Scalability: Today s Network Is Tomorrow s NE
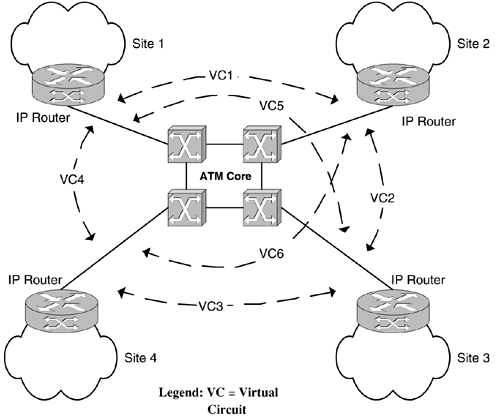
Scalability: Today's Network Is Tomorrow's NEScalability is one of the biggest problems facing modern networking (security is another). It affects devices [RouterScale2002], interfaces, links, internal soft objects (such as virtual circuits), and management systems. A scalability problem occurs when an increase in the number of instances of a given managed object in the network necessitates a compensating , proportional resource increase inside the management system. Layer 2 VPN ScalabilityScalability problems tend to arise in situations of proportional growth. Figure 3-2 illustrates a layer 2 VPN, which provides a good example of scalability. This scheme is often referred to as an overlay network because the IP network is overlaid on the underlying ATM infrastructure. Figure 3-2. Layer 2 VPN scalability: the N 2 problem. Sites 1 to 4 are all part of the one enterprise. This makes Figure 3-2 what is often called an intranet VPN. If one or more of the other sites is part of another organization, such as a customer or supplier, then we have an extranet VPN. Yet another VPN variant is the access VPN, which allows remote users to connect to it over some type of access technology, such as dialup. In Figure 3-2, four sites are contained in the VPN, with one IP router in each site cloud. In order to achieve full layer 3 connectivity, each site must have a virtual circuit connection to every other site. These connections are created through the ATM core . So, the number of ATM virtual circuits required is six; that is, N * ( N “ 1)/2, where N is the number of sites. The full mesh of six bidirectional virtual circuits is shown in Figure 3-2 as VC1-VC6. A full mesh provides the necessary connectivity for the VPN [PrinRussell]. This is generally referred to as the N 2 problem because the number of layer 2 virtual circuits required is proportional to the square of the number of sites. Anything in networking that grows at the rate of N 2 tends to give rise to a problem of scale. The reason for calling this the N 2 problem is because as the number of sites gets bigger, the N 2 term is more significant than the other terms. The problem gets worse if the ATM virtual circuits in the core are unidirectional (some vendors support only unidirectional permanent virtual circuits, or PVCs) in nature because then the number must be doubled in order for IP traffic to flow in both directions. Adding a new site to the VPN requires the creation of new virtual circuits from that site to all other sites. When the number of sites and subscribers is very large, the number of virtual circuits required tends to become unmanageable. Another less obvious problem with this is that each virtual circuit consumes switch capacity in terms of memory and control processor resources. Added to this is link bandwidth and fabric switching capacity if the virtual circuits reserve QoS resources. As if that wasn't enough, a further problem with layer 2 VPNs is that topology changes in the core can result in routing information exchanges of the order of N 4 [DavieRehkter2000]. In contrast, layer 3 VPNs provide a much more scalable solution because the number of connections required is proportional to number of sites, not the square of the number of sites. Layer 3 VPNs (such as RFC 2547) avoid the need for a full mesh between all of the customer edge routers by providing features such as:
Not surprisingly, layer 3 VPN technology is an area of great interest to both enterprise network managers and service providers. For enterprises , layer 3 VPNs provide advanced, potentially low-cost networking features while allowing the service to be provided and managed by a service provider. For SP networks, layer 3 VPNs provide a scalable solution as well as an opportunity to extend services all the way to the customer premises. Virtual Circuit Status MonitoringAnother example of scalability concerns the way in which an NMS manages status changes in ATM virtual circuits. If it is required for the NMS to read and interpret a MIB object table row for every ATM circuit, and this is done in an unrestricted fashion (where the NMS attempts to read all table entries at the same time), then there is scope for scalability problems. They arise when the number of MIB table entries becomes very large. In attempting to keep up with large tables on possibly hundreds of agents throughout a big network, the NMS can run low on resources such as processing power, memory, and disk, and can effectively grind to a halt (unrestricted SNMP get s also use up network bandwidth). The large number of managed objects gives rise to NMS resource issues ”that is, scalability. Really large SNMP tables can possibly also tax the resources of the host agent, resulting in timeouts and lost messages. The discussion here assumes this not to be the case. Some method has to be devised for reading only those table entries that have changed rather than all entries. Processing large (ever-increasing) tables is not scalable. Agents may be able to assist in this by using some form of compressed data in GetResponse and Trap messages. This would require:
A similar problem can occur in reverse when a manager wants to add entries to a large MIB table. In many cases (for example, when creating MPLS LSPs), it is necessary for the SNMP manager to specify an integer index for the new row. The index is a unique (in the sense of a relational database key) column in the table, and the next free value is used for the new LSP. So, if there are 10,000 LSPs already stored sequentially starting at 1, then the next available index is 10,001. The agent knows what the next free value is because it maintains the table. However, the manager may not necessarily know the extent of the table and often has to resort to an expensive MIB walk to determine the next free index. This is because agent data can be changed without the management system knowing about it; for example, using a command-line (or craft) interface, a user can independently add, delete, or modify NE data. This is mapped into the agent MIB, and if these operations do not generate traps, then the management system is oblivious to the data changes (unless it has an automatic discovery capability that reads the affected tables). There is a better way of navigating tables to cater to this and other situations. This brings us to our first MIB note. |
EAN: 2147483647
Pages: 150