Managing Business Logic with Struts
Overview
| Important |
This is a reminder that all source code and support for this book can now be found at http://www.apress.com, even though references within the chapters may point to http://www.wrox.com. |
So far we've seen how to use the Struts framework to facilitate the construction of an application. We've also examined the basic workflow of a Struts-based request along with the different components needed to carry out a user's requested action. However, while the Struts framework is a powerful tool for building applications, it is still only a tool. Using the Struts framework does not relieve you of the responsibility for architecting the application.
A framework like Struts is meant to promote rapid application development as well as ease the maintenance and extensibility of an application. However, if there is no forethought on how the business logic for an application is going to be built, it becomes very easy to "lock" an application's business logic into the Struts framework.
As a result, a development team using Struts might be able to quickly build the initial applications, but later, they will find that they cannot easily reuse the functionality in a non-Struts framework. A framework provides structure, but it also defines boundaries, constraints, and dependencies, which will cause a significant amount of problems, if they are not considered early on.
This chapter is going to demonstrate how to use several common J2EE design patterns, to ensure that the application's business logic is not too tightly coupled with the Struts framework. Specifically we are going to look at:
- Common implementation mistakes made while implementing a Struts Action class. We will examine how, even with the use of the Struts development framework, the Concern Slush and Tier Leakage antipatterns can still form (Refer to Chapter 1 for the discussion on the various antipatterns).
- How to refactor these antipatterns into a more maintainable framework, which will allow us to reuse business logic across both Struts and non-Struts applications.
The design patterns that will be covered in this chapter include:
- The Business Delegate pattern
- The Service Locator pattern
- The Session Faade pattern
All these design patterns will be implemented with the help of the JavaEdge application code.
Business Logic Antipatterns and Struts
The Struts framework's Model-View-Controller implementation significantly reduces the chance that the Concern Slush or Tier Leakage antipattern will form. Recollecting the discussion from Chapter 1, the Concern Slush antipattern forms when the system architect does not provide a framework separating the presentation, business, and data access logic into well-defined application tiers. As a result, it becomes difficult to reuse and support the code.
The Tier Leakage antipattern occurs when an application developer exposes the implementation details of one application tier to another tier. For example, when the presentation logic of the application, which is a JSP page, creates an EJB to invoke some business logic on its behalf. While the business logic for the page has been cleanly separated from the JSP code, the JSP page is exposed to the complexities of locating and instantiating the EJB. This creates a tight dependency between the presentation tier and the business tier.
The Struts framework does an excellent job of enforcing a clean separation of presentation and business logic within an application. All the presentation logic is encapsulated in JSP pages using Struts tag libraries to simplify the development effort. All business logic is placed in a Struts Action class. The JSP pages in the application are never allowed to invoke the business logic directly; it's the responsibility of the ActionServlet.
However, in a Struts-based application, the way in which the business logic is implemented is still decided by the application developer. Often, a developer who is new to the Struts framework will place all of the business and data-access logic into a Struts Action class. They need to consider the long-term architectural consequences of doing this. Without careful forethought and planning, antipatterns such as Concern Slush and Tier Leakage can still manifest themselves within an application.
At this point, you might be asking the question, "I thought the Struts development framework was supposed to refactor these antipatterns?" The answer is yes, to a point.
| Important |
Using a development framework does not relieve the development team of the responsibility of architecting the application. A development team needs to ensure that its use of a framework does not create dependencies that make it difficult to reuse application logic outside of the framework. The application architect is still responsible for enforcing the overall integrity of the application's architecture. A development framework is a tool, not a magic bullet. |
When development teams make the decision to adopt a development framework they often rush in and immediately begin writing code. They have not cleanly separated the "core" business logic from the framework itself. As a result, they often find themselves going through all sorts of contortions to reuse the code in non-framework-based applications.
Let's look at two code examples that can be precursors to the formation of the Concern Slush and Tier Leakage antipatterns in Struts.
Concern Slush and Struts
The Concern Slush antipattern can manifest itself in a Struts-based application, when the developer fails to cleanly separate the business and data access logic from the Struts Action class. Let's revisit the Post a Story page that was explored in the Chapter 3. The following is an example of how the PostStory.java action could be implemented:
package com.wrox.javaedge.struts.poststory;
import org.apache.struts.action.*;
import javax.servlet.http.*;
import javax.naming.*;
import java.sql.*;
import javax.sql.*;
import com.wrox.javaedge.story.*;
import com.wrox.javaedge.member.*;
import com.wrox.javaedge.story.ejb.PrizeManager;
public class PostStory extends Action {
public ActionForward perform(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response) {
PostStoryForm postStoryForm = (PostStoryForm) form;
HttpSession session = request.getSession();
MemberVO memberVO = (MemberVO) session.getAttribute("memberVO");
if (this.isCancelled(request)) {
return (mapping.findForward("poststory.success"));
}
Connection conn = null;
PreparedStatement ps = null;
try {
Context ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup("java:/MySQLDS");
conn = ds.getConnection();
conn.setAutoCommit(false);
StringBuffer insertSQL = new StringBuffer();
/*
* Please note that this code is only an example. The SQL code assumes
* that the story table is using an auto-generated key. However, in
* the JavaEdge application we use ObjectRelationalBridges Sequence
* capabilities to generate a key. This code will not work unless you
* modify the story table to use an auto-generated key for the
* story_id column
*/
insertSQL.append("INSERT INTO story( ");
insertSQL.append(" member_id , ");
insertSQL.append(" story_title , ");
insertSQL.append(" story_into , ");
insertSQL.append(" story_body , ");
insertSQL.append(" submission_date ");
insertSQL.append(") ");
insertSQL.append("VALUES( ");
insertSQL.append(" ? , ");
insertSQL.append(" ? , ");
insertSQL.append(" ? , ");
insertSQL.append(" ? , ");
insertSQL.append(" CURDATE() ) ");
ps = conn.prepareStatement(insertSQL.toString());
ps.setLong(1, memberVO.getMemberId().longValue());
ps.setString(2, postStoryForm.getStoryTitle());
ps.setString(3, postStoryForm.getStoryIntro());
ps.setString(4, postStoryForm.getStoryBody());
ps.execute();
conn.commit();
checkStoryCount(memberVO);
} catch(SQLException e) {
try{
if (conn != null) conn.rollback();
} catch(SQLException ex) {}
System.err.println("A SQL exception has been raised in " +
"PostStory.perform(): " + e.toString());
return (mapping.findForward("system.failure"));
} catch(NamingException e) {
System.err.println("A Naming exception has been raised in " +
"PostStory.perform(): " + e.toString());
return (mapping.findForward("system.failure"));
} finally {
try {
if (ps != null) ps.close();
if (conn != null) conn.close();
} catch(SQLException e) {}
}
return (mapping.findForward("poststory.success"));
}
private void checkStoryCount(MemberVO memberVO)
throws SQLException, NamingException {
Connection conn = null;
PreparedStatement ps = null;
ResultSet rs = null;
try {
Context ctx = new InitialContext();
DataSource ds = (DataSource) ctx.lookup("java:/MySQLDS");
conn = ds.getConnection();
StringBuffer selectSQL = new StringBuffer();
selectSQL.append("SELECT ");
selectSQL.append(" count(*) total_count ");
selectSQL.append("FROM ");
selectSQL.append(" story where member_id=? ");
ps = conn.prepareStatement(selectSQL.toString());
ps.setLong(1, memberVO.getMemberId().longValue());
rs = ps.executeQuery();
int totalCount = 0;
if (rs.next()) {
totalCount = rs.getInt("total_count");
}
boolean TOTAL_COUNT_EQUAL_1000 = (totalCount==1000);
boolean TOTAL_COUNT_EQUAL_5000 = (totalCount==5000);
if (TOTAL_COUNT_EQUAL_1000 || TOTAL_COUNT_EQUAL_5000) {
//Notify Prize Manager
PrizeManager prizeManager = new PrizeManager();
prizeManager.notifyMarketing(memberVO, totalCount);
}
} catch(SQLException e) {
System.err.println("A SQL exception has been raised in " +
" PostStory.checkStoryCount(): " + e.toString());
throw e;
} catch(NamingException e) {
System.err.println("A Naming exception has been raised in " +
" PostStory.checkStoryCount(): " +
e.toString());
throw e;
} finally {
try {
if (rs != null) rs.close();
if (ps != null) ps.close();
if (conn != null) conn.close();
} catch(SQLException e) {}
}
}
}
The above perform() method performs two very simple functions:
- It inserts the data submitted by the user on the Post a Story page using the standard JDBC and SQL calls. From our discussions in Chapter 3, we know that the submitted data has already been validated by the validate() method on the PostForm class.
