Source Adapters
| Each of the components in this section are source adapters. DataReader SourceThe DataReader Source Adapter provides a way to retrieve rows from a database table resulting from a SQL query. Table 20.1 provides the standard profile for this component.
Setting Up the DataReader Source AdapterTo set up the DataReader Source Adapter, you must create a valid ADO.NET Connection Manager, which you select on the Connection Managers tab in the DataReader Source designer. Next, click on the Component Properties tab and type the SQL query you want to use in the SqlCommand property. Figure 20.7 shows the Advanced Editor for the DataReader Source Adapter with the query in the generic String Value Editor. Figure 20.7. The DataReader Source Adapter uses a query to fetch rows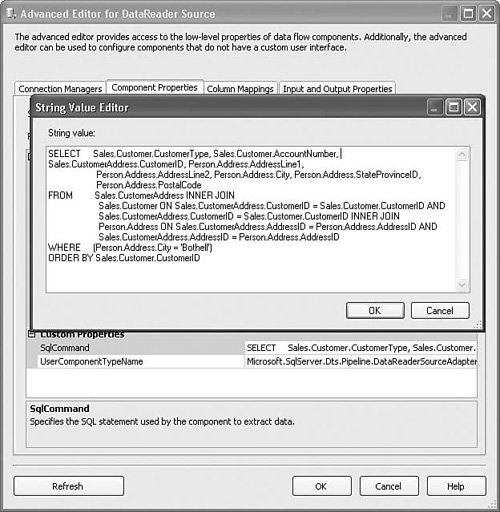 Tip Only the more masochistic among us enjoy typing complex SQL queries into tiny editors. Because the Advanced Editor is a generic designer and SQL queries are string properties, the default editor is, unfortunately and unavoidably, an edit box. So, to create the query, open SQL Server Management Studio, and build the query there. Or, you can use the query builder that you launch from the SQL Task, and then copy/paste the query into the SqlQuery property. There is little complexity here. The DataReader Source Adapter has one property, SqlCommand, which it uses to retrieve rows. The type and number of columns is defined by the query. The columns you select in the query are the columns available for downstream components. Note Certain terms such as upstream, downstream, and backpressure have come into the vocabulary of Integration Services. Mostly, they are analogic with their physical pipeline counterparts. The IsSorted and SortKeyPosition PropertiesThe DataReader Source Adapter, like other components, has an important property that might easily go unnoticed called IsSorted. Some components, like Merge and MergeJoin, require rows arriving at their inputs to be sorted. This property tells the Data Flow Task that the output from the DataReader Source Adapter is sorted. Obviously, that's not enough information to be useful because it doesn't tell you how they are sorted or on what column. Therefore, there is also a property on columns called SortKeyPosition, where you can specify if the column is sorted, in what column rank (column sorted 1st, 2nd, or 3rd) and in what order (ascending/descending). Note The output of a component can only be sorted if it is asynchronous. The reason for this is because synchronous transforms can only process rows as they arrive on their outputs. They cannot change the order of rows. In the sample solution, S20 - StockComponents, there is a package called DataReaderSource.dtsx. That package has a DataReader Source Adapter with a query that is abbreviated as follows: SELECT Sales.Customer.CustomerType, Sales.CustomerAddress.CustomerID, ... FROM ... ORDER BY Sales.Customer.CustomerType ASC, Sales.Customer.CustomerID ASC This is a simple query for building a customer list for all customers living in Bothell, Washington. The ORDER BY clause is important here because it causes the resultset to be sorted on two columns, CustomerType and CustomerID. To represent this sort order in the DataReader Source Adapter (or any other component that generates sorted rows), you set the value of the SortKeyPosition property, as shown in Figure 20.8. Figure 20.8. Use SortKeyPosition to indicate column rank and sort order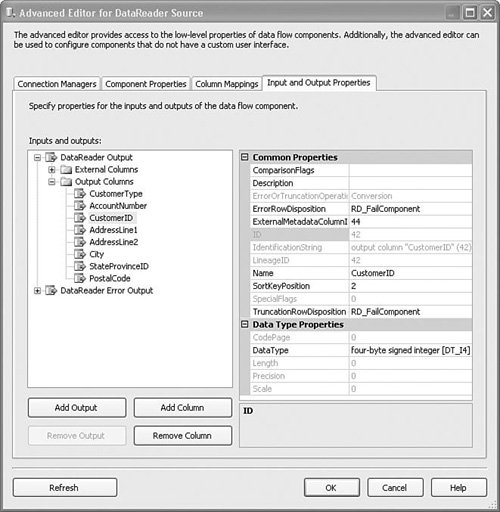 Notice the SortKeyPosition property for the CustomerID column has the value of 2. The SortKeyPosition property on the CustomerType column is not shown, but it has the value of 1. Positive sort key positions mean that the column is sorted in ascending order. A sort key position of zero means the column is not sorted and a negative sort key position means that the column is sorted in descending order. Finally, the numbers for the sort key positions must start with 1 or -1 and increase by 1. The following are valid sequences for defining the sort key positions for columns followed by an explanation. Each number represents the value for the SortKeyPosition for a different column.
