Understanding SQL Subqueries
Understanding Nested Queries That Return Sets of Rows
Although all of the example nested queries in Tip 319, "Understanding How to Use Nested Queries to Work with Multiple Tables at Once," return a single column of data values, a subquery's SELECT clause can contain multiple column references or expressions instead. Your DBMS, however, may restrict your ability to work with multiple-column subquery results. Suppose, for example, that you want to generate a list of customers waiting for a specific make and model of car that you now have in inventory. If your DBMS product lets you use row value constructors in an IN set membership test, you can execute a query similar to this
SELECT * FROM customers WHERE (model_year, make, model) IN (SELECT model_year, make, model FROM auto_inventory)
to generate a list of customers whose "dream" cars you now have on hand. However, if your DBMS, like MS-SQL Server, allows you to test for a set membership only one value at a time, you can rewrite the query as:
SELECT * FROM customers WHERE (model_year+make+model) IN (SELECT model_year+make+model FROM auto_inventory)
Here, the subquery's SELECT clause returns a single, composite value. The most important thing to understand now is that SQL does not limit the number of columns that a subquery can return. Each DBMS product imposes its own rules on which SQL statements and clauses are allowed to work with multiple column values at once.
A nested query that returns sets of rows with multiple columns is especially useful when you want to execute an INSERT statement that copies either some or all of the column data values from rows in one table into another table. Suppose, for example, that you want to consolidate customer and "dream car" inventory information into a single table named: CUST_CARS_INVENTORY. First, execute the TRUNCATE statement
TRUNCATE TABLE cust_cars_inventory
to remove any rows previously added to the table. Next, execute an INSERT statement similar to this:
INSERT INTO cust_cars_inventory SELECT c.*, VIN, price FROM customers c, auto_inventory I WHERE (c.model_year+c.make+c.model) = (i.model_year+i.make+i.model)
The subquery (the nested SELECT statement) sends the INSERT clause joined rows consisting of all of the columns from rows in the CUSTOMERS table joined to the vehicle ID number (VIN) and price column data values from related rows in the AUTO_INVENTORY table.
| Note |
You can avoid taking up disk space for a CUST_CARS_INVENTORY table by using the CREATE VIEW statement (which you learned about in Tip 215, "Using the CREATE VIEW Statement to Display the Results of Joining Two or More Tables") to create a virtual instead of a physical table. For the current example, the CREATE VIEW statement CREATE VIEW vw_cust_cars_inventory AS SELECT c.*, VIN, price FROM customers c, auto_inventory I WHERE (c.model_year+c.make+c.model) = (i.model_year+i.make+i.model) will create a virtual table named VW_CUST_CARS_INVENTORY whose contents are identical to the (physical) CUST_CARS_INVENTORY table filled by the INSERT statement with joined rows from the CUSTOMERS and AUTO_INVENTORY tables. |
The most important thing to understand now is that a nested query (or subquery) can return either rows with a single column value or rows with multiple column values. The DBMS product that you are using determines whether you must tell the subquery to return values one column at a time or one row (of column values) at a time.
Understanding Subqueries
A subquery is a SELECT statement within another SQL statement. In general, you can use a subquery in a statement anywhere an expression can appear. Moreover, a subquery can retrieve data from any table to which you have the correct access rights. As such, by nesting a subquery within a query or even within another subquery, you can combine information from two or more tables without writing complex JOIN statements that combine entire tables and then filter out many unwanted and unrelated joined rows.
For example, to generate a results table that shows the names of a company's managers, the names of the employees they manage, and the total sales for each employee, you can use a grouped query with a self-JOIN and an INNER JOIN similar to:
SELECT RTRIM(m.f_name)+' '+m.l_name AS 'Manager', RTRIM(e.f_name)+' '+e.l_name AS 'Employee', SUM(invoice_total) AS 'Total Sales' FROM employees m JOIN employees e ON m.emp_ID = e.emp_ID JOIN invoices ON salesperson = e.emp_ID GROUP BY m.f_name, 1.f_name, e.f_name, e.l_name ORDER BY manager, employee
Or, you can use a single-table query with two subqueries such as:
Or, you can use a single-table query with two subqueries such as:
SELECT (SELECT RTRIM(f_name)+' '+l_name FROM employees WHERE emp_ID = e.manager_ID) AS 'Manager', RTRIM(f_name)+' '+l_name AS 'Employee', (SELECT SUM(invoice_total) FROM invoices WHERE salesperson = emp_ID) AS 'Total Sales' FROM employees e WHERE manager_ID IS NOT NULL ORDER BY manager, employee
In the current example, the main query retrieves the name of each employee assigned to a manager from the EMPLOYEES table and then uses a subquery to get the manager's name from the same table and a second subquery to retrieve the total sales for each employee from the INVOICES table.
Aside from always being enclosed in parentheses ( () ) the subquery appears otherwise identical to all other SELECT statements. There are, however, a few differences between a subquery and other SQL statements:
- While a SELECT statement can use only columns from the tables listed in its FROM clause, a subquery can use not only columns from tables listed in the subquery's FROM clause, but also any columns from tables listed in the FROM clause of the enclosing SQL statement.
- A subquery in a SELECT statement must return a single column of data. Moreover, depending on its use in the query (such as using subquery results as an item in the enclosing query's SELECT clause), the enclosing query may require that the subquery return a single value (vs. multiple rows of values from single column).
- A subquery cannot have an ORDER BY clause. (Since the user never sees a results table from a subquery that returns multiple data values, it does not make any sense to sort the rows in the hidden interim results table anyway.)
- A subquery must consist of only one SELECT statement—meaning that you cannot write an SQL statement that uses the UNION of multiple SELECT statements as a subquery.
You will learn everything you ever wanted to know about subqueries in Tips 322–343. For now, the important thing to understand is that a subquery is a SELECT statement you can use as an expression in an SQL statement.
Understanding the Value of a Main Query Column When Referenced in a Subquery
A feature critical to the operation of a subquery is its ability to reference column values from the current row in the main (or enclosing) query.
SELECT emp_ID, RTRIM(f_name)+' +l_name AS 'Name', (SELECT SUM(invoice_total) FROM invoices WHERE salesperson = emp_ID) AS 'Sales Volume' FROM employees WHERE dept = 'Sales'
will list the EMP_ID, name, and total sales for each employee in the sales department. As such, the query gives both summary and detail information in each row of the results table. The main (or enclosing) query provides the employee detail (EMP_ID and name) from the EMPLOYEES table, while the subquery (or inner query) provides the sales volume (summary/aggregate total) from the INVOICES table.
To generate the query's results table, the DBMS executes the main (enclosing) query
SELECT emp_ID, RTRIM(f_name)+' +l_name AS 'Name' FROM employees WHERE dept = 'Sales'
by reading the rows of employee data in the EMPLOYEES table one row at a time. After retrieving a row of employee information, the system checks the DEPT column of the current row (that is, the row just read and now being processed) to see of the employee is in the sales department. If the employee is in the sales department, the DBMS adds the EMP_ID and name from the current row to the results table and then executes the subquery
(SELECT SUM(invoice_total) FROM invoices WHERE salesperson = emp_ID)
to get the employee's total sales volume from the INVOICES table.
Notice that in the current example, SALESPERSON in the subquery's WHERE clause references a column in the subquery's INVOICES table, while EMP_ID in the subquery's WHERE clause references a column in the main (enclosing) query's EMPLOYEES table. After the DBMS reads a row from the EMPLOYEES table, the system uses the value in the EMP_ID column of the current row (the row just read) when it executes the subquery.
The EMP_ID column referenced in the WHERE clause of the subquery in the current example is an outer reference—a reference to a column name that does not appear in any of the tables listed in the subquery's FROM clause. Instead, an outer reference refers to a column from one of the tables listed in the main (outer) query's FROM clause. Moreover, the DBMS takes the value of the outer reference (EMP_ID, in the current example) from the column in the row currently being processed in the main (outer) query.
Understanding Subquery Comparison Tests
If a subquery generates a results table with a single value (that is, a results table with one column and no more than one row), you can use the subquery as one (or both) of the expressions in a subquery comparison test. As you can see from the syntax of a subquery comparison test,
{|| {=|<>|>|>=|<|<=}
{|
the only difference between it and any other comparison test is that the subquery comparison test (as its name implies) includes at least one subquery. The six comparison operators work exactly the same way whether comparing the values of two nonsubquery expressions, the value of a nonsubquery expression with a subquery result, or the results from two subqueries.