- It checks, via a call to checkStoryCount(), if the total number of stories submitted by a JavaEdge member is at the 1000 or 5000 mark. On the 1000th and 5000th story submitted by the user, the marketing department is notified via the PrizeManager class.
The PrizeManager class integrates several legacy systems throughout the organization and ultimately sends the user $100 dollars to spend at the bookstore on the JavaEdge site.
From a functional perspective, the code for the perform() method works well. However, from an architectural viewpoint, the implementation for the PostStory class shown above is a mess. There are several problems present in the above code that will eventually cause significant long-term maintenance and extensibility problems. These problems include:
- The entire business logic for adding a story and checking the total number of stories submitted by a user is embedded in the Struts Action class. This has several architectural consequences:
- If the development team wants to reuse this logic, it must use the PostStory class (even if it does not really fit into the other application); refactor the business logic into a new Java class; or perform the oldest form of reuse: cut and paste.
- The business logic for the application is tied directly to the Struts framework. If the development team decides to move the application from the Struts framework, it is looking at a significant amount of work.
- There is no clean separation of the business and data access logic. While these two pieces of logic are cleanly separated by Struts from the presentation tier, there is still a significant amount of dependency being created between the business logic and the data access logic:
- The Action class has intimate knowledge of which data access technology is being used to access the data used by JavaEdge application. If the development team wants to switch to a new data access technology at some point, it must revisit every single place in the application that is interacting with a database.
- The Action class has SQL Data Definition Language (DDL) embedded in it. Any changes to the underlying table structures that the JavaEdge application is using can send ripple effects throughout the system.
| Important |
A ripple effect is when there is such tight dependency between application modules or application code and data structures that a change to one piece of code sends you hunting throughout the rest of application for other areas that must be modified to reflect that change. |
For example, if a data relationship between two tables were to change, such as a one-to-many relationship being refactored into a many-to-many relationship, any SQL code embedded in the application that accessed these tables would need to be visited and probably refactored.
Abstraction is the key to avoiding a ripple effect. If the SQL logic for the application is cleanly hidden behind a set of interfaces that did not expose the actual structure of the database table to the application, the chance of a ripple effect occurring is much less. In the next chapter we will demonstrate how to use some basic design patterns to achieve this goal.
The code shown above is difficult to follow and maintain. Even though the business logic for the Post A Story page is very simplistic, it still took almost two pages of code to implement. Keep the following in mind, while building your first Struts-based application:
| Important |
Development frameworks like Struts are used for building applications. However, the business logic in applications often belongs to the enterprise and not just a single application. How many times have you seen the business logic cut across multiple applications within an organization? Be wary of embedding too much business logic directly within Struts. Otherwise you might find that reuse of business logic becomes extremely difficult. |
Tier Leakage and Struts
Many development teams will get an uneasy feeling about the amount of business logic being placed in the Struts Action class. They might have already run into situations where they have the same business logic being reused in many of their applications.
The natural tendency is to refactor the Struts code and move it into a component-based architecture (such as Enterprise JavaBeans) or services-based architecture (such as web services). This moves the business logic out of the Struts Action class and makes it easily available to the other applications. Let's refactor the PostStory class and move all of the business logic into an Enterprise JavaBean called StoryManager. The code for the rewritten PostStory class is shown below:
package com.wrox.javaedge.struts.poststory;
import org.apache.struts.action.*;
import javax.servlet.http.*;
import javax.naming.*;
import javax.ejb.*;
import java.rmi.*;
import javax.rmi.*;
import com.wrox.javaedge.common.*;
import com.wrox.javaedge.story.*;
import com.wrox.javaedge.member.*;
import com.wrox.javaedge.story.ejb.*;
public class PostStory extends Action {
public ActionForward perform(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response){
if (this.isCancelled(request)) {
return (mapping.findForward("poststory.success"));
}
PostStoryForm postStoryForm = (PostStoryForm) form;
HttpSession session = request.getSession();
MemberVO memberVO = (MemberVO) session.getAttribute("memberVO");
try {
Context ctx = new InitialContext();
Object ref = ctx.lookup("storyManager/StoryManager");
StoryManagerHome storyManagerHome =
(StoryManagerHome) PortableRemoteObject.narrow(ref,
StoryManagerHome.class);
StoryManager storyManager = storyManagerHome.create();
storyManager.addStory(postStoryForm, memberVO);
} catch(ApplicationException e){
System.err.println("An Application exception has been raised in " +
"PostStory.perform(): " + e.toString());
return (mapping.findForward("system.failure"));
} catch(NamingException e) {
System.err.println("A Naming exception has been raised in " +
"PostStory.perform(): " + e.toString());
return (mapping.findForward("system.failure"));
} catch(RemoteException e) {
System.err.println("A Remote exception has been raised in " +
"PostStory.perform(): " + e.toString());
return (mapping.findForward("system.failure"));
} catch(CreateException e) {
System.err.println("A Create exception has been raised in " +
"PostStory.perform(): " + e.toString());
return (mapping.findForward("system.failure"));
}
return (mapping.findForward("poststory.success"));
}
}
The above code appears to solve all the problems defined earlier. It is much easier to read and understand. The Concern Slush antipattern, which was present earlier, has been refactored. By moving the business logic out of the PostStory.perform() method and into the StoryManager EJB, it can be reused more easily across multiple applications.
