Using Nonblocking Handles with Line-Oriented I/O As explained in Chapter 12, it's dangerous to mix line-oriented reads with select() because the select call doesn't know about the contents of the stdio buffers. Another problem is a line-oriented read blocks if there isn't a complete line to read; as soon as any I/O operation blocks, a multiplexed program stalls. What we would like to do is to change the semantics of the getline() call so that we can distinguish among three distinct conditions: -
A complete line was successfully read from the filehandle. -
The filehandle has an EOF or an error. -
The filehandle does not yet have a complete line to read. The standard Perl <> operator and getline() functions handle conditions 1 and 2 well, but they block on condition 3. Our goal is to change this behavior so that getline() returns immediately if a complete line isn't ready for reading but distinguishes this event from an I/O error. The IO::Getline module that we develop here is a wrapper around a filehandle or IO::Handle object. It has a constructor named new() and a single object method named getline() . | $wrapped = IO::Getline->new ($filehandle) This creates a new nonblocking getline wrapper. new() takes a single argument, either a filehandle or member of the IO::Handle hierarchy, and returns a new object. $result = $wrapped->getline($data) The getline() method reads a line of text from the wrapped filehandle and places it into $data , returning a result code that indicates the success or failure of the operation. $error = $wrapped->error This returns the last I/O error on the wrapper, or 0 if no error has been encountered . $wrapped->flush This returns the object to a known state, discarding any partially buffered data. $fh = $wrapped->handle This returns the filehandle used to construct the wrapper. | Notice that getline() acts more like read() or sysread () than the traditional <> operator. Instead of returning the read line directly, it copies the line into the $data argument and returns a result code. Table 13.1 gives the possible result codes from getline() . Table 13.1. Result Codes from the IO::Getline getline() Method | Outcome of Operation | Result Code | | Full line read | Length of line | | End of file | | | Operation would block | 0E0 | | Other I/O errors | undef | getline() returns the length of the line (including the newline) if it successfully read a line of text, if it encountered the end of file, and undef on other errors. However, there is an additional result code returned when getline() detects that the operation would block. In this case, the method returns the string 0E0 . As described in Chapter 8, when evaluated in a numeric context, 0E0 acts like 0 (it is treated as the floating point number 0. 0E0 ). However, when used in a logical context, 0E0 is true. You can interpret this result code as meaning "Zero but true." In other words, "no error yet; try again later." In addition to the getline() method, you can call any method of the wrapped filehandle object. IO::Getline simply passes the method call to the underlying object. This lets you call methods such as sysread() and close() directly on the getline object. Using IO::Getline IO::Getline is designed to be used in conjunction with select() . Because it never blocks, you can't use it simply as a plug-in replacement for the <> operator. To illustrate the intended use of IO::Getline, Figure 13.1 shows a small program that combines select() with IO::Getline to read from STDIN in a line-oriented way. We load the IO::Getline and IO::Select modules and create an IO::Select set containing the STDIN filehandle. We then call IO::Getline->new() to create a new nonblocking getline object wrapped around STDIN . Figure 13.1. Reading from STDIN with IO::Getline 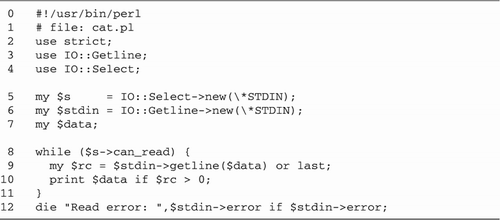 We now enter a select loop. Each time through the loop we call the select object's can_read() method, which returns true when STDIN has data to read from. Rather than read from STDIN with <> , we call the getline object's getline() method to read the line into $data. getline() may return a false value, in which case we exit the loop because we have reached the end of file. Or it may return a true result. If the result code is greater than , then we have a line to print, so we copy it to standard output. Otherwise, we know that a complete line hasn't yet been read, so we go back to the top of the select loop. At the end of the loop, we call the wrapper's error() method to see if the loop terminated abnormally. If so, we die with an error message that contains the error code. IO::Getline objects can also be used in blocking fashion. To do this is simply a matter of calling the object's blocking() method. The method is automatically passed down to the underlying filehandle: stdin->blocking(1); # turn blocking behavior back on We use this module in more substantial programs