When present in SQL statements, you will find subquery comparison tests in a WHERE clause. For example, you can use a subquery comparison in the WHERE clause of a SELECT statement similar to
SELECT emp_ID, RTRIM(f_name)+' '+l_name) AS 'Name', (SELECT sum(invoice_total) FROM invoices WHERE salesperson = emp_ID) AS 'Sales Volume' FROM employees WHERE dept = 'Sales' AND (SELECT SUM(invoice_total) FROM invoices WHERE salesperson = emp_ID) > 5000.00
to get a list of salespeople with total sales above $5,000.00.
| Note |
In order for a subquery comparison to evaluate to a valid value of TRUE or FALSE, the subquery (or subqueries) in the comparison test must generate a results table with exactly one row and one column. If the results table returns more than one column or more than one row, the DBMS will abort execution of the query and display an error message similar to: Server: Msg 512, Level 16, State 1, Line 1 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=, >, >= or when the subquery is used as an expression. |
On the other hand, if a subquery in a comparison test returns zero rows, the comparison test will evaluate to NULL (and not FALSE). As you learned in Tip 317, "Understanding Why the Expression NULL = NULL Evaluates to FALSE," when the comparison test evaluates NULL, the query will not abort processing. However, the final results table will have no rows because the WHERE clause did not evaluate to TRUE.
The EMP_ID column used in the subquery comparison test
(SELECT SUM(invoice_total) FROM invoices WHERE salesperson = emp_ID) > 5000.00
is an outer reference to an EMP_ID column in one of the tables listed in the enclosing query's FROM clause. As you learned in Tip 322, "Understanding the Value of a Main Query Column When Referenced in a Subquery," the DBMS uses the column value from the row currently being processed by the enclosing query when it encounters an outer (column) reference in a subquery.
Therefore, in the current example, the DBMS works its way through the EMPLOYEES table, one row at a time. When the DBMS encounters an EMPLOYEES table row that contains "sales" in the DEPT column, the system executes the subquery in the SELECT statement. The subquery generates a single-value results table with the total dollar volume of sales on invoices whose SALESPERSON column has the same value as the EMP_ID column in the current row of the EMPLOYEES table. If the total sales volume generated by the subquery is greater than $5,000.00, the DBMS adds the EMP_ID, employee name, and total sales volume to the main query's results table.
| Note |
You do not have to include a subquery in the enclosing query's SELECT clause to use it in a subquery comparison test. Moreover, you can use a subquery as either of the two expressions or as both of the expressions in a comparison. As such, if you want to know only the EMP_ID and name of each employee whose average invoice total is less than the overall average order for all salespeople, you can submit a query similar to SELECT emp_ID, RTRIM(f_name)+' '+l_name) AS 'Name', FROM employees WHERE dept = 'Sales' AND (SELECT AVG(invoice_total) FROM invoices WHERE salesperson = emp_ID) < (SELECT AVG(invoice_total) FROM invoices) to the DBMS for processing. |
Using the EXISTS Predicate in a Subquery to Determine If Any Rows Have a Column Value That Satisfies the Search Criteria
The EXISTS predicate lets you check a table to see if at least one row satisfies a set of search conditions. In practice, EXISTS is always used in conjunction with a subquery and evaluates to TRUE whenever the subquery returns at least one value. If the subquery's results table has no values (meaning that no rows in the table satisfied the search criteria in the subquery's WHERE clause), then the EXISTS predicate evaluates to FALSE.
Suppose, for example, that you want a list of salespeople who have a single customer that purchased more than $100,000 worth of merchandise or whose customers (taken as a whole) have made purchases of more than $500,000. Stated another way, you might say, "List the salespeople for whom there EXISTS at least one customer with total orders of more than $100,000, or for whom there EXISTS a set of customers that have made purchases or more than $5000.00." A query similar to
SELECT emp_ID, f_name, l_name FROM employees WHERE EXISTS (SELECT * FROM customers WHERE salesperson = emp_ID AND (total_purchases > 100000 OR (SELECT SUM(total_purchases) FROM customers WHERE salesperson = emp_ID) > 500000))
will generate the list of employees you want. To execute the query, the DBMS goes through the EMPLOYEES table one row at a time. When passed the EMP_ID column value from the row currently being processed in the main query, the subquery generates an interim (virtual) table with a value from one of the columns in the CUSTOMERS table for each row in the CUSTOMERS table that satisfies the search conditions in the subquery's WHERE clause.
If the subquery's interim (virtual) table has no values after the subquery executes, then the EXISTS predicate evaluates to FALSE, and the DBMS goes on to the next row in the EMPLOYEES table. On the other hand, if the subquery's interim (virtual) table has at least one value, the EXISTS predicate evaluates to TRUE and the DBMS will (in the current example) add the employee ID name to the main query's results table before going on to process the next row in the EMPLOYEES table.
| Note |
As you learned in Tip 321, "Understanding Subqueries," a subquery must produce a single column of results. Given a CUSTOMERS table with more than one column, the SELECT * in the subquery of the EXISTS test seems to violate this rule. However, since the EXISTS predicate really does not use any of the data values generated by subquery (the EXISTS predicate needs to know only if any values are generated), SQL treats the SELECT * in the subquery's SELECT clause as meaning "select any one column" vs. the usual "select all columns." |
In addition to the EXISTS predicate, which evaluates to TRUE if its subquery produces at least one row, you can use the NOT EXISTS, which evaluates to TRUE if its subquery produces no rows. For example, to get a list of salespeople who have not yet generated any revenue, you can submit a query similar to:
SELECT emp_ID, RTRIM(f_name)+' '+l_name AS 'Employee Name' FROM employees WHERE NOT EXISTS (SELECT * FROM customers WHERE salesperson = emp_ID AND total_purchases > 0)
If a salesperson has no customers or if none of the customers assigned to the salesperson has made a purchase (in which case TOTAL_PURCHASES will be 0.00), then the subquery in the EXISTS predicate will produce no rows. The absence of rows returned by its subquery will cause the EXISTS predicate to evaluate to FALSE. However, the keyword NOT will reverse the value of the EXISTS predicate, thereby causing it—and, consequently, the WHERE clause as well—to evaluate to TRUE. The DBMS will add the ID and name of the employee with zero sales to the main query's results table.
Understanding the Relationship Between Subqueries and Joins
When writing a SELECT statement that uses data from more than one table, you can often write the query as either a single-table SELECT statement with one or more subqueries or as a multi-table SELECT (or JOIN). For example, to get a list of customers whose orders are shipped to Arizona, California, Nevada, Oregon, or Washington, you can execute a multi-table query such as
SELECT DISTINCT c.cust_ID, f_name, l_name
FROM customers c, orders o
WHERE c.cust_ID = o.cust_ID
AND ship_to_state IN ('AZ','CA','NV','OR','WA')
which first cross joins the rows in the CUSTOMER table with the rows in the ORDERS table and then filters out unrelated joined rows (where CUST_ID from CUSTOMERS does not equal CUST_ID from ORDERS) and rows with SHIP_TO_STATE abbreviations for states other than one of the five states of interest.
Alternatively, you can generate the same results table using a single-table query with a subquery similar to:
SELECT cust_ID, f_name, l_name FROM customers
WHERE cust_ID IN
(SELECT cust_ID FROM orders
WHERE ship_to_state IN ('AZ','CA','NV','OR','WA')
When executing the query that has a subquery, the DBMS does not CROSS JOIN the rows of the table in the enclosing query with the rows of the table in the subquery. Instead, the DBMS retrieves the table in the main query, one row at a time. Then the DBMS executes the subquery for each of the rows in the main query.
In the current example, the DBMS retrieves a row from the CUSTOMERS table. Then the system executes the subquery to generate an interim results table with the CUST_ID value for each row in the ORDERS table that has a SHIP_TO_STATE that matches one of the five listed in the subquery's WHERE clause. If the value of the CUST_ID column from the current row being processed in the main query appears in the subquery's interim results table, the DBMS adds the customer name and ID to the main query's final results table.