The following sort key positions are invalid:
Tip If you incorrectly specify the sort key columns and attempt to close the component designer, you should receive an error similar to the following: Error at Data Flow Task [DTS.Pipeline]: The IsSorted property of output "DataReader Output" (6) is set to TRUE, but the absolute values of the non-zero output column SortKeyPositions do not form a monotonically increasing sequence, starting at one. The IsSorted and SortKeyPosition properties are not specific to the DataReader Source Adapter. Most components that transform or otherwise process data support these properties. Excel Source and DestinationThe Excel Source Adapter is provided to simplify access to Excel data. It is based on and actually uses the same designer as the OLE DB Source. In Chapter 10, "The Stock Connection Managers," there is a discussion about how to set up the Excel Connection Manager or alternatives to using Excel. You might want to quickly review that section. The setup for the Excel Destination Adapter is virtually identical to the Excel Destination Source Adapter. Table 20.2 provides the standard profile for these components.
Caution There is, at this time, no Jet for Excel or Access provider available for 64 bit. However, you can work around that by using the 32-bit version of DTExec.exe from the Program Files (x86) folder. Setting Up the Excel SourceOne of the first issues you need to contend with when using the Excel Source Adapter is data conversion. The Excel driver supports only six data types and Integration Services maps those types, as shown in Table 20.3.
Tip When importing data from Excel, you might find it helpful to use the Import/Export Wizard to generate the initial package because the wizard adds a Data Conversion transform to correctly convert the types. Figure 20.9 shows the Excel Source Editor. Figure 20.9. The Excel Source Editor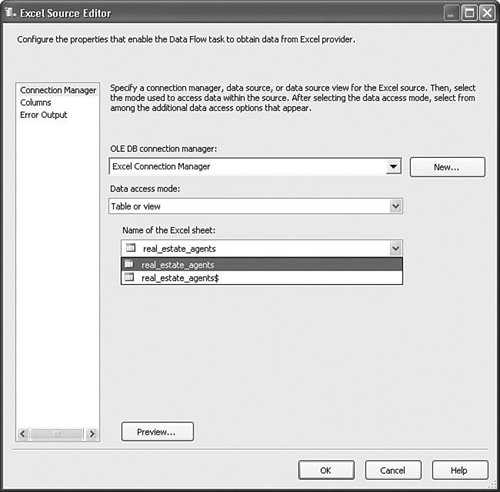 As you can see, the Excel Source Editor is very simple. You define an Excel Connection Manager, select it in the OLE DB Connection Manager, select the table access mode, and then select the name of the Excel sheet. Note The description for the connection selection drop down reads "OLE DB Connection Manager"; however, that is misnamed because the Excel Source reused the OLE DB Source designer. The designer does not allow you to select an OLE DB Connection Manager. It should read "Excel Connection Manager." Also, the description for the Excel sheet drop down should read "Name of the Excel sheet or range" because you can also select a named range to load. Flat File Source and DestinationThe Flat File Source and Destination Adapters provide a high-performance method to work with data from fixed width, delimited, and ragged right flat files. Table 20.4 provides the standard profile for these components.
