20.1 Access Control Strategies
| only for RuBoard - do not distribute or recompile |
20.1 Access Control Strategies
There are a number of techniques that can be used to control access to web-based information:
-
Restricting access by using URLs that are "secret" that is, URLs that are hidden and unpublished
-
Restricting access to a particular group of computers based on those computers' hostnames or Internet addresses
-
Restricting access to a particular group of users based on their identity
Most web servers can use these techniques to restrict access to HTML pages, CGI scripts, and API-invoking files. These techniques can be used alone or in combination. You can also add additional access control mechanisms to your own CGI and API programs.
20.1.1 Hidden URLs
The easiest way to restrict access to information and services is by storing the HTML files and CGI scripts in hidden locations on your web server.
For example, when Simson's daughter Sonia was born, he wanted to quickly put some photographs of her on the World Wide Web so that his friends and family could see them, but he didn't want to "publish" them so that anybody could look at them. Unfortunately, he didn't have the time to give usernames and passwords to the people he wanted to see the pictures. So Simson simply created a directory on his web server named http://simson.vineyard.net/sonia/ and put the photographs inside. Then he sent the URL to his parents, his in-laws, and a few other networked friends.
Hidden URLs are about as secure as a key underneath your door mat. Nobody can access the data unless they know where to look; then they have access to all that they want. Furthermore, this information is transitive. You might tell John about the URL, and John might tell Eileen, and Eileen might post it to a mailing list of her thousand closest friends. Somebody might put a link to the URL on another web page or even register the hidden URL with a web search engine.
Indeed, search engines such as Lycos, AltaVista, and Google pose a special problem for hidden URLs. Most search engines "spider" the Web by retrieving a page, indexing its content, analyzing the page for links, and then repeating the process with every page that is referenced by a link. If you have no links to a "secret" page, the search engines will generally not find it. However, if there is a single link to your page's hidden URL on any other page that is indexed by a search engine, it is likely that your hidden URL will be indexed as well. This can happen even if the page that linked to your hidden URL is later deleted; the links can still be active in the search engine's databanks. We've found lots of interesting and "hidden" pages by searching with keywords such as secret, confidential, proprietary, and so forth.
In general, avoid using secret URLs if you really care about maintaining the confidential nature of your page.
|

20.1.2 Host-Based Restrictions
Most web servers allow you to restrict access to particular directories from specific computers located on the Internet. You can specify these computers by their IP addresses or by their DNS hostnames.
Restricting access to IP-specific addresses or a range of IP addresses on a subnet is a relatively simple technique for limiting access to web-based information. This technique works well for an organization that has its own internal network and wishes to restrict access to people on that network. For example, you might have a network that has the IP addresses 204.17.195.1 through 204.17.195.254; by configuring your web server so that certain directories are accessible only to computers on network 204.17.195, you prevent outsiders from accessing information in those directories. This is a practical technique for many organizations that use Net 10 (10.0.0.0 through 10.255.255.255) behind their firewalls.
RFC 1918 reserves three blocks of IP address space for private addressing. These addresses are shown in Table 20-1.
| Range | Prefix notation | # of Hosts |
|---|---|---|
| 10.0.0.0-10.255.255.255 | 10/8 | 16,777,214 |
| 172.16.0.0-172.31.255.255 | 172.16/12 | 10,48,574 |
| 192.168.0.0 -192.168.255.255 | 192.168/16 | 65,534 |
According to RFC 1918:
An enterprise that decides to use IP addresses out of the address space defined in RFC 1918 can do so without any coordination with IANA or an Internet registry. The address space can thus be used by many enterprises. Addresses within this private address space will only be unique within the enterprise, or the set of enterprises which choose to cooperate over this space so they may communicate with each other in their own private internet.
Because private addresses have no global meaning, routing information about private networks shall not be propagated on inter-enterprise links, and packets with private source or destination addresses should not be forwarded across such links. Routers in networks not using private address space, especially those of Internet service providers, are expected to be configured to reject (filter out) routing information about private networks. If such a router receives such information the rejection shall not be treated as a routing protocol error.