Thus, a multi-table SELECT statement (or JOIN) involves the DBMS generating the CROSS JOIN of the tables list in the SELECT statement's FROM clause and filtering out the unwanted joined rows from the interim (virtual) Cartesian product. Conversely, the DBMS does not CROSS JOIN the main query table with the subquery table in a single-table SELECT with one or more subqueries. Instead, the DBMS goes through the rows in the main table and uses the subquery results to decide which rows from the main query's table to include in the SELECT statement's results table.
While most queries can be written either way, do not be surprised if you find that some queries can be written only as joins while others can be written only as single-table queries with subqueries. For example, if you want a list of customer names from the CUSTOMERS table along with each customer's total purchases from the ORDERS table, you can do this only with a grouped multi-table query similar to:
SELECT c.cust_ID, f_name, l_name, SUM(order_total) AS 'Total Purchases' FROM customers c, orders o WHERE c.cust_ID = o.cust_ID GROUP BY cust_ID, f_name, l_name
On the other hand, if you want to select rows from one table based on summary information from another table, only a query with subqueries will do. For example, there is no multi-table query (JOIN) only equivalent for a query such as
SELECT SID, f_name, l_name FROM students s WHERE (SELECT AVG(grade_received) FROM grades g WHERE g.student_ID = s.SID) > (SELECT AVG(grade_received) FROM grades)
which generates a list of student names from the STUDENTS who have above-average grades.
Using the Keyword IN with a Subquery to SELECT Rows in One Table Based on Values Stored in a Column in Another Table
The keyword IN lets you test whether or not a literal, the value of an expression, or the (single-value) result from a subquery that precedes the keyword matches one of the values in the set of values that follows it. For example, if you want to make a list of customers from California, Nevada, or Oregon, you can submit a query similar to:
SELECT cust_ID, f_name, l_name, phone_number
FROM customers
WHERE state IN ('CA','NV','OR')
The DBMS will test the value of the STATE column in each row of the CUSTOMERS table for a matching value in the set literals that follows the keyword IN. If the system finds a matching value, the WHERE clause evaluates to TRUE, and the DBMS adds the customer's CUST_ID, name, and PHONE_NUMBER to the SELECT statement's results table. Conversely, if the value in the STATE column has no match in the set of state abbreviations that follows the keyword IN, then the WHERE clause evaluates to FALSE, and the DBMS does not insert any column values from the current row being tested into the query results table.
If used to introduce a subquery, the keyword IN lets the DBMS use the single column of values returned by the subquery as the set of values in which it is to find a match for the data value that precedes the keyword. For example, suppose you want to get a list of all customers (from the CUSTOMERS table) that live in the same state as one of your company's offices (from the OFFICES table). The query
SELECT cust_ID, f_name, l_name, state FROM customers WHERE state IN (SELECT state FROM offices)
will go through the CUSTOMERS table one row at a time, checking to see if the value in each row's STATE column matches one of values in the STATE column from the OFFICES table (returned by the subquery). If the state abbreviation in the STATE column from the CUSTOMERS table matches one of the values in the STATE column from the OFFICES table, the WHERE clause evaluates to TRUE, and the DBMS will insert the customer's CUST_ID, name, and STATE in the query's final results table.
You will learn more about using IN and NOT IN to introduce subqueries in Tips 327–328. For now, the important thing to understand is that the subquery introduced by the keyword IN can retrieve a column of data values from any database table—not just those used in the main query. As such, the keyword IN, used in conjunction with a subquery, often makes it possible to extract from multiple tables information that is not available in a single table.
For example, in the current example, the CUSTOMERS table does not have a list of states in which your company has offices. Conversely, the OFFICES table does not have any customer details. The keyword IN, used to introduce the subquery in the WHERE clause, lets the DBMS SELECT rows from the CUSTOMERS table based on values stored in the STATE column of the OFFICES table.
Using the Keyword IN to Introduce a Subquery
When you use the keyword IN to introduce a subquery, you tell the DBMS to perform a subquery set membership test. In other words, you tell the DBMS to compare a single data value (that precedes the keyword IN) to a column of data values in the results table generated by the subquery (that follows the keyword). If the single data value matches one of the data values in the column of data values returned by the subquery, then the IN predicate evaluates to TRUE.
The syntax used to generate a results table based on a subquery set membership test is
SELECT FROM WHERE IN
where can be a literal value, a column name, an expression, or another subquery that returns a single value.
For example, if student information is stored in a STUDENTS table, and the classes each student is taking are listed in an ENROLLMENT table, then you can use a SELECT statement similar to
SELECT SID, f_name, l_name FROM students WHERE SID IN (SELECT student_ID FROM enrollment WHERE course_ID = 'ENGLISH-101')
to get a list of students enrolled in ENGLISH-101.
In executing a query, the DBMS processes the innermost subquery first. Thus, in the current example, the system first generates a list of all STUDENT_ID values from rows in the ENROLLMENT table that have ENGLISH-101 in the COURSE_ID column. Next, the DBMS goes through the STUDENTS table one row at a time and compares the value in the SID column of each row to the list of student IDs in the subquery's results table.
If the system finds a matching STUDENT_ID value (in the subquery results table) for the value in the SID column of the STUDENTS row it is processing, then the WHERE clause evaluates to TRUE, and the system inserts the student's ID and name into the main query's results table before going on to process the next row in the STUDENTS table. If, on the other hand, the DBMS finds no match for SID in the subquery results, then the WHERE clause evaluates to FALSE and the DBMS goes on to the next row in the STUDENTS table—without inserting the student ID and name from the current row being processed into the query's results table.
| Note |
The column of values returned by a subquery introduced by the keyword IN can be from either one of the tables used in the main query or another table altogether. The only requirement SQL places on the subquery is that it must return a single column of data values whose data type is compatible with the data type of the expression that precedes the keyword IN. |
Using the Keywords NOT IN to Introduce a Subquery
As you learned in Tip 327, "Using the Keyword IN to Introduce a Subquery," the keyword IN, when used to introduce a subquery in a WHERE clause, lets you test whether or not a value (from a row in the main query) matches one of the values in the column of values returned by the subquery. If the DBMS finds a matching value, the WHERE clause evaluates to TRUE, and the DBMS takes the action specified by the SQL statement before going on to process the next row in the table. If, on the other hand, there is no matching value in the subquery's single-column results table, then the DBMS takes no action on the current row being processed before going on to the next row.
The NOT keyword reverses the effect of the IN test. As such, if you introduce a subquery with the keywords NOT IN (vs. the keyword IN), the DBMS takes the action specified by the SQL statement if there is no matching value in the subquery's results table.
For example, using the same general syntax as the subquery set membership test (which you learned about in Tip 327), you submit a query such as
SELECT class_ID, title, instructor_ID FROM classes WHERE class_ID NOT IN (SELECT course_ID FROM enrollment)
and get a list of classes for which no students have registered-similar to the one in the lower pane of the MS-SQL Server Query Analyzer Window shown in Figure 328.1.
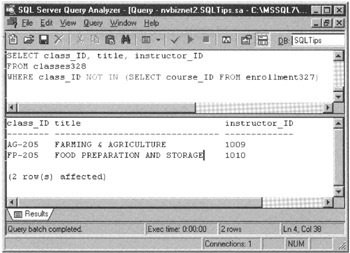
Figure 328.1: The MS-SQL Server Query Analyzer window with the results table from a NOT IN subquery set membership test
When executing a query, the DBMS processes the innermost subquery first. Thus, in the current example, the system first generates a list of all CLASS_ID values from rows in the ENROLLMENT table. Next, the DBMS goes through the CLASSES table one row at a time and compares the value in the CLASS_ID column of each row to each of the values in the list of class IDs in the subquery's results table.
