Bringing the Managed Data to the Code
| Bringing data and code together is a fundamental computing concept. It is central to the area of network management, and current trends in NE development bring it to center stage. Loading a locally hosted text file into an editor like Microsoft Notepad is a simple example: The editor is the code and the text file is the data. In this case, the code and data reside on the same machine, and bringing them together is a trivial task. Getting SNMP agent data to the manager code is not a trivial task in the distributed data model of network management because:
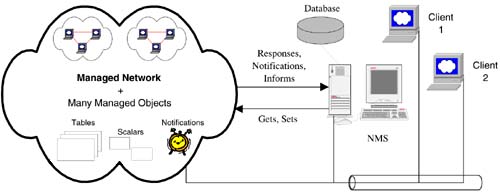
Agent-hosted managed objects change in tandem with the dynamics of the host machine and the underlying network ”for example, the ipInReceives object from Chapter 1, which changes value every time an IP packet is received. This and many other managed objects change value constantly, providing a means for modeling the underlying system and its place in the network. The same is true of all managed NEs. MIBs provide a foundation for the management data model. The management system must keep track of relevant object value changes and apply new changes as and when they are required. As mentioned in Chapter 1, the management system keeps track of the NEs by a combination of polling, issuing set messages, and listening for notifications. This is a classic problem of storing the same data in two different places and is illustrated in Figure 3-1, where a management system tracks the objects in a managed network using the SNMP messages we saw in Chapter 2, "SNMPv3 and Network Management." Figure 3-1. Components of an NMS. Figure 3-1 illustrates a managed network, a central NMS server, a relational database, and several client users. The clients access the FCAPS services exported by the NMS, for example, viewing faults, provisioning, and security configuration. The NMS strives to keep up with changes in the NEs and to reflect these in the clients . Even though SNMP agents form a major part of the management system infrastructure, they are physically remote from the management system. Agent data is created and maintained in a computational execution space removed from that of the management system. For example, the ipInReceives object is mapped into the tables maintained by the host TCP/IP protocol suite, and from there it gets its value. [1] Therefore, get or set messages sent from a manager to an agent result in computation on the agent host. The manager merely collects the results of the agent response. The manager-agent interaction can be seen as a loose type of message-based remote procedure call (RPC). The merit of not using a true RPC mechanism is the lack of associated overhead.
This is at once the strength and the weakness of SNMP. The important point is that the problem of getting the agent data to the manager is always present, particularly as networks grow in size and complexity. (This problem is not restricted to SNMP. Web site authors have a similar problem when they want to embed Java or JavaScript in their pages. The Java code must be downloaded along with the HTML in an effort to marry the browser with the Web site code and data. Interestingly, in network management the process is reversed : The data is brought to the code.) So, should the management system simply request all of the agent data? This is possibly acceptable on small networks but not on heavily loaded, mission-critical enterprise and SP networks. For this reason, the management system struggles to maintain an accurate picture of the ever-changing network. This is a key network management concept. If an ATM network operator prefers not to use signaled virtual circuits, then an extra monitoring burden is placed on the NMS. This is so because unsignaled connections do not recover from intermediate link or node failures. Such failures give rise to a race between the operator fixing the problem and the user noticing a service loss. These considerations lead us to an important principle concerning NMS technology: The quality of an NMS is inversely proportional to the gap between its picture of the network and the actual state of the underlying network ”the smaller the gap, the better the NMS . An ideal NMS responds to network changes instantaneously. Real systems will always experience delays in updating themselves , and it is the goal of the designers and developers to minimize them. As managed NEs become more complex, an extra burden is placed on the management system. The scale of this burden is explored in the next section. |
EAN: 2147483647
Pages: 150