in Chapter 17's TCP Urgent Data section, and in Chapter 18's The UDP Protocol section. The IO::Getline Module The IO::Getline module (Figure 13.2) illustrates the general technique for buffering partial reads from a nonblocking filehandle. Figure 13.2. The IO::Getline module  Lines 1 “9: Set up module We load the IO::Handle and Carp modules and bring in the EWOULDBLOCK error code from Errno. Another constant sets the size of the chunks that we will sysread() from the underlying filehandle. The Carp module provides error messages that indicate the location of the error from the caller's point of view, and is therefore preferred for use inside modules. Lines 10 “22: The new() method This is the constructor for new objects. We take the handle passed to us from the caller, mark it nonblocking, and incorporate it into a new blessed hash under the handle field. In addition, we define an internal area for buffering incoming data, stored in the buffer field, an index to use when searching for the end-of-line sequence stored in the index field, and two flags. The eof flag is set when we encounter an end-of-file condition, while error is set when we get an error. Lines 23 “30: The AUTOLOAD method AUTOLOAD is a subroutine that Perl invokes automatically when the caller tries to invoke a method that isn't defined in the module. We define this as a courtesy . The code just passes on the method call and arguments to the wrapped filehandle and returns an error if the method call fails. Line 31: The handle() accessor This method returns the wrapped filehandle if the caller wishes to gain low-level access to it. Line 32: The error() accessor If an error occurs during a getline() operation, this method returns its error number. Lines 33 “37: The flush() method The flush() method returns the object to a known state, emptying any partially buffered lines in the buffer field and setting index to . Lines 38 “77: The getline() method This is the interesting part of the module. At the time of entry, $_[0] (the first argument in the @_ array of subroutine arguments) contains the scalar variable that will receive the read line. To change the variable in the caller's code, we refer to $_[0] directly rather than copy it into a local variable in the usual way. Because we operate in a buffered way, we must be prepared to report to the caller conditions that occurred earlier. We start by checking our eof and error flags. If we encountered the EOF on the last call, we return numeric . Otherwise, if there was an error, we return undef . There may already be a complete line in our internal buffer left over from a previous read. We use Perl's built-in index() function to find the next end-of-line sequence in the buffer, returning its position. Instead of hard coding the newline character, we use the current contents of the $/ global. In addition, we can optimize the search somewhat by remembering where we left off the previous time. This information will be stored in the index field. We store the result of index() into a local variable, $i . Lines 49 “59: Read more data and handle errors If the end-of-line sequence isn't in our buffered data, then $i will be -1. In this case, we need to read more data from the filehandle and try again. We remember in index where the line-end search left off the previous time, and invoke sysread() , using arguments that cause the newly read data to be appended to the end of the buffer. If sysread() returns undef , it may be for any of a variety of reasons. Because it is nonblocking, one possibility is that we got an EWOULDBLOCK error. In this case, we cannot return a complete line at the current time, so we return 0E0 to the caller. Otherwise, we've encountered some other kind of I/O error. In this case, we return whatever is left in the buffer, even if it isn't a complete line. This is identical to the behavior of the <> operator, which returns a partial line on an error. We set our error flag and return the length of the result. Note that the caller won't actually see this undef result until the next call to getline() . Lines 54 “59: Handle EOF We take a similar strategy on EOF. In this case the sysread() result code is defined by . We return what we have left in the buffer, remember the condition in our eof flag, and return the size of the buffer contents. Lines 65 “77: Try for the end of line again If we get to this point, then sysread() appended one or more new bytes of data to our buffer. We now call index() again to see if an end-of-line sequence has appeared. If not, we remember where we stopped the search the last time and return 0E0 to the caller. Otherwise, we've found the end of line. We copy everything from the beginning of the buffer up through and including the end-of-line sequence into the caller's scalar, and then delete the part of the buffer we've used. We reset the index field to and return the length of the line. | 