| Before we begin our study of the specifics of file systems and HP-UX, we need to spend a little time thinking about what a file system really is. The Challenge Since the beginning of computer operating systems, there has been a need to store program instructions and data in some type of nonvolatile memory so that they may be recalled and loaded into the system's RAM when needed. Very early systems stored information by punching patterns into paper tape or "keypunch" cards. This worked but was very slow and added the tasks of storage, collation, and labeling to the growing list of duties for the computer operator. When rotating magnetic storage mechanisms were first created (early cylindrical rotating drums evolved into flat disks with multiple platters), basic storage algorithms were developed. File Systems: A Simple Approach The first disk drives had precious little storage space (some of the first floppy drives held only 140 KB of data!), and the storage algorithms employed were quite simplistic by necessity. Figure 8-2 outlines a basic approach. Figure 8-2. File System Basics: 101 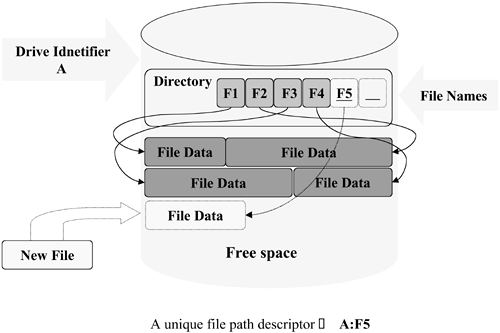
The first step was to come up with a way to identify specific drives under the control of the operating system. One approach was to assign drive letters to each physical drive. Once we can identify a specific drive, we need to be able to locate directory information for the files stored on it. Most early file system designs placed a pointer to the disk's directory data on the first physical sector of the mechanism (regardless of the overall size of a disk drive, they all have a first sector). These early directory structures were very sketchy in their details. Basically, there was an entry for each file consisting of its name, a starting offset, and the file's overall size. This approach is called a flat file system, so named because the file system had a single directory and all of its files were managed by this directory. In addition, all the data making up a specific file was stored in contiguous sectors on the disk. Once you found the beginning of a file, you simply read its data from the disk in a sequential manner until you reached its end. Although this approach is very dated, it still has certain strengths. If a file is to be accessed in a sequential manner or its contents are needed in their entirety, then the contiguous nature of storage in a flat file system provided good performance. A major weakness was the dynamics of what happened when a file was removed from the storage matrix or when an existing file needed to grow. When a file was removed, it left a hole. New files could be located in the hole as long as their size was equal to or smaller than that of the hole. New files larger than the hole needed to find available free space elsewhere on the disk. If an existing file needed to grow, it could simply extend its size if there was adjacent free space or be moved to an area of larger free space if one was available. This juggling of data resulted in fragmentation of the available free space within the overall disk. An approach to minimize this problem involved periodic disk maintenance to defragment the disk (see Figure 8-3). Figure 8-3. Fragmentation of Available Space 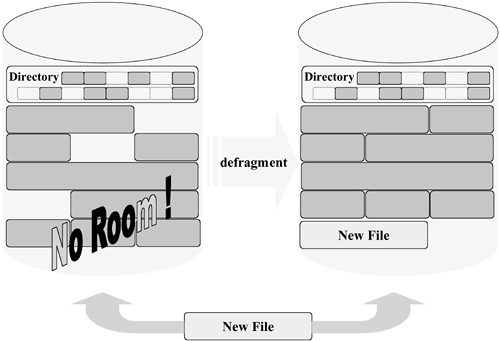
While defragmentation allowed the administrator to coalesce the free space holes into a contiguous free space at the end of the drive, it had to be performed while all the files on the drive were quiescent. This may not seem like much of an issue, but in today's world with 7-by-24 system utilization and +99.999% uptime requirements, defragmentation is a costly option. UNIX Gets a File System In the early 1970s, the developers of what was to become known as UNIX faced the need to design and implement a file system for their fledgling operating system. The file system designs in use at the time were mostly flat and required frequent defragmentation. Instead of following the crowd, our fearless UNIX developers chose to think outside the box and make fragmentation their friend. Figure 8-4 shows the first step to this new approach. Figure 8-4. Fragmentation Is Our Friend 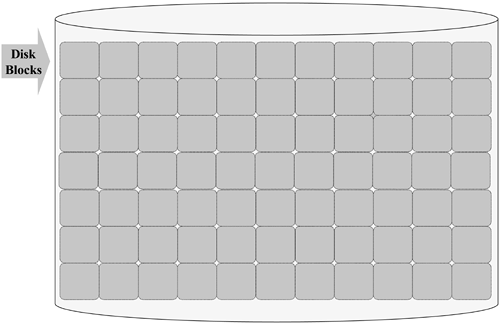
First, the entire disk is subdivided into uniform disk blocks (for the original UNIX file system, the block size was 512 bytes). A file's data is stored in any available disk block. There is no requirement that they be sequential or contiguous. The disk's free blocks are easily managed by the use of a simple bit allocation map. Each block is represented by a bit in the bitmap. If the bit is set, the block is in use; if it is not set, the block is available. The challenge with this design is to track the specific blocks that belong to a file and the order in which they are allocated. To this end, a section of the disk space is reserved (at the time of file system creation) to hold information about each file (see Figure 8-5). Figure 8-5. Creating an Index 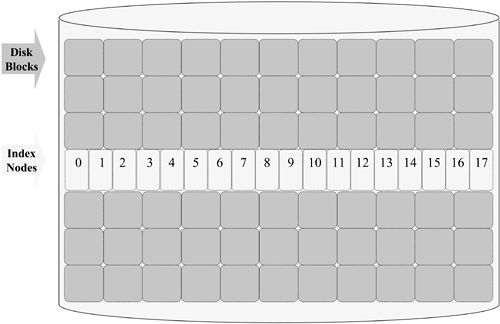
