Creating Indexes for Fast Data Retrieval
Understanding Indexes
Although not defined in the SQL-92 standard, most DBMS products automatically create an index based on a table's PRIMARY KEY and let you define additional indexes to speed up data access and retrieval. Do not confuse a PRIMARY KEY (see Tip 171, "Understanding Primary Keys") or a FOREIGN KEY (see Tip 173, "Understanding Foreign Keys") with an index. Database keys (which are defined in the SQL standard) are constraints that place limits on column data values. Indexes, meanwhile, are physical storage structures (like tables) that the DBMS can use to quickly find table rows with specific values in one or more columns.
While the rows in a table are not in any particular order, the values in an index are arranged in either ascending or descending order. The DBMS uses a table's index as you would an index in a book. When executing a query based on a data value in an indexed column, the database looks in the index to find the column value and then follows the index entry's pointer to the table row.
| Note |
One exception to the unordered nature of rows in a relational table is MS-SQL Server's implementation of a clustered index, which you will learn about in Tip 165, "Understanding MS-SQL Server Clustered Indexes." For unclustered indexes, the DBMS sorts the values in the index but does not arrange a table's rows in any particular order. On MS-SQL Server, however, a table can have a single clustered index, and MS-SQL Server arranges the table's rows based on the data values that make up the columns in the clustered index. |
The presence of an index structure in an SQL database does not violate Codd's ninth rule, which specifies that a relational database must have "logical data independence," because the presence or absence of an index is completely transparent to the SQL user. (You learned about Codd's rules in Tip 6, "Understanding Codd's 12-Rule Relational Database Definition.")
Suppose, for example, that you wanted to display information on calls your marketing personnel made to 263–1052 using a SELECT statement similar to:
SELECT date_called, call_time, hangup_time, dispo, called_by FROM call_history WHERE phone_number = 2631052
The statement itself does not indicate whether the CALL_HISTORY table has an index based on the PHONE_NUMBER column and will execute the query in either case. If there is no index, the DBMS will have to sequentially scan (read) every row in the table, displaying column values from those rows with a 2631052 in the PHONE_NUMBER column. If the CALL_HISTORY table has millions of rows, the process of retrieving and examining each and every row can take a long time.
If, on the other hand, the table has an index based on the PHONE_NUMBER column, as shown in Figure 159.1, the DBMS can use a search method to find the first index entry that satisfies the search criteria. Next, the DBMS needs to read sequential items in the index only until the "next" index value no longer satisfies the search condition.
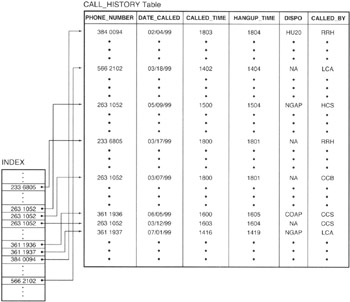
Figure 159.1: CALL_HISTORY Table with an index on the PHONE_NUMBER column
The advantages of using an index are that:
- An index greatly speeds up a search because the index is sorted and the DBMS can use special access methods to find a particular data value in the index.
- The index adds little to the actual row retrieval overhead because each index row is small (typically a single data value and a pointer) and can, therefore, be retrieved quickly. Moreover, the index increases the speed of the physical row retrieval by providing a pointer value that tells the DBMS exactly where on disk it can find the row the user wants to see.
- The index drastically reduces the number of rows the DBMS must read during a query. In the current example, the DBMS can stop reading after three retrievals (given that there are only three 2631052 entries in the table) instead of scanning (reading) all of the perhaps millions of rows in the table.
Balanced against these advantages, the main disadvantages of using an index are that:
- The index uses disk space the DBMS could otherwise use to store table data or transaction logs.
- Each INSERT and DELETE requires additional overhead because the DBMS must add (INSERT) or remove (DELETE) a row not only in the table itself, but also in each of the indexes on the table. Moreover, each update on an indexed column requires that the DBMS change both the base table and the data stored in the index on the column being updated.
To maximize the advantages of using an index and minimize the disadvantages, add multiple indexes to tables that are more often used in queries than as targets of INSERT and UPDATE operations. Furthermore, in tables you index, base the index(es) on columns that are frequently found in search conditions your users use in queries on the table. As mentioned at the beginning of this tip, the DBMS always creates an index based on a table's PRIMARY KEY in anticipation that the table's rows will most often be queried with SELECT statements containing a range of PRIMARY KEY values in the WHERE clause.
Understanding How MS SQL Server Selects an Index for a Query
MS-SQL Server has the ability to use multiple indexes per table within a single query. As a result, MS-SQL Server's 7.0 multiple search condition query execution is greatly improved over previous versions because the user can virtually eliminate table scans (in which the DBMS reads every row in a table) by creating indexes on the correct table columns. After creating one or more indexes on a table, you should typically let MS-SQL Server's query optimizer decide which index to use during query execution.
