Working with Comparison Predicates and Grouped Queries
Understanding Comparison Predicates
An SQL predicate is an expression (often referred to as search condition) in a WHERE clause that asserts a fact. If the assertion is TRUE for a given row in a table, the DBMS performs the action specified by the SQL statement; if the assertion is FALSE, the DBMS goes on to check the predicate against the column values in the next row of the input table. In short, a predicate acts as a filter, allowing only rows that meet its specifications to pass through for further processing.
Table 256.1 shows the six comparison operators you can use to write a comparison predicate.
|
Operator |
Usage |
Meaning |
|---|---|---|
|
= |
A = B |
Process when A is equal to B |
|
< |
A < B |
Process when A is less than B |
|
<= |
A <= B |
Process when A is less than or equal to B |
|
> |
A > B |
Process when A is greater than "B" |
|
>= |
A >= B |
Process when A is greater than or equal to B |
|
<> |
A <> B |
Process when A is not equal to B |
Although you can use a comparison operator to compare any two values-even two literals (constants)-the true value of a comparison predicate is that it lets you identify rows you want based on the value stored in each of one or more columns. For example, the comparison predicate in the WHERE clause of the statement
SELECT * FROM customers WHERE 5 = 5
is of no use as a filter, since 5 is equal to 5 for all rows in the table. As such, the query will display every row in the EMPLOYEE table and could have been written more efficiently without the WHERE clause as:
SELECT * FROM customers
Conversely, the statement
DELETE FROM invoices WHERE invoice_date < '01/01/1900'
tells the DBMS to remove only those rows for invoices dated prior to 01/01/1900 from the INVOICES table. Similarly the comparison predicate in the statement
SELECT cust_ID, cust_name, last_paid, amt_paid, still_due FROM customers WHERE (GETDATE() - last_paid) > 30 AND total_due > 500
tells the DBMS to display only those customers who have outstanding balances greater than $500 and who have not made a payment within the last 30 days. Finally, the UPDATE statement
UPDATE customers SET salesperson = 'Konrad' WHERE salesperson = 'Kris'
tells the DBMS to change the value in the SALESPERSON column to Konrad only in those rows that currently have Kris as the SALESPERSON.
| Note |
Each comparison operator always works with two values. However, you can test for as many column values as you like (two at a time) by joining multiple comparison predicates using the Boolean operators (OR, AND, and NOT) that you learned about in Tip 94, "Using Boolean Operators OR, AND, and NOT in a WHERE Clause." |
Using the BETWEEN Keyword in a WHERE Clause to Select Rows
When you want to work with a set of rows with a column value that lies within a specified range of values, use the keyword BETWEEN in the statement's WHERE clause. For example, to get a list of employees hired during the month of March 2000, you can use a SELECT statement similar to that shown in the MS-SQL Server Query Analyzer input pane near the top of Figure 257.1 to produce a results table similar to that shown at the bottom of the figure.
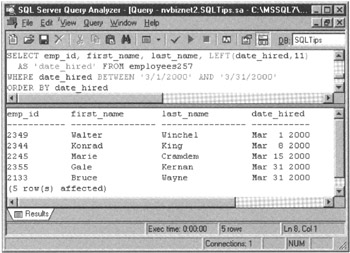
Figure 257.1: MS-SQL Server Query Analyzer query and results table using the BETWEEN keyword
Although the SELECT statement in the current example shows a query in which the upper and lower bounds of the range are literal values, the BETWEEN predicate can actually consist of any three valid SQL expressions with compatible data types, using the syntax:
BETWEEN AND
For example, you can use the SELECT statement
SELECT * FROM employees WHERE (total_sales - 25000) BETWEEN (SELECT AVG(total_sales) FROM employees) AND (SELECT AVG(total_sales) * 1.2 FROM employees)
to list those employees whose total sales volume minus $25,000, is between the average sales volume and 120 percent of the average.
The BETWEEN predicate evaluates to TRUE whenever the value of is greater than or equal to the value of and less than or equal to the value of . Therefore, the query
SELECT first_name, last_name FROM employees WHERE last_name BETWEEN 'J' and 'Qz'
is equivalent to:
SELECT first_name, last_name FROM employees WHERE last_name >= 'J' and last_name <= 'Qz'
One thing to keep in mind is that the value of the low end of the range () must be less than or equal to the value of the high end of the range (). While query
SELECT * FROM employees WHERE date_hired BETWEEN '01/01/2000' AND '01/31/2000'
may appear to be equivalent to
SELECT * FROM employees WHERE date_hired BETWEEN '01/31/2000' AND '01/01/2000'
it is not. The first query lists employees hired in January 2000, while the second query will never list any employees because it can never be the case that the DATE_HIRED is greater than or equal to 01/31/2000 (the ) while at the same time being less than or equal to 01/01/2000 (the ).
