Metrics and Configuration Management Reference
OVERVIEW
If configuration management (CM) provides the framework for the management of all systems engineering activities, then metrics provide the framework for measuring whether or not configuration management has been effective.
That metrics are an absolute requirement is proven by the following dismal statistics:
- Over half (53 percent) of IT projects overrun their schedules and budgets , 31 percent are cancelled, and only 16 percent are completed on time. Source: Standish Group, publication date: 2000.
- Of those projects that failed in 2000, 87 percent went more than 50 percent over budget. Source: KPMG Information Technology, publication date: 2000.
- In 2000, 45 percent of failed projects did not produce the expected benefits, and 88 to 92 percent went over schedule. Source: KPMG Information Technology, publication date: 2000.
- Half of new software projects in the United States will go significantly over budget. Source: META Group, publication date: 2000.
- The average cost of a development project for a large company is $2,322,000; for a medium- sized company, it is $1,331,000; and for a small company, it is $434,000. Source: Standish Group, publication date: 2000.
- In 1995, $81 billion was the estimated cost for cancelled projects. Source: Standish Group, publication date: 1995.
- Over half (52.7 percent) of projects were projected to cost more than 189 percent of their original estimates. Source: Standish Group, publication date: 2000.
- Some 88 percent of all U.S. projects are over schedule, over budget, or both. Source: Standish Group, publication date: 2000.
- The average time overrun on projects is 222 percent of original estimates. Source: Standish Group, publication date: 2000.
While configuration management is not a panacea for all problems, practicing sound CM methodologies can assist in effectively controlling the systems engineering effort. This chapter surveys a wide variety of metrics that can be deployed to measure the developmental process. Not all metrics are applicable to all situations. The organization must carefully consider which of the following metrics are a best fit.
WHAT METRICS ARE AND WHY THEY ARE IMPORTANT
Why should anyone care about productivity and quality? There are several reasons for this. The first and foremost reason is that our customers and end users require a working, quality product. Measuring the process as well as the product tells us whether we have achieved our goal. However, there are other, more subtle reasons why one needs to measure productivity and quality, including:
- The development of systems is becoming increasing complex. Unless one measures, one will never know whether or not one's efforts have been successful.
- On occasion, technology is used just for the sake of using a new technology. This is not an effective use of a technology. Measuring the effectiveness of an implementation ensures that one's decision has been cost-effective .
One measures productivity and quality to quantify the project's progress as well as to quantify the attributes of the product. A metric enables one to understand and manage the process as well as to measure the impact of change to the process that is, new methods , training, etc. The use of metrics also enables one to know when one has met his goals that is, usability, performance, test coverage, etc.
In measuring software systems, one can create metrics based on the different parts of a system for example, requirements, specifications, code, documentation, tests, and training. For each of these components , one can measure its attributes, which include usability, maintainability, extendibility, size , defect level, performance, and completeness.
While the majority of organizations will use metrics found in books such as this one, it is possible to generate metrics specific to a particular task. Characteristics of metrics dictate that they should be:
- Collectable
- Reproducible
- Pertinent
- System independent
Sample product metrics include:
- Size: lines of code, pages of documentation, number and size of test, token count, function count
- Complexity: decision count, variable count, number of modules, size/volume, depth of nesting
- Reliability: count of changes required by phase, count of discovered defects, defect density = number of defects/size, count of changed lines of code
Sample process metrics include:
- Complexity: time to design, code, and test, defect discovery rate by phase, cost to develop, number of external interfaces, defect fix rate
- Methods and tool use: number of tools used and why, project infrastructure tools, tools not used and why
- Resource metrics: years of experience with team, years of experience with language, years of experience with type of software, MIPS per person, support personnel to engineering personnel ratio, non-project time to project time ratio
- Productivity: percent time to redesign, percent time to redo, variance of schedule, variance of effort
Once the organization determines the slate of metrics to be implemented, it must develop a methodology for reviewing the results of the metrics program. Metrics are useless if they do not result in improved quality or productivity. At a minimum, the organization should:
- Determine the metric and measuring technique.
- Measure to understand where you are.
- Establish worst, best, planned cases.
- Modify the process or product, depending on results of measurement.
- Remeasure to see what has changed.
- Reiterate.