Setting Up the Flat File Source AdapterTo set up the Flat File Source Adapter, you need to first create a Flat File Connection Manager, as described in Chapter 10. The setup for the Flat File Destination Adapter is virtually identical to the Flat File Source Adapter. Figure 20.10 shows the simple Flat File Source Editor. Figure 20.10. The Flat File Source Editor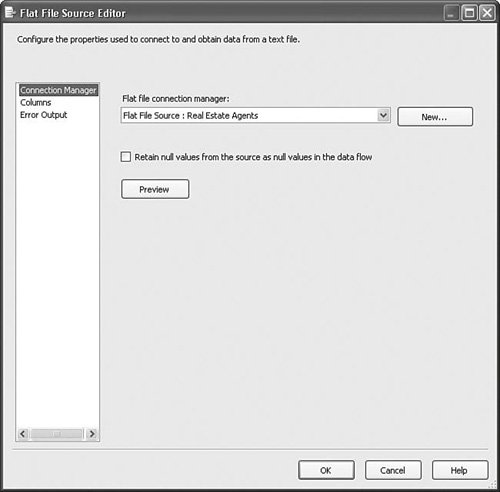 Most of the work of setting up flat file access is accomplished in the connection manager. However, there are two custom properties worth noting, as described in the following sections. RetainNullsYou can set the RetainNulls property from two locations. On the custom editor, you enable this property with the Retain Nulls Values check box on the Connection Manager tab. In the Advanced Editor, you can find the property on the Component Properties tab. This setting specifies how the Flat File Source Adapter should handle source NULL values. When this property is set to FALSE, the Flat File Source Adapter replaces NULL values from the source data with appropriate default values for each column, such as zero for numeric columns or empty strings for string columns. FileNameColumnNameThis custom property provides a way to add a column to the output that will contain the name of the file from where the row originates. The property is not available in the Flat File Source Editor and must be set in the Advanced Editor or in the properties grid. The example uses SourceFileName for the column name. Take a look at Figure 20.11, which shows the column with the name of the file for each row. Figure 20.11. Viewing the SourceFileName column specified in the FileNameColumnName custom property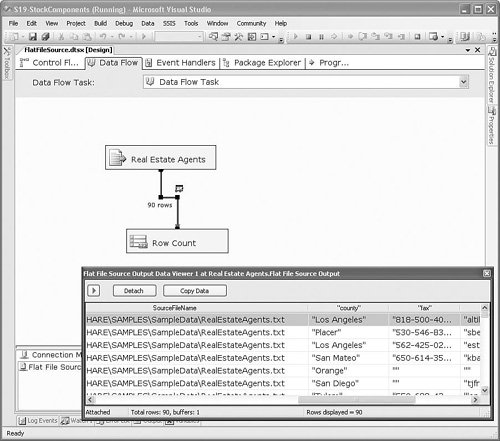 This property is useful for tracking data lineage (where data is coming from) and troubleshooting problem files.
OLE DB Source and DestinationThe OLE DB Source Adapter provides a way to retrieve data from sources using OLE DB. Table 20.5 provides the standard profile for these components.