Instead of specifying computers by IP address, most web servers allow you to restrict access on the basis of DNS domains. For example, your company may have the domain company.com and you may configure your web server so any computer that has a name of the form *.company.com can access your web server. Specifying client access based on DNS domain names has the advantage that you can change your IP addresses and you don't have to change your web server's configuration file as well. (Of course, you will have to change your DNS server's configuration files, but you would have to change those anyway.)
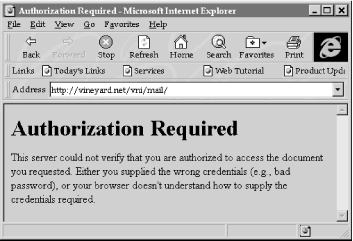
The advantage of host-based restrictions is that they are largely transparent to users. If a user is working from a host that is authorized and she clicks on a URL that points to a restricted directory, she sees the directory. If the user is working from a host that is not authorized and she clicks on the URL that points to a restricted directory, the user sees a standard message that indicates that the information may not be viewed. A typical message is shown in Figure 20-1.
Figure 20-1. Access denied
|
20.1.2.1 Using firewalls to implement host-based access control
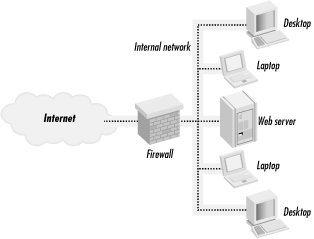
You can also implement host-based restrictions using a firewall to block incoming HTTP connections to particular web servers that should only be used by people inside your organization. Such a network is illustrated in Figure 20-2.
Figure 20-2. Using a firewall to implement host-based restrictions; access to the internal web server is blocked by the firewall.
20.1.2.2 Caveats with host-based access control
Host-based addressing is not foolproof:
-
IP spoofing can be used to transmit IP packets that appear to come from a different computer from the one they actually do come from. This is not a risk for static content such as HTML files, since the server will be unable to send the response back to the attacker. However, spoofed IP packets are a concern for programs executed by web servers (e.g., CGI and ASP scripts).
-
Host-based access control will not protect information from attackers who enter an organization's network using a remote-access system such as Carbon Copy, Windows NT RAS, VPNs, or IP tunneling. In these cases, the attacker's computer will appear to be behind your firewall, even though the attacker's computer may actually be located elsewhere.
-
Host-based addressing that is based on DNS names requires that you have a secure DNS server. Otherwise, an attacker could simply add his own computer to your DNS domain, and thereby gain access to the confidential files on your web server.
20.1.3 Identity-Based Access Controls
Restricting access to your web server based on usernames is one of the most effective ways of controlling access. Each user is given a username and a password. The username identifies the person who wishes to access the web server, and the password authenticates the person.
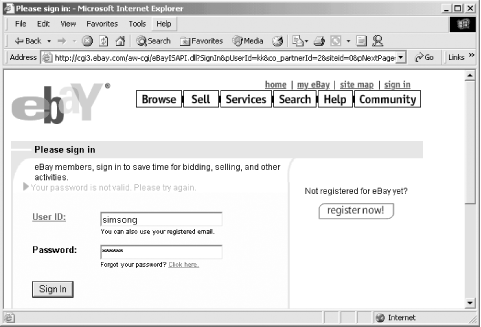
When a user attempts to reference an access-controlled part of a web site, the web server requires the web browser to provide a username and password. The web browser recognizes this request and displays a request, such as the one shown in Figure 20-3.
Figure 20-3. Prompt for user's password
Because passwords are easily shared or forgotten, many organizations are looking for alternatives to them. One approach is to use public key technology. Another approach is to give authorized users a physical token, such as a smart card, which they must have to gain access. Most of these systems merely require that the users enter their normal username and a different form of password. For example, users of the RSA Security SecurID card enter a password that is displayed on their smart cards; the password changes every minute.
One of the advantages of user-based access controls over host-based controls is that authorized users can access your web server from anywhere on the Internet. A sales force that is based around the country or around the world can use Internet service providers to access the corporate web site, rather than having to place long distance calls to the home office. Or you might have a sales person click into your company's web site from a high-speed network connection while visiting a client.
User-based access can also be implemented through the use of cookies (see Section 8.4).
| only for RuBoard - do not distribute or recompile |
EAN: 2147483647
Pages: 194