TRADITIONAL CM METRICS
The following metrics are typically used by those measuring the CM process:
- Average rate of variance from scheduled time
- Rate of first-pass approvals
- Volume of deviation requests by cause
- The number of scheduled, performed, and completed configuration management audits by each phase of the life cycle
- The rate of new changes being released and the rate that changes are being verified as completed; the history compiled from successive deliveries is used to refine the scope of the expected rate
- The number of completed versus scheduled (stratified by type and priority) actions
- Man-hours per project
- Schedule variances
- Tests per requirement
- Change category count
- Changes by source
- Cost variances
- Errors per thousand source lines of code (KSLOC)
- Requirements volatility
IEEE PROCESS FOR MEASUREMENT
Using the IEEE methodology [IEEE 1989], the measurement process can be described in nine stages. These stages may overlap or occur in different sequences, depending on organization needs. Each of these stages in the measurement process influences the production of a delivered product with the potential for high reliability. Other factors influencing the measurement process include:
- A firm management commitment to continually assess product and process maturity, or stability, or both during the project
- The use of trained personnel in applying measures to the project in a useful way
- Software support tools
- A clear understanding of the distinctions among errors, faults, and failures
Product measures include:
- Errors, faults, and failures: the count of defects with respect to human cause, program bugs , and observed system malfunctions
- Mean-time-to-failure, failure rate: a derivative measure of defect occurrence and time
- Reliability growth and projection: the assessment of change in failure-freeness of the product under testing or operation
- Remaining product faults: the assessment of fault-freeness of the product in development, test, or maintenance
- Completeness and consistency: the assessment of the presence and agreement of all necessary software system parts
- Complexity: the assessment of complicating factors in a system
Process measures include:
- Management control measures address the quantity and distribution of error and faults and the trend of cost necessary for defect removal.
- Coverage measures allow one to monitor the ability of developers and managers to guarantee the required completeness in all the activities of the life cycle and support the definition of correction actions.
- Risk, benefit, and cost evaluation measures support delivery decisions based both on technical and cost criteria. Risk can be assessed based on residual faults present in the product at delivery and the cost with the resulting support activity.
The nine stages consist of the following.
Stage 1 Plan Organizational Strategy
Initiate a planning process. Form a planning group and review reliability constraints and objectives, giving consideration to user needs and requirements. Identify the reliability characteristics of a software product necessary to achieve these objectives. Establish a strategy for measuring and managing software reliability. Document practices for conducting measurements.
Stage 2 Determine Software Reliability Goals
Define the reliability goals for the software being developed to optimize reliability in light of realistic assessments of project constraints, including size scope, cost, and schedule.
Review the requirements for the specific development effort to determine the desired characteristics of the delivered software. For each characteristic, identify specific reliability goals that can be demonstrated by the software or measured against a particular value or condition. Establish an acceptable range of values. Consideration should be given to user needs and requirements.
Establish intermediate reliability goals at various points in the development effort.
Stage 3 Implement Measurement Process
Establish a software reliability measurement process that best fits the organization's needs. Review the rest of the process and select those stages that best lead to optimum reliability.
Add to or enhance these stages as needed. Consider the following suggestions:
- Select appropriate data collection and measurement practices designed to optimize software reliability.
- Document the measures required, the intermediate and final mile-stones when measurements are taken, the data collection requirements, and the acceptable values for each measure.
- Assign responsibilities for performing and monitoring measurements, and provide the necessary support for these activities from across the internal organization.
- Initiate a measure selection and evaluation process.
- Prepare educational material for training personnel in concepts, principles, and practices of software reliability and reliability measures.
Stage 4 Select Potential Measures
Identify potential measures that would be helpful in achieving the reliability goals established in Stage 2.
Stage 5 Prepare Data Collection and Measurement Plan
Prepare a data collection and measurement plan for the development and support effort. For each potential measure, determine the primitives needed to perform the measurement. Data should be organized so that information related to events during the development effort can be properly recorded in a database and retained for historical purposes.
For each intermediate reliability goal identified in Stage 2, identify the measures needed to achieve this goal. Identify the points during development when the measurements are to be taken. Establish acceptable values or a range of values to assess whether the intermediate reliability goals are achieved.
Include in the plan an approach for monitoring the measurement effort itself. The responsibility for collecting and reporting data, verifying its accuracy, computing measures, and interpreting the results should be described.