In order for MS-SQL Server to consider using an index, one of the columns in the SELECT statement's WHERE clause must be the first column in the index. For example, if you have a CALL_HISTORY table created with
CREATE call_history (phone_number INTEGER, date_called DATETIME, call_time SMALLINT, hangup_time SMALLINT, disposition VARCHAR(4), called_by CHAR(3))
and create an index with
CREATE INDEX date_index ON call_history (date_called, call_time, phone_number)
MS-SQL Server will never select the DATE_INDEX when executing the query
SELECT * FROM call_history WHERE phone_number = 2631070
because the column named in the search condition (PHONE_NUMBER) is not the first column in the index.
| Note |
You will learn how to create indexes using the CREATE INDEX statement in Tip 161, "Using the CREATE INDEX Statement to Create an Index." For now, the important thing to know is that MS-SQL Server will choose to use an index only if its first column is one of the columns named in the SELECT statement's WHERE clause. |
Conversely, if you create another index by executing the CREATE statement
CREATE INDEX caller_index ON call_history (called_by, date_called)
and submit the query
SELECT * FROM call_history WHERE called_by = 'RRH' AND phone_number = 2631056
the MS-SQL Server optimizer will review the system tables that summarizes the distribution of information in the table being queried and decide whether a table scan or indexed query is the best way to retrieve the data requested by the SELECT statement. If the DBMS decides that an indexed query is best, it will use the second, CALLER_INDEX, as the only index available for selection (in the current example), since its first column (CALLED_BY) is one of the columns used in the SELECT statement's search criteria.
Instead of letting MS-SQL Server's optimizer choose the best index when it executes a query, you can tell the DBMS which index to use by including an INDEX = clause in the SELECT statement's FROM clause. For example, the SELECT statement
SELECT * FROM call_history INDEX=caller_index WHERE date_called BETWEEN '01/01/2000' AND '01/31/2000'
forces the DBMS to use the CALLER_INDEX when MS-SQL Server would have chosen the DATE_INDEX to optimize the query.
| Note |
Be very careful when forcing the DBMS to use a particular index vs. letting the optimizer select the best one for the job. In the current example, forcing the use of the CALLER_INDEX causes significant and unnecessary overhead in that the DBMS will have to read every entry in the index in order to satisfy the query. Had MS-SQL Server been allowed to use the DATE_INDEX instead, the DBMS would have used an efficient search algorithm to find the first index entry that satisfied the search criteria (DATE_CALLED BETWEEN '01/01/200' AND '01/31/2000') and could have stopped reading rows in the index as soon as it encountered the first date outside the acceptable date range. |
Using the CREATE INDEX Statement to Create an Index
As you learned in Tip 159, "Understanding Indexes," indexes let a DBMS answer queries without reading every row in each of the tables listed in a SELECT statement's FROM clause. For large tables, performing a full-table scan looking for rows whose column data values satisfy a query's search criteria can be very expensive in terms of processing time. Imagine reading a system manual from cover to cover each time you need help on a particular topic. Without an index, you (like the DBMS) would spend the majority of your time reading pages of information that have nothing to do with answering the question at hand. Just as using a system manual's alphabetized index lets you quickly zero in on the page(s) with the information you want, traversing the sorted values in database indexes lets the DBMS find and retrieve table rows that satisfy a query's search condition(s) with the least amount of system overhead.
When executing a CREATE INDEX statement, the DBMS reads through the table being indexed one row at a time. As it reads each row, the system creates a key (from the concatenation of the column[s] being indexed), and inserts the key into the index along with a pointer to the physical disk location of the row that produced it.
The basic syntax of the CREATE INDEX statement is:
CREATE [UNIQUE] INDEX ON ( [ASC | DESC] [,... [ASC | DESC]])
Therefore, to create an index on the INV_DATE and INV_NO columns of an INVOICES table, you would use a CREATE INDEX statement similar to:
CREATE INDEX date_index ON INVOICES (inv_date, inv_no)
| Note |
Some DBMS products let you specify whether the values in the index are sorted in ascending (ASC) or descending (DESC) order. Before using ASC or DESC in your CREATE INDEX statements, check your system manual to make sure that your DBMS product supports the selection of an index sort option. MS-SQL Server, for example, lets you add the ASC and DESC after the column name(s) in the CREATE INDEX statement, but it ignores both attributes and always sorts its indexes in ascending order. |
Adding the keyword UNIQUE to the CREATE INDEX statement tells the DBMS to create a unique index, which allows only nonduplicate entries. In the current example, if you change the CREATE INDEX statement to
CREATE UNIQUE INDEX date_index ON INVOICES (inv_date, inv_no)
the DBMS will create the index DATE_INDEX only if every row in the INVOICES table has a unique pair of data values for INV_DATE and INV_NO—that is, only one row in a table could have an INV_DATE of 02/01/2000 and an INV_NO of 5. Moreover, after the DBMS creates a unique index, attempts to insert a row into the indexed table will fail with an error message similar to
Server: Msg 2601, Level 14, State 3, Line 1 Cannot insert duplicate key row in object 'invoices' with unique index 'date_index'. The statement has been terminated.
if adding the row's key value requires the DBMS to INSERT a duplicate entry into a unique index.
| Note |
When creating a unique index, make sure none of the columns being indexed allow NULL values. MS-SQL Server, for example, treats a NULL as a distinct value. As such, if you create a single-column unique index, MS-SQL Server will only allow users to add one row only to the table with a NULL in the indexed column. (Adding a second row would require a duplicate key entry [two NULLs] in the unique index.) |
Understanding MS SQL Server CREATE INDEX Statement Options
Tip 161, "Using the CREATE INDEX Statement to Create an Index," refers to the statement syntax
CREATE [UNIQUE] INDEX ON ( [ASC | DESC][,... [ASC | DESC]])
as the basic syntax for a CREATE INDEX statement because every DBMS product provides its own set of additional options you can use to tell the system such things as the drive or location on the hard drive where it is to create the index, how much free space to leave for additional data on each index page, and how the index is to be maintained.