However, the rewritten PostStory class shown above still has flaws in it that can lead to a Tier Leakage antipattern. The refactored perform() method has intimate knowledge of how the business logic is being invoked. The entire business logic is contained within the EJB, and the application developer has to perform a JNDI lookup and then retrieve a reference to the EJB by invoking its create() method.
What happens if the development team later wants to rewrite the business logic and wrap it to use a web service instead of an EJB? Since the PostStory action class has direct knowledge that the business logic it needs is contained within an EJB, the class must be rewritten to now invoke a web service instead of an EJB.
| Note |
As you will see shortly, what is needed here is some kind of proxy that will sit between the framework class (the PostStory class) and the actual business logic (the EJB). The proxy should completely abstract how the business logic is being invoked. This proxy, also known as the Business Delegate pattern, will be discussed shortly. |
Another problem with the code shown above is that the addStory() method is taking the PostStoryForm class as an input parameter:
storyManager.addStory(postStoryForm, memberVO);
This creates a dependency between the business logic, which is responsible for adding a story to the JavaEdge application, and the Struts framework in which the application is built. If the developers want to use the StoryManager EJB in a non-Struts-based application, they would not be able to do so easily.
| Important |
Even when choosing to use a Java open source development framework it is important not to create tight dependencies between the framework and business logic. Applications rarely exist in a vacuum. They often have to be integrated with the other systems being maintained by the IT department. This integration often means reusing code that has already been written. Tight-coupling of business logic with framework can limit your ability to reuse that business logic in applications that are not built with your chosen framework. |
This is why it is still extremely important to apply the architectural principals of abstraction and encapsulation, even when building Struts-based applications. Antipatterns are subtle beasts. It is rare for developers to feel the full impact of an antipattern in the first application that they build. Instead, the problems caused by an antipattern will suddenly manifest themselves, when the development team has already deployed several applications and needs to integrate or reuse the code in these applications. That is when the antipattern and the full scope of the necessary rework is revealed.
Separating Business Logic from Struts
The challenge is to build our Struts application in such a way that the business logic for the application becomes independent of the actual Struts framework. The Action classes in our Struts application should only be a plug-in point for the business logic.
Fortunately, common J2EE design patterns provide a readily available solution. These patterns are particularly well suited for solving many of the dependencies between the framework and the business logic as were discussed earlier. In this chapter, we are not going to cover all the J2EE design patterns, in great detail. Instead, we are going to discuss the patterns that are most appropriate for use in building Struts-based applications.
The design patterns that are going to be discussed include:
- The Business Delegate pattern
- The Service Locator pattern
- The Session Faade pattern
The diagram below demonstrates how the above J2EE design patterns can be assembled to partition the business logic used in the application from the Struts development framework:
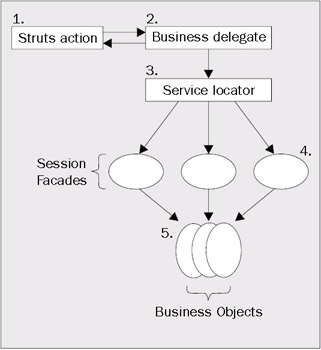
Let's revisit the whole process of how an end user adds a new story to the JavaEdge application, using the architectural model shown above:
- The user makes a request to add a story. The perform() method in the PostStory action class is invoked. However, in the above model, the PostStory action does not contain the actual code for adding the user's story and checking the number of stories submitted by the user. Instead, the PostStory class instantiates a Business Delegate that carries out this business logic.
- The Business Delegate is a Java class that shields the PostStory action class from knowing how the business logic is created and executed. In the section on Tier Leakage and Struts earlier, the code for adding a story was moved to the StoryManager EJB. The Business Delegate class would be responsible for looking up this EJB via JNDI. All the public methods in the StoryManager EJB should be available to the Business Delegate. All the public method calls in the Business Delegate would be forwarded to the StoryManager EJB.
- The Business Delegate does not have the direct knowledge of how to look up the StoryManager EJB. Instead, it uses a class called the ServiceLocator. The ServiceLocator is used to look up the various resources within the application. Examples of resources looked up and returned by a ServiceLocator class include the home interface for EJBs and DataSource objects for retrieving JDBC connections.
- The EJBs returned by the ServiceLocator class are known as Session Faades. A Session Faade is an EJB that wraps a complex business process involving multiple Java objects behind a simple-to-use coarse-grained interface. In the PostStory example, the StoryManager EJB is a Session Faade that hides all of the steps involved in adding a story to the JavaEdge application.
- The business objects are responsible for carrying out the individual steps in the business action requested by the end user. Business-logic classes should never be allowed to talk directly to any of the databases used by the application. Instead, theses classes should interact with the database via a data-persistence faade.
At a first glance, this might seem like a significant of work for carrying out even the simplest task. However, the abstraction provided by these design patterns is tremendous.
| Important |
The effects of good architecture (and bad) are not immediately apparent. However, the time spent in properly abstracting your applications can have huge pay offs in terms of the maintainability and extensibility of your code. |
The J2EE design patterns, demonstrated in the above diagram, completely separate the business logic from the Struts framework and ensure that the business logic for the whole application has no intimate knowledge of the data-access code being used.
Implementing the Design Patterns
The remaining sections of this chapter are going to discuss the implementations of the J2EE design patterns discussed so far. We will be refactoring the PostStory action class so that it uses a Business Delegate to invoke the logic that it needs to carry out the user request.
The diagram below, which looks similar to the previous one, demonstrates the actions that takes place when the perform() method of the PostStory class is invoked:
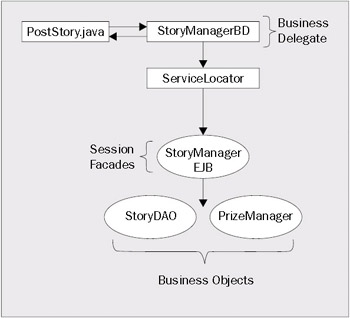
Implementing the Business Delegate Pattern
A Business Delegate pattern hides the complexity of instantiating and using the enterprise services such as EJBs or web services from the application consuming the service. A Business Delegate pattern is very straightforward. It is implemented by wrapping an already existing service behind a plain Java class. Each public method available in the service is mapped to a public method in the Business Delegate.