These indexed information nodes (inodes) have a fixed size and are arranged in an array located in the middle of the disk's storage space. Since each file reference required accessing the file's inode by locating the inodes in the middle of the disk, overall disk access times were optimized. The inode array is a prime example of what we call metadata, the administrative overhead required to manage the file system's user data. Additional metadata structures are shown in Figure 8-6. Figure 8-6. Metadata 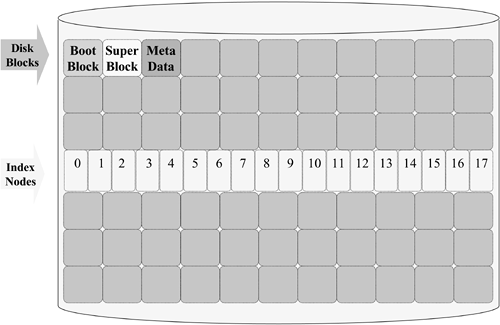
As we mentioned, the inode table was located in the middle of the disk to improve overall access time; but as not all disk drives are the same size, there needed to be a metadata structure in a well-known location on all disks containing potential file systems. To meet this need, several additional structures were created. When a machine is booting, it is running from simplified code in its boot ROM. A boot ROM usually has very minimalist driver code and can read only the first block of a device. For this reason, the first block of the disk is reserved as a boot block. Next, a block called the superblock is allocated. The superblock contains static and dynamic information about the specifics of the file system on the disk. One of the most important components is a pointer to the starting address (a byte offset) of the inode table. Additional structures, such as bit allocation maps, are also assigned and mapped by the superblock. Each type of file system may have its own specific additions to the contents of the superblock but certain key values are located at fixed offsets within the superblock regardless of the file system type. These values are used by the kernel to identify the file system type, version, and basic static configuration data. Layering a Directory Hierarchy on a Flat File System Another feature desired by the UNIX developers was the implementation of a hierarchical file system. The file structure was based on a basically flat model (there is only one inode table per file system), so a method needed to be developed to facilitate the use of directories and subdirectories. This brought about the creation of a special type of file known as a directory. This is an important point: in UNIX, a directory is simply a special type of data file. Every file on a UNIX system is known by its file system's device number and its inode number. Directory files contain a pairing of file names with their inode numbers on the local file system. Let's consider what is required to locate the contents of a file with the pathname of /home/chris/stuff (see Figure 8-7). Figure 8-7. Super Blocks, Index Nodes, Directories, and User Data 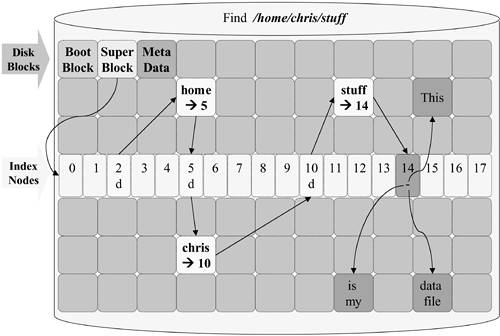
We start our search with the superblock of the / (root) file system. The superblock gives us the offset for the start of the inode table. As a standard, all file systems use inode 2 to point to their root directory data blocks. The size of an inode is fixed, and the first inode has an index of 0. Therefore, if you know an inode number, you may easily calculate its location on the disk volume. To find inode 2, you simply take the inode table offset from the superblock and add 2 * inode-size-in-bytes and you have the byte offset from the beginning of the file system. Examination of the root directory reveals that the home directory file's inode is 5. We return to the inode table and access node 5 and follow the block pointer to its data block. This reveals the inode number for the chris subdirectory. We then access node 10 and locate the stuff directory block pointer. From this block we learn that inode 14 contains the attributes of the /home/chris/stuff file. Now we simply have to follow the various block pointers in this inode to access the file's data. You may have noticed that the inode contains pointers to disk data blocks and a type flag to let us know whether the next step of our scavenger hunt will lead us to a directory file or a regular file. The actual specifics of the inode data structure differ from one file system type to another. Next, we study the specifics of the Hierarchical File System (HFS) as implemented by the HP-UX operating system. |