If the system finds no matching CLASS_ID value (in the subquery results table) for the value in the CLASS_ID column of the CLASSES row it is processing, then the IN predicate evaluates to FALSE. However, the NOT keyword then reverses the result of the predicate such that the WHERE clause evaluates to TRUE. The system inserts the CLASS_ID, TILE, and INSTRUCTOR_ID column values from the current row being tested into the main query's results table before going on to process the next row in the CLASSES table. If, on the other hand, the DBMS does find a matching value for CLASS_ID in the single-column subquery results table, then the IN predicate evaluates to TRUE. After the NOT modifier reverses the predicate's value, the WHERE clause evaluates to FALSE, and DBMS goes on to the next row in the CLASSES table-without inserting column values from the current row being processed into the main query's results table.
| Note |
The IN and NOT IN subquery set membership tests are not limited to being used only in the WHERE clause of a SELECT statement. Although always found in a WHERE clause, the WHERE clause itself may be part of any SQL statement (such as DELETE, INSERT, SELECT, or UPDATE) that accepts a WHERE clause. For example, if you want to remove all classes in which no students have enrolled during the past five years, you can use NOT IN to introduce the subquery in a DELETE statement such as: DELETE FROM classes WHERE date_class_added < GETDATE() - 1825 AND class_ID NOT IN (SELECT course_ID FROM enrollment WHERE date_enrolled >= GETDATE() - 1825) |
Using ALL to Introduce a Subquery That Returns Multiple Values
If you are going to use only one of the six SQL comparison operators (=, <>, >, >=, <, or <=) to compare the values of two expressions, then the expression that precedes the operator and the expression that follows it must each evaluate to a single value. Therefore, you can use a subquery as one of the expressions in a comparison predicate only if the subquery produces a single value for the comparison test.
For example, if you have an AUTO_POLICIES table and an ACCIDENTS table, you can submit a query similar to
SELECT policy_number, make, model FROM auto_policies p WHERE (SELECT COUNT(*) FROM accidents a WHERE (description LIKE '%rollover%' AND mph <= 35) AND a.make = p.make AND a.model = p.model) > 0
and the DBMS will generate a list of insurance policies written on cars that have had at least one rollover accident at or below 35 miles per hour. If the ACCIDENTS table has more than one row detailing a ROLLOVER at under 35 MPH for the make and model of car being tested in the main query, the subquery will generate an interim results table with more than one row. However, the subquery is still a valid expression for the comparison predicate because the COUNT(*) aggregate function reduces the results table generated by the subquery to a single value.
Now, suppose you want to get a list of the policies written on the make and model of automobile with the highest incident of rollover accidents at or below 35 MPH. The single value for an entire table returned by an aggregate function, such as COUNT(*), will not suffice in this type of query. Instead, you need the DBMS to subtotal the count of rollover accidents by make and model of automobile, and then you need the system to compare the rollover count for each make and model of automobile against the maximum rollover count from the other makes and models of automobiles.
The quantifiers ALL, SOME, and ANY let you use a comparison operator to compare a single value to each of the values returned by a subquery. For example, a query such as
SELECT policy_number, f_name, l_name, make, model FROM auto_policies p WHERE (SELECT COUNT(*) FROM accidents a WHERE (description LIKE '%rollover%' AND mph <= 35) AND a.make = p.make AND a.model = p.model) > ALL (SELECT COUNT(*) FROM accidents a WHERE (description LIKE '%rollover%' AND mph <= 35) AND (a.make <> p.make OR a.model <> p.model) GROUP BY make, model)
will list the make and model of car in the POLICIES table that has more rollover accidents than any other make and model of car in the ACCIDENTS table.
The first subquery (on the left side of the > ALL comparison) returns a single value-the number of rollover accidents experienced by the make and model of car being tested in the main query. Meanwhile, the second subquery (on the right side of the > ALL comparison) returns the rollover accident count for each of the other makes and models of cars from the ACCIDENTS table.
Although the subquery to the right to the greater than (>) comparison operator has more than one value, the ALL quantifier lets you use it in the comparison by telling the DBMS to compare the multiple values in the list of values with the single value, one value at a time. In other words, the ALL quantifier changes the comparison from one in which a single value is compared to a set of multiple values into multiple single value comparisons-one for each row in the subquery's results table.
If all of the comparison tests evaluate to TRUE, then the WHERE clause evaluates to TRUE, and the main query adds column values from the current row in the AUTO_POLICIES table to the SELECT statement's final results table. If, on the other hand, any of the comparisons evaluates to FALSE, the WHERE clauses evaluates to FALSE, and the DBMS goes on to test the next row in the AUTO_POLICIES table-without adding any column data values to the query's final results table.
You will learn how to use the SOME and ANY quantifiers to introduce a multi-valued subquery in Tip 330, "Using SOME or ANY to Introduce a Subquery That Returns Multiple Values." For now, the important thing to know is that the ALL qualifier lets you compare a single value that precedes a comparison operator with each of the values in the set of values returned by a subquery that follows it. Moreover, the comparison predicate (and subsequently the WHERE clause) evaluates to TRUE only if all of the comparisons between the single value to the left of the comparison operator and each of the values in the subquery's results table evaluates to TRUE.
Using SOME or ANY to Introduce a Subquery That Returns Multiple Values
As you learned in Tip 329, "Using ALL to Introduce a Subquery That Returns Multiple Values," ALL, SOME, and ANY are quantifiers that let you compare a single value to the left of a comparison operator with a subquery (to the right of the comparison operator) that generates a single-column results table with multiple rows. Remember, the DBMS will abort a query of the form
SELECT FROM
WHERE {=|<>|>|>=|<|<=}
with an error message similar to
Server: Msg 512, Level 16, State 1, Line 1 Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, <=, >, >= or when the subquery is used as an expression.
if the subquery in the WHERE clause generates a single-column results with multiple values.
If you rewrite the query by introducing the subquery with one of the three quantifiers (ALL, SOME, ANY, or any), such as:
SELECT FROM
WHERE {=|<>i>|>=|<|<=} {SOME|ANY|ALL}
the DBMS will not abort the query if the subquery's single-column results table has more than one row of data. Instead, the DBMS will compare the value of (left of the comparison operator) to each of the values returned by the subquery that follows the comparison operator.
As you learned in Tip 329, if you use the ALL quantifier, every one of the comparisons of the value with one of the values must evaluate to TRUE in order for the WHERE clause to evaluate to TRUE. The SOME and ANY quantifiers, on the other hand, let the WHERE clause evaluate to TRUE so long as at least one of the comparisons between the value of and one of the values returned by the subquery evaluates to TRUE.
For example, if you want a list of salespeople that have exceeded their daily sales quota by 50% or more at least once during the past two weeks, you can submit a query similar to:
SELECT emp_ID, f_name, l_name, sales_quota FROM employees WHERE dept = 'SALES' AND (sales_quota * 1.50) <= ANY (SELECT SUM(order_total) FROM orders WHERE salesperson = emp_ID AND order_date >= GETDATE() - 14 GROUP BY order_date)
Although the subquery to the right of the less than or equal to (<=) comparison operator has more than one value, the ANY quantifier lets you use it as one of the expressions in a comparison.
Then ANY quantifier tells the DBMS to compare the single value to the left of the comparison operator with each of the values returned by the subquery, one at a time. If the operation evaluates to TRUE for any (that is, at least one) of the comparisons performed, then the WHERE clause evaluates to TRUE. When the WHERE clause evaluates to TRUE, the DBMS adds column data values from the current row being tested as a row to the main query's results table.
