2.1 Concepts of high availability clusters
|
| < Day Day Up > |
|
2.1 Concepts of high availability clusters
Today, as more and more business and non-business organizations rely on their computer systems to carry out their operations, ensuring high availability (HA) to their computer systems has become a key issue. A failure of a single system component could result in an extended denial of service. To avoid or minimize the risk of denial of service, many sites consider an HA cluster to be a high availability solution. In this section we describe what an HA cluster is normally comprised of, then discuss software/hardware considerations and introduce possible ways of configuring an HA cluster.
2.1.1 A bird's-eye view of high availability clusters
We start with defining the components of a high availability cluster.
Basic elements of a high availability cluster
A typical HA cluster, as introduced in Chapter 1, "Introduction" on page 1, is a group of machines networked together sharing external disk resources. The ultimate purpose of setting up an HA cluster is to eliminate any possible single points of failure. By eliminating single points of failure, the system can continue to run, or recover in an acceptable period of time, with minimal impact to the end users.
Two major elements make a cluster highly available:
-
A set of redundant system components
-
Cluster software that monitors and controls these components in case of a failure
Redundant system components provide backup in case of a single component failure. In an HA cluster, an additional server(s) is added to provide server-level backups in case of a server failure. Components in a server, such as network adapters, disk adapters, disks and power supplies, are also duplicated to eliminate single points of failure. However, simply duplicating system components does not provide high availability, and cluster software is usually employed to control them.
Cluster software is the core element in HA clusters. It is what ties system components into clusters and takes control of those clusters. Typical cluster software provides a facility to configure clusters and predefine actions to be taken in case of a component failure.
The basic function of cluster software in general is to detect component failure and control the redundant components to restore service after a failure. In the event of a component failure, cluster software quickly transfers whatever service the failed component provided to a backup component, thus ensuring minimum downtime. There are several cluster software products in the market today; Table 2-1 lists common cluster software for each platform.
| Platform type | Cluster software |
|---|---|
| AIX | HACMP |
| HP-UX | MC/Service Guard |
| Solaris | Sun Cluster, Veritas Cluster Service |
| Linux | SCYLD Beowulf, Open Source Cluster Application Resources (OSCAR), IBM Tivoli System Automation |
| Microsoft Windows | Microsoft Cluster Service |
Each cluster software product has its own unique benefits, and the terminologies and technologies may differ from product to product. However, the basic concept and functions of most cluster software provides have much in common. In the following sections we describe how an HA cluster is typically configured and how it works, using simplified examples.
Typical high availability cluster configuration
Most cluster software offers various options to configure an HA cluster. Configurations depend on the system's high availability requirements and the cluster software used. Though there are several variations, the two configurations types most often discussed are idle or hot standby, and mutual takeover.
Basically, a hot standby configuration assumes a second physical node capable of taking over for the first node. The second node sits idle except in the case of a fallover. Meanwhile, the mutual takeover configuration consists of two nodes, each with their own set of applications, that can take on the function of the other in case of a node failure. In this configuration, each node should have sufficient machine power to run jobs of both nodes in the event of a node failure. Otherwise, the applications of both nodes will run in a degraded mode after a fallover, since one node is doing the job previously done by two. Mutual takeover is usually considered to be a more cost effective choice since it avoids having a system installed just for hot standby.
Figure 2-1 on page 34 shows a typical mutual takeover configuration. Using this figure as an example, we will describe what comprises an HA cluster. Keep in mind that this is just an example of an HA cluster configuration. Mutual takeover is a popular configuration; however, it may or may not be the best high availability solution for you. For a configuration that best matches your requirements, consult your service provider.
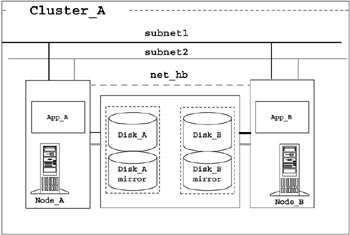
Figure 2-1: A typical HA cluster configuration
As you can see in Figure 2-1, Cluster_A has Node_A and Node_B. Each node is running an application. The two nodes are set up so that each node is able to provide the function of both nodes in case a node or a system component on a node fails. In normal production, Node_A runs App_A and owns Disk_A, while Node_B runs App_B and owns Disk_B. When one of the nodes fail, the other node will acquire ownership of both disks and run both applications.
