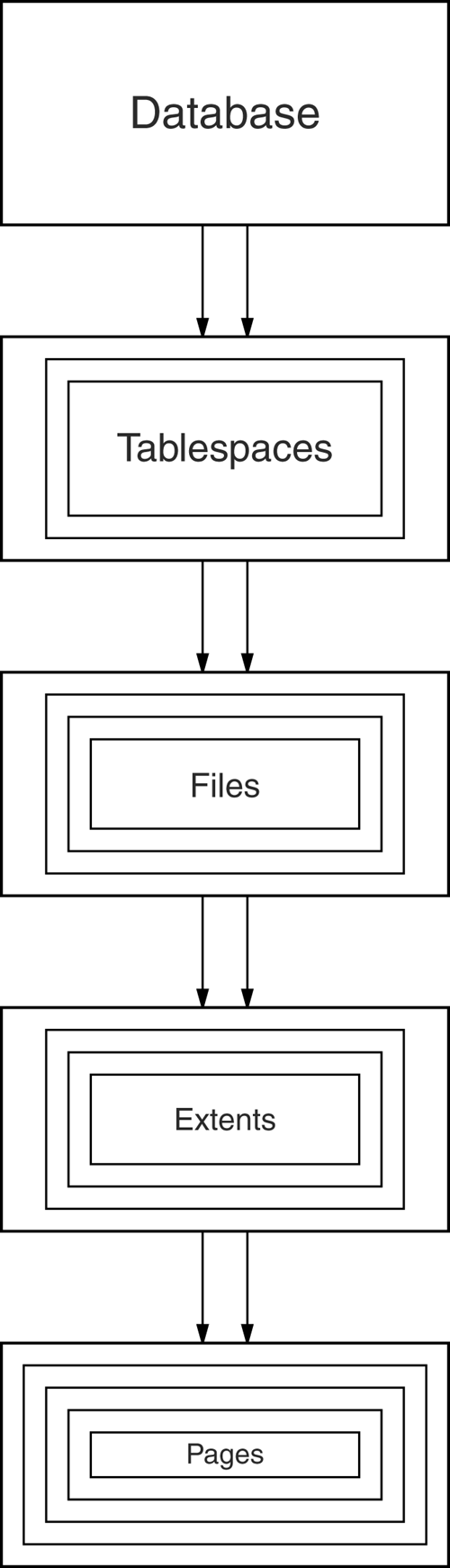
The Storage Hierarchy
| You can doubtless think of many examples of storage hierarchies in ordinary life. For example, people live in neighborhoods, which are in towns, which are in regions , countries , continents, and so on up the line. The relations are generally many-to-one , although there are occasional one-to-one correspondences (e.g., Australia is both a country and a continent ), and occasional exceptions (e.g., a person can straddle a city boundary). Figure 8-1 shows the storage hierarchythe physical constructs of a database. The hierarchy of physical objects suggests thatwith occasional one-to-one correspondences or exceptionsdata rows live in pages, which are in extents, which are in files, tablespaces, and databases. There is a reason for each level of grouping. To see what the reason is, we'll go through each of those objects in order, up the line. Figure 8-1. Physical constructs; the storage hierarchy PagesDepending on the DBMS, a page is also called a data block , a block , a blocking unit , a control interval , and a row group . A page is a fixed- size hopper that stores rows of data. Pages have four common characteristics, which are not true by definition but are always true in practice. They are:
One other thing about pages is usually true in practice and is always recommendedAll rows in a page are rows for the same table. It is true that IBM and Microsoft allow mixing rows from different tables into the same page, while Oracle allows mixing in a special condition called clustering, but these exceptions have advantages in special cases only. Table 8-1 shows what the Big Eight do with pages. The most interesting fact is how slight the differences are. Notes on Table 8-1:
Table 8-1. DBMSs and Pages
Now that we know what a page is, let's look at what a page is for:
Because a page is a minimum unit, when you ask for a single row, the DBMS will access a page. The only thing you'll see is the single row, but now you know what's really going on. And you can use that knowledge. Here's what it implies:
Both of these implications suggest that making rows smaller is a good thing. But there is a limit to all good things, and the limit is 512 (it's just a house keeping thing, having to do with the way some DBMSs store page header information in a fixed space). To sum it up, your aim should be to have at least 10 rows per page, but fewer than 512 rows. LOB PagesAn exceptional situation arises when a column is defined as a BLOB or another LOB data type such as TEXT, IMAGE, or CLOB. Recall (from Chapter 7, "Columns") that BLOB columns are rarely on the same page as the other columns of a tablethey get pages of their own. With many DBMSs, BLOBs are even automatically in a file of their ownthe best method. With most DBMSs (MySQL is an exception), BLOB pages can't be shared. You can't store two BLOBs on one page, and you can't store BLOB and non-BLOB columns on one page. Therefore any BLOB that isn't NULL will involve a lot of overhead space: the pointer from the main page (about 10 bytes), the page header (about 80 bytes per BLOB page), and the unused space at the end of the last BLOB page (a few thousand bytes on average). If a table has LOBs in it, you should avoid table scans, and you should avoid SELECT * ... statements. ExtentsAn extent is a group of contiguous pages. Extents exist to solve the allocation problem. The allocation problem is that, when a file gets full, the DBMS must increase its size. If the file size increases by only one page at a time, waste occurs because:
Suppose, though, that the DBMS adds eight pages when the file gets full, instead of only one page. That solves the allocation problem. Call that eight-page amount an extent, and you now have a definition of what an extent is, in its primary meaning. Notice that in the primary meaning, extents are units of allocation, not units of I/O as pages are. Now suppose that, in the CREATE TABLE statement, you were able to define two things: (a) an initial extent size (how much to allocate during CREATE) and (b) a " next " extent size (how much to allocate each subsequent time when the file gets full). Well, you can. Here's an example using Informix's nonstandard SQL extension syntax: CREATE TABLE Table1 ( column1 INTEGER, column2 VARCHAR(15), column3 FLOAT) EXTENT SIZE 20 NEXT SIZE 16 Depending on the DBMS, you can usually define the initial and next extent sizes, but most people make no specification and just use default values. Typical default values are: 16x4KB pages (IBM), 8x8KB pages (Microsoft)or 1MB for certain tablespaces (Oracle). Clearly Oracle is different. Oracle believes that it's a good idea to preallocate a large amount of file space. This makes the allocation problem a rare phenomenon . To see extents in action, we used Ingres to create a table with ten rows per page and 16 pages per extent. Then we timed INSERT speed. We found that INSERT speed was consistent except for a small hiccup (7% slower) on every 10th row (i.e., at each page end) and a slightly larger hiccup (20% slower) on every 160th row (i.e., at each extent end). It is possible to predict an average INSERT time, but the worst case is much worse than the average. All because of extents. Read groupsA read group is a group of contiguous pages. For many DBMSs, a read group is the same thing as an extent, but there's a logical difference. A read group is the number of pages that are read together, while an extent is the number of pages that are allocated together. Table 8-2 shows the usual name and default size of a read group for the Big Eight. Consider IBM. Table 8-2 tells us that IBM's default page size is 4KB, and the default read group size is 16 pages. This SQL statement forces IBM to perform a table scan: SELECT * from Table1 WHERE column1 LIKE '%XX%' Table 8-2. DBMSs and Read Groups
When executing this SELECT, IBM reads 16 pages at a time into the buffer. This is faster than reading 16 pages, one at a time. It's the right thing to do because all pages must be examined in order to resolve the query. It would be wrong to keep all the pages in cache, though, because pages read during a table scan are unlikely to be needed again soon. So a read group is a unit of I/O, but not the minimal unitthe page is the minimal unit, and the page is also the administrative unit for caches. It comes down to this: If most of your SELECTs involve table scans, then you want the read group size to be double the default amount. If the only way to accomplish this is to double the extent size, so be it. Increasing the read group size will also mean that more space is needed in memory for the buffer pool. Tip If the extent size is not the same as the read group size, then it should be an exact multiple of the read group size. FilesA file is a group of contiguous extents. And that's about it. Surprisingly, a file is not a physical representation of a table. It could be, but usually it isn't because of one of the following:
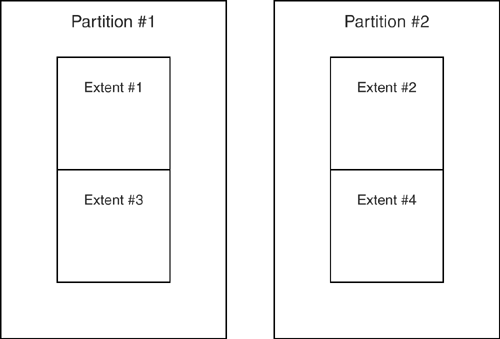
PartitionsA partition is a group of contiguous extents. Often a partition is a file, but it doesn't have to be. [3] Suppose you have four extents, numbered {1 , 2 , 3 , 4} . Figure 8-2 shows what a two-partition system could look like.