Using the IN or NOT IN Predicate in a WHERE Clause to Select Rows
IN and NOT IN predicates let you select a row based on whether or not the row has a column value that is a member of (included in) a set of values. Suppose, for example, that your company has offices in Nevada, California, Utah, and Texas. Since you have to collect sales tax for customers living in those states, you could use the IN predicate in an UPDATE statement such as
UPDATE invoices SET sales_tax = invoice_total * 0.07
WHERE ship_to_state IN ('NV', 'CA', 'UT', 'TX')
to compute the sales tax (given that each state charges the same 7 percent sales tax rate). Conversely, the NOT IN predicate in an UPDATE statement such as
UPDATE invoices SET sales_tax = 0.00
WHERE ship_to_state NOT IN ('NV', 'CA', 'UT', 'TX')
will set sales tax due to 0.00 for customers that do not live any of the states in which your company has offices.
The syntax for the IN and NOT IN predicates is:
[NOT] IN ( [...,.])
While the IN predicate evaluates to TRUE if the is a member of the set of values listed between the parenthesis ( () ), the NOT IN predicate evaluates to TRUE if the is not a member of the set.
As was the case with the BETWEEN predicate (which you learned about in Tip 257, "Using the BETWEEN Keyword in a WHERE Clause to Select Rows"), the IN and NOT IN predicates do not really add to the expressive power of SQL. In the current example, you could have written the UPDATE statement by testing for multiple equalities (joined with OR operators) such as:
UPDATE invoices SET sales_tax = invoice_total * 0.07 WHERE ship_to_state = 'NV' OR ship_to_state = 'CA' OR ship_to_state = 'UT' OR ship_to_state = 'TX'
However, the IN (and NOT IN) predicate does save you some typing if there are a large number of values in the set you are testing for membership (or exclusion) of the value of the .
Using Wildcard Characters in the LIKE Predicate
You can use the LIKE predicate to query the database for a character string value when you know only a portion of the string you want. As such, the keyword LIKE when used in a WHERE clause lets you compare two character strings for a partial match and is especially valuable when you have some idea of the string's contents but do not know its exact form.
The LIKE predicate has two wildcard characters you can use to write the search string when you know only its general form and not all of its characters. The percent sign (%) can stand for any string of zero or more characters in length, and underscore (_) can stand for any single character. To search for a character string using one or more wildcard characters in a LIKE query, simply include the wildcard(s) in a string literal along with the portion of the string you know.
For example, to search for all teachers whose last names begin with the letters "Ki," you could execute a SELECT statement similar to
SELECT first_name, last_name FROM faculty WHERE last_name LIKE 'Ki%'
which will produce a results table similar to:
first_name last_name ---------- --------- Konrad King Wally Kingsly Sam Kingston
Each of the rows selected from the FACULTY table has a LAST_NAME value staring with the two letters "Ki" and followed by any number of other characters.
Similarly, if you want to match any single character vs. any multiple characters, you would use the underscore (_) instead of the percent sign (%). For example, if you know that the letter S was the second character of any class in the Sciences curriculum, and you wanted a list of 100-level courses, you could execute a SELECT statement similar to
SELECT course_ID, description FROM curriculum WHERE course_ID LIKE '_S10_'
to produce a results table similar to:
course_ID description --------- ----------------------------------------- CS101 Introduction to Computer Science BS109 Biological Sciences - Anatomy & Physiology MS107 Beginning Quadratic Equations
Each of the rows the DBMS selects from the CURRICULUM table has COURSE_ID value with S as the second character, followed by 10, and ending with one and only one additional character. Unlike the percent sign (%) wildcard, which can match zero or more characters, the underscore (_) wildcard can match one and only one character. As such, in the current example, the course_IDs S101 and CS101H would not be included in the query's results table. The S in S101 is the first and not the second character, and two characters instead of one follow the 10 in CS101H.
Using Escape Characters in the LIKE Predicate
In Tip 259, "Using Wildcard Characters in the LIKE Predicate," you learned how to use wildcard characters in a LIKE predicate to query the database for string values when you know only a portion of the string you want. However, what do you do when you want to search for a string that includes one of the wildcard characters?
