What Are URLs?
| < Day Day Up > |
A URL is a uniform way to refer to objects and services on the Internet. Even novice users should be familiar with typing a URL, such as http://www.democompany.com, in a browser dialog box, to get to a Web site. Internet users also use URLs to invoke other Internet services, such as transferring files via FTP or sending e-mail. HTML authors use URLs in their documents to define hyperlinks to other Web documents. Despite its potentially confusing collection of slashes and colons, the URL syntax is designed to provide a clear, simple notation that people can easily understand. The following concepts will help you to understand the major components of a URL address.
| Note | Some people call URLs "universal resource locators." Except for a historical reference to "universal resource locators" in documentation from a few years ago, the current standard wording is "uniform resource locator." |
| Note | The W3C often calls what users believe a URL to be a URI. The W3C is working from a more advanced view of Web addressing discussed later in the chapter. For this discussion we always use URL, which is more broadly understood . |
Basic Concepts
To locate any arbitrary object on the Internet, you need to find out the following information:
-
First, you need to locate and access the machine on the Internet (or intranet) on which the object resides. Locating the site might be a matter of specifying its domain name or IP address, whereas accessing the machine might be a matter of providing a username and password.
-
After you access the machine, you need to determine the name of the desired file, where the file is located, and what protocol will be used to retrieve the information or access the object.
The URL describes where something is and how it will be retrieved. The where is specified by the machine name, the directory name, and the filename. The how is specified by the protocol (for example, HTTP). Slashes and other characters are used to separate the parts of the address into machine-readable pieces. The basic structure of the URL is shown here:
protocol://site address/directory/filename
The next several sections look at the individual pieces of a URL in closer detail.
Site Address
A document exists on some server computer somewhere on the global Internet or within a private intranet. The first step in finding a document is to identify its server. The most convenient way to do this on a TCP/IP-based network is with a symbolic name, called a domain name . On the Internet at large, a fully qualified domain name (FQDN) typically consists of a machine name, followed by a domain name. For example, www.microsoft.com specifies a machine named www in the microsoft.com domain. On an intranet, however, things might be a little different, because you can avoid using a domain name. For example, a machine name of hr-server might be all that you need to access the human resources server within your company's intranet.
| Note | A machine name indicates the local, intra-organizational name for the actual server. A machine name can be just about any name because machine naming has no mandated rules. Conventions exist, however, for identifying servers that provide common Internet resources. Servers for Web documents usually begin with the www prefix or often today have no set machine name. However, many local machines have names similar to the user's own name (for example, jsmith), his or her favorite cartoon character (for example, homer), or even an esoteric machine name (for example, dell-p6-200-a12). Machine naming conventions are important because they allow users to form URLs without explicitly spelling them out. A user who understands domain names and machine naming conventions should be able to guess that Toyota's Web server is http://www.toyota.com. |
The other part of most site addresses ”the domain name ”is fairly regular. Within the United States, a domain name consists of the actual domain or organization name, followed by a period, and then a domain type. Consider, for example, sun.com. The domain itself is sun, which represents Sun Microsystems. The sun domain exists within the commercial zone because of Sun's corporate status, so it ends with the domain type of com . In the United States, most domain identifiers currently use a three-character code that indicates the type of organization that owns the server. The most common codes are com for commercial, gov for government, org for nonprofit organizations, edu for educational institutions, net for networks, and mil for military. Recently, the general top level domain (gTLD) name space has been expanded to include domain extensions such as .biz, . info , .name, .aero, .pro, .museum, and .coop. Furthermore, many international names have suggested using their domains as top-level domains such as .cc, .nu, .ws, and .tv. Even more countries , large and small, seem to be allowing global registration of their domain names, which is unfortunate as it somewhat ruins the regional information that geographical domain names provided.