The important thing to understand about the ANY (or SOME) quantifier is that it lets you compare a single value that precedes a comparison operator with each of the values in the set of values returned by a subquery that follows it. If any of the comparisons between the single value to the left of the comparison operator and each of the values in the subquery's results table evaluates to TRUE, then the predicate (and the WHERE clause) evaluates to TRUE.
| Note |
The quantifiers SOME and ANY are synonymous. As you learned in Tip 315, "Understanding the Ambiguous Nature of ANY and How SQL Implements It to Mean SOME," the ambiguous nature of ANY prompted the SQL standards committee to add the quantifier SOME to the SQL-92 standard. Some DBMS products support only the original quantifier ANY. However, most now support both SOME and ANY. If your DBMS supports both, the one you choose is a matter of personal preference since both will produce a TRUE result if any one of the comparisons of the test value to each of the subquery data values evaluates to TRUE. |
Using an Aggregate Function in a Subquery to Return a Single Value
When you read about aggregate functions in Tips 113-120, you learned how to use each of the functions to display a table attribute in summary form in the query's results table. For example, when you wanted to know the number of rows in the EMPLOYEES table in Tip 113, "Using the COUNT(*) Aggregate Function to Count the Number of Rows in a Table," you submitted the query:
SELECT COUNT(*) FROM employees
And when you wanted to know the cost of the highest-priced item the PRODUCTS table in Tip 117, "Using the MAX() Aggregate Function to Find the Maximum Value in a Column," you submitted the query:
SELECT MAX(item_cost) AS 'Max Item Cost' FROM products
In addition to including aggregate function results in a query's results table, you can also get the value returned by an aggregate function as part of a search condition in a subquery's WHERE clause. For example, if you want to display the PRODUCT_ID, DESCRIPTION, and ITEM_COST of the highest-priced item in your PRODUCTS table, you can submit a query similar to:
SELECT product_ID, description, item_cost FROM products WHERE item_cost = (SELECT MAX(item_cost) FROM products)
| Note |
An aggregate function, such as MAX(), always returns a single value. Therefore, a subquery with only an aggregate function in its SELECT statement will always return a single value. Bear in mind, however, that just because the subquery returns a single value does not mean that the enclosing query, too, will return a single row. In the current example, if more than one product has the same price as the highest-priced item in the PRODUCTS table, the subquery will sill return one value-the largest value in the ITEM_COST column in the PRODUCTS table. However, the main query will display the PRODUCT_ID, DESCRIPTION, and ITEM_COST for each of the items in the PRODUCTS table that has the same ITEM_COST as the maximum ITEM_COST in the PRODUCTS table. Thus, the results table in the current example will have more than one row if more than one product has an ITEM_COST equal to the highest ITEM_COST in the PRODUCTS table. |
Because an aggregate function always returns a single value, you can use a subquery whose SELECT clause has only aggregate function as either of the two expressions in a comparison predicate. After all, a subquery with only one column (the aggregate function) in its SELECT clause is guaranteed to always return one an only one value-the single value returned by the aggregate function. Therefore, to get a list of employees whose average total order is larger than the overall average order total, you can submit a query similar to:
SELECT emp_ID, f_name, l_name FROM employees e WHERE (SELECT AVG(order_total) FROM orders o WHERE o.salesperson = e.emp_ID) > (SELECT AVG(order_total) FROM orders)
Notice that the SELECT clause in each of the two subqueries contains a single aggregate function: AVG(ORDER_TOTAL). As such, each subquery is a single valued expression the DBMS can compare using one of the six comparison operators (such as the greater than [>], in the current example) in a comparison predicate.
Understanding Nested Subqueries
With the exception of the enclosing parenthesis ( () ), a subquery looks and functions exactly the same as any other SELECT statement. Therefore, since a SELECT statement can have a subquery, a subquery, which is (arguably) nothing more than a SELECT statement within another SQL statement, can itself have a subquery. Although the examples in Tips 321-331 show a two-level nesting of queries with a first-level subquery inside a main query, SQL also allows three-level (and higher) queries.
For example, the SELECT statement
SELECT f_name, l_name, ticker, rating_date, rating, employer AS 'underwriter' FROM stock_picks sp, analysts a WHERE sp.analyst_ID = a.analyst_ID AND a.analyst_ID IN (SELECT analyst_ID FROM analysts WHERE employer IN (SELECT underwriter FROM IPO_list i WHERE i.ticker = sp.ticker))
is a three-level query designed to display ratings for stock purchases made by the analysts who work for the companies that brought a stock public.
The DBMS executes subqueries starting with the innermost subquery and then working its way outward through the subqueries. Thus, in the current example, the DBMS retrieves a stock symbol from a row in the CROSS JOIN of the rows in the STOCK_PICKS table and the ANALYSTS table. The system then uses the stock symbol in the innermost (second-level) subquery
WHERE employer IN (SELECT underwriter FROM IPO_list i WHERE i.ticker = sp.ticker)
to generate a column that lists the names of the firms that brought the company with ticker symbol TICKER public. Next, the DBMS uses the second-level subquery's results table for the IN predicate of the first-level subquery
(SELECT analyst_ID FROM analysts WHERE employer IN ()
which generates the list of analysts who work for the firms that underwrote the stock with ticker symbol TICKER. The system then uses the results of the first-level subquery to filter out unwanted joined rows in the CROSS JOIN of STOCK_PICKS and ANALYSTS in the main query:
SELECT f_name, l_name, symbol, rating_date, rating, employer AS 'underwriter' FROM stock_picks sp, analysts a WHERE sp.analyst_ID = a.analyst_ID AND analyst_ID IN ( subquery)
The DBMS uses the same methodology to process fourth-level, fifth-level, and so on (through nth-level) queries. (It works it way from the innermost [highest-level] subquery outward.)
SQL-92 does not specify a maximum number of nesting levels for subqueries. However, most DBMS implementations restrict the number of subquery levels to a small number. A query quickly becomes too time consuming to process (and often too difficult to understand and maintain) as its level of subquery nesting increases.
Understanding the Role of Subqueries in a WHERE Clause
A subquery in a WHERE clause acts as a filter for the row-selection process of the enclosing query (or subquery). For example, if you want to know the names of the salespeople with above-average GROSS_SALES_YTD, you can execute a query such as:
SELECT f_name, l_name FROM employees WHERE dept = 'Sales' AND gross sales_ytd > (SELECT AVG(gross_sales_ytd) FROM employees WHERE dept='Sales')
The DBMS will execute the inner query to get the average GROSS_SALES_YTD for all employees in the sales department. It then uses this number to filter out rows of sales department employees from the EMPLOYEES table who have GROSS_SALES_YTD below the average (returned by the AVG aggregate function in the subquery).
In the current simple example, you could execute the subquery on its own to get the average GROSS_SALES_YTD. Then, when you know the average, you can use it in place of the subquery in the SELECT statement. For example, suppose the average value in GROSS_SALES_YTD column is $227,500.50. You could then rewrite the query as:
SELECT f_name, l_name FROM employees WHERE dept = 'Sales' AND gross_sales_ytd > 227500.50
However, if you "hard-code" the average GROSS_SALES_YTD figure into the query, you will have to execute the (sub)query and rewrite the query again the next time you want the list of above-average salespeople. A subquery lets you avoid this duplication of effort by letting you filter out unwanted rows based on values that change over time-without your having to know that the "filter" values are beforehand.
Moreover, using a subquery in a WHERE clause to filter out unwanted rows is much less time-consuming than writing and executing multiple queries when there are a large number of computations to perform. Suppose, for example, that the EMPLOYEES table does not have a GROSS_SALES_YTD column. Rather, to get the gross sales figure for each employee, you have to compute the sum of the values in the ORDER_TOTAL column of the ORDERS table for each salesperson's customers' orders. If the company has a large number of salespeople, executing a query such as
SELECT SUM(order_total) FROM orders WHERE salesperson = 11
repeatedly (substituting each salesperson's EMP_ID for 11 in the example) to get the total sales for each employee can be quite time-consuming-especially if you have to complete the report on a monthly, weekly, or even daily basis.
If you use a subquery (or multiple subqueries) in a WHERE clause instead, you can have the DBMS compute the average order (YTD) for each salesperson, determine the average sales (YTD) for all salespeople, and report the names of salespeople with above-average sales-all in one query similar to:
SELECT f_name, l_name FROM employees WHERE dept = 'Sales' AND (SELECT AVG(order_total) FROM orders WHERE salesperson = emp_ID AND order_date >= '01/01/2000') > (SELECT AVG(order_total) FROM orders WHERE order_date >= '01/01/2000')
The important thing to understand is that the subquery in a WHERE clause is used to compute the value (or set of values) that the DBMS can use in a search condition-just like any other literal value of column reference. As always, the DBMS inserts into the final results table column values from only those (joined) rows for which the WHERE clause search condition evaluates to TRUE.
Using Nested Queries to Return a TRUE or FALSE Value
In Tip 333, "Understanding the Role of Subqueries in a WHERE Clause," you learned that you can use a subquery to compute a value for use with a comparison operator in a WHERE clause. Sometimes, however, you want to take an action based on whether or not a table has any rows that satisfy a search condition vs. whether or not a column or set of columns has a specific value. A WHERE clause subquery introduced with the keyword EXISTS will return a simple TRUE or FALSE Boolean value that the DBMS can use in deciding whether or not to take the action specified by the SQL statement.
