The XML Document
| XML is all of the following:
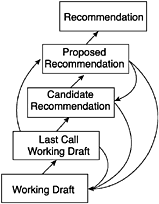
Table 1.1. The W3C XML Technologies
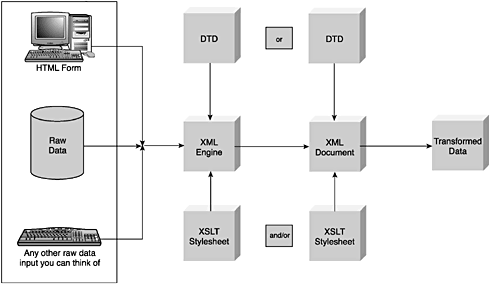
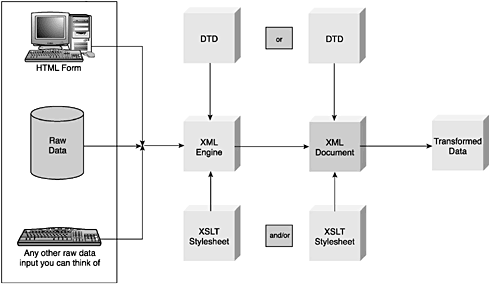
The XML ProcessLet's take a look at how the different components of the XML system listed in Table 1.1 fit together. I call this the XML process. Figure 1.4 shows all the parts of the process from Table 1.1 that we'll be concerned with and their relationship to one another. Figure 1.4. The XML process. Here is the flow of data in the process:
We'll return to this diagram several times to illustrate where we are in the process. Components of an XML DocumentFigure 1.5 shows where we currently are in the XML process. Figure 1.5. The document in the XML process. Listing 1.1 is a sample XML document that I will use to illustrate and explain its various components. Listing 1.1 Sample XML Document<?xml version="1.0" standalone="no"?> <!-- ******* Resumes for Potential Hires ******* --> <RESUMES xmlns='http://www.myorg.net/tags'> <PERSON PERSONID="p1"> <NAME> <LAST>Shelton</LAST> <FIRST>Rick</FIRST> </NAME> <ADDRESS> <STREET>911 Intranet Ave.</STREET> <CITY>Canberra</CITY> <COUNTRY>Australia</COUNTRY> <PC>A34G-90</PC </ADDRESS> <TEL>(+612) 111-2345</TEL> <EMAIL>shelton@somewhere.com</EMAIL> </PERSON> <PERSON PERSONID="p2"> <NAME> <LAST>Tenney</LAST <FIRST>Corey</FIRST> </NAME> <ADDRESS> <STREET>211 Yardwork Circle</STREET> <CITY>Roy, UT</CITY> <COUNTRY>USA</COUNTRY> <ZIP>64067</ZIP> </ADDRESS> <TEL/> <EMAIL>tenney@yardwork.com</EMAIL> </PERSON> </RESUMES> XML DeclarationAlthough it isn't required, XML documents can begin with the statement <?xm...?> . This is the XML declaration that specifies that the following data is an XML document. It also has additional attributes of version , encoding , and standalone . version is a required attribute, and the others are optional. Why are these important? If the version of XML ever changes (changes never happen, right?), there must be a mechanism in place for developers to determine what version they are working with. XSLT 1.0 just became 1.1, for example. The encoding and standalone attributes are important from a Unicode and DTD perspective, respectively. In the sample document, the following declaration <?xml version="1.0" standalone="no"?> gives us the additional information that this XML document conforms to version 1.0 of the XML standard and that there is an external DTD associated with it. (This document cannot stand alone. ) Of course, if this document had a DTD defined within it, then the standalone attribute would be "yes" . After all this discussion about DTDs, you might think that DTDs are required; they're not. Later in this chapter, in the "Document Type Definition" and "The DOCTYPE Declaration" sections, we'll go into much more detail on DTDs.