To check for the existence of a percent sign (%) in a character data type column, for example, you need a way to tell the DBMS to treat a percent sign (%) in the LIKE predicate as a literal value instead of a wildcard. The keyword ESCAPE lets you identify a character that tells the DBMS to treat the character immediately following the escape character in the search string as a literal value. For example, the query
SELECT cust_ID, cust_name, discount FROM customers WHERE discount LIKE "%S%" ESCAPE 'S'
uses the escape character S to tell the DBMS to treat the second percent sign (%) in the search string %S% as a literal value (and not a wildcard). As a result, the query will return the CUST_ID, CUST_NAME, and DISCOUNT column values for any rows in which the last character in the DISCOUNT column is a percent sign (%).
Similarly, if you want to search for the underscore (_) character in a data type column, you would use the keyword ESCAPE in a query such as
SELECT product_code, description FROM inventory WHERE product_code LIKE "XY$_%" ESCAPE '$'
to tell the DBMS to treat the character following the dollar sign ($) as a literal character instead of a wildcard. As a result, of the query in the current example, the DBMS will display the PRODUCT_CODE and DESCRIPTION of all INVENTORY items in which the product code starts with "XY_".
Using LIKE and NOT LIKE to Compare Two Character Strings
SQL has two predicates that let you search the contents of a CHARACTER, VARCHAR, or TEXT data type column for a pattern of characters. The LIKE predicate will return the set of rows in which the target column contains the pattern of characters in the search string. Conversely, the NOT LIKE predicate will return those rows in which the pattern is not found in the target column.
For example, the query
SELECT * FROM customers WHERE cust_name LIKE 'KING'
will display rows in the CUSTOMERS table in which the value in the target column (CUST_NAME) is KING. Meanwhile, the query
SELECT * FROM customers WHERE cust_name NOT LIKE 'SMITH'
will display the rows in the CUSTOMERS table that do not have SMITH in the CUST_NAME column.
The LIKE and NOT LIKE predicates are of little value if not used with the wildcard characters you learned about in Tip 259, "Using Wildcard Characters in the LIKE Predicate." After all, you could have written the two example queries using the equality (=) and not equal to (<>) comparison operators, as follows:
SELECT * FROM customers WHERE cust_name = 'KING' SELECT * FROM customers WHERE cust_name <> 'SMITH'
In short, the LIKE predicate is useful when you "know" only some of the characters in the target column, or if you want to work with all rows that contain a certain pattern of characters. For example, if you "know" the name of the customer is something like KING, but you are not sure if it is KINGSLY, KING, or KINGSTON, you could query the database using a SELECT statement similar to:
SELECT * FROM customers WHERE cust_name LIKE 'KING%'
The percent sign (%) wildcard character tells the DBMS to match any zero of more characters. As such, the query in the current example tells the DBMS to display the columns in a CUSTOMERS table rows in which the value of the target column (CUST_NAME) starts with the letters KING followed by any zero or more additional characters.
Similarly, if you precede the search string with a percent sign (%) you can search for a pattern of characters within a string. For example, the query
SELECT * FROM customers WHERE notes LIKE "%give%discount%"
will display the rows in the CUSTOMERS table in which the value in the target column (NOTES) includes the word GIVE followed by at least one occurrence of the word DISCOUNT. Therefore, the DBMS would display the columns in a row in which the NOTES column contained the string: "Excellent customer. Make sure to give a 5% discount with next order."
Conversely, the NOT LIKE predicate, when used in conjunction with one or more wildcard characters, will display those rows that do not contain the pattern of characters given by the search string. Thus, the query
SELECT * FROM customers WHERE notes NOT LIKE "%discount%"
will display a list of customer rows whose NOTES column does not include the pattern of letters that make up the word discount.