The code below, called StoryManagerBD.java, demonstrates how to wrap an EJB called StoryManager. The StoryManager EJB is responsible for adding the stories and comments submitted by JavaEdge users to the JavaEdge database.
The details of the JavaEdge database will be covered in the next chapter.
package com.wrox.javaedge.ejb;
import javax.naming.*;
import javax.rmi.*;
import java.rmi.*;
import javax.ejb.*;
import com.wrox.javaedge.story.*;
import com.wrox.javaedge.member.*;
import com.wrox.javaedge.common.*;
import com.wrox.javaedge.story.ejb.*;
public class StoryManagerBD {
StoryManager storyManager = null;
public StoryManagerBD() throws ApplicationException {
try {
Context ctx = new InitialContext();
Object ref = ctx.lookup("storyManager/StoryManager");
StoryManagerHome storyManagerHome = (StoryManagerHome)
PortableRemoteObject.narrow(ref, StoryManagerHome.class);
storyManager = storyManagerHome.create();
} catch(NamingException e) {
throw new ApplicationException("A Naming exception has been raised in " +
"StoryManagerBD constructor: " +
e.toString());
} catch(RemoteException e) {
throw new ApplicationException("A Remote exception has been raised in " +
"StoryManagerBD constructor: " +
e.toString());
} catch(CreateException e) {
throw new ApplicationException("A Create exception has been raised in " +
"StoryManagerBD constructor: " +
e.toString());
}
}
public void addStory(StoryVO storyVO) throws ApplicationException {
try {
storyManager.addStory(storyVO);
} catch(RemoteException e) {
throw new ApplicationException("A Remote exception has been raised in " +
"StoryManagerBD.addStory(): " +
e.toString());
}
}
public void addComment(StoryVO storyVO, StoryCommentVO storyCommentVO)
throws ApplicationException{
try {
storyManager.addComment(storyVO, storyCommentVO);
} catch(RemoteException e) {
throw new ApplicationException("A Remote exception has been raised in "+
"StoryManagerBD.addComment(): " +
e.toString());
}
}
}
The StoryManagerBD class looks up the home interface of the StoryManager EJB in its constructor. Using the retrieved home interface, the StoryManager EJB is created. A reference to the newly created bean will be stored in the private attribute, called storyManager, of the StoryManagerBD class:
public StoryManagerBD() throws ApplicationException{
try{
Context ctx = new InitialContext();
Object ref = ctx.lookup("storyManager/StoryManager");
StoryManagerHome storyManagerHome = (StoryManagerHome)
PortableRemoteObject.narrow(ref, StoryManagerHome.class);
storyManager = storyManagerHome.create();
}
Handling Exceptions in the Business Delegate
While looking up and creating a reference to the StoryManager EJB, any exceptions that are raised will be caught and thrown back as an ApplicationException:
} catch(NamingException e) {
throw new ApplicationException("A Naming exception has been raised in "+
"StoryManagerBD constructor: " +
e.toString());
}
An ApplicationException is a generic exception that will be used to wrap any exceptions raised while the Business Delegate is processing a request.
It is extremely important that any raised exception be caught and thrown back as an ApplicationException. The Business Delegate design pattern is supposed to simplify the process of invoking the business logic for an application and hide the underlying implementation details.
The ApplicationException class is used to "level" all exceptions thrown by the business logic tier to a single type of exception. By doing this, classes such as PostStory only need to know how to deal with one type of exception and will not be unnecessarily exposed to implementation details of the business tier (that the business logic is implemented using EJBs or web services, etc.).
In our example, this means that the PostStory class would have to capture CreateException, RemoteException, and NamingException, which could be thrown while using the Business Delegate pattern. This would give the PostStory class intimate knowledge of how the business logic for the request was being carried out.
| Important |
Never expose an application that uses a Business Delegate to any of the implementation details wrapped by the delegate. This includes any exceptions that might be raised during the course of processing a request. |
The ApplicationException is used to notify the application, which consumes a service provided by the Business Delegate, that some kind of error has occurred. It is up to the application to decide how it will respond to an unexpected exception.
Avoiding Dependencies
Another noticeable part of our implementation of the StoryManagerBD class is that each of the public methods is just a simple pass through to the underlying service (in this case, a stateless EJB). However, none of these public methods takes a class that can tie the business logic to a particular front-end technology or development framework.
A very common mistake while implementing the first Struts application is to pass an ActionForm or HttpServletRequest object to the code executing the business logic. Passing in a Struts-based class, such as ActionForm, ties the business logic directly to the Struts framework. Passing in an HttpServletRequest object creates a dependency where the business logic is only usable by a web application. Both of these situations can be easily avoided by allowing "neutral" objects, which do not create these dependencies, to be passed into a Business Delegate implementation.
After the StoryManagerBD has been implemented, let's look at how the PostStory class has changed:
package com.wrox.javaedge.struts.poststory;
import java.util.Vector;
import org.apache.struts.action.*;
import javax.servlet.http.*;
import com.wrox.javaedge.common.*;
import com.wrox.javaedge.story.*;
import com.wrox.javaedge.member.*;
import com.wrox.javaedge.story.*;
public class PostStory extends Action {
public ActionForward perform(ActionMapping mapping,
ActionForm form,
HttpServletRequest request,
HttpServletResponse response) {
if (this.isCancelled(request)){
return (mapping.findForward("poststory.success"));
}
PostStoryForm postStoryForm = (PostStoryForm) form;
HttpSession session = request.getSession();
MemberVO memberVO = (MemberVO) session.getAttribute("memberVO");
try {
StoryVO storyVO = new StoryVO();
storyVO.setStoryIntro(postStoryForm.getStoryIntro());
storyVO.setStoryTitle(postStoryForm.getStoryTitle());
storyVO.setStoryBody(postStoryForm.getStoryBody());
storyVO.setStoryAuthor(memberVO);
storyVO.setSubmissionDate(new java.sql.Date(System.currentTimeMillis()));
storyVO.setComments(new Vector());
StoryManagerBD storyManager = new StoryManagerBD();
storyManager.addStory(storyVO);
} catch(Exception e) {
System.err.println("An application exception has been raised in " +
"PostStory.perform(): " + e.toString());
return (mapping.findForward("system.failure"));
}
return (mapping.findForward("poststory.success"));
}
}
In the redesigned PostStory class we do introduce a little bit more code because we have to copy the data from the PostStoryForm class to a StoryVO and then pass that value object into the StoryManagerBD's addStory() method. However, even though we are writing more code we have broken a dependency between our Struts Action class and a piece of business logic.