For example, if an insurance company wants to impose a 10 percent surcharge on any auto policy on which it has paid a claim during the past year, you can submit a query similar to
SELECT policy_number, RTRIM(f_name)+' '+l_name AS 'Name', cost * .10 AS 'Surcharge' FROM auto_policies ap WHERE EXISTS (SELECT * FROM claims_paid c WHERE c.policy_number = ap.policy_number AND claim_date > GETDATE() - 365)
which will list the POLICY_NUMBER, insured's name, and SURCHARGE for each policy listed in the CLAIMS_PAID table. Conversely, if the POLICY_NUMBER from the AUTO_POLICIES table in the main query is not found in the CLAIMS_PAID table by the subquery, the EXISTS predicate returns FALSE, and the system will not add the column data values from the row currently being processed to the final results table.
Similarly, a subquery introduced by NOT EXISTS will return the Boolean value TRUE when the table(s) in the subquery have no rows that satisfy the search condition(s) in its WHERE clause. For example, suppose the AUTO_POLICIES table in the preceding example were altered to include a SURCHARGE and DISCOUNT column. If you wanted to record the 10 percent claims surcharge in the SURCHARGE column of policies on which the company paid claims, you could use an UPDATE statement similar to:
UPDATE auto_policies SET surcharge = .1 * cost, discount = 0.00 WHERE EXISTS (SELECT * FROM claims_paid c WHERE c.policy_number = auto_policies.policy_number AND claim_date > GETDATE() - 365)
Similarly, to record a 10 percent discount in the DISCOUNT column of policies that were claims-free during the past year, you could execute an UPDATE statements such as:
UPDATE auto_policies ap SET discount = .1 * cost, discount = 0.00 WHERE NOT EXISTS (SELECT * FROM claims_paid c WHERE c.policy_number = auto_policies.policy_number AND claim_date > GETDATE() - 365)
When the DBMS executes the second UPDATE statement in the current example, the NOT EXISTS predicate will return TRUE if its subquery returns no rows. Therefore, if none of the rows in the ACCIDENTS table in the subquery has the same POLICY_NUMBER as the current row being processed from the AUTO_POLICIES table in the main query, then the subquery results table will contain no rows. EXISTS will evaluate to FALSE. However, the NOT keyword will reverse the value of EXISTS, and the NOT EXISTS predicate (and overall WHERE clause) will evaluate to TRUE. When the WHERE clause evaluates to TRUE in the second UPDATE statement of the current example, the DBMS will set the value of DISCOUNT column to 10 percent of the policy's cost and will set the value of the SURCHARGE column to 0.
Understanding Correlated Subqueries
As you learned in Tip 321, "Understanding Subqueries," and Tip 332, "Understanding Nested Subqueries," the DBMS executes the SELECT statement in a subquery over and over again—once each time it processes a (joined) row from the source table(s) in the main query. Sometimes, however, a subquery produces the same results table for every row processed by the main query. For example, if there are 10 salespeople in the sales department and you submit the query
SELECT RTRIM(f_name)+' 'l_name AS 'Employee', sales_YTD FROM employees WHERE dept = 'Sales' AND sales_YTD > (SELECT AVG(sales_YTD) FROM employees)
to list the name and SALES_YTD for each employee with an above-average amount of sales in the year, it is very inefficient to have the DBMS repeat the subquery 10 times. After all, the average of the SALES_YTD column values will be the same every time the system computes it.
Fortunately, the DBMS optimizer recognizes subqueries that make no outer column references and executes them only once. After determining the constant value (or set of values) the subquery will return (each time it is executed), the DBMS uses this constant value (or constant set of values) when processing each row of the main query.
Therefore, if the average SALES_YTD in the current example is $50,000.00, then the DBMS optimizer will convert the SELECT statement in the current example to
SELECT RTRIM(f_name)+' 'l_name AS 'Employee', sales_YTD FROM employees WHERE sales_YTD > 50000.00
to reduce the amount of processing required by the query. In its new form, the SELECT statement will produce the same results table, but the shortcut makes it possible for the DBMS to process the subquery once instead of 10 times.
The optimizer cannot use this shortcut, however, if the subquery contains an outer column reference. For example, if you submit a query such as
SELECT c.cust_ID, f_name, l_name, inv_date, SUM(amt_due) AS 'Total Due' FROM customers c, invoices i WHERE amt_due <> 0 AND c.cust_ID = i.cust_ID AND ( (SELECT SUM(amt_due) FROM invoices WHERE invoices.cust_ID = c.cust_ID) > 5000.00 OR EXISTS (SELECT inv_date FROM invoices WHERE invoices.cust_ID = c.cust_id AND amt_due > 0 AND inv_date < GETDATE() - 30) ) GROUP BY c.cust_ID, f_name, l_name, inv_date ORDER by "Total Due"
to get the list of customers who currently owe over $5,000.00 total on invoices or have an invoice with a balance on an invoice dated more than 30 days in the past, the DBMS must execute the subquery
(SELECT SUM(amt_due) FROM invoices WHERE invoices.cust_ID = c.cust_ID) > 5000.00
and the subquery
EXISTS (SELECT inv_date FROM invoices WHERE invoices.cust_ID = c.cust_id AND amt_due > 0 AND inv_date < GETDATE() - 30)
once for each row in the customers table, because the "sum" of the outstanding balances will be different for each of the customer rows in the CUSTOMERS table.
A subquery (such as the two in the current example) that references a column value from an enclosing (or outer) query, is called a correlated subquery because the subquery's results are correlated with each of the rows in the enclosing (outer) query. In the current example, the C.CUST_ID in each of the two subqueries is an outer reference to the CUST_ID column of the row currently being tested in an enclosing (and, in this instance, main) query. Because the value of the CUST_ID is unique to each row in the CUSTOMERS table, the two subqueries in the SELECT statement will be working with a different set of invoices for each joined row from the CROSS JOIN of the rows in the CUSTOMERS table and the rows in the INVOICES table. As a result, the DBMS cannot execute either query only once and use the results of that execution when it processes each of the joined rows in turn.
The important thing to understand now is that a correlated subquery is a subquery that makes an outer reference to at least one column in the row being tested by an enclosing query. Whenever the DBMS "sees" an outer reference in a subquery, it "knows" that it is working with a correlated subquery and must therefore execute the subquery once for each (joined) row it processes from the source table(s) in the enclosing query.
Understanding the Role of Subqueries in a HAVING Clause
In Tip 333, "Understanding the Role of Subqueries in a WHERE Clause," you learned that you can use a subquery in a WHERE clause to filter out individual unwanted rows. A subquery in HAVING clause can also be used in the filtering process. However, instead of using subquery results in a HAVING clause to filter out individual rows, the subquery's results table filters out groups of rows at a time
While a WHERE clause can appear in both grouped and ungrouped queries, a HAVING clause, if present, almost always follows the GROUP BY clause in a grouped query. For example, the HAVING clause in the grouped query
SELECT f_name, l_name, SUM(order_total) AS 'Total Orders' FROM employees, orders WHERE employees.emp_ID = orders.salesperson AND order_date BETWEEN '10/01/2000' AND '10/31/2000' GROUP BY f_name, l_name HAVING SUM(order_total) > .25 * (SELECT SUM(order_total) FROM orders WHERE order_date BETWEEN '10/01/2000' AND '10/31/2000')
tells the DBMS to list each salesperson whose total sales for October 2000 represented more than 25 percent of the sales made during the month by all of the salespeople combined.
Because the subquery in the HAVING clause makes no outer column references, the DBMS can calculate the product of the total orders multiplied by .25 once, and then use the product repeatedly (as a constant) in the HAVING clause as it tests each group of rows for inclusion in the final results table. (After all, 25 percent of the ORDER_TOTAL for October 2000 will be the same whether the DBMS is comparing it to the ORDER_TOTAL for the group of orders sold by the first, tenth, or nth salesperson.)
When executing the main query, the system goes through joined (EMPLOYEES/ORDERS) rows one row at a time, grouping (and totaling) the orders by salesperson. The DBMS then uses the search condition in the HAVING clause to filter out unwanted groups of rows. In the current example, the system removes any groups of rows in which the sum of the ORDER_TOTAL column values in the group is less than or equal to 25 percent of the grand total of all of the values in the ORDER_TOTAL column for the month of October 2000.