Understanding the MS SQL Server Extensions to the LIKE Predicate Wildcard Characters
In Tip 259, "Using Wildcard Characters in the LIKE Predicate," you learned how to use the percent sign (%) and underscore (_) wildcard characters in LIKE predicates to compare character strings for a partial match. While the underscore lets you match any single character and the percent sign (%) lets you match any pattern of zero or more characters, neither wildcard lets you specify the range in which the unknown character(s) must fall. For example, the query
SELECT * FROM employees WHERE badge LIKE '1___'
with three underscores after the 1 tells the DBMS to display any employees whose four-character badge number starts with a 1. If you want to limit the results to badge numbers in which the first character is a 1 and the second character is an a, A, b, B, c, or C, for example, MS-SQL Server lets you use brackets ([]) to provide specify a set of characters the wildcard underscore (_) can match. As such, the query
SELECT * FROM employees WHERE badge LIKE '1[a-cA-C]__'
tells the DBMS to display four character badge numbers in which the first character is a "1", the second character is an uppercase or lower case letter "A", "B", or "C", and is followed by any to other characters (represented by the final two wildcard underscores in the search string).
Conversely, if you want to exclude a range of characters from those matched by the wildcard, insert a caret (^) between the left bracket ([) and the first value in the range of characters that can be substituted for the wildcard character.. For example, if you want a list of badge numbers in which the first character is a number 1-9 and the three remaining characters are not letters of the alphabet, MS-SQL Server lets you execute a query similar to:
SELECT * FROM employees WHERE badge LIKE '[1-9][^a-zA-Z][^a-zA-Z][^a-zA-Z]'
Using the NULL Predicate to Find All Rows in Which a Selected Column Has a NULL Value
As you learned in Tip 30, "Understanding the Value of NULL," a NULL value in a column indicates unknown or missing data. Because the actual value in the column is not known, the DBMS cannot make any assumptions about its value. As a result, the SELECT statement
SELECT * FROM employees WHERE manager = NULL
will never display any rows—even if several rows in the EMPLOYEES table have a NULL value in the MANAGER column.
The reason for the seemingly incorrect behavior in which the WHERE clause test
NULL = NULL
does not return TRUE when the value in the MANAGER column is NULL is that NULL really means "not known." As such, the DBMS cannot make a determination whether the unknown value on the left side of the equality operator is the same as the unknown value on the right side. Therefore, the DBMS must return the value NULL for
NULL = NULL
instead of TRUE.
To find out if a table column's value is NULL, use the IS NULL predicate. Unlike the equality operator (=), which evaluates to TRUE only if the items on both sides of the operator are equal, the IS NULL operator simply tests for a state of being—that is, "is the value in the column NULL?" which can be either TRUE or FALSE without making any assumptions as to the actual value of the column. Thus, the query
SELECT * FROM employees WHERE manager IS NULL
will display those rows in the EMPLOYEES table in which the value in the MANAGER column has a NULL (unknown or missing) value.
SQL also provides a special predicate you can use to find those rows that do not have a NULL value in a specific column. After all, if the test
NULL = NULL
evaluates NULL (and not TRUE), the test
NULL <> NULL
must evaluate NULL as well, since the DBMS cannot make any assumptions as to the actual value of the NULL (unknown) value on either side of the not equal to (<>) comparison operator.
To query the DBMS for rows in which the value in the MANAGER column is not NULL, use IS NOT NULL. For example, the SELECT statement
SELECT * FROM employees WHERE manager IS NOT NULL
will display the columns in the rows of the EMPLOYEES table in which the value in the MANAGER column is not NULL.
Understanding the ALL Qualifier in a WHERE Clause
The ALL qualifier uses the syntax
ALL
to let you use a (such as =, <>, >, and <) to compare the (single) value of the to each of the values in the results table returned by the single column that follows the keyword ALL. If every comparison evaluates to TRUE, the WHERE clause returns TRUE. On the other hand, if any comparison evaluates to FALSE, or if the returns no rows, the WHERE clause returns FALSE.
For example, if you want a list of salespeople from OFFICE 1 that had more sales than all of the salespeople in your company's other offices, you can execute a SELECT statement with an ALL qualified WHERE clause similar to:
SELECT * FROM employees WHERE sales > ALL (SELECT sales FROM employees WHERE OFFICE <> 1)
When evaluating an ALL qualifier in a WHERE clause, the DBMS uses the to compare each value of the to each of the column values returned by the . In the current example, the WHERE clause evaluates TRUE only when the value of the SALES column (the ) is greater than (the ) every value in the results table returned by the (the single column SELECT statement that follows the keyword ALL). The WHERE clause evaluates to FALSE if any comparison of the to a results table value is FALSE or if the subquery returns no rows.
In addition to using a column reference as the , you can also use any literal value (constant) or SELECT statement that returns a single value. (While the to the right of the keyword ALL can return more the one value, the query used to generate the must return, by definition, a single value.)