The StoryManagerBD, as it no longer has the PostStoryForm class passed in as a parameter, can be reused in a non-Struts based application. This small piece of abstraction avoids creating a dependency on a Struts-specific class.
| Important |
Abstraction, when applied appropriately, gives our applications the ability to evolve gracefully as the business and technical requirements of the application change over time. |
Implementing the Service Locator Pattern
Implementing a Business Delegate can involve a significant amount of repetitive coding. Every Business Delegate constructor has to look up the service that it is going to wrap, via a JNDI call. The Service Locator pattern mitigates the need for this coding and, more importantly, allows the developer to hide the implementation details associated with looking up a service. A Service Locator can be used to hide a variety of different resources such as:
- JNDI lookups for an EJBHome interface
- JNDI lookups associated with finding a JDBC DataSource for retrieving a database connection
- Object creation associated with:
- Looking up an Apache Axis Call class for invoking a web service
- Retrieving a Persistence Broker/Manager for ObjectRelational Management tools, such as the open source package ObjectRelationalBridge (OJB), Oracle's TopLink, etc.
In addition, the implementation of a Service Locator pattern allows you to implement optimizations to your code without having to revisit the multiple places in your application.
For instance, performing a JNDI lookup is expensive. If you allow your Business Delegate classes to directly invoke a JNDI, to implement a caching mechanism that minimizes the number of JNDI calls would involve a significant amount of rework. However, if you centralize all of your JNDI lookup calls behind a Service Locator pattern, you would be able to implement the optimizations and caching and only have to touch one piece of code. A Service Locator pattern is easy to implement. For the time it takes to implement the pattern, the reduction in overall maintenance costs of the application can easily exceed the costs of writing the class.
The Business Delegate class also allows you to isolate vendor-specific options for looking up JNDI components; thereby limiting the effects of "vendor lock-in".
Shown below is a sample Service Locator implementation that abstracts how an EJB home interface is looked up via JNDI. The Service Locator implementation for the JavaEdge application provides the methods for looking up EJBHome interfaces and JDBC database connections:
package com.wrox.javaedge.story.ejb;
import java.sql.*;
import javax.sql.DataSource;
import java.util.Hashtable;
import javax.naming.*;
import javax.ejb.*;
import javax.rmi.*;
import org.apache.ojb.broker.*;
import com.wrox.javaedge.story.ejb.StoryManagerHome;
import com.wrox.javaedge.common.*;
public class ServiceLocator {
private static ServiceLocator serviceLocatorRef = null;
private static Hashtable ejbHomeCache = null;
private static Hashtable dataSourceCache = null;
//Enumerating the different services available from the Service Locator
public static final int STORYMANAGER = 0;
public static final int JAVAEDGEDB = 1;
//The JNDI Names used to lookup a service
private static final String STORYMANAGER_JNDINAME =
"storyManager/StoryManager";
private static final String JAVAEDGEDB_JNDINAME="java:/MySQLDS";
//References to each of the different EJB Home Interfaces
private static final Class STORYMANAGERCLASSREF = StoryManagerHome.class;
static {
serviceLocatorRef = new ServiceLocator();
}
//Private Constructor for the ServiceLocator
private ServiceLocator() {
ejbHomeCache = new Hashtable();
dataSourceCache = new Hashtable();
}
/*
* The Service Locator is implemented as a Singleton. The getInstance()
* method will return the static reference to the Service Locator stored
* inside the ServiceLocator Class.
*/
public static ServiceLocator getInstance() {
return serviceLocatorRef;
}
/*
* The getServiceName will retrieve the JNDI name for a requested
* service. The service is indicated by the ServiceId passed into
* the method.
*/
static private String getServiceName(int pServiceId)
throws ServiceLocatorException {
String serviceName = null;
switch (pServiceId) {
case STORYMANAGER: serviceName = STORYMANAGER_JNDINAME;
break;
case JAVAEDGEDB: serviceName = JAVAEDGEDB_JNDINAME;
break;
default: throw new ServiceLocatorException(
"Unable to locate the service requested in " +
"ServiceLocator.getServiceName() method. ");
}
return serviceName;
}
/*
* Returns the EJBHome class reference for a requested service.
* If the method cannot make a match, it will throw a ServiceLocatorException.
*/
static private Class getEJBHomeRef(int pServiceId)
throws ServiceLocatorException {
Class homeRef = null;
switch (pServiceId) {
case STORYMANAGER: homeRef = STORYMANAGERCLASSREF;
break;
default: throw new ServiceLocatorException(
"Unable to locate the service requested in " +
"ServiceLocator.getEJBHomeRef() method. ");
}
return homeRef;
}
/*
* The getEJBHome() method will return an EJBHome interface for a requested
* service. If it cannot find the requested EJB, it will throw a
* ServiceLocator exception.
*
* The getEJBHome() method caches a requested EJBHome so that the first
* time an EJB is requested, a home interface will be retrieved and then
* be placed into a cache.
*/
public EJBHome getEJBHome(int pServiceId)
throws ServiceLocatorException {
//Trying to find the JNDI Name for the requested service
String serviceName = getServiceName(pServiceId);
EJBHome ejbHome = null;
try {
//Checking to see if I can find the EJBHome interface in cache
if (ejbHomeCache.containsKey(serviceName)) {
ejbHome = (EJBHome) ejbHomeCache.get(serviceName);
return ejbHome;
} else {
//If I could not find the EJBHome interface in the cache, look it
//up and then cache it.
Context ctx = new InitialContext();
Object jndiRef = ctx.lookup(serviceName);
Object portableObj =
PortableRemoteObject.narrow(jndiRef, getEJBHomeRef(pServiceId));
ejbHome = (EJBHome) portableObj;
ejbHomeCache.put(serviceName, ejbHome);
return ejbHome;
}
} catch(NamingException e) {
throw new ServiceLocatorException("Naming exception error in " +
"ServiceLocator.getEJBHome()", e);
} catch(Exception e) {
throw new ServiceLocatorException("General exception in " +
"ServiceLocator.getEJBHome", e);
}
}
/*
* The getDBConn() method will create a JDBC connection for the
* requested database. It too uses a caching algorithm to minimize
* the number of JNDI hits that it must perform.
*/
public Connection getDBConn(int pServiceId) throws ServiceLocatorException {
//Getting the JNDI Service Name
String serviceName = getServiceName(pServiceId);
Connection conn = null;
try {
// Check to see if the requested DataSource is in the cache
if (dataSourceCache.containsKey(serviceName)) {
DataSource ds = (DataSource) dataSourceCache.get(serviceName);
conn = ((DataSource)ds).getConnection();
return conn;
} else {
// The DataSource was not in the cache. Retrieve it from JNDI
// and put it in the cache.