In addition to noncorrelated subqueries (that is, subqueries without outer references), you can also use correlated subqueries in a HAVING clause. Suppose, for example, that you want a list showing the name and total sales for each salesperson whose sales during October 2000 exceeded the person's total sales for the prior month by 50 percent or more. Because the subquery contains an outer reference (to the EMP_ID in the group of rows being processed in the main query), the DBMS must execute the correlated subquery in HAVING clause of the query
SELECT f_name, l_name, SUM(order_total) AS 'Total Orders' FROM employees, orders, emp_ID WHERE employees.emp_ID = orders.salesperson AND order_date BETWEEN '10/01/2000' AND '10/31/2000' GROUP BY f_name, l_name, emp_ID HAVING SUM(order_total) >= 1.5 * (SELECT SUM(order_total) FROM orders WHERE salesperson = emp_ID AND order_date BETWEEN '09/01/2000' AND '09/30/2000')
multiple times—one time for each salesperson with sales during the month of October 2000.
To execute the SELECT statement in the current example, the DBMS goes through the joined rows in the (EMPLOYEES/ORDERS) table one group of rows at a time, totaling orders by salesperson. Instead of using a constant value (computed once before applying the HAVING clause filter), the DBMS must compute the total September 2000 sales for a salesperson before going on to test the group of orders from the next salesperson. If the sum of the values in the ORDER_TOTAL column of the group of rows being tested does not exceed the value in the subquery's results table by 50 percent or more, the DBMS filters the group of rows out of the final results table.
The important thing to understand now is that a subquery in a HAVING clause serves the same purpose as a subquery in a WHERE clause. After executing the subquery either once or multiple times (once for each group or rows being processed if the HAVING clauses has a correlated subquery), the system uses the value returned by the subquery to filter unwanted (joined) rows from the enclosing query's results table.
Understanding the Execution Order of Correlated and Noncorrelated Subqueries in JOIN Statements
When executing a JOIN statement that has a noncorrelated subquery, the DBMS joins related rows in the main query's tables first. Next, the system uses any nonsubquery search criteria in main query's WHERE clause to filter out unwanted rows. Then the DBMS executes the subquery to filter out the remaining unwanted rows from the interim (virtual) results table. Finally, the DBMS sends column values from the remaining joined rows to the SELECT clause for output in the query's final results table.
Suppose, for example, that you submit the JOIN statement
SELECT RTRIM(c.f_name)+' '+c.l_name AS 'Customer', RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson' FROM customers c JOIN employees e ON salesperson = emp_ID WHERE cust_ID IN (SELECT cust_ID FROM orders WHERE order_date BETWEEN '01/01/2000' AND '12/31/2000' GROUP BY cust_ID HAVING SUM(order_total) > 100000.00)
to generate a list showing the customer and salesperson for each account that purchased more than $100,000 in products during the year 2000. The DBMS first generates the CROSS JOIN of the CUSTOMERS and EMPLOYEES tables. Next, it uses the nonsubquery conditions in the WHERE clause to filter out rows in which the SALESPERSON (from the CUSTOMERS table) does not match the EMP_ID (from the EMPLOYEES table). The system also filters out any rows with an order date before 01/01/200 or after 12/31/2000. Then the DBMS executes the subquery to generate a table of CUST_ID values from customers with orders totaling more than $100,000.00. Finally, the system works its way through the joined rows in the in the interim (virtual) main query table one row at a time, checking for the existence of the CUST_ID from the joined row in the list of CUST_ID values returned by the subquery. If the CUST_ID from the joined row is in the list returned by the subquery, the DBMS sends the customer and employee name column values to the SELECT clause for output in the final results table.
If the subquery in the JOIN statement is a noncorrelated subquery—meaning that it makes no outer references to column values in an enclosing query—the DBMS needs to execute the subquery only once. For example, in the current example, the DBMS needs to generate the list of CUST_ID values only one time because the list of customers that purchased over $100,000.000 in products will be the same whether the DBMS is testing the first row or the 200th row for inclusion in the final results table. However, if the JOIN statement uses a correlated subquery instead, the DBMS must execute the subquery repeatedly—once for each of the rows not yet filtered out of the interim results table.
For example, if you rewrite the query in the preceding example as
SELECT RTRIM(c.f_name)+' '+c.l_name AS 'Customer', RTRIM(e.f_name)+' '+e.l_name AS 'Salesperson' FROM customers c JOIN employees e ON salesperson = emp_ID WHERE (SELECT SUM(order_total) FROM orders o WHERE o.cust_ID = c.cust_ID AND order_date BETWEEN '01/01/2000' AND '12/31/2000') > 100000.00
the subquery in the WHERE clause is now correlated, since it makes an outer reference to the CUST_ID column value from the enclosing (main) query. Because the sum of each customer's orders is different, the DBMS must execute the subquery repeatedly—once for each joined row in the interim (CUSTOMERS/EMPLOYEES) table it is testing for inclusion in the final results table.
Using the Keyword IN to Introduce a Correlated Subquery to Determine the Existence of a Table Column Having a Specific Value
A correlated subquery can be used in an SQL statement anywhere a noncorrelated subquery can appear. Therefore, while the example queries in Tips 326 and 327 used the keyword IN to produce non-correlated subqueries, you can also use IN to produce correlated subqueries. For example, the query
SELECT cust_ID, f_name, l_name, street_address, state, zip_code FROM customers WHERE 'NV' IN (SELECT ship_to_state FROM orders o WHERE o.cust_ID = c.cust_ID)
will display the rows in the CUSTOMERS table that have NV in the SHIP_TO_STATE column.
| Note |
Due to the heavy processing requirements of correlated subqueries, use them only when there is no alternative. In the current example, the DBMS will execute the subquery repeatedly, generating the list of states to which orders were sent once for each customer. A more efficient alternative is to rewrite the query in the current example either as a JOIN, such as: SELECT DISTINCT c.cust_ID, f_name, l_name, street_address, state, zip_code FROM customers c JOIN orders o ON o.cust_ID = c.cust_ID WHERE ship_to_state = 'NV' or as a multi-table SELECT statement with a WHERE clause similar to: SELECT DISTINCT cust_ID, f_name, l_name, street_address, state, zip_code FROM customers c, orders o WHERE c.cust_ID = o.cust_ID AND ship_to_state = 'NV' |
Understanding Correlated Subqueries Introduced with Comparison Operators
As is the case with a noncorrelated subquery, you can use a correlated subquery in an SQL statement almost anywhere an expression can appear. However, depending on the context in which a subquery is used, SQL places certain restrictions on the subquery's results. For example, if you use a correlated subquery as the expression following one of the six SQL comparison operators (=, <>, >, >=, <, or <=), the subquery must return a single value.
Suppose, for example, that you give your customers a discount of up to 6 percent off their next orders based on the amount they purchased from your company during the past 30 days according to the following schedule:
lower_limit upper_limit discount ----------- ----------- -------- 0.00 9,999.99 0% 10,000.00 19,999.99 1% 20,000.00 29,999.99 2% 30,000.00 39,999.99 3% 40,000.00 49,999.99 4% 50,000.00 59,999.99 5% 60,000.00 999,999.99 6%
The query
SELECT cust_ID, RTRIM(f_name)+' '+l_name AS 'Customer', (SELECT discount FROM discount_schedule WHERE lower_limit <= (SELECT SUM(order_total) FROM orders WHERE orders.cust_ID = c.cust_ID AND order_date >= GETDATE() - 30 AND order_date < GETDATE()) AND upper_limit >= (SELECT SUM(order_total) FROM orders WHERE orders.cust_ID = c.cust_ID AND order_date >- GETDATE() - 30 AND order_date < GETDATE())) AS 'Pct_Discount' FROM customers c WHERE c.cust_ID IN (SELECT cust_ID FROM orders WHERE order_date >= GETDATE() - 30 AND order_date < GETDATE())
will display the CUST_ID, name, and discount percentage for all customers who have placed at least one order during the past 30 days.
