6.1 GPFS description
| < Day Day Up > |
| GPFS is a major component of the IBM clusters offering. Its purpose is to satisfy the needs of the most demanding applications in terms of I/O throughput and resilience. This is obtained by combining the processing power and disk bandwidth of selected nodes and making them available to the whole cluster. There are other file systems that can be used to provide shared and consistent access to files inside a cluster. Network File System (NFS) is still very much in use. However, if an NFS can be mounted on all the nodes in a cluster, the files are still served by a single node, and this quickly becomes a bottleneck. This single server architecture does not scale well when the number of client nodes increases . The open source community provides Parallel Virtual File System (PVFS [1] ), which uses concepts similar to GPFS. It can use any number of server nodes, each node using its own disks and disk adapters. It is known to work on pSeries Linux clusters, but lacks the high availability features of GPFS.
Here we describe the GPFS architecture and components and how they operate . However, this description is by no means exhaustive and the interested reader should refer to the following documentation for more information:
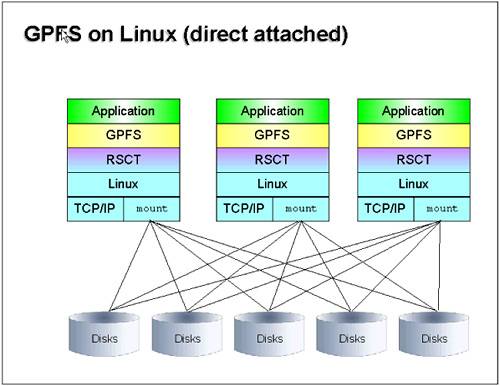
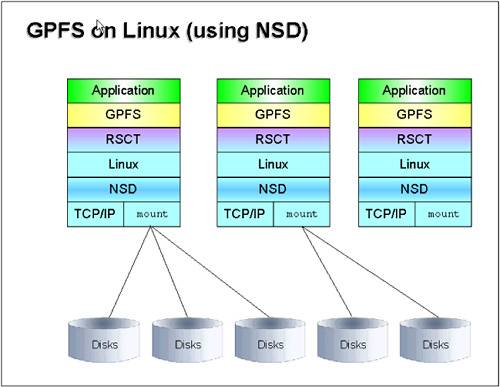
6.1.1 Principles of operationGPFS version 2.2 supports two modes of operation, depending on the type of attachment of the storage devices to the nodes: direct-attached disks, and Network Shared Disks. We describe these as follows :
Figure 6-1 illustrates the direct-attached disks mode of operation. Figure 6-1. GPFS with direct-attached disks The Network Shared Disks mode is shown in Figure 6-2 on page 282. Figure 6-2. GPFS with Network Shared Disks GPFS is implemented at the VFS level so that applications can use it transparently just like any other file system. GPFS also provides an API for applications that would like to benefit from some of the features that are not accessible through the UNIX file system interface. On AIX pSeries clusters, IBM Parallel Environment 4.1 implements the I/O part of the MPI 2 standard with GPFS, providing a very high performance parallel I/O environment for large parallel applications. 6.1.2 TerminologyGPFS defines various entities, as described here: GPFS clusterGPFS cluster identifies the collection of nodes that you intend to run GPFS on. GPFS clusters can be of different types, but the only type supported on Linux is the loose cluster type or "lc". AIX GPFS clusters can be of other types: hacmp in HACMP environments, or sp if defined on AIX clusters equipped with SP Switch or SP Switch 2. With the lc type, GPFS clusters can be interoperable between AIX and Linux on xSeries. Nodes in a GPFS cluster must use the same communication adapters. In the case of Linux on pSeries, only Ethernet is supported. GPFS nodesetA nodeset is a subset of the GPFS cluster, and this is where the file systems are defined. A node can only belong to one nodeset at a time. It is really where all the configuration takes place. Examples of attributes that are private to a GPFS nodeset are quorums, and the maximum size of the caching attributes of the file systems, and the communication protocol to use between the participating nodes. Failure groupA failure group identifies the set of disks that have a common point of failure. For example, two disks on the same adapter on the same node are part of the same failure group. This information is used by GPFS to decide on data placement in order to improve data availability. Indeed, there is no point to having two replicas on the same data in the same failure group, as they would both become unavailable in case of a failure. 6.1.3 ComponentsGPFS consists of the following components:
6.1.4 AdvantagesAs a general purpose file system, GPFS has several unparalleled features that we detail now. I/O performanceBy aggregating the individual I/O performance and processing power of many cluster nodes, GPFS can dramatically improve the disk throughput of serial and parallel applications. A sound design should make sure that you match the performance characteristics of all the components (nodes, disks, network or fiber adapters) to avoid bottlenecks. GPFS is at its best for large sequential I/O patterns, and it is the file system of choice for distributed applications that need to operate concurrent read and write operations on files. High availabilityWhen properly configured, GPFS provides a highly resilient file system. It can recover from failures at the disk, adapter, or node level. Node failure recovery is facilitated with three components of RSCT:
With data replication enabled, not only can the structure and operation of the file system be continuous, but the data can also be made highly available. FlexibilityDisks and nodes can be added on the fly to a GPFS nodeset. When it becomes more convenient from an operational point of view, the data can then be rebalanced between the various disks and nodes. |
| < Day Day Up > |
EAN: N/A
Pages: 108
- Challenging the Unpredictable: Changeable Order Management Systems
- The Effects of an Enterprise Resource Planning System (ERP) Implementation on Job Characteristics – A Study using the Hackman and Oldham Job Characteristics Model
- Distributed Data Warehouse for Geo-spatial Services
- Data Mining for Business Process Reengineering
- Healthcare Information: From Administrative to Practice Databases