Context ctx = new InitialContext();
DataSource newDataSource = (DataSource) ctx.lookup(serviceName);
dataSourceCache.put(serviceName, newDataSource);
conn = newDataSource.getConnection();
return conn;
}
} catch(SQLException e) {
throw new ServiceLocatorException("A SQL error has occurred in " +
"ServiceLocator.getDBConn()", e);
} catch(NamingException e) {
throw new ServiceLocatorException("A JNDI Naming exception has "+
"occurred in " +
"ServiceLocator.getDBConn()", e);
} catch(Exception e) {
throw new ServiceLocatorException("An exception has occurred " +
"in ServiceLocator.getDBConn()", e);
}
}
}
The Service Locator implementation shown above is built using the Singleton design pattern. This design pattern allows us to keep only one instance of a class per Java Virtual Machine (JVM). This instance is used to service all the requests for the entire JVM.
Since looking up the resources such as EJBs or DataSource objects is a common activity, implementing the ServiceLocator class pattern as a Singleton pattern prevents the needless creation of multiple copies of the same object doing the same thing. To implement the Service Locator as a Singleton, we need to first have a private constructor that will instantiate any resources being used by the ServiceLocator class:
private ServiceLocator() {
ejbHomeCache = new Hashtable();
dataSourceCache = new Hashtable();
}
The default constructor for the ServiceLocator class shown above is declared as private so that a developer cannot directly instantiate an instance of the ServiceLocator class. (We can have only one instance of the class per JVM.)
A Singleton pattern ensures that only one instance of an object is present within the virtual machine. The Singleton pattern is used to minimize the proliferation of large numbers of objects that serve a very narrow purpose. In the case of the Service Locator pattern, its sole job is to look up or create objects for other classes. It does not make sense to have a new Service Locator instance being created every time a user needs to carry out one of these tasks.
| Important |
The Service Locator pattern is a very powerful design pattern, but it tends to be overused. Inexperienced architects will make everything a Singleton implementation. Using a Singleton pattern can introduce re-entrancy problems in applications that are multi-threaded. One thread can alter the state of Singleton implementation while another thread is working. Now, a Singleton pattern can be made thread-safe through the use of Java synchronization blocks. However, synchronization blocks represent potential bottlenecks within an application as only one thread at a time can execute the code surrounded by a synchronization block. |
Our Service Locator implementation is going to use two Hashtables, ejbHomeCache and dataSourceCache, which respectively store EJBHome and DataSource interfaces. So, we initialize them in the default constructor of the ServiceLocator.
The constructor is called via an anonymous static block that is invoked the first time the ServiceLocator class is loaded by the JVM:
static {
serviceLocatorRef = new ServiceLocator();
}
This anonymous static code block invokes the constructor and sets a reference to a ServiceLocator instance, which is declared as a private attribute in the ServiceLocator class.
We use a method called getInstance() to retrieve an instance of ServiceLocator class stored in the serviceLocatorRef variable:
public static ServiceLocator getInstance(){
return serviceLocatorRef;
}
To retrieve an EJBHome interface, the getEJBHome() method in the ServiceLocator class is invoked. This method takes an integer value (pServiceId) that represents the EJB being requested. For our Service Locator implementation, all the available EJBs have a public static constant defined in the ServiceLocator class. For instance, the StoryManager EJB has the following constant value:
public static final int STORYMANAGER = 0;
The first action taken by the getEJBHome() method is to look up the JNDI name that will be used to retrieve a resource, managed by the Service Locator. The JNDI name is looked up by calling the getServiceName() method, into which the pServiceId parameter is passed.
String serviceName = getServiceName(pServiceId);
Once the JNDI service name is retrieved, the ejbHomeCache is checked to see if that EJBHome interface is already cached. If a hit is found, the method immediately returns with the EJBHome interface stored in the cache:
if (ejbHomeCache.containsKey(serviceName)) {
ejbHome = (EJBHome) ejbHomeCache.get(serviceName);
return ejbHome;
If the requested EJBHome interface is not located in the ejbHomeCache Hashtable, the getEJBHome() method will look up the interface, add it to the ejbHomeCache, and then return the newly retrieved interface back to the calling application code:
} else {
Context ctx = new InitialContext();
Object jndiRef = ctx.lookup(serviceName);
Object portableObj =
PortableRemoteObject.narrow(jndiRef, getEJBHomeRef(pServiceId));
ejbHome = (EJBHome) portableObj;
ejbHomeCache.put(serviceName, ejbHome);
return ejbHome;
}
The getDBConn() method is designed in a very similar fashion. When the user requests a JDBC connection via the getDBConn() method, the method checks the dataSourceCache for a DataSource object before doing a JNDI lookup. If the requested DataSource object is found in the cache, it is returned to the method caller, otherwise, a JNDI lookup takes place.
Let's revisit the constructor of the StoryManagerBD and see how using a Service Locator can significantly lower the amount of work involved in instantiating the StoryManager EJB:
public StoryManagerBD() throws ApplicationException {
try {
ServiceLocator serviceLocator = ServiceLocatory.getInstance();
StoryManagerHome storyManagerHome = (StoryManagerHome)
serviceLocator.getEJBHome(ServiceLocator.STORYMANAGER);
storyManager = storyManagerHome.create();
} catch(ServiceLocatorException e) {
throw new ApplicationException("A ServiceLocator exception has been " +
"raised in StoryManagerBD constructor: "
+ e.toString());
}
}
Our Service Locator implementation has significantly simplified the process of looking up and creating an EJB.
The Service Locator Pattern to the Rescue
The author ran into a situation just this past year in which he was building a web-based application that integrated to a third-party Customer Relationship Management (CRM) system.
The application had a significant amount of business logic, embedded as PL/SQL stored procedures and triggers, in the Oracle database it was built on. Unfortunately, they had used an Oracle package, called DBMS_OUTPUT, to put the trace code through all of their PL/SQL code. This packaged never caused any problems because the end-users of the CRM package used to enter the database data via a "fat" GUI interface, which always kept the database transactions very short.
However, the author needed to build a web application that would collect all of the user's data and commit it all at once. The transaction length was significantly longer than what the CRM vendors had anticipated. As a result, the message buffer that the DBMS_OUTPUT package used for writing out the log, would run out of space and the web application would fail at what appeared to be random intervals.
At this point the author and his team were faced with the choice of going through every PL/SQL package and trigger and stripping out the DBMS_OUTPUT code (which should have never been put in production code). However, the DBA informed them that if they started every session with a call to DBMS_OUTPUT.DISABLE, they would be able to disable the DBMS_OUTPUT package. This would disable the DBMS_OUTPUT package for that particular session, but would not cause any problems for other application users.
If the developers had allowed a direct JNDI lookup to retrieve DataSource objects for getting a JDBC connection, they would have had the daunting task of going through every line of in the application and making the call to the DBMS_OUTPUT.DISABLE. However, since the team had implemented a Service Locator pattern and used it to retrieve all the database connections, there was only one place in which the code had to be modified.