Figure 8-2. A two-partition system Partitions are bad if there are few extents and few database users. Why? Because the fundamental principle is that rows should be crammed together. That helps caching and reduces the number of page writes. Partitions are good ifand only ifthere are many extents and many database users. Why? Two reasons, actually. The first is that in a multiuser environment, partitioning reduces contention . The second is that in a multidisk-drive environment, partitioning increases parallelism. How does partitioning reduce contention? Suppose that User AMY and User BOB are both doing an INSERT. User AMY arrives first and locks the final page of the final extent. (In practice the DBMS starts by looking for free space within the file, but this example is realistic enough.) Now User BOB arrives andhere's the tricklocks the final page of the final extent in the other partition. BOB is not locked out because AMY and BOB do not have to contend for the same end page. How does partitioning increase parallelism? Suppose that the partitions are on different independent disk drives (Disk #1 and Disk #2) and that the DBMS must read a page in Extent #1 (stored on Disk #1) and also a page in Extent #2 (stored on Disk #2). In this case, the DBMS can issue simultaneous "seek and read" commands for the two pages. Because the drives work independently, the time to perform both commands is the same as the time to perform only one command. In fact you can realize some of partitioning's advantages with any multithreaded operating system even if the partitions are areas within a single file on a single disk drive, but if you have the hardware to do it, you should keep partitions as separated as they can be. Balanced partitions are best. If there is a 50/50 chance that a user will want Partition #1 instead of Partition #2, and there is a 50/50 chance that a desirable page is in Partition #1 instead of Partition #2, then there's balance. Obviously there would be more contention if User AMY and User BOB were more likely to go for the same partition, or if Page #1 and Page #2 were more likely to be on the same partition. In other words, it is wrong to sayLet's separate the much-used records from the little-used records. That's fine if the little-used records are being shuffled off to a slow or remote storage medium, but we're talking about two storage areas on the same disk, or two disk drives of equal quality. Balanced partitions are best. IBM, Informix, Ingres, Microsoft, Oracle, and Sybase support partitioning with non-standard extensions to the CREATE TABLE or ALTER TABLE statements (InterBase and MySQL don't support partitioning). You should be able to specify under what conditions an INSERT will head for Partition #1 rather than Partition #2. For example, with Informix's non-standard SQL-extension syntax, you can specify conditions like: ... BY EXPRESSION branch_number < 7 IN Partition1, transaction_time < TIME '11:00:00' IN Partition2 This attempt to use logic is vain, because there is no guarantee that the conditions are changeless. If they were, you would probably use separate tables instead of separate partitions. A simple hash algorithm that ensures random or round- robin distribution of rows is all you really need. Partitioning is normal in all big shops except data warehouses. Partitioning is unpopular for data warehouses because:
Naturally, even data warehouses do some distribution in order to encourage parallel queries ( putting joined tables and their indexes on different drives, say). Real partitioning, though, is for OLTP. People over-generalize and say that sequential queriers put similars together while ad-hoc queriers distribute them randomly , but that's an aide-memoire rather than a true observation.
TablespacesA tablespace (also called a dbspace by some DBMSs, e.g., Informix) is a file, or a group of files, that contains data. For example, this non-standard Oracle SQL-extension statement creates and associates a tablespace with a 10MB file: CREATE TABLESPACE Tb DATAFILE '\disk01\tb.dbs' SIZE 10M; Here's another example, using IBM's syntax: CREATE TABLESPACE Tb MANAGED BY DATABASE USING ('d:\data1') This IBM tablespace has no preset size limitation. It can grow up to the size allotted for the file named d:\data1 . A tablespace can contain a single table, or it can be shared either between one table and its indexes or between multiple tables. In other words, it's possible to mix extents from different objects in the same tablespace. Mixing brings some advantages for administration but has no great performance effect. The typical reasons for dividing databases into tablespaces are:
The Bottom Line: Storage HierarchyA page is a fixed-size hopper that stores rows of data. A page is a minimal unit for disk I/O, a unit for locking, a unit for caching, and a unit for administration. All pages in a file have the same size. The choice of page sizes is restricted to certain multiples of 1024, between 1KB and 64KB. The optimum page size is related to the disk drive's cluster size; 8KB is the current usual page size. Pages contain an integral number of rows. All rows in a page are rows for the same table. When you ask for rows, the DBMS gets pages. Big rows waste space. Keep row size smallbut not too small. Aim for a minimum of 10 rows and a maximum of 511 rows per page. When you access two rows on the same page, the second access is freethat is, access to Row #1 is free if the page is still in the buffer pool since you accessed it for Row #2. Use this fact to help performance: do two INSERTs together, fetch in the DBMS's default order, make rows smaller or pages larger. LOB columns are rarely on the same page as the other columns of a tablethey get pages of their own. If a table has LOBs in it, avoid table scans and SELECT * ... statements. An extent is a group of contiguous pages that are allocated together. A read group is a group of contiguous pages that are read together. If the extent size is not the same as the read group size, then it should be an exact multiple of the read group size. A file is a group of contiguous extents. A partition is also a group of contiguous extents. Often a partition is a file, but it doesn't have to be. Partitions are bad if there are few extents and few database users. Partitions are good if there are many extents and many database users because partitioning reduces contention and increases parallelism. If you have the hardware to do it, keep partitions physically separated. Don't make assumptions that are only true for not-yet-partitioned databases. For example, ignore the observation that some tables have rows in order by date of insertion. Start partitioning before you have 100 users or one million rows or two disk drives. Don't worry about tables that are small or are used by only a small group of users. Strive for balance. Balanced partitions are best. A tablespace is a group of files. It's possible to mix extents from different objects in the same tablespace. Mixing brings some advantages for administration, but has no great performance effect. |
EAN: 2147483647
Pages: 125