An Industrial-Strength Object Database
At its core , Exchange Server is an object database. This object database is highly scalable, can be replicated, is built for 24/7 availability, and can hold many different types of objects, including messages, Microsoft Office documents, video files, voicemail, faxes, hyperlinks , text documents, custom forms, and executable files. You can store all of your application's data in the database and replicate the information to other locations so the application and its relevant information are available anywhere at any time. We'll look at key features of the Exchange Server database next .
Huge Storage Capacity
Many collaborative applications require that large amounts of data be continuously available. Exchange Server makes an excellent repository for this data because it can handle large amounts of information and ensure the reliability and availability of that information. Exchange Server supports very large databases ”up to 16 terabytes (16,000 gigabytes). That's a lot of information ”consider that if you compiled every Wall Street transaction in history, you'd have only a little more than 1 terabyte. The only factor that really limits the size of your database is the hardware you run Exchange Server on. The database can run continuously because it has online defragmentation and allows backup programs to work with the database, even when users are logged on.
Exchange Server can store many types of objects and their associated data in the same database. These different types of objects can even be in the same table, or folder (as tables are called in Exchange Server). Users simply drag and drop objects into these folders, and Exchange Server adds them to the database. This flexibility gives you a distinct advantage when you develop applications. Figure 2-4 shows a folder in Microsoft Outlook with many different objects.
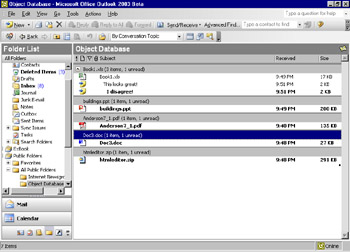
Figure 2-4: The Exchange Server database with many types of objects in a single folder
Multiple Views
The Exchange Server database not only supports multiple objects in a single folder but also multiple views of those objects. You can create views of the objects stored in the folder by sorting, grouping, and filtering the objects using any combination of their properties. For example, you can customize the view of an Exchange Server folder containing Office documents by specifying Office properties, as shown in Figure 2-5. Properties you define can be included as columns in a view, and you can use them to sort and group items in the view.
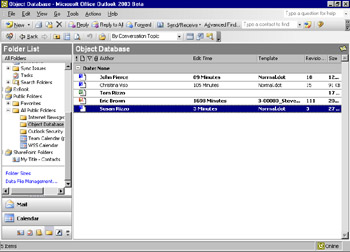
Figure 2-5: Views support using properties of Office documents
Exchange Server also supports "per-user" views that allow individual users to create views. Exchange Server actually maintains, for each user, the initial view of the folder, the status of read and unread items, and whether a particular grouping is expanded in the view. Figure 2-6 shows the same view as Figure 2-5, but for a different user. Notice how different the screen shots look in terms of read and unread items. Certain items are marked as read and stored per-user so that the system can track individual read and unread messages for each user . Views can also be replicated off line by using Exchange Server's built-in replication features.
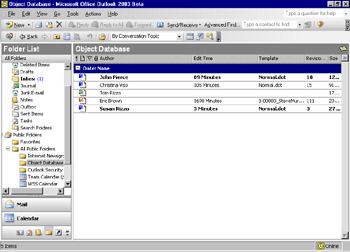
Figure 2-6: The initial view of the same discussion folder for a different user
Built-In Replication
The Exchange Server database can be replicated from one instance of Exchange Server to another and from Exchange Server to Outlook on a client machine. Exchange Server even supports filtered replication between the server and the client.
Replication in Exchange is not the same as simple duplication. Exchange Server replication is more similar to synchronization in that only the changes are sent to replicas in the system. Sending only changes, as opposed to copying an entire folder in each replication cycle, saves time and network bandwidth.
To set up server-to-server replication with Exchange Server, an administrator simply selects the folder to be replicated and then selects the server to replicate the folder to. The settings that enable server-to-server replication in the Microsoft Exchange System Manager program are shown in Figure 2-7. Once these settings are in place, the actual replication messages are sent over the Exchange Server messaging infrastructure. This allows the replication messages to leverage Exchange Server's load balancing, least-cost routing, and failover capabilities. Exchange Server also supports setting the time and size limits of the replication messages.
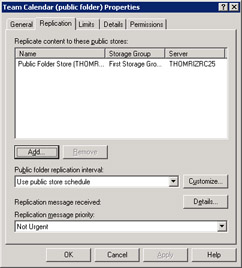
Figure 2-7: Setting up server-to-server replication for your applications in Exchange Server
The Exchange Server replication feature has built-in conflict management capabilities that enable different users to edit the same information at the same time in the same folder or even in replicas of a folder in different locations. To determine which item to accept as the newest, Exchange Server implements "last saved wins," the process of querying the time an item was saved and retaining the most recently saved version. You can also set an option that alerts users via e-mail when items are in conflict. Both versions of the item are sent to these users, and they decide which item is the most up-to-date. Exchange Server keeps the item they select.
For server-to-client replication, Exchange Server and Outlook support bidirectional synchronization of changes to information in Exchange Server folders. This synchronization occurs in Outlook as a background process so users can continue working in Outlook. Synchronization can be scheduled at certain intervals. For example, a user can configure Outlook replication so that every 30 minutes the Outlook client synchronizes its local database with new information from Exchange Server.
Outlook also supports filtered replication, in which only a subset of information is synchronized with the local database. Filtered replication is most useful to users when they want to take only a subset of the large amount of data in the Exchange Server database off line. For example, imagine an Exchange Server folder with 50,000 sales contacts. A typical user cannot accommodate the entire folder on her local hard disk, so she can set the replication criterion to only the contacts for whom she is the sales representative. Instead of 50,000 contacts, the filtered subset is 1000 contacts. Figure 2-8 shows the dialog box in Outlook in which users set criteria for filtered replication.
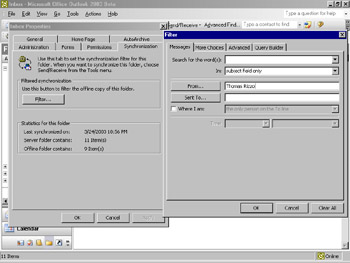
Figure 2-8: Setting up filtered replication in Outlook
Schema Flexibility
When you begin work on an application that connects to a database, you are usually forced to plan your schema for the database before you start writing your application. If the application's requirements change and a new field has to be added to the database, the schema might not be flexible enough to support the addition and you might have to drop your database and create a new one.
With the Exchange Server database, however, you can add new fields at any point in development, which means you can accommodate the changing requirements of an application. New fields are automatically available for users to include in custom views.
Transaction Logging
A transaction is a unit of work ”for example, adding an item to an Exchange Server database. Before any item is committed to the Exchange Server database, the transaction is written to a transaction log file. This process is called write-ahead transaction logging , and it guarantees that no item will be lost.
Transaction logs allow Exchange Server to recover the database after a failure such as a power loss. In this scenario, once power is restored and the server rebooted, Exchange Server automatically recovers the database using checkpoints in the transaction logs, to replay any transactions that were not committed to the database before the power failure.
The transaction log is an inherent feature of the Exchange Server database, so any application you develop on Exchange Server can take advantage of it. Any items your application sends or stores in the Exchange Server system will be delivered or committed, even in the event of certain failures in the computer system or network.
Multiple Databases
Exchange supports multiple databases on a single server. This support provides administrative flexibility because you can break out multiple mailbox databases on a single server and do a backup/restore on each of these mailbox databases individually. Multiple databases also give developers the flexibility of having multiple application databases on a single server.
EAN: 2147483647
Pages: 227