For example, the syntax of the CREATE INDEX statement on MS-SQL Server is:
CREATE [UNIQUE] [CLUSTERED I NONCLUSTERED] INDEX ON
([,...]) [WITH [DROP_EXISTING] [[,] FILLFACTOR = <% fill factor>] [[,] PAD_INDEX] [[,] IGNORE_DUP_KEY] [[,]STATISTICS_NONRECOMPUTE] ] [ON ]
The remaining sections of this tip will explain the meaning of each of the options available when creating an index on an MS-SQL Server. If you are using an SQL server other than MS-SQL Server, familiarize yourself with the purpose of each option and then check your system manual to see which index options are available on your DBMS.
UNIQUE
In Tip 161, you learned that applying the UNIQUE option to an index prevents the insertion rows into the indexed table if the column values in the rows produce a key value that already exists in the table's unique index. In essence, creating an index based on two or more columns and specifying the UNIQUE option is a way to apply a non-PRIMARY KEY multi-column UNIQUE constraint to the table being indexed. Since every combination of the indexed column values must be unique in the INDEX, then the same combination of column values must also be unique in the table itself. You INSERT a row into a table without adding the key value for the row to each of the indexes on the table.
CLUSTERED NONCLUSTERED
An MS-SQL Server nonclustered index works the way in which you would expect an index to work. The DBMS sorts the key values in the nonclustered index (in ascending order) while leaving the indexed table's rows unsorted. Conversely, when you create a clustered index, MS-SQL Server sorts not only the key values in the index, but also sorts the rows in the table to match the sort of the index. You will learn more about clustered indexes in Tip 165, "Understanding MS-SQL Server Clustered Indexes." By default, MS-SQL Server creates a nonclustered index if you specify neither the clustered nor the nonclustered option when creating an index.
DROP_EXISTING
Because a table can have only one clustered index, you must first DROP the existing clustered index if you want to re-create it or a new one based on a different set or order of indexed columns. Whenever you DROP a clustered index, MS-SQL Server automatically rebuilds each of the remaining nonclustered indexes on the table. The server also re-creates all nonclustered indexes on a table whenever it creates a clustered index for the table. Thus, dropping a clustered index and re-creating it using a DROP INDEX and then a CREATE CLUSTERED INDEX statement results in MS-SQL Server building each nonclustered index twice.
The DROP_EXISTING option lets you re-create a clustered index using a single statement. When the DBMS executes a CREATE CLUSTERED INDEX statement with the DROP_EXISTING option, it deletes the existing clustered index, re-creates it, and then rebuilds all of the nonclustered indexes.
FILLFACTOR
MS-SQL Sever stores table and index data in 2KB pages. Index pages are linked together in a tree arrangement such as that shown in Figure 162.1.
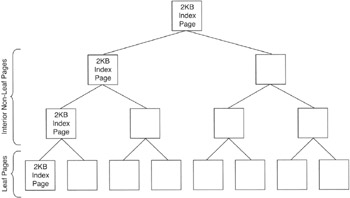
Figure 162.1: MS-SQL Server index page tree
The way in which MS-SQL Server uses a binary tree to find specific key values in an index is beyond the scope of this book. The important things to know are that index key values are stored in 2KB pages, and whenever an index page gets full, the DBMS must split the page in two to add additional nodes with space for more key values to its index page tree.
Page splits are very expensive in terms of system overhead and therefore should be avoided when possible. The FILLFACTOR tells the DBMS how much space to leave for additional key values on each of the leaf pages it creates while executing a CREATE INDEX statement.
| Note |
Regardless of the value supplied for the FILLFACTOR, the DBMS always creates interior (nonleaf) pages with room for one additional entry in a clustered index and room for two additional entries in a nonclustered index. |
A FILLFACTOR of 100, for example, tells the DBMS to use 100 percent of the 2KB available in each leaf page for existing index values. While completely filling the leaf pages creates the smallest index possible, doing so also produces a large number of index page splits when rows are added to the table or indexed column values are changed. With a FILLFACTOR of 100 none of the leaf pages have room to hold additional key values and any row insertion or indexed column value change will cause a page split. Therefore, you should specify a FILLFACTOR of 100 percent (FILLFACTOR=100) only for "read-only" tables not subject to future insertions and updates.
Use a small FILLFACTOR such as 10 percent for indexes on tables that do not yet contain their complete datasets. When you specify a FILLFACTOR of 10, for example, the DBMS will fill leaf pages to only 10 percent of capacity. Therefore, if the sum of the column sizes that make up the index is such that 200 keys can fit on a 2KB page, the DBMS will build each leaf page with 20 key values—leaving the remaining 180 (90 percent) available to hold additional keys without requiring index page splits when adding new rows or updating indexed column values to the indexed table.
If you do not explicitly specify a FILLFACTOR (1 - 100), MS-SQL Server will set the FILLFACTOR to 100 and fill each leaf to 100% capacity.