Redundant hardware components are the bottom-line requirement to enable a high availability scenario. In the scenario shown here, notice that most hardware components are duplicated. The two nodes are each connected to two physical TCP/IP networks, subnet1 and subnet2, providing an alternate network connection in case of a network component failure. They share a same set of external disks, Disk_A and Disk_B, each mirrored to prevent the loss of data in case of a disk failure. Both nodes have a path to connect to the external disks. This enables one node to acquire owner ship of an external disk owned by another node in case of a node failure. For example, if Node_A fails, Node_B can acquire ownership of Disk_A and resume whatever service that requires Disk_A. Disk adapters connecting the nodes and the external disks are duplicated to provide backup in the event of a disk adapter failure.
In some cluster configurations, there may be an additional non-TCP/IP network that directly connects the two nodes, used for heartbeats. This is shown in the figure as net_hb. To detect failures such as network and node failure, most cluster software uses the heartbeat mechanism.
Each node in the cluster sends "heartbeat" packets to its peer nodes over TCP/IP network and/or non-TCP/IP network. If heartbeat packets are not received from the peer node for a predefined amount of time, the cluster software interprets it as a node failure.
When using only TCP/IP networks to send heartbeats, it is difficult to differentiate node failures from network failures. Because of this, most cluster software recommends (or require) a dedicated point-to-point network for sending heartbeat packets. Used together with TCP/IP networks, the point-to-point network prevents cluster software from misinterpreting network component failure as node failure. The network type for this point-to-point network may vary depending on the type of network the cluster software supports. RS-232C, Target Mode SCSI, Target Mode SSA is supported for point-to-point networks in some cluster software.
Managing system components
Cluster software is responsible for managing system components in a cluster. It is typically installed on the local disk of each cluster node. There is usually a set of processes or services that is running constantly on the cluster nodes. It monitors system components and takes control of those resources when required. These processes or services are often referred to as the cluster manager.
On a node, applications and other system components that are required by those applications are bundled into a group. Here, we refer to each application and system component as resource, and refer to a group of these resources as resource group.
A resource group is generally comprised of one or more applications, one or more logical storages residing on an external disk, and an IP address that is not bound to a node. There may be more or fewer resources in the group, depending on application requirements and how much the cluster software is able to support.
A resource group is associated with two or more nodes in the cluster, and in normal production. A resource group is the unit that a cluster manager uses to move resources to one node from another. It will reside on the primary node in normal production; in the event of a node or component failure on the primary node, the cluster manager will move the group to another node. Figure 2-2 shows an example of resources and resource groups in a cluster.
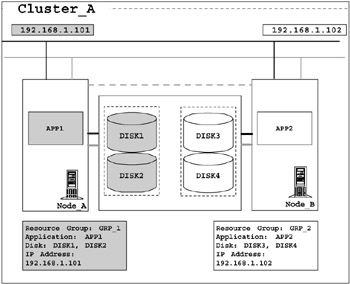
Figure 2-2: Resource groups in a cluster
In Figure 2-2, a resource group called GRP_1 is comprised of an application called APP1, and external disks DISK1 and DISK2. IP address 192.168.1.101 is associated to GRP_1. The primary node for GRP1 is Node_A, and the secondary node is Node_B.
GRP_2 is comprised of application APP2, and disks DISK3 and DISK4, and IP address 192.168.1.102. For GRP_2, Node_B is the primary node and Node_A is the secondary node.
Fallover and fallback of a resource group
In normal production, cluster software constantly monitors the cluster resources for any signs of failure. As soon as a cluster manager running on a node detects a node or a component failure, it will quickly acquire the ownership of the resource group and restart the application.
In our example, assume a case where Node_A crashed. Through heartbeats, Node_B detects Node_A's failure. Because Node_B is configured as a secondary node for resource GRP_1, Node_B's cluster manager acquires ownership of resource group GRP_1. As a result, DISK1 and DISK2 are mounted on Node_B, and the IP address associated to GRP_1 has moved to Node_B.
Using these resources, Node_B will restart APP1, and resume application processing. Because these operations are initiated automatically based on pre-defined actions, it is a matter of minutes before processing of APP1 is restored. This is called a fallover. Figure 2-3 on page 38 shows an image of the cluster after fallover.