Domain space beyond the United States typically contains more information than organization type with a FQDN, including a country code as well and generally is written as follows :
machine name.domain name.domain type.country code
Zone identifiers outside the U.S. use a two-character code to indicate the country hosting the server. These include ca for Canada, mx for Mexico, jp for Japan, and so on. The U.S. also uses the .us extension although it has only recently caught on outside of local government and k12 educational environments. Within each country, the local naming authorities might create domain types at their own discretion, but these domain types can't correspond to American extensions. For example, www.sony.co.jp specifies a Web server for Sony in the co zone of Japan. In this case, co, rather than com, indicates a commercial venture. In the United Kingdom, the educational domain space has a different name, ac . Oxford University's Web server is www.ox.ac.uk, whereby ac indicates academic, compared to the U.S. edu extension for education . In spite of the avoidance of geographical name use for large, multinational companies (such as Sony), regional naming differences are still at this point very much alive . Web page authors linking to nonnative domains are encouraged to first understand the naming conventions of those environments. One special top-level domain, int , is reserved for organizations established by international treaties between governments , such as the European Union (eu.int). Top-level domains, such as com , net , and any new domains, will not necessarily correspond to a particular geographic area.
| Note | Symbolic names make it convenient for people to refer to Internet servers. A server's real address is its Internet Protocol (IP) numeric address. Every accessible server on the Internet has a unique IP address by which it can be located using the TCP/IP protocol. An IP address is a numeric string that consists of four numbers between 0 and 255 and is separated by periods (for example, 10.0.0.124). This number then might correspond to a domain name, such as www.democompany.com. Note that a server's symbolic name must be translated, or resolved, into an IP address before it can be used to locate a server. An Internet service known as Domain Name Service (DNS) automatically performs this translation. You can use an IP address instead of a symbolic name to specify an Internet server, but doing so gives up mnemonic convenience. In some cases, using an IP address might be necessary because although every server has an IP address, not all servers have symbolic names. |
Investigating all aspects of the domain name structure is beyond the scope of this book. However, it should be noted that domain name formats and the domain name lookup service are very critical to the operation of the Web. If the domain name server is unavailable, it is impossible to access a Web server. To learn more about machine and domain names, see http://www.domainnotes.com.
| Note | Domain names are not case-sensitive. Addresses can be written as www.Democompany. com or www.DEMOCOMPANY.com. A browser should handle both properly. Case typically is changed for marketing or branding purposes. However, directory and file names following the domain name might be case-sensitive, depending on the operating system the Web server is running on. For example, UNIX systems are case-sensitive, whereas Windows machines are not. Trouble can arise if casing is used randomly . As a rule of thumb, keep everything in lowercase. |
Directory
Servers might contain hundreds, if not thousands, of files. For practical use, files need to be organized into manageable units, analogous to the manila folders traditionally used to organize paper documents. This unit is known as a directory. After you have determined the server on which a document resides, the next step toward identifying its location is to specify the directory that contains the file. Just as one manila folder can contain other folders, directories can contain other directories. Directories contain other directories in a nested, hierarchical structure that resembles the branches of a tree.
The directory that contains all others is known as the root directory . Taken together, all the directories and files form a file tree, or file system . A file is located in a file system by specifying its directory path . This is the nested list of all directories that contain the file, from the most general ”the root directory ”to the most specific. Similar to the UNIX operating system, directories hosted on Web servers are separated by forward slashes (/) rather than backslashes (\), as in MS-DOS and Windows. Figure 4-2 shows a sample file tree for a Web site.
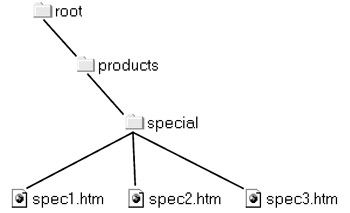
Figure 4-2: Sample file tree
Figure 4-2 shows how directories are organized within (or above and below) one another. For example, the directory called special is within the products directory, which is within the root directory. The full path should be written as /products/special/ to indicate that special is an actual directory, not a file in the products directory. When linking to other files, you might need to refer to a directory above the current directory, or to the current directory itself. In the scheme presented, ./ means the current directory, whereas ../ means one directory up in the hierarchy. A document in the special directory with a link path of ../ will link up to the products directory. Interestingly, while this type of information should be common knowledge to even a casual computer user, with the rise of GUI operating systems, many users are not as aware of this notation as they might be. However, for Web site construction it is mandatory to understand this.