PAD_INDEX
The PAD_INDEX option is useful only if you specify a nonzero FILLFACTOR. While the FILLFACTOR tells the DBMS what percentage of the 2KB leaf page space to use when building a new index, the PAD_INDEX option tells the DBMS to apply the FILLFACTOR usage percentage to the nonleaf, interior pages in the index tree. As such, if you specify FILLFACTOR=10 and also add the PAD_INDEX option to the CREATE INDEX statement, the DBMS will generate leaf and nonleaf index pages that contain only approximately 205 bytes of data (10 percent of 2KB).
Regardless of the FILLFACTOR specified, the DBMS always puts at least one key value on each interior page and leaves room for at least one additional key entry (two entries for non-clustered indexes).
IGNORE_DUP_KEY
Specifying the IGNORE_DUP_KEY option does not let you create a unique index on a column (or set of columns) if the table already contains duplicate values in the column (or combination of columns). IGNORE_DUP_KEY affects only the way in which MS-SQL Server handles future UPDATE and INSERT statements that attempt to add rows with duplicate key values into a unique index.
Whether you include the IGNORE_DUP_KEY option or not, the system will not allow you to add a row to a table if its column values would result in a duplicate key being added to a unique index. However, without the IGNORE_DUP_KEY option, the DBMS will abort a duplicate key insertion attempt with an error and will roll back all transaction processing up to that point. Conversely, if you include the IGNORE_DUP_KEY option in the CREATE UNIQUE INDEX statement, MS-SQL Server still aborts a duplicate key insertion attempt, but it issues a warning message (instead of raising an error) and continues transaction processing with the next statement.
STATISTICS_NONRECOMPUTE
During index creation, MS-SQL Server makes notes in a special statistics page regarding the distribution of data values in the indexed columns of the table. The DBMS later uses its statistics pages when deciding which of the indexes to use in minimizing the time it takes to answer a query. Adding the STATISTICS_NONRECOMPUTE option to the CREATE INDEX statement tells MS-SQL Server not to automatically recompute the index statistics periodically when the statistics become outdated due to row insertions, deletions, and indexed column value changes.
Setting the STATISTICS_NONRECOMPUTE option eliminates the overhead involved in performing periodic table scans to update index statistics pages. However, out-of-date statistics may prevent the query optimizer from selecting the optimal index when executing a query. Using the "wrong" index reduces the speed at which the DBMS can return query results and may in fact wipe out any overhead reduction by forcing table scans for query results instead of allowing an efficient indexed search.
ON
A FileGroup is the logical name MS-SQL Server uses to refer to a physical disk spaces the database uses to hold its objects. When you execute the CREATE DATABASE statement, MS-SQL Server creates the FileGroup PRIMARY and stores all tables, views, indexes, stored procedures, and so on in the disk space allocated to the PRIMARY FileGroup. You can create and add additional FileGroups (named physical disk areas) to the database at any time.
The advantage of having multiple FileGroups in a database is that you can spread them across multiple physical disk drives, which allows the system hardware to perform simultaneous I/O operations on database objects. Suppose, for example, that you let the DBMS create the PRIMARY FileGroup on the C drive and then created the FileGroup FILEGROUP2_D on the D drive and FILEGROUP3_E on the E drive. The CREATE INDEX statements
CREATE INDEX product_index ON invoices (product_code, inv_date, inv_no) ON FILEGROUP2_D CREATE INDEX date_index ON invoices (inv_date, inv_no) ON FILEGROUP3_E
would place each of the two indexes on a different disk drive. As such, when you insert a new row into the INVOICES table, the DBMS could tell the system hardware to update the table on the C drive and then have it update both the indexes simultaneously. If both indexes were located in the same FileGroup, the operating system would have to update one index and then proceed to update the other.
Using the MS SQL Server Enterprise Manager to Create an Index
In addition to the CREATE INDEX statement (which you learned about in Tip 161, "Using the CREATE INDEX Statement to Create an Index," and Tip 162, "Understanding MS-SQL Server CREATE INDEX Statement Options"), MS-SQL Server also provides a graphical method for index creation through the Enterprise Manager.
To use the MS-SQL Server Enterprise Manager to CREATE an index, perform the following steps:
- Start the Enterprise Manager by clicking your mouse pointer on the Start button. When Windows displays the Start menu, move your mouse pointer to Programs, select Microsoft SQL Server 7.0, and then click your mouse pointer on Enterprise Manager.
- To display the list of SQL servers, click your mouse pointer on the plus (+) to the left of SQL Server Group.
- Click your mouse pointer on the plus (+) to the left of the icon for the SQL server on which you want to create the index. For example, if you want to create an index for a table on a server named NVBIZNET2, click your mouse pointer on the plus (+) to the left of the icon for NVBIZNET2. The Enterprise Manager will display folders containing databases and services available on the MS-SQL Server you selected.
- Click your mouse pointer on the plus (+) to the left of the Databases folder. The Enterprise Manager will display a list of the databases managed by the server you selected in Step 3.
- Select the database that contains the table on which you wish to create the index. For the current project, click your mouse pointer on the plus (+) to the left of the SQLTips icon in the expanded Databases list. Enterprise Manager will display the icons for the database objects types in the SQLTips database.
- Click your mouse pointer on the icon for Tables. Enterprise Manager will display the list of tables in the SQLTips database in its right pane.
- Click your mouse pointer on the table for which you wish to create an index. (Enterprise Manager sorts the list of tables alphabetically. If you do not see the one you want, use the scroll bar on the right side of the Enterprise Manager window to display additional database tables.) For the current example, click your mouse pointer on the icon for the INVOICES table.