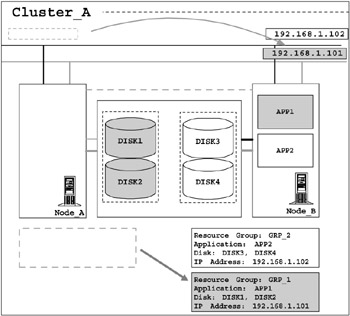
Figure 2-3: Fallover of a resource group
Note that this is only a typical scenario of a fallover. Most cluster software is capable of detecting both hardware and software component failures, if configured to do so. In addition to basic resources such as nodes, network, disks, what other resources could be monitored differs by product. Some cluster software may require more or less configuration to monitor the same set of resources. For details on what your choice of cluster software can monitor, consult your service provider.
After a node recovers from a failure, it rejoins the cluster. Depending on the cluster configuration, the resource group that failed over to a standby node is returned to the primary node at the time of rejoining. In this Redbook, we refer to this cluster behavior as fallback.
To describe this behavior using our example, when fallback is initiated, resource group GRP_1 moves back to Node_A and returns to its normal production state as shown in Figure 2-2 on page 36. There are some considerations about fallback. These are summarized in 2.1.2, "Software considerations" on page 39 under Fallback policy.
As described, cluster software addresses node failure by initiating a fallover of a resource group from the failed node to the standby node. A failed node would eventually recover from a failure and rejoin the cluster. After the rejoining of the failed node, you would have the choice of either keeping the resource group on the secondary node, or relocating the resource group to the original node. If you choose the latter option, then you should consider the timing of when to initiate the fallback.
Most cluster software provides options on how a resource group should be managed in the event of a node rejoining the cluster. Typically you would have the option of either initiating a fallback automatically when the node rejoins the cluster, or have the node just rejoin the cluster and manually initiate a fallback whenever appropriate. When choosing to initiate an automatic fallback, be aware that this initiates a fallback regardless of the application status. A fallback usually requires stopping the application on the secondary node and restarting the application on the primary node. Though a fallback generally takes place in a short period of time, this may disrupt your application processing.
To implement a successful HA cluster, certain software considerations and hardware considerations should be met. In the following section, we describe what you need to consider prior to implementing HA clusters.
2.1.2 Software considerations
In order to make your application highly available, you must either use the high availability functions that your application provides, or put them under the control of cluster software. Many sites look to cluster software as a solution to ensure application high availability, as it is usually the case that high availability functions within an application do not withstand hardware failure.
Though most software programs are able to run in a multi-node HA cluster environment and are controllable by cluster software, there are certain considerations to take into account. If you plan to put your application under control of any cluster software, check the following criteria to make sure your application is serviced correctly by cluster software.
Application behavior
First think about how your application behaves in a single-node environment. Then consider how your application may behave in a multi-node HA cluster. This determines how you should set up your application. Consider where you should place your application executables, and how you should configure your application to achieve maximum availability. Depending on how your application works, you may have to install them on a shared disk, or just have a copy of the software on the local disk of the other node. If several instances of the same application may run on one node in the event of a fallover, make sure that your application supports such a configuration.
Licensing
Understand your application licensing requirements and make sure the configuration you plan is not breaching the application license agreements. Some applications are license-protected by incorporating processor-specific information into each instance of application installed. This means that even though you implement your application appropriately and the cluster hardware handles the application correctly in case of a fallover, the application may not be able to start because of your license restrictions. Make sure you have licenses for each node in the cluster that may run your applications. If you plan to have several instances of the same application running on one node, ensure you have the license for each instance.
Dependencies
Check your application dependencies. When configuring your software for an HA cluster, it is important that you know what your applications are dependent upon, but it is even more important to know what your application should not be dependent upon.
Make sure your application is independent of any node-bound resources. Any applications dependent on a resource that is bound to a particular node may have dependency problems, as those resources are usually not attached or accessible to the standby node. Things like binaries or configuration files installed on locally attached drives, hard coding to a particular device in a particular location, and hostname dependencies could become a potential dependency issue.
Once you have confirmed that your application does not depend on any local resource, define which resource needs to be in place to run your application. Common dependencies are data on external disks and an IP address for client access. Check to see if your application needs other dependencies.