Markup DelimitersAn XML document is composed of one or more elements that are, in turn , composed of two (sometimes one) tags. The opening tag places the element name between a less than symbol (<) and a greater than (>) symbol. The closing tag is identical to the opening tag except that a forward slash (/) is placed before the element name. Our sample document shows that <LAST>Shelton</LAST> is one of its elements. The document has several more elements, one of which has the opening tag <STREET> and the closing tag </STREET> . Element NamesThe following are guidelines for choosing element names:
root ElementThe root element delineates the starting and ending points of the document data. It is the outermost element of the document. In our example, <RESUMES> </RESUMES> is the root element. Empty ElementsThere are cases in which an element will have no associated data with it. An example would be a null field in a database transferred to an XML document. The field exists whether or not it contains data, so we need an empty element for it. This is represented by a single tag having the forward slash ( / ) after the name. Remember that in the markup delimiters discussion, I said that sometimes an element consists of only one tag. In our example, there is no telephone number for the second person, so we place an empty element <TEL/> . AttributesXML element attributes are similar in appearance and function to attributes contained in HTML tags. They modify or further define the tag with which they are associated. They are contained inside the tag and consist of an attribute name and an accompanying value. The PERSON tag in our resumes document has an attribute, as shown in the following example: <PERSON PERSONID="p1"> The attribute name is PERSONID , and its value in this instance is p1 . The attribute value must be expressed in quotes. CommentsXML comments are identical in form and function to HTML comments. They begin with <!- and end with --> . The second line of our document <!-- ******* Resumes for Potential Hires ******* --> is an XML comment. Entity ReferencesFive characters are not allowed between tags in an XML document. These characters are shown in Table 1.2. Table 1.2. Entity Substitutions
A closer look will point out why using any of these entities would interfere with parsing. The ampersand delimits special characters like those in the Entity column of Table 1.2. The remaining entities delimit the tags themselves and attribute data. CDATAWhen you have a section of an XML document that you want to remain untouched or unprocessed by an XML parser, place it in a CDATA section. These sections are treated as plain text. They would be excellent for sections of code in which you don't want the parser to interpret any special characters such as the entity references mentioned previously. CDATA sections are delimited with <![CDATA[ and ]]> .
In the following example, the parser will treat the entities as plain text, and no interpretation will occur: <![CDATA[Here is a section on CDATA & its syntax with <element> tags]]> NamespacesNamespaces are a recent addition to XML. They are not mandatory but are advisable to use. Their main purpose is to ensure element uniqueness.Think about the following situation. I could define a tag <NETSTORAGE> in a document about types of disk storage. It is likely that another XML author might have a different document defining the same tag. If these documents were ever combined (quite likely), then these elements would collide. Here's an example.You have an XHTML document with standard XHTML tags. You want to add some elements of your own design to the document, but some of your tags have been defined with the same name as some of the XHTML tags. This would really mess up an HTML interpreter and would definitely give undesired results. Namespace assignments help avoid this situation by assigning a scope to tags. If this seems farfetched, remember that you can define two elements with the same name having two different meanings and have each one in a different document. The odds of you (or the company you work for) ever combining these documents can be pretty high. Namespace definitions are usually specified as an attribute of a tag. These definitions can be assigned a name (scope) in the document by appending a colon and the desired name to the xmlns declaration. In this example, I assigned the name res to the namespace 'http://www.myorg.net/restags': <RESUMES xmlns:res='http://www.myorg.net/restags'> In the following example, with this declaration, I prefix all tags with this name: <RES:PERSON PERSONID="p1"> <RES:NAME> <RES:LAST>Shelton</LAST> <RES:FIRST>Rick</FIRST> Again, look at the XML document and the root element declaration. This example illustrates the default namespace for this document: <RESUMES xmlns='http://www.myorg.net/tags'> All tags in this document that do not have a namespace prefix are assumed to belong to this document's namespace. In the following example, the prefix isn't necessary: <PERSON PERSONID="p1"> <:NAME> <LAST>Shelton</LAST> <FIRST>Rick</FIRST> This might seem like overkill right now, but in Chapter 3 when we talk about stylesheet transformations, you will see that this construct is used more often than not. It is also possible to have more than one namespace declaration in the same XML document: <RESUMES xmlns="http://www.myorg.net"> xmlns:phonenumbers="http://www.phones.net" With this declaration, look at the document fragment in Listing 1.2. Listing 1.2 Resumes XML Document Fragment<ADDRESS> <STREET>911 Intranet Ave.</STREET> <CITY>Canberra</CITY> <COUNTRY>Australia</COUNTRY> </ADDRESS> <phonenumbers:TEL>(+612) 111-2345</TEL> <EMAIL>shelton@somewhere.com</EMAIL> Because the first namespace declaration had no name appended to it, it is the default namespace, and no prefix is necessary for the document tags except in the case of the <TEL> tag. A second namespace was defined for the document that applied to the <TEL> tag. This is not a trick. The fact that the <TEL> tag was associated with a different namespace than the other tags in the document was known by the document writer beforehand. Well- Formed DocumentsFor an XML parser to properly process an XML document, it must be at a minimum what is known as well-formed. To meet this requirement, the document must conform to the following minimum criteria:
|