11.6 Network Backup Systems
| So far, we've considered onlybackups and restores of disks on a local computer system. However, many organizations need to take a more unified and comprehensive approach to their total backup needs. We will consider various available solutions for this problem in this section. 11.6.1 Remote Backups and RestoresThe simplest way to move beyond the single-system backup view is to consider remote backup and restores. It is very common to want to perform a backup over the network. The reasons are varied: your system may not have a tape drive at all since not all systems come with one by default any more, there may be a better (faster, higher capacity) tape drive on another system, and so on. Most versions of dump and restore can perform network-based operations (Tru64 requires you to use the separate rdump and rrestore commands). This is accomplished by specifying a device name of the form host:local_device as an argument to the -f option. The hostname may also optionally be preceded by a username and at-sign; for example, -f chavez@hamlet:/dev/rmt1 performs the operation on device /dev/rmt1 on host hamlet as user chavez. This capability uses the same network services as the rsh and rcp commands. Remote backup facilities depend on the daemon /usr/sbin/rmt (which is often linked to /etc/rmt).[18] To be allowed access on the remote system, there needs to be a .rhosts in its root directory, containing at least the name of the (local) host from which the data will come. This file must be owned by root, and its mode must not allow any access by group or other users (for example, 400). This mechanism has the mechanism's usual negative security implications (see Section 7.6).
The HP-UX fbackup and frestore utilities accept remote tape drives as arguments to the normal -f option. For example: # fbackup -0u -f backuphost:/dev/rmt/1m -i /chem 11.6.2 The Amanda FacilityAmanda is theAdvanced Maryland Automated Network Disk Archiver. It was developed at theUniversity of Maryland (James da Silva was the initial author). The project's home page is http://www.amanda.org, where it can be obtained free of charge. This section provides an overview of Amanda. Consult Chapter 4 of Unix Backup and Recovery for a very detailed discussion of all of Amanda's features (this chapter is also available on the Amanda home page). 11.6.2.1 About AmandaAmanda allows backups from a network of clients to be sent to a single designated backup server. The package operates by functioning as a wrapper around native backup software like GNU tar and dump. It can also back up files from Windows clients via the Samba facility (smbtar). It has a number of nice features:
At present, Amanda does have a couple of annoying limitations:
11.6.2.2 How Amanda worksAmanda uses a combination of full and incremental backups to save all of the data for which it is responsible, using the smallest possible daily backup set that can do so. Its scheme first computes the total amount of data to be backed up. It uses this total, along with a couple of parameters defined by the system administrator, to figure out what to do in the current run. These are the key parameters:
Amanda's overall strategy is twofold: to complete a full backup of the data within each cycle and to be sure that all changed data has been backed up between full dumps. The traditional method of doing this is to perform the full backup followed by incrementals on the days between them. Amanda operates differently. Each run (night), Amanda performs a full backup of part of the data, specifically, the fraction that is required to back up the entire data set in the course of a complete backup cycle. For example, if the cycle is 7 days long (with one run per day), 1/7 of the data must be backed up each day to complete a full backup in 7 days. In addition to this "partial" full backup, Amanda also performs incremental backups for all data that has changed since its own last full backup. Figure 11-1 illustrates an Amanda backup cycle lasting 4 days, in which 15% of the data changes from day to day. The box at the top of the figure stands for the complete set of data for which Amanda is responsible; we have divided it into four segments to represent the part of the data that gets a full backup at the same time. Figure 11-1. The Amanda backup scheme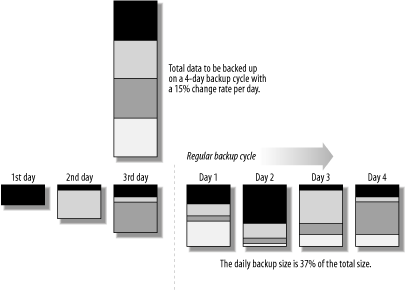 The contents of the nightly backups are shown at the bottom of the figure. The first three days represent a start-up period. On the first night, the first quarter of the data is fully backed up. On the second night, the second quarter is fully backed up, and the 15% of the data from the previous night that changed during day 2 is also saved. On day 3, the third quarter of the total data is fully backed up, as well as the changed 15% of day 2's backup. In addition, 15% of the portion backed up on the first night is written for each of the intervening nights since its full backup: in other words, 30% of that quarter of the total data. By day 4, the normal schedule is in force. Each night, one quarter of the total data is backed up in full, and incrementals are performed for each of the other quarters as appropriate to the time that has passed since their last full backup.