Automation
Most cluster software uses scripts or agents to control software and hardware components in a cluster. For this reason, most cluster software requires that any application handled by it must be able to start and stop by command without manual intervention. Scripts to start and stop your applications are generally required. Make sure your application provides startup and shutdown commands. Also, make sure that those commands do not prompt you for operator replies. If you plan to have your application monitored by the cluster software, you may have to develop a script to check the health of your application.
Robustness
Applications should be stable enough to withstand sudden hardware failure. This means that your application should be able to restart successfully on the other node after a node failure. Tests should be executed to determine if a simple restart of the application is sufficient to recover your application after a hardware failure. If further steps are needed, verify that your recovery procedure could be automated.
Fallback policy
As described in "Fallover and fallback of a resource group" on page 37, cluster software addresses node failure by initiating a fallover of the resource group from the failed node to the standby node. A failed node would eventually recover from a failure and rejoin the cluster. After the rejoining of the failed node, you would have the choice of either keeping the resource group on the secondary node or relocating the resource group to the original node. If you choose to relocate the resource group to the original node, then you should consider the timing of when to initiate the fallback.
Most cluster software gives you options on how a resource group should be managed in the event of a node rejoining the cluster. Typically you would have the option of either initiating a fallback automatically when the node rejoins the cluster, or having the node just rejoin the cluster and manually initiate a fallback whenever appropriate.
When choosing to initiate an automatic fallback, be aware that this initiates a fallback regardless of the application status. A fallback usually requires stopping the application on the secondary node and restarting the application on the primary node. Though a fallback generally takes place in a short period of time, this may disrupt your application processing.
2.1.3 Hardware considerations
In this case, hardware considerations involve how to provide redundancy. A cluster that provides maximum high availability is a cluster with no single points of failure. A single point of failure exists when a critical cluster function is provided by a single component. If that component fails, the cluster has no way of providing that function, and the application or service dependent on that component becomes unavailable.
An HA cluster is able to provide high availability for most hardware components when redundant hardware is supplied and the cluster software is configured to take control of them. Preventing hardware components from becoming single points of failure is not a difficult task; simply duplicating them and configuring the cluster software to handle them in the event of a failure should solve the problem for most components.
However, we remind you again that adding redundant hardware components is usually associated with a cost. You may have to make compromises at some point. Consider the priority of your application. Balance® the cost of the failure against the cost of additional hardware and the workload it takes to configure high availability. Depending on the priority and the required level of availability for your application, manual recovery procedures after notifying the system administrator may be enough.
In Table 2-2 we point out basic hardware components which could become a single point of failure, and describe how to address them. Some components simply need to be duplicated, with no additional configuration, because the hardware in which they reside automatically switches over to the redundant component in the event of a failure. For other components you may have to perform further configuration to handle them, or write custom code to detect their failure and trigger recovery actions. This may vary depending on the cluster software you use, so consult your service provider for detailed information.
| Hardware component | Measures to eliminate single points of failure |
|---|---|
| Node | Set up a standby node. An additional node could be a standby for one or more nodes. If an additional node will just be a "hot standby" for one node during production, a node with the same machine power as the active node is sufficient. If you are planning a mutual takeover, make sure the node has enough power to execute all the applications that will run on that server in the event of a fallover. |
| Power source | Use multiple circuits or uninterruptable power supplies (UPS.) |
| Network adapter | To recover from a network adapter failure, you will need at least two network adapters per node. If your cluster software requires a dedicated TCP/IP network for heartbeats, additional network adapters may be added. |
| Network | Have multiple networks to connect nodes. |
| TCP/IP subsystem | Use a point-to-point network to connect nodes in the cluster. Most cluster software requires, or recommends, at least one active network (TCP/IP or non-TCP/IP) to send "heartbeats" to the peer nodes. By providing a point-to-point network, cluster software will be able to distinguish a network failure from a node failure. For cluster software that does not support non-TCP/IP network for heartbeats, consult your service provider for ways to eliminate TCP/IP subsystem as a single point of failure. |
| Disk adapter | Add an additional disk adapter to each node. When cabling your disks, make sure that each disk adapter has access to each external disk. This enables an alternate access path to external disks in case of a disk adapter failure. |
| Disk controller | Use redundant disk controllers. |
| Disk | Provide redundant disks and enable RAID to protect your data from disk failures. |
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 92