- Select the Action menu All Tasks option, and click your mouse pointer on Manage Indexes. Enterprise Manager will display the Manage Index dialog box.
- To define a new index, click your mouse pointer on the New button. Enterprise Manager will display a Create New Index dialog box similar to that shown in Figure 163.1.
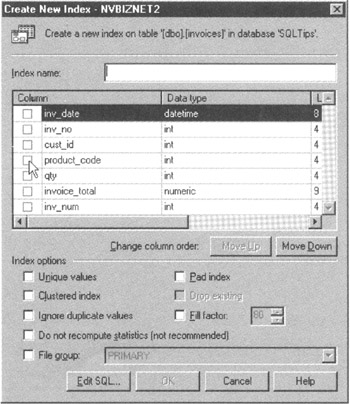
Figure 163.1: The MS-SQL Server Enterprise Manager Create New Index dialog box - Enter a name for the index in the Index Name field. Although not any valid object name is permissible as an index name, use the name of the first column in the index as either part of or the beginning of the name to make it easier to figure out if MS-SQL Server will use the index to speed up a query. (In Tip 160, "Understanding How MS-SQL Server Selects an Index for a Query," you learned that MS-SQL Server will use an index for a query only if a column used in the SELECT statement's search criteria is the first column in the index.) Also, if you preface indexes on FOREIGN KEY columns with fk_ and the index on the PRIMARY KEY with pk_, you can easily keep track of which keys have indexes and which do not. For the current project, enter product_code_index into the Index Name field.
- To select the column(s) to index, click your mouse pointer on the check box to the left of each of the column names you want to include. For the current example, click your mouse pointer on the check box to the left of PRODUCT_CODE and on the check box to the left of INV_DATE until both contain check marks.
- Use the Move Up and Move Down buttons to specify the order of the columns in the index. For the current project, move the INV_DATE column down so that it is the second column in the index. To do so, click you mouse pointer on the column name INV_DATE, and then click your mouse pointer on the Move Down button repeatedly until INV_DATE appears after PRODUCT_CODE in the column list area of the dialog box.
- Select the additional options for the index by clicking your mouse pointer on the check boxes to the left of each index option you want to select in the Index options section of the dialog box. (You learned what each of the index options means in Tip 162.) For the current project, leave all of the index options check boxes blank.
- To create the index and return to the Manage Index dialog box, click on the OK button.
- Repeat Steps 9–14 for each new index you want to create. If you need to change the definition of an index, click your mouse pointer on the index you want to modify and then on the Edit button. Or, to remove (DROP) an index, click your mouse pointer on the Delete button.
- When you are finished defining indexes for the table, click your mouse button on the Close button.
As you learned in Tip 160, the order of the columns in an index is very important. Therefore, be sure to arrange the columns in the index properly in Step 12. An index with the correct columns in an incorrect order is useless. For example, leaving the INV_DATE as the first column of the PRODUCT_CODE_INDEX will result in the DBMS having to perform a full-table scan to satisfy the query
SELECT SUM(qty) FROM invoices WHERE product_code = 4
whereas rearranging the index columns as PRODUCT_CODE followed by INV_DATE will let MS-SQL Server use the index PRODUCT_CODE_INDEX to reduce the number of table row retrievals to just those in which the value of the product code is 4.
Using the DROP INDEX Statement to Delete an Index
Although table indexes can greatly reduce the amount of time it takes the DBMS to return the results of a query by reducing the required number of read operations, indexes do take up disk space and can have a negative on performance if the indexed tables are often updated. Remember, updating the value in an indexed column is twice as expensive in terms of processing overhead as updating the same column if it is not part of an index.
When changing an indexed column value, the DBMS not only must change the value of the column in the table, but also must update each index that includes the column. Since the DBMS stores indexes as additional tables, updating a column that is also a part of three indexes results in four table updates vs. one for a table with no indexes. Similarly, each DELETE statement not only must remove a row from the main table, but also must delete a row from each index on the table. Moreover, INSERT statements add even more overhead since each one requires that the DBMS add data to the indexed table and to every one of the indexes on that table. (Unless you are updating a column that appears in every index on a table, the DBMS does not have to change every index when storing an updated indexed column value.)
To minimize the overhead and disk space usage of database indexes, use the DROP INDEX statement to remove indexes you no longer need. Like the CREATE INDEX statement, the syntax of the DROP INDEX statement will vary among database products. Some require only the name of the index, such as:
DROP INDEX
Others require both table name and index name, such as:
DROP INDEX .
MS-SQL Server, for example, requires both table name and index name. As such, you would execute the DROP INDEX statement
DROP INDEX invoices.product_code_index
to remove the index PRODUCT_CODE_INDEX from the INVOICES table.
Understanding MS SQL Server Clustered Indexes
A clustered index is a special index on an MS-SQL Server table that forces the DBMS to store table data in the exact order of the index. The advantages of using a clustered index are:
- The table will use the minimum disk space required because the DBMS will automatically reuse space previously allocated to deleted rows when new rows are inserted.
- Queries with value range criteria based on the columns in a clustered index will execute more quickly because all of the values within a range are physically located next to each other on the disk.
- Queries in which data is to be displayed in ascending order based on the columns in the clustered index do not need an ORDERED BY clause since the table data is already in the desired output order.
