ECmpFolded);
Within the key's constructor you must specify the field type. Table 3-6 summarizes those available.
Table 3-6. Key Types
| Field Type | Key Types |
|---|---|
| Integer | ECmpTInt8, ECmpTInt16, ECmpTInt32, ECmpTInt, ECmpTUint8, ECmpTUint16, ECmpTUint32, ECmpTUint, ECmpTInt64 |
| Text | ECmpNormal, ECmpNormal8, ECmpNormal16, ECmpFolded, ECmpFolded8, ECmpFolded16, ECmpCollated, ECmpCollated8, ECmpCollated16 |
The integer types simply match the integer type of field (for example, use ECmpTInt for a TInt object). The textual types specify the text "width" (8- or 16-bit), and whether the text should be treated normally, folded or collated. Folding effectively ignores differences assumed to be insignificant for comparison, such as case differences. Collating removes all such differences and also allows special linguistic characters and character combinations to be compared, such as equating "ss" with " b " in German, or "AElig" with "ae".
Notice that the length can also be specified for text comparisons. This is not necessary for descriptor types, since the length is implicit. If a length is specified, however, the text is assumed to be a simple char array.
Here is how the key is defined in CElementCArray::SortBySymbolL() :
TKeyArrayPtr key(_FOFF(CChemicalElement, iSymbol), ECmpFolded);
ECmpFolded specifies that the sorting is done on a text field and that simple case differences should be ignored. Since no size is given, the field iSymbol is assumed to be a descriptor with an implicit length.
It is important to realize that the _FOFF macro must be able to access the data members . This implies that CElementCArray must be a friend of CChemicalElement for the sort (and find) methods to be able to calculate the offset of CChemicalElement 's private data members. Another alternative would be to make the data public, but that is an undesirable design option.
Once the key has been constructed, sorting is simply a matter of passing the key into the Sort() method of the array.
Finding
Finding data in a CArray is a little more complex; it involves the following steps:
- Construct an instance of the appropriate key type, specifying the offset of the field to be matched, the comparison type and (for char arrays) the text length.
- Construct a new object, which contains the data you are looking for.
- Invoke Find() on the array, passing in the key, the example object and a TInt to receive the search result. Find() will return zero if the item is found and will set the search result to the index the item was found at. If the item is not found, then the search result is set to the size of the array and an error code is returned.
The example application provides CElementCArray::FindElementByAtomicNumberL() to allow you to find, within the array, an element with a particular atomic number. This function creates the key and then invokes DoFindL() where Find() is called.
TInt error = iElementArray->Find(example, aKey, foundAt);
The first argument, example , is an object of the templated type matching the data being sought. aKey is the key to use for the searchthis specifies which data field is to be matched in exactly the same way as with sorting. The final argument, foundAt , is a TInt& that will contain the index of the matching element if one is found. If no match is found, or some other error occurs, then an error code will be returned by the functionin this case foundAt will contain the size of the array.
As with CElementRArray , some of the common code within the find functions has been factored out. The implementation of CElementCArray::FindElementByAtomicNumberL() , together with CElementCArray::DoFindL() is shown below:
[View full width]TInt CElementCArray::FindElementByAtomicNumberL(TInt aAtomicNumber) const { // Make the key TKeyArrayPtr key(_FOFF(CChemicalElement, iAtomicNumber), ECmpTInt); // Find the element using the given atomic number only return DoFindL(key, KNullDesC, KNullDesC, aAtomicNumber); } TInt CElementCArray::DoFindL(TKeyArrayPtr& aKey, const TDesC& aName, const TDesC& aSymbol, TInt aAtomicNumber) const { // A utility function to wrap up the find operation CChemicalElement* example = CChemicalElement::NewL(aName, // The example element to
The DoFindL() function has been implemented in such a way that it can find elements based on their name, symbol or atomic number. Since the discussion here is concerned with finding elements of a particular atomic number, a null descriptor, KNullDesC , is passed through for both the name and the symbol. Remember that you need to check the value returned from Find() to determine whether a match was made. In this example the function, DoFindL() will leave if the required element is not found successfully.
Descriptor Arrays
Descriptors commonly need storing in arrays, so Symbian OS provides a number of instantiable descriptor arrays for such situation.
All of the descriptor arrays are derived from MDesCArray (which predictably has MDesC8Array and MDesC16Array variants). MDesCArray provides a common interface for accessing the basic functionality of the different descriptor array classes (which include CDesCArrayFlat , CPtrCArray and numerous others). The (simplified) declaration of MDesC16Array is shown below:
class MDesC16Array { public: virtual TInt MdcaCount() const = 0; virtual TPtrC16 MdcaPoint(TInt aIndex) const = 0; }; MDescC16Array::MdcaCount() returns the number of descriptors in the array; MDescC16Array::MdcaCount() returns a TPtrC16 pointing to the descriptor specified by aIndex . This API allows any type of descriptor array to be accessed regardless of its actual type.
Full details of creating and using desciptor arrays can be found in the SDK documentation.
Limitations
To finish off the discussion of CArray types, it is worth pointing out their limitations, particularly with regard to finding and sorting.
Firstly, it is only possible to search and sort integer or nested text fields. It is not possible to search or order floating-point values or heap-allocated text (including HBufC* ).
It is only possible to sort into ascending order.
Searches always start from the beginning of the array, and they will only return the first matchnote that this also applies to RArray s.
As a final note, it is worth being aware that a number of Symbian OS APIs use descriptor arrayssince these are CArray types, it is sometimes impossible to avoid their use!
Array Summary
Symbian OS provides two basic types of dynamic array: RArray s and CArray s. The array classes are all templated, with the parameter defining the type of object that is to form an array element. Both types of array offer the standard functionality that you would expect from an array class, such as sorting and searching.
Where possible you should favor the use of an RArray type, as they offer greater efficiency and ease of use, particularly when using pointers. However, you should be aware that RArray s do impose a limit on the size of the elements (640 bytes), and for efficiency, insertions into the array should be infrequent. The main benefit of a CArray is its support for segmented storage. Obviously the type of array you use may be dictated by the required parameters of a function you want to call, but, if not, always consider a RArray first.
EAN: 2147483647
Pages: 139