Section 13.11. High Availability Disaster Recovery
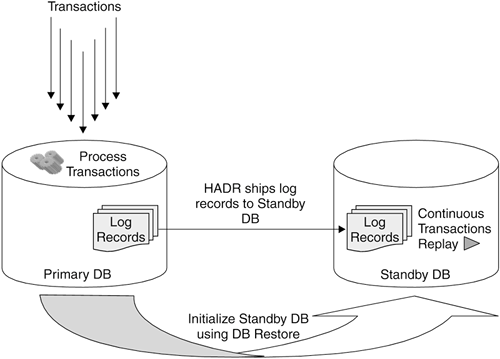
High Availability Disaster Recovery (HADR) uses log record shipping to keep a standby database in synch with your primary database. Then if that primary server fails, your applications can automatically switch their processing to the secondary server with absolutely no data loss. 13.11.1. Overview of HADRDB2 High Availability Disaster Recovery (HADR) is a database replication feature that provides a high-availability and disaster recovery solution for complete as well as partial site failures. HADR is available as part of DB2 Enterprise Server Edition, and as an additional cost option on DB2 Workgroup Server Edition and DB2 Express Edition. In an HADR environment you will have two database servers, the primary and secondary. The primary server is where the source database is stored and accessed (see Figure 13.10). As transactions are processed on the source database server, database log records are automatically shipped to the secondary server. The secondary server has a database that is cloned from the source database, typically by backing up the database and restoring it. When HADR is started, log records are captured on the primary database and sent to the secondary database. Once received they are replayed on the secondary database. Through continuous replay of the log records, the secondary database keeps an in-synch replica of the primary database and acts as a standby database. Figure 13.10. Overview of HADR
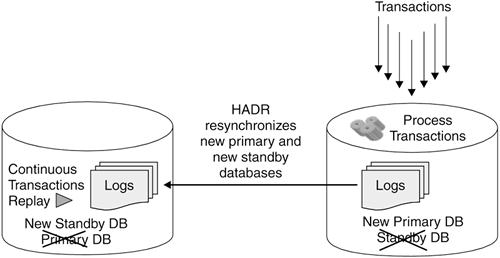
When a failure occurs on the primary database, the standby database takes over the transactional workload and becomes the new primary database (see Figure 13.11). If the failed server later becomes available again, it can be resynchronized to catch up with the new primary database and the transactions that have been performed. At this time the former primary database now becomes the new standby database (see Figure 13.12). Figure 13.11. Standby database taking over primary database role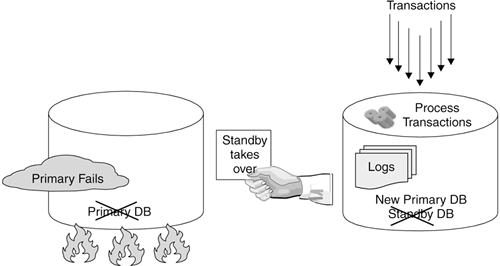 Figure 13.12. New standby database resynchronizes and catches up with the new primary DB
13.11.2. Overview of HADR SetupNow that you understand how HADR works, let's take a closer look at the steps for setting up HADR. 13.11.2.1 Preparing the Primary and Standby Databases for HADRAfter you have identified the HADR pair (i.e., the primary and standby databases), you need to enable archival logging on the primary database (see section 13.2.4.2, Archival Logging). You also need to configure the database configuration parameters that are related to HADR on the primary and standby databases. Table 13.3 lists these parameters.
13.11.2.2 Cloning the Primary DatabaseYou can clone the primary database by taking a full database backup of the primary database, copy the backup image to the standby system, and restore it to a new or existing standby database. After the database restore, the standby database is placed in roll forward pending state. This means that the standby database will not be active to process any read or write transactions until it takes over the primary database role in the event of a failover. Note that strict symmetry of table space and container configuration is required on the standby database. The name, path, and size of the containers must match the primary database. If any of the configurations do not match, HADR may fail to replicate the data to the standby database. 13.11.2.3 Starting the Standby DatabaseWhen the standby database is started, it enters the local catch-up state. Pending log records (if any) will be replayed on the standby database (see Figure 13.13). Figure 13.13. States of the standby database
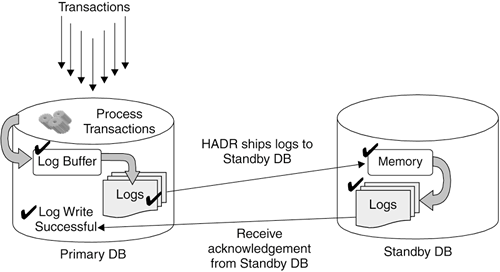