This indicates that you might not appreciate the abstraction that the Service Locator pattern provides until you need to make a change in how a resource is requested that will affect a significant amount of your code base.
EJBs and Struts
Since the release of the J2EE specifications, it has been incessantly drilled into every J2EE developer that all business logic for an application should be placed in the middle tier as session-based Enterprise JavaBeans (EJB). Unfortunately, many developers believe that by putting their business logic in EJBs they have successfully designed their application's middle tier.
The middle tier of an application often captures some of the core business processes used throughout the enterprise. Without careful forethought and planning, many applications end up with a middle tier that is too tightly coupled to a specific application. The business logic contained within the application cannot easily be reused elsewhere and can become so complex that is not maintainable.
Two symptoms of a poorly designed middle tier are when EJBs for the application are:
- Too fine-grained
A very common mistake, when building Struts-based applications with EJBs, is to have each Action class have a corresponding EJB. This results in a proliferation of EJBs and can cause serious performance problems in a high-transaction application. The root cause of this is that the application developer is treating a component-based technology (that is, EJB) like an object-oriented technology (that is, plain old Java classes).
In a Struts application, you can often have a small number of EJBs carrying out the requests for a much larger number of Action classes. If you find a one-to-one mapping between Action classes and EJBs, the design of the application needs to be revisited.
- Too fat
Conversely, some developers end up placing too much of their business logic in an EJB. Putting too much business logic into a single EJB makes it difficult to maintain it and reuse it in other applications. "Fat" EJBs are often implemented by the developers who are used to programming with a module development language, such as C or Pascal, and are new to object-oriented analysis and design.
The author has encountered far more of the latter design problem: "fat" EJBs when building Struts- based applications. Let's look at the "fat" EJB problem in more detail.
On "Fat" EJBs
"Fat" EJBs are monolithic "blobs" of code that do not take advantage of object-oriented design.
| Important |
The term "blob" is not the author's term. It is actually an antipattern that was first defined in the text: AntiPatterns: Refactoring Software, Architectures, and Projects in Crisis, Brown, Malveau, McCorkmick, Mowbray; John Wiley & Sons, ISBN 0-471-19713-0. The Blob antipattern is an antipattern that forms when a developer takes an object-oriented language like C++ or Java and uses it in a procedural manner. |
In a Struts application an extreme example of this might be manifested by a single EJB that contains one method for each of the Action classes present in the Struts application. The perform() method for each Action class would invoke a corresponding method on the EJB to carry out the business logic for the action.
This is an extreme example of a "fat" EJB. A more typical example of a "fat" EJB is one in which the EJBs are designed along functional breakdowns within the application. In the JavaEdge application, you might have a Member EJB and a Story EJB that encapsulate all of the functionality for that specific set of application tasks.
This kind of functional breakdown into individual EJBs makes sense. EJBs are coarse-grained components that wrap processes. The EJB model does offer the same type of object-oriented features (polymorphism, encapsulation, etc.) as its more fine-grained counterparts: plain java classes. The problem arises when the EJB developer does not use the EJB as a wrapper around more fine-grained objects but instead puts all of the business logic for a particular process inside the EJB.
For example, if you remember earlier in the chapter we talked about how many developers will push all of their business logic from their Struts Action class to an EJB. We demonstrated how if you did not use a Business Delegate pattern to hide the fact you were using EJBs, you could end up creating tight dependencies between Struts and the EJB APIs.
What we did not talk about is how blindly moving your business logic out of the PostStory Action class and into an EJB can result in a "fat" EJB. Shown below is the StoryManagerBean.java class:
package com.wrox.javaedge.story.ejb;
import javax.naming.*;
import java.rmi.*;
import javax.ejb.*;
import java.sql.*;
import com.wrox.javaedge.common.*;
import com.wrox.javaedge.story.*;
import com.wrox.javaedge.member.*;
import com.wrox.javaedge.story.dao.*;
import com.wrox.javaedge.struts.poststory.*;
public class StoryManagerBean implements SessionBean {
private SessionContext ctx;
public void setSessionContext(SessionContext sessionCtx) {
this.ctx = sessionCtx;
}
public void addStory(StoryVO storyVO)
throws ApplicationException, RemoteException{
Connection conn = null;
PreparedStatement ps = null;
try {
conn = ServiceLocator.getInstance().getDBConn(ServiceLocator.JAVAEDGEDB);
conn.setAutoCommit(false);
StringBuffer insertSQL = new StringBuffer();
insertSQL.append("INSERT INTO story( ");
insertSQL.append(" member_id , ");
insertSQL.append(" story_title , ");
insertSQL.append(" story_into , ");
insertSQL.append(" story_body , ");
insertSQL.append(" submission_date ");
insertSQL.append(") ");
insertSQL.append("VALUES( ");
insertSQL.append(" ? , ");
insertSQL.append(" ? , ");
insertSQL.append(" ? , ");
insertSQL.append(" ? , ");
insertSQL.append(" CURDATE() ) ");
ps = conn.prepareStatement(insertSQL.toString());
ps.setLong(1, storyVO.getStoryAuthor().getMemberId().longValue());
ps.setString(2, storyVO.getStoryTitle());
ps.setString(3, storyVO.getStoryIntro());
ps.setString(4, storyVO.getStoryBody());
ps.execute();
checkStoryCount(storyVO.getStoryAuthor());
} catch(SQLException e) {
throw new ApplicationException("SQL Exception occurred in " +
"StoryManagerBean.addStory()", e);
} catch(ServiceLocatorException e) {
throw new ApplicationException("Service Locator Exception occurred in " +
"StoryManagerBean.addStory()", e);
} finally {
try {
if (ps != null) ps.close();
if (conn != null) conn.close();
} catch(SQLException e) {}
}
}
private void checkStoryCount(MemberVO memberVO)
throws SQLException, NamingException {
...
}
public void addComment(StoryVO storyVO, StoryCommentVO storyCommentVO)
throws ApplicationException, RemoteException{
...
}
public void addStory(PostStoryForm postStoryForm, MemberVO memberVO)
throws ApplicationException, RemoteException{
...
}
public void ejbCreate() { }
public void ejbRemove() { }
public void ejbActivate() { }
public void ejbPassivate(){ }
}
We have not included the full listing of the StoryManagerBean class for the sake of brevity. However, you should be able to tell that this EJB is going to be huge if all of the business logic associated with managing stories is put into it.
The JavaEdge application is an extremely simple application. In more real-world EJB implementations, the amount of business logic that is put into the EJB can become staggering. Let's look at how the Session Faade design pattern can help us manage the business logic contained within an EJB.