Setting Up the OLE DB Source AdapterYou can configure the OLE DB Source Adapter to consume all columns provided by the connection manager or by using a query. The setup for the OLE DB destination is virtually identical to the source. There are four access modes:
OLE DB Connection Managers created from a data source can provide additional options such as retrieving rows from a named source. Figure 20.12 shows the OLE DB Source Editor with the Employee table from AdventureWorks selected. Figure 20.12. The OLE DB Source Editor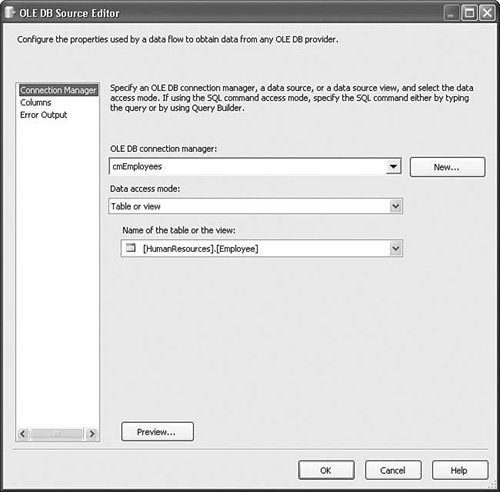 Raw File Source and DestinationThe RawFile Source Adapter provides a way to temporarily stage data to disk. It is an extremely fast storage format because it stores the rows in the same format as the Data Flow Task stores rows in the buffer memory. RawFile adapters do not support Binary Large Object (BLOB) types. The RawFile always loads from files created by the RawFile Destination Adapter and is useful for scenarios in which you need to break up the data flow into smaller units. For example, on underpowered servers, you might experience quicker throughput by breaking large and complex data flows into smaller, less complex data flows connected by raw files. Also, opinions on this vary, but most feel it is important to stage data at key junctures during the Extract, Transform, and Load (ETL) process. The RawFile is ideal for this. The setup for the RawFile destination is virtually identical to the source. Table 20.6 provides the profile for these components.
There are two access modes:
Setting Up the RawFile Source AdapterSetting up the component is a matter of specifying the filename in the FileName property. It is highly recommend that you do not use the filename AccessMode. If you do, whenever you move the package, you might need to modify it to update the raw filename and folder. XML SourceThe XML Source Adapter provides a way to read XML files and convert the contents into tabular form suitable for processing in the Data Flow Task. Table 20.7 provides the profile for this component.
Setting Up the XML Source AdapterThere are three access modes for the XML Source Adapter, as follows:
Figure 20.13 shows the XML Source Editor. Figure 20.13. The XML Source Editor with an XML file specified at an http URL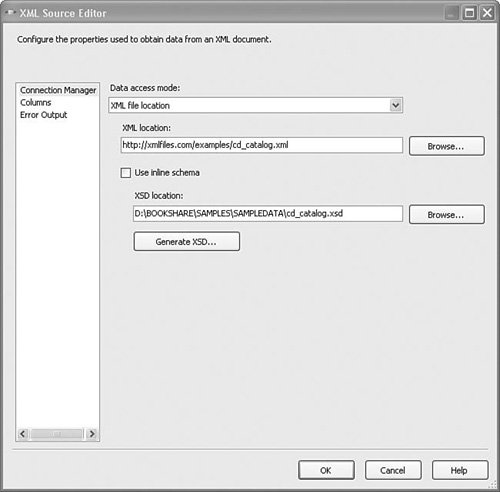 The option for using an inline schema allows you to use an XSD schema that's embedded within the XML file. This is useful if you want to decrease the number of files you work with or if your source system only provides XML files with inline schema. The XML Source Adapter can have more than one output and more than one error output depending on the shape of the XML. The sample package, XMLSource.dtsx in the sample solution S20-StockComponents, contains a Data Flow Task with an XML Source Adapter having one output on a fairly simplistic XML file. However, files are often structured hierarchically. For example, the sample XML file is a catalog of CDs. A more complex XML file might have a collection of CD catalogs. The XML Source Adapter determines what these hierarchical relationships are and generates outputs based on those relationships. Caution The schemas can support a single namespace only; they do not support schema collections. The XML Source Adapter also only supports single rooted XML files. The XML Source Adapter needs a schema to use as metadata for mapping output columns from the source adapter. If a valid schema file (XSD) that describes the XML is available, you can use it. Otherwise, you can click on the GenerateSchema button and generate your own XSD schema file for the selected XML file. After you've supplied a valid schema, make sure you click on the Columns tab to establish the columns that you want to consume. Finally, the default length for string types is 255 and the default type is Unicode string (DT_WSTR). For columns such as first name or ZIP Code, that's much too much wasted space going through the data flow. You should modify the column types and lengths in the Advanced Editor for those columns to ensure that they are only as large as absolutely necessary, but no larger. This is a good general guideline, but applies especially in this case because the XML Source Adapter defaults to such long strings. |
EAN: 2147483647
Pages: 200