When the end of any local pending log records is reached, the standby database enters the remote catch-up state. It replays log records from the primary database until the standby database is caught up. The primary database must be active for the standby database to be in the remote catch-up state. When all of the log records on the primary system have been replayed, the primary and standby databases enter the peer state, which is when log records are shipped and applied to the standby database whenever the primary database flushes these log records to disk. You can specify one of the three synchronization modes to protect from potential loss of data (see section 13.11.3, Synchronization Modes). 13.11.2.4 Starting the Primary DatabaseWhen the primary database is started, the primary server waits for the standby server to contact it. If the standby server does not make a contact with the primary server after a period of time, HADR will not start. You can configure this timeout period using the HADR_TIMEOUT configuration parameter (see Table 13.3). This configuration avoids having two systems starting up as the primary server at the same time. 13.11.3. Synchronization ModesRecall that when the HADR-enabled databases are in the peer state, log pages that are flushed to the log file on disk at the primary database are shipped and applied to the standby database. To indicate how log writing is managed between the primary and standby databases, you specify the synchronization mode. There are three synchronization modes: SYNC (Synchronous), NEARSYNC (Near Synchronous), and ASYNC (Asynchronous). In synchronous (SYNC) mode, log writes are considered successful only when:
Figure 13.14 shows how the log records are built on the primary server and sent to the secondary server. They are processed on both servers to keep the databases in synch. The application will not be able to proceed until both servers have been updated. Figure 13.14. Synchronization mode: SYNC
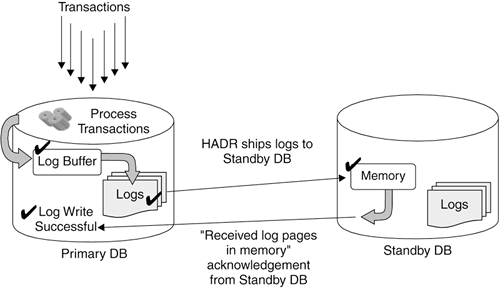
Log records in the primary and standby database are almost (NEARSYNC) asynchronous because log writes are considered successful only when:
Figure 13.15 shows how the log records are built on the primary server and sent to the secondary server. As soon as the log record is received on the secondary database, the application can continue with other operations. Figure 13.15. Synchronization mode: NEARASYNC
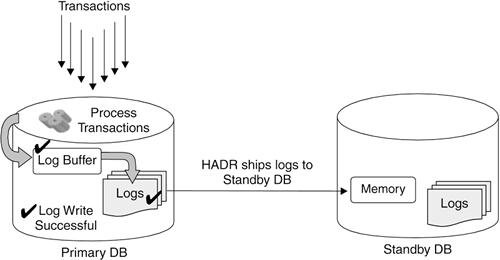
In ASYNC mode, the primary database does not wait for acknowledgement from the standby database. Log writes are considered successful only when:
Figure 13.16 shows how the log records are built on the primary server and sent to the secondary server. As soon as the log record is sent to the secondary database, the application can continue with other operations. Figure 13.16. Synchronization mode: ASYNC
13.11.4. The HADR WizardAs you can see, the HADR is a powerful feature that you can use to implement a high-availability solution. Like any other technology, it needs an interface so that users can exploit its features more efficiently. The HADR Wizard is user-friendly graphical tool that helps you set up, configure, and manage the HADR databases. The HADR Wizard guides you through the tasks required to set up the HADR environment, stopping and starting HADR, and switching database roles in HADR. To launch the wizard, go to the Control Center, right-click on the database, and select High Availability Disaster Recovery. As shown in Figure 13.17, you can choose to set up or manage HADR. Figure 13.17. Launching the HADR Wizard from the Control Center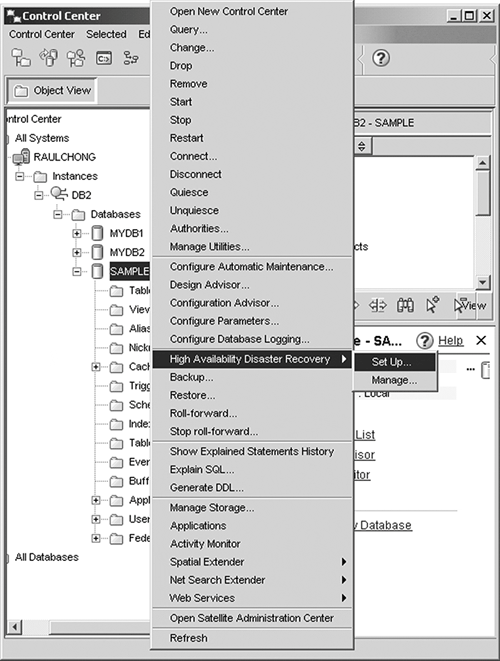 Choosing Set Up launches the HADR Wizard, as shown in Figure 13.18, which will step you through the process. Figure 13.18. Setting up the HADR environment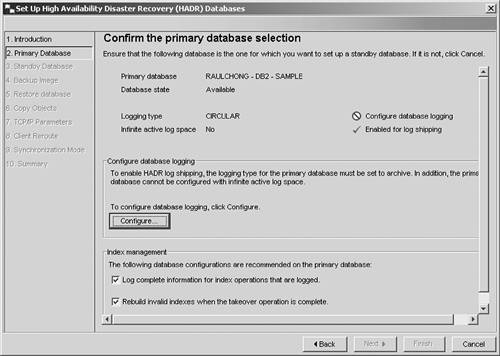 |

EAN: 2147483647
Pages: 313