Stage 6 Monitor the Measurements
Monitor measurements. Once the data collection and reporting begin, monitor the measurements and the progress made during development, so as to manage the reliability and thereby achieve the goals for the delivered product. The measurements assist in determining whether the intermediate reliability goals are achieved and whether the final goal is achievable. Analyze the measure and determine if the results are sufficient to satisfy the reliability goals. Decide whether a measure's results assist in affirming the reliability of the product or process being measured. Take corrective action.
Stage 7 Assess Reliability
Analyze measurements to ensure that reliability of the delivered software satisfies the reliability objectives and that the reliability, as measured, is acceptable.
Identify assessment steps that are consistent with the reliability objectives documented in the data collection and measurement plan. Check the consistency of acceptance criteria and the sufficiency of tests to satisfactorily demonstrate that the reliability objectives have been achieved. Identify the organization responsible for determining final acceptance of the reliability of the software. Document the steps in assessing the reliability of the software.
Stage 8 Use Software
Assess the effectiveness of the measurement effort and perform the necessary corrective action. Conduct a follow-up analysis of the measurement effort to evaluate the reliability assessment and development practices, record lessons learned, and evaluate user satisfaction with the software's reliability.
Stage 9 Retain Software Measurement Data
Retain measurement data on the software throughout the development and operation phases for use in future projects. This data provides a baseline for reliability improvement and an opportunity to compare the same measures across completed projects. This information can assist in developing future guidelines and standards.
METRICS AS A COMPONENT OF THE PROCESS MATURITY FRAMEWORK
The Contel Technology Center's Software Engineering lab has as one of its prime goals the improvement of software engineering productivity. As a result of work in this area, Pfleeger and McGowan [1990] have suggested a set of metrics for which data is to be collected and analyzed. This set of metrics is based on a process maturity framework developed at the Software Engineering Institute (SEI) at Carnegie Mellon University. The SEI framework divides organizations into five levels based on how mature (i.e., organized, professional, aligned to software tenets) the organization is. The five levels range from initial, or ad hoc, to an optimizing environment. Contel recommends that metrics be divided into five levels as well. Each level is based on the amount of information made available to the development process. As the development process matures and improves , additional metrics can be collected and analyzed .
Level 1 Initial Process
This level is characterized by an ad hoc approach to software development. Inputs to the process are not well-defined but the outputs are as expected. Preliminary baseline project metrics should be gathered at this level to form a basis for comparison as improvements are made and maturity increases . This can be accomplished by comparing new project measurements with the baseline ones.
Level 2 Repeatable Process
At this level, the process is repeatable in much the same way that a sub-routine is repeatable. The requirements act as input, the code as output, and constraints are such things as budget and schedule. Although proper inputs produce proper outputs, there is no means to easily discern how the outputs are actually produced. Only project- related metrics make sense at this level because the activities within the actual transitions from input to output are not available to be measured. Measures are this level can include:
- Amount of effort needed to develop the system
- Overall project cost
- Software size : non-commented lines of code, function points, object, and method count
- Personnel effort: actual person-months of effort, report person-months of effort
- Requirements volatility: requirements changes
Level 3 Defined Process
At this level, the activities of the process are clearly defined. This means that the input to and output from each well-defined functional activity can be examined, which permits a measurement of the intermediate products. Measures include:
- Requirements complexity: number of distinct objects and actions addressed in requirements
- Design complexity: number of design modules, Cyclomatic complexity, McCabe design complexity
- Code complexity: number of code modules, Cyclomatic complexity
- Test complexity: number of paths to test, of object-oriented development, and then number of object interfaces to test
- Quality metrics: defects discovered, defects discovered per unit size (defect density), requirements faults discovered, design faults discovered , fault density for each product
- Pages of documentation
Level 4 Managed Process
At this level, feedback from early project activities is used to set priorities for later project activities. At this level, activities are readily compared and contrasted; the effects of changes in one activity can be tracked in the others. At this level, measurements can be made across activities and are used to control and stabilize the process so that productivity and quality can match expectation. The following types of data are recommended to be collected. Metrics at this stage, although derived from the following data, are tailored to the individual organization.
- Process type. What process model is used, and how is it correlating to positive or negative consequences?
- Amount of producer reuse. How much of the system is designed for reuse? This includes reuse of requirements, design modules, test plans, and code.
- Amount of consumer reuse. How much does the project reuse components from other projects? This includes reuse of requirements, design modules, test plans, and code. (By reusing tested , proven components effort can be minimized and quality can be improved.)
- Defect identification. How and when are defects discovered? Knowing this will indicate whether those process activities are effective.