When creating a clustered index, bear in mind that a table can have one and only one such index. After all, the table's rows must be arranged in the order of the clustered index, and a single table can have only one physical arrangement of records on disk.
To create a clustered index, add the keyword CLUSTERED to the CREATE INDEX statement you learned about in Tip 161, "Using the CREATE INDEX Statement to Create an Index," and Tip 162, "Understanding MS-SQL Server CREATE INDEX Statement Options." For example, to CREATE a clustered index based on the PRODUCT_CODE and INV_DATE columns of an INVOICES table, execute the CREATE INDEX statement:
CREATE CLUSTERED INDEX cl_product_code_index ON invoices (product_code, inv_date)
| Note |
The CL_ at the beginning of the index name CL_PRODUCT_CODE_INDEX, is optional. However, if you start every clustered index with CL_, you can easily distinguish the clustered index (if any) for a particular table from the nonclustered indexes on the table. |
If you define a clustered index for a table that contains data, MS-SQL Server will lock the table while creating the index. As such, make sure to create clustered indexes for tables with a lot of rows only during those times when it is most convenient for the table's data to be unavailable to DBMS users and application programs. While building the index, the DBMS not only inserts the clustered index column values into the index, but it also rebuilds the table itself, arranging the rows in the same order in which their key entries appear in the index.
After creating a clustered index on a table, the DBMS will automatically rearrange rows as necessary to keep the rows of the table in the same order as the keys in the index as you INSERT new rows or UPDATE values in columns that are part of the cluster. As such, it is not a good idea to CREATE a clustered index on a table that is subject to a high number of row insertions or updates to clustered index columns. The overhead involved in physically moving rows in the table as well as updating the index will quickly outweigh any performance gains resulting from the omission of ORDER BY clauses and the faster execution of value range searches.
| Note |
When executing a CREATE INDEX statement that has neither the CLUSTERED nor the NONCLUSTERED keyword, the DBMS will create a NONCLUSTERED index. |
Using the MS SQL Server Index Tuning Wizard to Optimize Database Indexes
In Tips 159-165, you learned that most DBMS products support indexes because indexes can greatly improve overall system performance by speeding up query execution and reducing the overhead resulting from unnecessary full table scans. However, you also learned that selecting the wrong columns to index can actually have a negative impact on system response time. If the majority of a system's queries are based on nonindexed columns while those columns that are indexed seldom appear in SELECT statement WHERE clauses, the DBMS not only fails to capitalize on the advantages of indexing, but it also incurs the additional overhead of maintaining indexes that serve no useful purpose.
MS-SQL Server provides the Server Profiler and Index Tuning Wizard to help you create the optimal set of indexes for your operating environment. After the Server Profiler captures a log of all queries submitted against a database to a trace file, the Index Tuning Wizard can analyze the statements within the log to determine the indexes that will result in the greatest improvement in query and overall DBMS performance. By using a trace file that lists a representative sample of system queries, the Index Tuning Wizard's suggestions are based on the server's actual workload vs. some theoretical database model.
To use the MS-SQL Server Index Tuning Wizard, perform the following steps:
- Start the Enterprise Manager by clicking your mouse pointer on the Start button. When Windows displays the Start menu, move your mouse pointer to Programs, select Microsoft SQL Server 7.0, and then click your mouse pointer on Enterprise Manager.
- To display the list of SQL servers, click your mouse pointer on the plus (+) to the left of SQL Server Group.
- Select the SQL server that manages the database with the tables on which you want to run the Index Tuning Wizard by click your mouse pointer on the server's icon. For example, if you want to run the wizard on a server named NVBIZNET2, click your mouse pointer on the icon for NVBIZNET2.
- Select the Tools menu Wizards option. Enterprise Manager will display the Select Wizard dialog box.
- To display the list of database management wizards, click your mouse pointer on the plus (+) to the left of Management.
- Click your mouse pointer on the Index Tuning Wizard entry in the expanded list of database management wizards, and then click on the OK button. Enterprise Manager will start the Index Tuning Wizard, which will display its Welcome to the Index Tuning Wizard message box.
- Click your mouse pointer on the Next button to proceed to the Index Tuning Wizard-Select Server and Database dialog box shown in Figure 166.1.
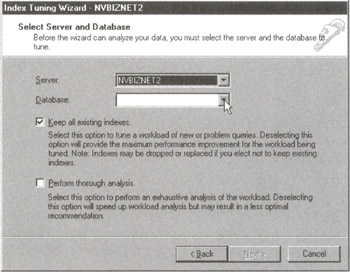
Figure 166.1: The MS-SQL Server Index Tuning Wizard Select Server and Database dialog box - To select the database with the tables you want to index, click your mouse pointer on the drop-down list button to the right of the Database field. After the Index Tuning Wizard displays the list of database names on the server you selected in Step 3, click your mouse pointer on the name of the database you want to use. For the current project, click your mouse pointer on SQLTips.
- To have the Index Tuning Wizard remove existing indexes it finds to be unnecessary based on the system query workload, click your mouse button to the left of "Keep all existing indexes" to make the check mark disappear.
Note The Index Tuning Wizard may drop an index name in a SELECT statement's INDEX= clause. As a result, a previously functional query may stop working. Since the MS-SQL Server Query Optimizer almost always selects the most efficient index for a query, you should discourage the use of forcing the SQL Server to use a particular index by including an INDEX= clause in a SELECT statement.