In the current example, the correlated subquery introduced by each of the two comparison operators (<= and >=) produces a single value—the sum of the ORDER_TOTAL column for the orders placed by the customer with the CUST_ID from the row being tested in the main query. Because a correlated subquery makes an outer reference to a column in the row being tested in an enclosing query, the DBMS must execute the subquery repeatedly. Therefore, in the current example, the system will sum the ORDER_TOTAL column in the orders table each time it tests another customer row (from the CUSTOMERS table) for inclusion in the final results table.
The DBMS optimizer should pick up the fact that the two correlated subqueries are identical and should sum up each customer's ORDER_TOTAL only once (per customer). Another way to write the query is
SELECT cust_ID, RTRIM(f_name)+' '+l-name AS 'Customer', (SELECT discount FROM discount_schedule WHERE (SELECT SUM(order_total) FROM orders WHERE orders.cust_ID = c.cust_ID AND order_date >= GETDATE() - 30 AND order_date < GETDATE()) BETWEEN lower_limit AND upper_limit) AS 'Pct_Discount' FROM customers c WHERE c.cust_ID IN (SELECT cust_ID FROM orders WHERE order_date >= GETDATE() - 30 AND order_date < GETDATE())
which has only one correlated subquery. The keyword BETWEEN performs the greater than or equal to (>=) and less than or equal to (<=) tests on the LOWER_LIMIT and UPPER_LIMIT values in the DISCOUNT_SCHEDULE table.
| Note |
The correlated subquery in the current example is itself the subquery of another subquery that puts the customer's discount percentage into the PCT_DISCOUNT column of the main query's final results table. Notice, too, that a correlated subquery can make an outer column reference to any query (or subquery) that encloses it. In the current example, the correlated sub-subquery makes an outer column reference not to the subquery in which it is enclosed, but rather to the CUST_ID column of the row being tested in the main query (which encloses both the subquery and the subquery's correlated subquery). |
Using a Correlated Subquery as a Filter in a HAVING Clause
While the DBMS uses the search conditions in a WHERE clause to filter individual unwanted rows out of the query's results table, the system uses search conditions in a HAVING clause to remove groups of rows for which the search conditions evaluate to FALSE. In Tip 336, "Understanding the Role of Subqueries in a HAVING Clause," you learned that you can use a subquery as one of the expressions in a HAVING clause search condition. It should come as no surprise, then, that you can use a correlated subquery as one of the expressions in a HAVING clause search condition as well.
Suppose, for example, that you want to see if an organization is a bit "top heavy" in its management ranks because it has more managers than workers in any department. A query similar to
SELECT dept FROM employees e GROUP BY dept HAVING (SELECT COUNT(*) FROM employees cs_e WHERE e.dept = cs_e.dept AND(position LIKE '%Manager%' OR position LIKE '%Supervisor%' OR position LIKE '%President%')) > (SELECT COUNT(*) FROM employees cs_e WHERE e.dept = cs_e.dept AND(position NOT LIKE '%Manager%' AND position NOT LIKE '%Supervisor%' AND position NOT LIKE 'President%')) ORDER BY dept
will display the names of the departments that have more employees with job titles such as manger, assistant manger, supervisor, vice president, or president than not.
In executing the SELECT statement, the DBMS first groups all rows from the EMPLOYEES table in an interim (virtual) table by department-conceptually similar to that shown in Figure 340.1.
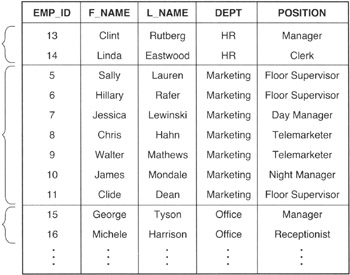
Figure 340.1: The rows in grouped query's interim (virtual) EMPLOYEES table grouped by DEPT
Next, the system goes through the virtual table one department at a time, executing the correlated subqueries in the HAVING clause for each department, and using the subquery results to filter out the groups of rows from departments that have a "management" count that is less than or equal to the "worker" count. Finally, the DBMS sends the value in the DEPT column from each of the remaining groups to the SELECT clause for output in the final results table.
Using a Correlated Subquery to Select Rows for an UPDATE Statement
If you submit an UPDATE statement without a WHERE clause, the DBMS will change the values stored in the column(s) specified in the UPDATE statement's SET clause throughout every row of a table. For example, if you submit the UPDATE statement
UPDATE inventory SET price = price * .75
the DBMS will reduce the PRICE of every item in the inventory by 25 percent. Although this may make your salespeople and customers very happy, you may have to answer to your stockholders for reducing the company's profit margin on high-demand items that are already in short supply.
To confine the changes an UPDATE statement will make to specific rows in a table, add a WHERE clause to the UPDATE statement. For example, to discount only those items that have had no sales within the past 30 days, rewrite the UPDATE statement in the preceding example as:
UPDATE inventory SET price = price * .75 WHERE NOT EXISTS (SELECT * FROM invoice_details i WHERE inventory.item_no = i.item_number AND inv_no IN (SELECT inv_no FROM invoices WHERE inv_date >= GETDATE() - 30))
When processing the revised UPDATE statement, the DBMS first executes the sub-subquery (the noncorrelated subquery within the correlated subquery in the WHERE clause) to generate the list of invoice numbers from invoices for sales made during the past 30 days. The system then goes through the INVENTORY table one item (row) at a time, testing the UPDATE requirement for each row by executing the correlated subquery for each item_number (ITEM_NO) in the INVENTORY table.
Each time it is executed, the correlated subquery builds a list of INVOICE_DETAILS rows from invoices entered within the last 30 days in which the ITEM_NUMBER (from the INVOICE_DETAILS table) matches the value in the ITEM_NO column of the INVENTORY table row being tested. If the item number was not included on any invoice detail records (rows) generated during the past 30 days, then the subquery returns no rows-which causes the EXISTS clause to evaluate to FALSE. However, the keyword NOT (which introduces the EXISTS clause) changes the FALSE to TRUE, thereby causing the WHERE clause to evaluate to TRUE. As such, the WHERE clause causes the DBMS to reduce the item's price by 25 percent whenever there are no invoices that show the item number (ITEM_NO) as being sold within the past 30 days.
The important thing to understand is that the outer column reference in an UPDATE statement's correlated subquery lets you implement a JOIN between the table(s) in the subquery and the target table in the UPDATE statement. While the SQL-89 specification prohibited subqueries in an UPDATE statement from making outer references to columns in the table being updated, the SQL-92 specification has no such restriction. As such, an UPDATE statement such as
UPDATE orders SET shipping_and_handling = 0 WHERE (SELECT SUM(order_total) FROM orders o WHERE o.order_number = orders.order_number) > 1000.00
(which waives the shipping and handling charge on all orders over $1,000.00) was unacceptable under the SQL-89 specification but is perfectly legal in SQL-92.
| Note |
If a correlated subquery in the WHERE clause of an UPDATE statement makes outer references to columns being changed by the statement itself, the DBMS uses the values in the columns prior to any changes throughout the execution of the UPDATE statement. |
SQL Tips and Techniques
- Understanding SQL Basics and Creating Database Files
- Using SQL Data Definition Language (DDL) to Create Data Tables and Other Database Objects
- Using SQL Data Manipulation Language (DML) to Insert and Manipulate Data Within SQL Tables
- Working with Queries, Expressions, and Aggregate Functions
- Understanding SQL Transactions and Transaction Logs
- Using Data Control Language (DCL) to Setup Database Security
- Creating Indexes for Fast Data Retrieval
- Using Keys and Constraints to Maintain Database Integrity
- Performing Multiple-table Queries and Creating SQL Data Views
- Working with Functions, Parameters, and Data Types
- Working with Comparison Predicates and Grouped Queries
- Working with SQL JOIN Statements and Other Multiple-table Queries
- Understanding SQL Subqueries
- Understanding Transaction Isolation Levels and Concurrent Processing
- Writing External Applications to Query and Manipulate Database Data
- Retrieving and Manipulating Data Through Cursors
- Understanding Triggers
- Working with Data BLOBs and Text
- Working with Ms-sql Server Information Schema View
- Monitoring and Enhancing MS-SQL Server Performance
- Working with Stored Procedures
- Repairing and Maintaining MS-SQL Server Database Files
- Writing Advanced Queries and Subqueries
- Exploiting MS-SQL Server Built-in Stored Procedures
- Working with SQL Database Data Across the Internet
EAN: 2147483647
Pages: 632