- Use of defect density model for testing. To what extent does the number of defects determine when testing is complete? This controls and focuses testing as well as increases the quality of the final product.
- Use of configuration management. Is a configuration management scheme imposed on the development process? This permits trace-ability, which can be used to assess the impact of alterations.
- Module completion over time. At what rates are modules being completed? This reflects the degree to which the process and development environment facilitate implementation and testing.
Level 5 Optimizing Process
At this level, measures from activities are used to change and improve the process. This process change can affect the organization as well as the project. Studies by the SEI report that 85 percent of organizations are at level 1, 14 percent at level 2, and 1 percent at level 3. None of the firms surveyed had reached Levels 4 or 5. Therefore, the authors have not recommended a set of metrics for Level 5.
STEPS TO TAKE IN USING METRICS
- Assess the process: determine the level of process maturity.
- Determine the appropriate metrics to collect.
- Recommend metrics, tools, and techniques.
- Estimate project cost and schedule.
- Collect appropriate level of metrics.
- Construct project database of metrics data, which can be used for analysis and to track the value of metrics over time.
- Cost and schedule evaluation: when the project is complete, evaluate the initial estimates of cost and schedule for accuracy. Determine which of the factors might account for discrepancies between predicted and actual values.
- Form a basis for future estimates.
IEEE DEFINED METRICS
The IEEE standards [1988] were written with the objective of providing the software community with defined measures currently used as indicators of reliability. By emphasizing early reliability assessment, this standard supports methods through measurement to improve product reliability.
This section presents a sub-set of the IEEE standard that is easily adaptable by the general IT community.
Fault Density
This measure can be used to predict remaining faults by comparison with expected fault density, determine if sufficient testing has been completed, and establish standard fault densities for comparison and prediction.
F d = F/KSLOC
Where:
- F = total number of unique faults found in a given interval and resulting in failures of a specified severity level
- KSLOC = number of source lines of executable code and nonexecutable data declarations, in thousands
Defect Density
This measure can be used after design and code inspections of new development or large block modifications. If the defect density is outside the norm after several inspections, it is an indication of a problem.
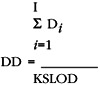
Where:
- D i = total number of unique defects detected during the ith design or code inspection process
- I = total number of inspections
- KSLOD = in the design phase, this is the number of source lines of executable code and nonexecutable data declarations, in thousands
Cumulative Failure Profile
This is a graphical method used to predict reliability, estimate additional testing time to reach an acceptable reliable system, and identify modules and sub-systems that require additional testing. A plot is drawn of cumulative failures versus a suitable time base.
Fault Days Number
This measure represents the number of days that faults spend in the system, from their creation to their removal. For each fault detected and removed, during any phase, the number of days from its creation to its removal is determined (fault-days). The fault-days are then summed for all faults detected and removed, to get the fault-days number at system level, including all faults detected and removed up to the delivery date. In those cases where the creation date of the fault is not known, the fault is assumed to have been created at the middle of the phase in which it was introduced.
Functional or Modular Test Coverage
This measure is used to quantify a software test coverage index for a software delivery. From the system's functional requirements, a cross-reference listing of associated modules must first be created.
Functional (Modular)Test Coverage Index = 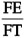
Where:
- FE = number of the software functional (modular) requirements for which all test cases have been satisfactorily completed
- FT = total number of software functional (modular) requirements
Requirements Traceability
This measure aids in identifying requirements that are either missing from, or in addition to, the original requirements.
TM = 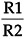 —100%
—100%
Where:
|
R1 |
= |
number of requirements met by the architecture |
|
R2 |
= |
number of original requirements |
Software Maturity Index
This measure is used to quantify the readiness of a software product. Changes from previous baselines to the current baselines are an indication of the current product stability.
SMI = 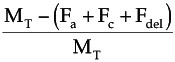
Where:
- SMI = software maturity index
- M T = number of software functions (modules) in the current delivery
- F a = number of software functions (modules) in the current delivery that are additions to the previous delivery
- F c = number of software functions (modules) in the current delivery that include internal changes from a previous delivery
- F del = number of software functions (modules) in the previous delivery that are deleted in the current delivery
- SMI can be estimated as:
SMI =
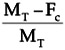
Number of Conflicting Requirements
This measure is used to determine the reliability of a software system resulting from the software architecture under consideration, as represented by a specification based on the entity-relationship-attributed model. What is required is a list of the system's inputs, its outputs, and a list of the functions performed by each program. The mappings from the software architecture to the requirements are identified. Mappings from the same specification item to more than one differing requirement are examined for requirements inconsistency. Additionally, mappings from more than one specification item to a single requirement are examined for specification inconsistency.