- To have the Index Tuning Wizard suggest the indexes which will most improve system and query performance, click your mouse pointer on the check box to the left of "Perform thorough analysis" to make a check mark appear.
- Click your mouse pointer on the Next button. The Wizard will display the Index Tuning Wizard-Identify Workload dialog box shown in Figure 166.2.
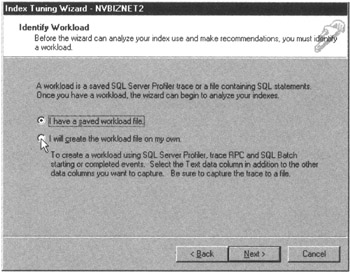
Figure 166.2: The MS-SQL Server Index Tuning Wizard Identify Workload dialog box - If you previously saved an MS-SQL Server Profiler trace to disk or have a file containing SQL statements on which you want the Index Tuning Wizard to base its analysis, click your mouse pointer on the I Have a Saved Workload File radio button; then click the Next button and continue at Step 21.
- To create a new trace file of your system's workload, click your mouse pointer on the radio button to the left of I Will Create the Workload File on My Own, and then click on the Finish button. The Index Tuning Wizard will end, and the Enterprise Manager will start the MS-SQL Server Profiler.
- In the MS-SQL Server Profiler application window, select the File menu Run Traces option (or click your mouse pointer on the Start Traces [the green triangle] button on the Standard toolbar). MS-SQL Server Profiler will display a list of traces in a Start Selected Traces dialog box, similar to that shown in Figure 166.3.
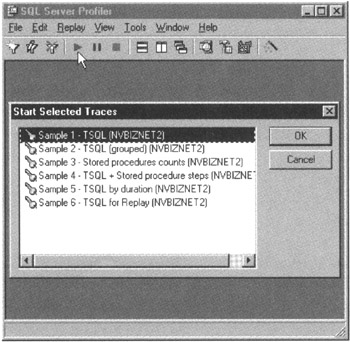
Figure 166.3: The MS-SQL Server Profiler Start Selected Traces dialog box - The Sample 1 trace (which comes standard with MS-SQL Server) will capture the events and data columns the Index Tuning Wizard needs for its analysis. As such, click your mouse pointer on Sample 1-TSQL () to select the Sample 1 trace, and then click on the OK button.
The MS-SQL Server Profiler will start logging SQL queries processed by the SQL server against the database you selected in Step 8. You need to let the profiler run for a while in order to build up a log with a representative sample of the database query workload on your DBMS. Depending on your system's usage patterns, capturing a representative sample workload may take several hours or several days. Capturing a good sample of the queries most often using during normal operations is important because the Index Tuning Wizard bases its recommendations on optimizing the SELECT statements in the log file. If the log is not representative of the queries that commonly occur in your DBMS, then the indexes the Index Tuning Wizard suggests may not be the ones that produce the best performance under your system's normal workload.
Note If you are running the Server Profiler over a long period of time, be sure to write the trace log's contents to your hard drive periodically by selecting the File menu Save option every couple of hours (at least). When presented with the Save As dialog box, enter a name for the trace file in the File Name field and then click your mouse pointer on the OK button. The one thing you want to avoid is creating a large, unsaved log file only to have your system reset or lock up for some reason before you save the trace log to a disk file.
- After the trace log contains a representative sample of your system's workload, click your mouse pointer on the Stop This Trace (the red square) button on the Standard toolbar.
- To save the trace log to disk, select the File menu Save option. The MS-SQL Server Profiler will display the Save As dialog box.
- Enter a filename for the log file in the File Name field, and then click your mouse pointer on the OK button. For the current project, enter INDEX_TRACE-SQLTips in the File Name field.
- Select the File menu Exit option to exit the MS-SQL Server Profiler application.
- Return to the MS-SQL Server Enterprise Manager window and repeat Steps 4-12. (If you closed the Enterprise Manager while running the Profiler, repeat Steps 1-12 instead.) Be sure to click the radio button to the left of I Have a Saved Workload File when you perform Step 12.
- After you click your mouse pointer on the Next button in Step 12, the Index Tuning Wizard will display the Specify Workload dialog box shown in Figure 166.4. Click your mouse pointer on the My Workload File radio button. The wizard will display the Open dialog box.
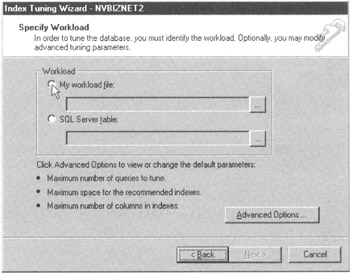
Figure 166.4: The MS-SQL Server Index Tuning Wizard Specify Workload dialog box - In the File Name field, enter the name of the trace (log) file you want the Index Tuning Wizard to analyze, and then click your mouse pointer on the OK button. For the current project, enter INDEX_TRACE-SQLTips in the File Name field.
- If you want to specify the maximum number of queries to tune, the maximum space for the recommended indexes, or the maximum columns per index, click your mouse pointer on the Advanced Options button. The Index Tuning Wizard will display its Index Tuning Parameters dialog box, which has the fields you need to enter each of the three maximum value options. For the current project, accept the system defaults.