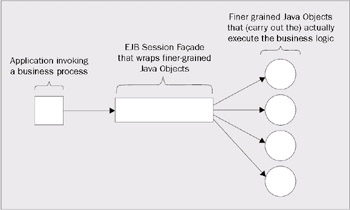
The Session Faade Pattern
The Session Faade pattern is implemented as a stateless session EJB, which acts as a coarse-grained wrapper around finer-grained pieces of code. Typically, these finer-grained pieces of code are going to be plain old Java classes rather than the more component-oriented EJB architecture. In a component- based architecture, a component wraps the business processes behind immutable interfaces. The implementation of the business process may change, but the interface that the component presents to the applications (which invoke the business process) does not change.
Instead the methods on an EJB implemented as a Session Faade should act as entry point through which the business process is carried by more fine-grained Java classes.
The diagram below illustrates this:
So if we were going to re-write the StoryManagerBean's addStory() method to be less monolithic and be more fine-grained it might be rewritten to look something like this:
public void addStory(StoryVO storyVO)
throws ApplicationException, RemoteException {
try {
StoryDAO storyDAO = new StoryDAO();
storyDAO.insert(storyVO);
PrizeManager prizeManager = new PrizeManager();
int numberOfStories =
prizeManager.checkStoryCount(storyVO.getStoryAuthor());
boolean TOTAL_COUNT_EQUAL_1000 = (numberOfStories==1000);
boolean TOTAL_COUNT_EQUAL_5000 = (numberOfStories==5000);
if (TOTAL_COUNT_EQUAL_1000 || TOTAL_COUNT_EQUAL_5000) {
prizeManager.notifyMarketing(storyVO.getStoryAuthor(), numberOfStories);
}
} catch (DataAccessException e){
throw new ApplicationException("DataAccessException Error in " +
StoryManagerBean.addStory(): " +
e.toString(), e);
}
}
The addStory() method is much more manageable and extensible. All of the data-access logic for adding a story has been moved to the StoryDAO class (which will be covered in more detail in the next chapter). All of the logic associated with prize management has been moved to the PrizeManager class.
As you can see, we've also refactored the code associated with the checkStoryCount() method. The checkStoryCount() method is only used when trying to determine whether or not the individual qualifies for a prize. So we moved the checkStoryCount() method to the PrizeManager. We could also have moved this method to the StoryDAO class. By moving it out of the StoryManager EJB we avoid having "extraneous" code in the Session Faade implementation.
Implementing the Session Faade pattern is not difficult. It involves looking at your EJBs and ensuring that the individual steps for carrying out a business process are captured in fine-grained Java objects. The code inside of the Session Faade implementation should act as the "glue" that strings these individual steps together into a complete process.
Any method on a Session Faade EJB should be short. If its over 20-30 lines, you need to go back and revisit the logic contained within the method to see if it can be refactored out into smaller individual classes. Remember, one of the core concepts behind object-oriented design is division of responsibility. Always keep this in mind as you are building your EJBs.
What about Non-EJB Applications?
All of the examples presented so far in this chapter have made the assumption that we are using EJB- based J2EE to gain the benefits offered by these design patterns. However, it is very easy to adapt these patterns to a non-EJB Struts-based application. The author has worked on many successful Struts applications using these patterns and just a web container.
For non-EJB Struts implementations, you should still use the Business Delegate pattern to separate the Struts Action class from the Java classes that carry out the business logic. You need not implement a Session Faade pattern in these situations. Instead, your Business Delegate class will perform the same function as the Session Faade class. The Business Delegate would act as a thin wrapper around the other Java objects carrying out a business process.
You might ask the question, "Why go through all of this extra work even in a non-J2EE application?" The reason is simple; by cleanly separating your Action class from the application's business logic (using a Business Delegate pattern), you provide a migration path for moving your applications to a full J2EE environment.
At some point, you might need to move the Struts applications to a full-blown J2EE application server and not just a JSP/servlet container. You can very easily move your business logic to Session Faades and EJBs, without rewriting any of your Struts applications. This is because you have separated your Struts applications from your business logic.
Your Struts applications only invoke the business logic through a plain Java interface. This abstraction allows you to completely refactor the business tier of your applications without affecting the applications themselves.
| Important |
The authors of this book struggled when trying to determine whether or not they should build the JavaEdge application as an EJB-based application. In the end, we decided not, because JavaEdge is such a simple application, that it did require the power (and the complexity) that came with implementing an EJB solution. Since the logic for the JavaEdge application was simple we embedded most of it as calls to Data Access Objects (covered in the next chapter) directly inside the Business Delegate implementations. The business logic was not broken out into Session Faade and was instead kept inside the Business Delegate classes. However, even though the JavaEdge application does not use EJBs in its implementation, the author of this chapter felt that this material was an important piece when looking at using Struts for your own EJB-based applications. As the Struts Action classes only talked to Business Delegates we could have easily refactored the code into an EJB-based solution without having to touch any of the Struts code. The design patterns talked about in this chapter cleanly separate the Struts framework from how the business logic for the application is being invoked. This allows us to evolve the application over time while minimizing the effects of these changes on the application. |
Summary
Often, in an object-oriented and component-based environment, more value is gained from interface reuse and the abstraction it provides than the actual code reuse. The business logic for an application changes regularly. Well-defined interfaces that abstract away the implementation details help shield an application from this uncertainty. This chapter explored how to use common J2EE design patterns to cleanly separate the business logic from the Struts framework on which the application is built. This promotes code reuse and also gives the developer more flexibility in refactoring business logic at a later date.
This chapter covered the following J2EE design patterns:
- Business Delegate Pattern
Hides the details of how the business logic used by the Struts application is actually invoked. It allows the development team to refactor the business tier while minimizing its impact on the applications that use the business logic. It also hides the technology (EJBs, web services, or just plain Java classes) used to implement the actual business logic.
- Service Locator Pattern
Simplifies the process of requesting commonly used resources like EJBs and DataSource objects within your Business Delegate.
- Session Faade Pattern
Is an EJB, which provides a coarse-grained interface that wraps a business process. Carrying out the individual steps for the business process, wrapped by the Session Faade, is left to much more fine-grained Java objects.
This chapter focused solely on modeling and implementing the business tier of a Struts-based application. However, we still need to focus on the how data is retrieved and manipulated by the business-logic tier. The next chapter is going to demonstrate how to use an open source object/relational mapping tool, called ObjectRelationalBridge (OJB), to build a data persistence tier. In addition, it will discuss how to use J2EE data-access design patterns to hide the implementation details in the data-persistence tier from the business tier.
Introduction
- The Challenges of Web Application Development
- Creating a Struts-based MVC Application
- Form Presentation and Validation with Struts
- Managing Business Logic with Struts
- Building a Data Access Tier with ObjectRelationalBridge
- Templates and Velocity
- Creating a Search Engine with Lucene
- Building the JavaEdge Application with Ant and Anthill
EAN: 2147483647
Pages: 83