Cyclomatic Complexity
This measure is used to determine the structured complexity of a coded module. The use of this measure is designed to limit the complexity of the module, thereby promoting understandability of the module.
C = E - N + 1
Where:
|
C |
= |
complexity |
|
N |
= |
number of nodes (sequential groups of program statements) |
|
E |
= |
number of edges (program flows between nodes) |
Design Structure
This measure is used to determine the simplicity of the detailed design of a software program. The values determined can be used to identify problem areas within the software design.
DSM = 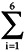 W i D i
W i D i
Where:
|
DSM |
= |
design structure measure |
|
P1 |
= |
total number of modules in program |
|
P2 |
= |
number of modules dependent on input or output |
|
P3 |
= |
number of modules dependent on prior processing (state) |
|
P4 |
= |
number of database elements |
|
P5 |
= |
number of nonunique database elements |
|
P6 |
= |
number of database segments |
|
P7 |
= |
number of modules not single entrance /single exit |
The design structure is the weighted sum of six derivatives determined using the primitives given above.
|
D 1 |
= |
designed organized top-down |
|
D 2 |
= |
module dependence (P2/P1) |
|
D 3 |
= |
module dependent on prior processing (P3/P1) |
|
D 4 |
= |
database size (P5/P4) |
|
D 5 |
= |
database compartmentalization (P6/P4) |
|
D 6 |
= |
module single entrance/exit (P7/P1) |
The weights (W i ) are assigned by the user based on the priority of each associated derivative. Each W i has a value between 0 and 1.
Test Coverage
This is a measure of the completeness of the testing process, from both a developer's and user's perspective. The measure relates directly to the development, integration, and operational test stages of product development.

Where:
- Program functional primitives are either modules, segments, statements, branches, or paths
- Data functional primitives are classes of data
- Requirement primitives are test cases or functional capabilities
Data or Information Flow Complexity
This is a structural complexity or procedural complexity measure that can be used to evaluate the information flow structure of large-scale systems, the procedure and module information flow structure, the complexity of the interconnections between modules, and the degree of simplicity of relationships between sub-systems, and to correlate total observed failures and software reliability with data complexity.
Weighted IFC = Length — (Fan-in — Fan-out) 2
Where:
- IFC = information flow complexity
- Fan-in = local flows into a procedure + number of data structures from which the procedures retrieves data
- Fan-out = local flows from a procedure + number of data structures that the procedure updates
- Length = number of source statements in a procedure (excluding comments)
The flow of information between modules or sub-systems needs to be determined either through the use of automated techniques or charting mechanisms. A local flow from module A to B exists if one of the following occurs:
- A calls B.
- B calls A, and A returns a value to B that is passed by B.
- Both A and B are called by another module that passes a value from A to B.
Mean Time to Failure
This measure is the basic parameter required by most software reliability models. Detailed record keeping of failure occurrences that accurately track time (calendar or execution) at which the faults manifest themselves is essential.
Software Documentation and Source Listings
The objective of this measure is to collect information to identify the parts of the software maintenance products that may be inadequate for use in a software maintenance environment. Questionnaires are used to examine the format and content of the documentation and source code attributes from a maintainability perspective.
The questionnaires examine the following product characteristics:
- Modularity
- Descriptiveness
- Consistency
- Simplicity
- Expandability
- Testability
Two questionnaires ” the Software Documentation Questionnaire and the Software Source Listing Questionnaire ” are used to evaluate the software products in a desk audit.
For the software documentation evaluation, the resource documents should include those that contain the program design specifications, program testing information and procedures, program maintenance information, and guidelines used in the preparation of the documentation. Typical questions from the questionnaire include:
- The documentation indicates that data storage locations are not used for more than one type of data structure.
- Parameter inputs and outputs for each module are explained in the documentation.
- Programming conventions for I/O processing have been established and followed.
- The documentation indicates the resource (storage, timing, tape drives , disks, etc.) allocation is fixed throughout program execution.
- The documentation indicates that there is a reasonable time margin for each major time-critical program function.
- The documentation indicates that the program has been designed to accommodate software test probes to aid in identifying processing performance.