For example, if you are a publisher and want to see if any one title sold more copies than all of the other titles you published combined, you could execute a SELECT statement with an ALL qualifier similar to the following:
SELECT * FROM titles WHERE (SELECT SUM(qty_sold) FROM sales WHERE sales.isbn = titles.isbn) > ALL (SELECT SUM(qty_sold) FROM sales WHERE sales.isbn <> titles.isbn)
In the current example, the SELECT clause used as the computes the total sales volume for each of the books in the SALES table. The DBMS uses the greater than comparison operator to compare each sales volume figure to the value returned by the . If the comparison evaluates to TRUE for a given row in the TITLES table, the WHERE clause returns TRUE, and the DBMS displays the row's columns in the SELECT statement's results table.
Understanding the SOME and ANY Qualifiers in a WHERE Clause
Similar to the ALL qualifier you learned about in Tip 264, "Understanding the ALL Qualifier in a WHERE Clause," the SOME and ANY qualifiers use the syntax
{SOME|ANY)
to let you use a to compare the (single) value of the to each of the values in the results table returned by the single-column . If any one of comparisons evaluates to TRUE, the WHERE clause returns TRUE. Conversely, if all comparisons evaluate to FALSE, or if the returns no rows, the WHERE clause returns FALSE.
Suppose, for example, that you want a list of salespeople from OFFICE 1 that have more sales than at least one of the salespeople in your company's other offices, you can execute a SELECT statement with either a SOME (or an ANY) qualified WHERE clause similar to:
SELECT * FROM employees WHERE sales > SOME (SELECT sales FROM employees WHERE OFFICE <> 1)
When evaluating a SOME qualifier in a WHERE clause, the DBMS uses the to compare each value of the to each of the column values returned by the . In the current example, the WHERE clause evaluates to TRUE whenever a value in the SALES column of a row from the EMPLOYEES table (the ) is greater than (the of) one or more values in the results table returned by the (the single-column SELECT statement that follows the keyword ALL). The WHERE clause evaluates to FALSE if every comparison of the to results table value is FALSE or if the subquery returns no rows.
As was true with the ALL qualifier, the can be a column reference, a literal value (constant), or a subquery that returns a single value—so long as the data type of the is compatible with the data type of values returned by the single-column that follows the keyword ALL.
For example, if you are a publisher and want to see if any one title sold more copies than any one of the other titles you published, you could execute a SELECT statement with an ANY (or a SOME) qualifier similar to the following:
SELECT * FROM titles WHERE (SELECT SUM(qty_sold) FROM sales WHERE sales.isbn = titles.isbn) > ANY (SELECT qty_sold FROM sales WHERE sales.isbn <> titles.isbn)
In the current example, the SELECT clause, used as the , takes the number of books sold for each title, and uses the greater than (>) comparison operator to compare the count sold to the sales counts of all of the other books in the results table returned by the . If any of the comparisons evaluates to TRUE for a given row in the TITLES table, the WHERE clause returns TRUE, and the DBMS displays the row's columns in the SELECT statement's results table.
SQL Tips and Techniques
- Understanding SQL Basics and Creating Database Files
- Using SQL Data Definition Language (DDL) to Create Data Tables and Other Database Objects
- Using SQL Data Manipulation Language (DML) to Insert and Manipulate Data Within SQL Tables
- Working with Queries, Expressions, and Aggregate Functions
- Understanding SQL Transactions and Transaction Logs
- Using Data Control Language (DCL) to Setup Database Security
- Creating Indexes for Fast Data Retrieval
- Using Keys and Constraints to Maintain Database Integrity
- Performing Multiple-table Queries and Creating SQL Data Views
- Working with Functions, Parameters, and Data Types
- Working with Comparison Predicates and Grouped Queries
- Working with SQL JOIN Statements and Other Multiple-table Queries
- Understanding SQL Subqueries
- Understanding Transaction Isolation Levels and Concurrent Processing
- Writing External Applications to Query and Manipulate Database Data
- Retrieving and Manipulating Data Through Cursors
- Understanding Triggers
- Working with Data BLOBs and Text
- Working with Ms-sql Server Information Schema View
- Monitoring and Enhancing MS-SQL Server Performance
- Working with Stored Procedures
- Repairing and Maintaining MS-SQL Server Database Files
- Writing Advanced Queries and Subqueries
- Exploiting MS-SQL Server Built-in Stored Procedures
- Working with SQL Database Data Across the Internet
EAN: 2147483647
Pages: 632
