7.2 Performance Characteristics of Quicksort
Despite its many assets, the basic quicksort program has the definite liability that it is extremely inefficient on some simple files that can arise in practice. For example, if it is called with a file of size N that is already sorted, then all the partitions will be degenerate, and the program will call itself N times, removing just one element for each call.
Property 7.1
Quicksort uses about N2/2 comparisons in the worst case.
By the argument just given, the number of comparisons used for a file that is already in order is
![]()
All the partitions are also degenerate for files in reverse order, as well as for other kinds of files that are less likely to occur in practice (see Exercise 7.6). 
This behavior means not only that the time required will be about N2/2 but also that the space required to handle the recursion will be about N (see Section 7.3), which is unacceptable for large files. Fortunately, there are relatively easy ways to reduce drastically the likelihood that this worst case will occur in typical applications of the program.
The best case for quicksort is when each partitioning stage divides the file exactly in half. This circumstance would make the number of comparisons used by quicksort satisfy the divide-and-conquer recurrence
![]()
The 2CN/2 covers the cost of sorting the two subfiles; the N is the cost of examining each element, using one partitioning index or the other. From Chapter 5, we know that this recurrence has the solution
![]()
Although things do not always go this well, it is true that the partition falls in the middle on the average. Taking into account the precise probability of each partition position makes the recurrence more complicated and more difficult to solve, but the final result is similar.
Property 7.2
Quicksort uses about 2N ln N comparisons on the average.
The precise recurrence formula for the number of comparisons used by quicksort for N randomly ordered distinct elements is
![]()
with C1 = C0 = 0. The N + 1term covers the cost of comparing the partitioning element with each of the others (two extra for where the indices cross); the rest comes from the observation that each element k is likely to be the partitioning element with probability 1/k, after which we are left with random files of size k - 1 and N - k.
Although it looks rather complicated, this recurrence is actually easy to solve, in three steps. First, C0 + C1 + ··· + CN-1 is the same as CN-1 + CN-2 + ··· + C0, so we have
![]()
Second, we can eliminate the sum by multiplying both sides by N and subtracting the same formula for N - 1:
![]()
This formula simplifies to the recurrence
![]()
Third, dividing both sides by N(N + 1) gives a recurrence that telescopes:
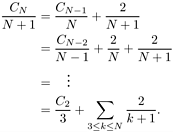
This exact answer is nearly equal to a sum that is easily approximated by an integral (see Section 2.3):
![]()
which implies the stated result. Note that 2N ln N 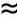 1N lg N, so the average number of comparisons is only about 39 percent higher than in the best case.
1N lg N, so the average number of comparisons is only about 39 percent higher than in the best case.
This analysis assumes that the file to be sorted comprises randomly ordered records with distinct keys, but the implementation in Programs 7.1 and 7.2 can run slowly in some cases when the keys are not necessarily distinct and not necessarily in random order, as illustrated in Figure 7.4. If the sort is to be used a great many times or if it is to be used to sort a huge file (or, in particular, if it is to be used as a general-purpose library sort that will be used to sort files of unknown characteristics), then we need to consider several of the improvements discussed in Sections 7.5 and 7.6 that can make it much less likely that a bad case will occur in practice, while also reducing the average running time by 20 percent.
Figure 7.4. Dynamic characteristics of quicksort on various types of files
The choice of an arbitrary partitioning element in quicksort results in differing partitioning scenarios for different files. These diagrams illustrate the initial portions of scenarios for files that are random, Gaussian, nearly ordered, nearly reverse ordered, and randomly ordered with 10 distinct key values (left to right), using a relatively large value of the cutoff for small subfiles. Elements not involved in partitioning end up close to the diagonal, leaving an array that could be handled easily by insertion sort. The nearly ordered files require an excessive number of partitions.
Exercises
7.6 Give six files of 10 elements for which quicksort (Program 7.1) uses the same number of comparisons as the worst-case file (when all the elements are in order).
7.7 Write a program to compute the exact value of CN, and compare the exact value with the approximation 2N ln N, for N = 103, 104, 105, and 106.
N equal elements?
7.9 About how many comparisons will quicksort (Program 7.1) make when sorting a file consisting of N items that have just two different key values (k items with one value, N - k items with the other)?
7.10 Write a program that produces a best-case file for quicksort: a file of N distinct elements with the property that every partition will produce subfiles that differ in size by at most 1.
| Top |
EAN: 2147483647
Pages: 158