The software source listing evaluation reviews either high-order language or assembler source code. Multiple evaluations using the questionnaire are conducted for the unit level of the program (module). The modules selected should represent a sample size of at least 10 percent of the total source code. Typical questions include:
- Each function of this module is an easily recognizable block of code.
- The quantity of comments does not detract from the legibility of the source listings.
- Mathematical models as described and derived in the documentation correspond to the mathematical equations used in the source listing.
- Esoteric (clever) programming is avoided in this module.
- The size of any data structure that affects the processing logic of this module is parameterized.
- Intermediate results within this module can be selectively collected for display without code modification.
IT DEVELOPER S LIST OF METRICS
McCabe s Complexity Metric
McCabe's [1976] proposal for a cyclomatic complexity number was the first attempt to objectively quantify the "flow of control" complexity of software.
The metric is computed by decomposing the program into a directed graph that represents its flow of control. The cyclomatic complexity number is then calculated using the following:
V(g) = Edges - Nodes + 2
In its shortened form, the cyclomatic complexity number is a count of decision points within a program with a single entry and a single exit plus one.
Halstead s Effort Metric
In the 1970s, Halstead [1976] developed a theory regarding the behavior of software. Some of his findings evolved into software metrics. One of these is referred to as "Effort" or just "E," and is a well-known complexity metric.
The Effort measure is calculated as:
E = Volume/Level
where Volume is a measure of the size of a piece of code and Level is a measure of how "abstract" the program is. The level of abstracting varies from almost zero (0) for programs with low abstraction, to almost one (1) for programs that are highly abstract.
SUMMARY
This chapter provides a detailed reference listing for pertinent CM and software engineering metrics.
REFERENCES
[Halstead 1977] Halstead, M., Elements of Software Science, Elsevier, New York, 1977 .
[IEEE 1989] IEEE Guide for the Use of IEEE Standard Dictionary of Measures to Produce Reliable Software, Standard 982.2-1988, June 12, 1989 , IEEE Standards Department, Piscatawy, NJ.
[IEEE 1988] IEEE Standard of Measures to Produce Reliable Software, Standard 982.1-1988, IEEE Standards Department, Piscataway, NJ.
[McCabe 1976] McCabe, T., "A Complexity Measure," IEEE Transactions on Software Engineering , 308 “320 , December 1976 .
[Pfleeger and McGowan 1990] Pfleeger, S.L. and C. McGowan, "Software Metrics in the Process Maturity Framework," Journal of Systems Software , 12, 255 “261, 1990 .
Note : The information contained within the IEEE standards metrics section is copyrighted information of the IEEE, extracted from IEEE Std. 982.1 “1988, IEEE Standard Dictionary of Measures to Produce Reliable Software. This information was written within the context of IEEE Std 982.1 “1988 and the IEEE takes no responsibility for or liability for damages resulting from the reader's misinterpretation of said information resulting from the placement and context of this publication. Information is reproduced with the permission of the IEEE.
Preface
- Introduction to Software Configuration Management
- Project Management in a CM Environment
- The DoD CM Process Model
- Configuration Identification
- Configuration Control
- Configuration Status Accounting
- A Practical Approach to Documentation and Configuration Status Accounting
- Configuration Verification and Audit
- A Practical Approach to Configuration Verification and Audit
- Configuration Management and Data Management
- Configuration Change Management
- Configuration Management and Software Engineering Standards Reference
- Metrics and Configuration Management Reference
- CM Automation
- Appendix A Project Plan
- Appendix C Sample Data Dictionary
- Appendix D Problem Change Report
- Appendix E Test Plan
- Appendix G Sample Inspection Plan
- Appendix I System Service Request
- Appendix J Document Change Request (DCR)
- Appendix K Problem/Change Report
- Appendix L Software Requirements Changes
- Appendix M Problem Report (PR)
- Appendix N Corrective Action Processing (CAP)
- Appendix P Project Statement of Work
- Appendix Q Problem Trouble Report (PTR)
- Appendix S Sample Maintenance Plan
- Appendix T Software Configuration Management Plan (SCMP)
- Appendix U Acronyms and Glossary
- Appendix V Functional Configuration Audit (FCA) Checklist
- Appendix W Physical Configuration Audit (PCA) Checklist
- Appendix X SCM Guidance for Achieving the Repeatable Level on the Software
- Appendix Y Supplier CM Market Analysis Questionnaire
EAN: 2147483647
Pages: 235