Note Of the three maximum options, you will want to increase the maximum space for the recommended indexes if your database tables have a large number or rows-which means each index will need to hold a large number of key values. The defaults for the maximum number of queries to tune and maximum columns per index will typically yield the optimal tuning results. If you are unsure of the settings you want, you can always try different settings by repeating Steps 23-25 and using the settings that yield the highest value for the percentage of estimated improvement shown near the bottom of the Index Recommendations dialog box (shown in Figure 166.6).
- Click your mouse pointer on the Next button to display the Index Tuning Wizard-Select Tables to Tune dialog box shown in Figure 166.5.
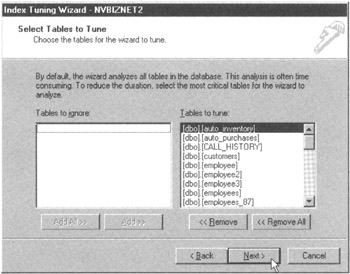
Figure 166.5: The MS-SQL Server Index Tuning Wizard Select Tables to Tune dialog boxThe default is to have the wizard tune the indexes for all tables. If you want to work with only some of the tables, select the tables whose indexes you do not want to tune in Tables to Tune section of the dialog box, and then click your mouse pointer on the Remove button to exclude the tables you selected from the index tuning process. For the current project, accept the default and let the Index Tuning Wizard tune the indexes in all of the SQLTips database tables.
- After you have the list of tables whose indexes you want to tune in the Tables to Tune section of the dialog box, click your mouse pointer on the Next button. The Index Tuning Wizard will read through the log file you entered in Step 22 and use the MS-SQL Server Query Optimizer to asses the hypothetical performance of every query in the log based on using each of the possible combinations of indexes on columns used in the SELECT statements. After the wizard completes its analysis, it will display the list of indexes that produce the best overall performance for the entire set of queries in the log file, similar to that shown in Figure 166.6.
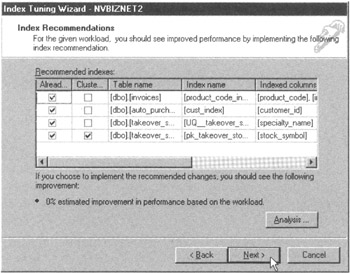
Figure 166.6: The MS-SQL Server Index Tuning Wizard Index Recommendations dialog box - Click your mouse pointer on the Next button. The wizard will display an Index Tuning Wizard-Schedule Index Update Job dialog box similar to that shown in Figure 166.7.
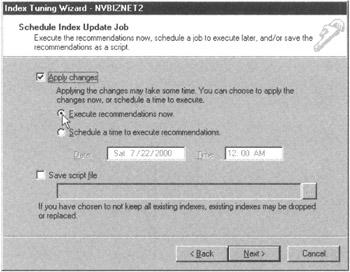
Figure 166.7: The MS-SQL Server Index Tuning Wizard Schedule Index Update Job dialog box - To have the Index Tuning Wizard apply the recommended changes to index structure of the database, click your mouse pointer on the "Apply changes" check box to make a check mark appear. Next, decide if you want the indexing process to happen now or if you want to schedule it for another time. For the current project, click your mouse pointer on the radio button to the left of Execute Recommendations Now.
Note Creating indexes on many and/or large database tables will have a significant impact on system performance, since the DBMS will spend the majority of its processing cycles on the task and users will find their statements executing much more slowly than normal. Moreover, when the DBMS creates a clustered index on an existing table, the table is unavailable for use while its index is being created. Therefore, carefully assess your system usage patterns and perform the index creation process at a time of low or (preferably) no system usage to have the least impact on database users and application programs.
- After making your selection of the timing of the index creation, click your mouse pointer on the Next button. The Index Tuning Wizard will display a Completing the Index Tuning Wizard message box. Click on the Finish button either to create the indexes now or to schedule their creation at a later time, depending on your selection in Step 27.
When the Index Tuning Wizard displays its successful completion message box after Step 28, click on the OK button to return to the Enterprise Manager application window.
SQL Tips and Techniques
- Understanding SQL Basics and Creating Database Files
- Using SQL Data Definition Language (DDL) to Create Data Tables and Other Database Objects
- Using SQL Data Manipulation Language (DML) to Insert and Manipulate Data Within SQL Tables
- Working with Queries, Expressions, and Aggregate Functions
- Understanding SQL Transactions and Transaction Logs
- Using Data Control Language (DCL) to Setup Database Security
- Creating Indexes for Fast Data Retrieval
- Using Keys and Constraints to Maintain Database Integrity
- Performing Multiple-table Queries and Creating SQL Data Views
- Working with Functions, Parameters, and Data Types
- Working with Comparison Predicates and Grouped Queries
- Working with SQL JOIN Statements and Other Multiple-table Queries
- Understanding SQL Subqueries
- Understanding Transaction Isolation Levels and Concurrent Processing
- Writing External Applications to Query and Manipulate Database Data
- Retrieving and Manipulating Data Through Cursors
- Understanding Triggers
- Working with Data BLOBs and Text
- Working with Ms-sql Server Information Schema View
- Monitoring and Enhancing MS-SQL Server Performance
- Working with Stored Procedures
- Repairing and Maintaining MS-SQL Server Database Files
- Writing Advanced Queries and Subqueries
- Exploiting MS-SQL Server Built-in Stored Procedures
- Working with SQL Database Data Across the Internet
EAN: 2147483647
Pages: 632