To restore files from an Amanda backup, you may need one complete cycle of media. Let's now consider a numeric example. Suppose we have 100 GB of data that we need to back up. Table 11-3 illustrates four Amanda backup schedules based on differing cycle lengths and per-day change percentages.
The table columns illustrate the data that would comprise each daily backup, breaking it down by the full backup portion and the incremental data from each previous full backup within the cycle. Note that Amanda computes what should be backed up every time it is run, so it is not as static as the preceding examples suggest, but the examples nevertheless provide a general picture of how the facility operates. In the next section, we consider how the backup size depends on the backup cycle more formally, including some expressions that can be used to decide on an appropriate backup cycle for specific conditions. NOTE
You can use the find command to help estimate the daily change rate: $ find dir -newer /var/adm/yesterday -ls | \ awk '{sum+=$7}; END {print "diff =",sum}' Repeat the command as needed to cover all the data to be backed up. Use touch to update the time for the file /var/adm/yesterday after all the find commands are run. Then, divide this value by the total used space (e.g., taken from df output). Repeat the process for several days or weeks to determine an average rate. 11.6.2.3 Doing the mathNext, we consider some expressions that can be used to compute starting parameters forAmanda (which can be fine-tuned over time, based on actual use). If this sort of mathematical analysis is of no interest to you, just skip this section. We will use the following variables:
To compute per-run amount of data that must be backed up, use this expression for S: 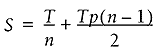 For example, 70 GB of data that changes by 10% per day using a 1 week backup cycle requires that 31 GB be backed up every night (70/7 + 70 x 0.1 x 6/2 = 10 + 42/2 = 10 + 21 = 31). If 31 GB is larger than the maximum capacity that you have in the available time, you'll need to adjust the other parameters (see below). Alternatively, if you have a fixed amount of backup capacity per run, you can figure out the required cycle length. Refer to the discussion of capacity planning earlier in this chapter for information on determining how much capacity you have. To compute n for a given nightly capacity, use this expression: where We have introduced the variable x to make the expression for n simpler. Suppose that you have a nightly backup capacity of 40 GB for the same scenario (70 GB total data, changing at 10% per day). Then x = 0.1/2 + 40/70 = 0.05 + 0.57 = 0.62. We can now compute This calculation yields solutions of 2 and 11 (rounding to integers). We can either do full backups of about half the data every night or use a much longer 11-day cycle and still be able to get the backups all done. Note that these values take maximum advantage of the available capacity. Now suppose that you have a nightly backup capacity of only 20 GB for the same scenario (70 GB total data, changing at 10% per day). Then x = 0.1/2 + 40/70 = 0.05 + 0.29 = 0.34. We can now compute
In general, you can compute the minimum per-run capacity for a given per-run percentage change (p) with this expression (which introduces F as the fraction of the total data that must be backed up): F indicates the fraction of that data that must be backed up each run in order for the system to succeed. So, in our case of a 10% change rate, Alternatively, you can compute the run cycle n that is required to minimize F (and thus S) for a given value of p with this expression:[20]
In our case, the cycle period which minimizes the amount of data to be backed up is Thus, both the minimum time cycle and per-run fraction of data to back up are determined only by the rate at which the data is changing, and the actual per-run backup size for a given amount of total backup data can be easily computed from them. Thus, having an accurate estimate for p is vital to rational planning.
11.6.2.4 Configuring AmandaBuilding and installing Amanda is generally straightforward, and the process is well-documented, so we will not consider it here. TheAmanda system includes the following components:
11.6.2.4.1 Setting up an Amanda clientOnce you have installed the Amanda software on a client system, there are a few additional steps to take. First, you must add entries to the /etc/inetd.conf and /etc/services files to enable support for theAmanda network services: /etc/services: amanda 10080/udp /etc/inetd.conf: amanda dgram udp wait amanda /path/amandad amandad The Amanda daemon runs as user amanda in this example; you should use whatever username you specified when you installed the Amanda software. In addition, you'll need to ensure that all the data that you want to be backed up is readable by the Amanda user and group. Similarly, the file /etc/dumpdates must exist and be writeable by the Amanda group. Finally, you must set up the authorization scheme that amandad will use. This is usually selected at compile time. You may use normal .rhosts-based authentication, Kerberos authentication (see below) or a separate .amandahosts (the default mechanism). The .amandahosts file is similar to a .rhosts file, but it applies only to the Amanda facility and so does not carry the same level of risk. Consult the Amanda documentation for full information about authentication options. 11.6.2.4.2 Selecting an Amanda serverSelecting an appropriate system as theAmanda server is crucial to good performance. You should keep the following items in mind:
11.6.2.4.3 Setting up the Amanda serverThere are several steps necessary to configure the Amanda server once the software is installed. First of all, you must add entries to the same network configuration files as those for Amanda clients: /etc/services: amanda 10080/udp amandaidx 10082/tcp amidxtape 10083/tcp /etc/inetd.conf: amandaidx stream tcp nowait amanda /path/amindexd amindexd amidxtape stream tcp nowait amanda /path/amidxtaped amidxtaped Next, you must configure Amanda by creating the required configuration files. Create a new subdirectory under etc/amanda in the top-level Amanda directory (i.e., /usr/local or /), if necessary. We will use Daily as our example. Then, create and modify amanda.conf and disklist configuration files in this subdirectory (the Amanda package contains example files that can be used as a starting point). We will begin with amanda.conf and consider its contents in groups of related entries. We will examine an annotated sample amanda.conf file. The initial entries in the file typically specify information about the local site and locations of important files: org "ahania.com" Organization name for reports. mailto "amanda-rep" Mail reports to this user. dumpuser "amanda" Amanda user account. printer "tlabels" Printer for tape labels. logdir "/var/log/amanda" Put log files here. indexdir "/var/adm/amindex" Store backup set index data here. The next few entries specify the basic parameters for the backup procedure: # fundamental parameters dumpcycle 7 days Length of the backup cycle (default=10 days). runspercycle 5 Amanda runs per cycle (if < 1/day). # network-related resource settings netusage 400 kps Maximum network bandwidth (default=300). inparallel 20 Max. simultaneous backups (default=10). ctimeout 120 Client timeout period (default=30 seconds). # incremental level bump parameters bumpsize 20 mb Min. savings for level 2 incrs. (default=10). bumpdays 1 Required # days at each level (default=2). bumpmult 2 Multiply bumpsize by this for each higher incremental level (default=1.5). The incremental bump level parameters specify when Amanda should increase the incremental backup level in order to make the backup set size smaller. Using these settings, Amanda will switch from level 1 incrementals to level 2 incrementals whenever it will save at least 20 MB of space. The multiplication factor has the effect of requiring additional savings to move to each higher incremental level. The threshold for each level is this factor times the saving required for the previous level, i.e., 40 for levels 2 to 3, 80 for levels 3 to 4, and so on. This strategy is designed to ensure that the added complexity of multiple levels of incremental backups also bring significant savings in the size of the backup set. These next entries specify information about the tape drive and media to use: # number of tapes in use Set to at least # tapes required for one full cycle tapecycle 25 plus a few spares (default=15). labelstr "Daily[0-9][0-9]*" Format of the table labels (regular expression). tapedev "/dev/rmt/0" tapetype "DLT" #changerdev "/dev/whatever" #tpchanger "script-path" Script to change to next tape (supplied). #runtapes 4 Maximum number of tapes per run. The first two entries specify the number of tapes in use and the pattern used by their electronic labels. Note that tapes must be prepared with amlabel prior to use (discussed below). The next two entries specify the location of the tape drive and its type. The final three entries are used with tape changers and are commented out in this example. Only one of tapedev and tpchanger must be used. Tape types are defined elsewhere in the configuration file with stanzas like this: define tapetype DLT { comment "DLT with 10 GB tapes" length 12500 mb Tape capacity (takes compression into account). speed 1536 kps Drive speed. lbl-templ "file" PostScript template file for printed labels. } The example configuration file includes many defined tape types. The length and speed parameters are used only for estimation purposes (e.g., how many tapes will be required). When performing the actual data transfer to tape, Amanda will keep writing until it encounters an end-of-tape mark. The following entry and holdingdisk stanza defines a disk holding area: # When media is unavailable, save this % of holding space # for degraded-mode incremental backups. reserve 50 Default is 100%. holdingdisk amhold0 { Name is amhold0. comment "Primary holding disk" directory "/scratch/amanda" # amount of space to use (+) or save (-); 0=use all (default) use -2 Gb Always leave this much space. } More than one holding disk may be defined. The final task to be done in the configuration file is to define various dump types: generalized backup actions having specific characteristics (but independent of the data to be backed up). Here is an example for the normal backup type (you can choose any names you like): define dumptype normal { comment "Ordinary backup" holdingdisk yes Use a holding disk. index yes Maintain index info on contents. program "DUMP" Backup command. priority medium Specify backup relative priority. # use 24-hour clock without punctuation starttime 2000 Don't begin backup before this time (8 P.M. here). } This dump type uses a holding disk, creates an index for the backup set contents for interactive restoration and uses the dump program to perform the actual backup. It runs at medium priority compared to other backups (the possibilities are low (0), medium (1), high (2) and an arbitrary integer, with higher numbers meaning the backup will be performed sooner). Backups using this method will not begin before 8 pm regardless of when the amdump command is issued. Amanda provides several pre-defined dump types in the example amanda.conf file which can be used or customized as desired. Here are some other parameters that are useful in dump type definitions: program "GNUTAR" Use the GNU tar program for backups. This is also the value to use for Samba backups. exclude ".exclude" GNU tar exclusion file (located in top-level of the filesystem to be backed up). compress server "fast" Use software compression on server using the fastest compression method. Other keywords are "client" and "best". auth "krb4" Use Kerberos 4 user authentication. kencrypt yes Encrypt transmitted data. ignore yes Do not run this backup type. Amanda's disklist configuration file specifies the actual filesystems to be backed up. Here are some sample entries: # host partition dumptype spindle hamlet sd1a normal -1 hamlet sd2a normal -1 dalton /chem srv_comp -1 leda //leda/e samba -1 # Win2K system astarte /data1 normal 1 astarte /data2 normal 1 astarte /home normal 2 # dump all alone The columns in this file hold the hostname, disk partition (specified by file in /dev, full special file name, or mount point), the dump type, and a spindle parameter. The latter serves to control which backups can be done at the same time on a host. A value of -1 says to ignore this parameter. Other values define backup groups within a host; Amanda will only run backups from the same group in parallel. For example, on host astarte, the /home filesystem must be backed up separately from the other two (the latter may be backed up simultaneously if Amanda so wishes). There are a few final steps that are needed to complete the Amanda server setup:
Amanda expects the proper tape to be in the tape drive when the backup process begins. You can determine the next tape needed for the Daily configuration by running the following command: # amadmin Daily tape The Amanda system will need some ongoing administration, including tuning and cleanup. The latter is accomplished via the amflush and amcleanup commands. amflush is used to force the data in the holding disk to backup media, and it is typically required after a media failure occurs during an Amanda run. In such cases, the backup data is still written to the holding disk. The amcleanup command needs to be run after an Amanda run aborts or after a system crash. Finally, you can temporarily disable an Amanda configuration by creating a file named hold in the corresponding subdirectory. While this file exists, the Amanda system will pause. This can be used to keep the configuration information intact in the event of a hardware failure on the backup device or a device being temporarily needed for another task. 11.6.2.5 Amanda reports and logsTheAmanda system produces a report for each backup run and sends it by electronic mail to the user specified in the amanda.conf configuration file. The reports are quite detailed and contain the following sections:
You should examine the reports regularly, especially the sections related to errors and performance. Amanda also produces log files for each run, amdump.n, and log.date.n, located in the designated log file directory. These are more verbose versions of the email report, and they can be helpful in tracking some sorts of problems. 11.6.2.6 Restoring files from an Amanda backupAmanda provides the interactive amrecover utility for restoring files fromAmanda backups. It requires that backup sets be indexed (using the index yes setting) and that the two indexing daemons mentioned previously be enabled. The utility must be run as root from the appropriate client system. Here is a sample session: # amrecover Daily AMRECOVER Version 2.4.2. Contacting server on depot.ahania.com ... ... Setting restore date to today (2001-08-12) 200 Working date set to 2001-08-14. 200 Config set to Daily. 200 Dump host set to astarte.ahania.com. $CWD '/home/chavez/data' is on disk '/home' mounted at '/home'. 200 Disk set to /home. amrecover> cd chavez/data /home/chavez/data amrecover> add jetfuel.jpg Added /chavez/data/jetfuel.jpg amrecover> extract Extracting files using tape drive /dev/rmt0 on host depot... The following tapes are needed: DAILY02 Restoring files into directory /home Continue? [Y/n]: y Load tape DAILY02 now Continue? [Y/n]: y warning: ./chavez: File exists Warning: ./chavez/data: File exists Set owner/mode for '.'? [yn]: n amrecover> quit In this case, the amrecover command is very similar to the standard restore command in its interactive mode. The amrestore command can also be used to restore data from an Amanda backup. It is designed to restore entire images from Amanda tapes. See its manual page or the discussion in Unix Backup and Restore for details on its use. 11.6.3 Commercial Backup PackagesThere are several excellent commercialbackup facilities available. An up-to-date list of current packages can be obtained from http://www.storagemountain.com. We won't consider any particular package here but, rather, briefly summarize the important features of a general-purpose backup package, which can potentially serve as criteria for comparing and evaluating any products your site is considering. You should expect the following features from a high-end commercial backup software package suitable for medium-sized and larger networks:
See Chapter 5 of Unix Backup and Recovery for an extended discussion of commercial backup package features. |


EAN: 2147483647
Pages: 162