| Note | Directory names might follow conventions specific to an operating system, including conventions for case sensitivity. Authors are cautioned to look carefully at directory casing. Furthermore, directories might follow popular usage conventions (for example, tmp), or they can be arbitrary. Usually, directory names reflect aspects of their content such as media types, subject matter, or access privileges. For example, a directory called "images" might be the name of a directory containing images. |
Filename
After you specify the server and directory path for a document, the next step toward locating it is to specify its filename. This step typically has two parts: a filename, followed by a standard file extension. Filenames can be any names that are applicable under the server's operating system. Special characters such as spaces, colons, and slashes can wreak havoc if used in names of Web-available files. A file named test:1.htm would present problems on a Macintosh system, whereas test/1.htm might be legal on a Macintosh but problematic on a PC or UNIX machine.
A dot separates the filename and the extension , which is a code, generally composed of three or four letters , which identifies the type of information contained in the file. For example, HTML source files have a .htm or .html extension. JPEG images have a .jpg extension. A file's extension is critically important for Web applications because it is the primary indication of the information type that a file contains. A Web server reads a file extension and uses it to determine which headers, in the form of a MIME type (discussed in Chapter 16), to attach to a file when delivering it to a browser. If file extensions are omitted or misused, the file could be interpreted incorrectly. When browsers read files directly, they also look at file extensions to determine how to render the file. If the extension is missing or incorrect, a file will not be properly displayed in a Web browser.
Although many operating systems support four or more letters for file extensions, using a three-letter extension (.htm) versus a four-letter extension (.html) may minimize cross- platform incompatibilities. For the greatest flexibility, you should also avoid using spaces, uppercase letters, and special characters. Authors and users, in particular, should be aware of case sensitivity in filenames and directory names.
| Note | It is possible to have filenames without extensions. Clean URLs that may employ content negotiation such as www.democompany.com/about show no file extension even when addressing files or other objects directly. This advanced idea, though W3C standards based, is still relatively rare and requires modification of a Web server to work. While far beyond the scope of this book, Apache administrators may look into mod_rewrite and mod_negotation to enable this interesting and highly usable URL form, while IIS administrators might use pageXchanger (www.pagexchanger .com) to achieve a similar result. |
Protocol
Finally, we need to specify how to retrieve information from the specified location. This is indicated in the URL by the protocol value. A protocol is the structured discussion that computers follow to negotiate resource-specific services. For example, the protocol that makes the Web possible is the Hypertext Transfer Protocol (HTTP). When you click a hyperlink in a Web document, your browser uses the HTTP protocol to contact a Web server and retrieve the appropriate document.
| Note | Although HTTP stands for Hypertext Transfer Protocol, it doesn't specify how a file is transported from a server to a browser, only how the discussion between the server and browser will take place to get the file. The actual transport of files usually is the responsibility of a lower- layer network protocol, such as the Transmission Control Protocol (TCP). On the Internet, the combination of TCP and IP makes raw communication possible. Although a subtle point, many Internet professionals are unaware of lower-level protocols below application protocols such as HTTP, which are part of URLs. |
Although less frequently used than HTTP, several other protocols are important to Web page authors because they are often invoked by hyperlinks. Table 4-1 lists some examples.
| Protocol | Description |
|---|---|
| file | Enables a hyperlink to access a file on the local file system |
| ftp (File Transfer Protocol) | Enables a hyperlink to download files from remote systems |
| mailto | Invokes a mail program to enable a hyperlink to send an addressed e-mail message |
| news | Enables a hyperlink to access a USENET newsgroup using an external news reader |
| telnet | Enables a hyperlink to open a telnet session on a remote host |
| Note | Sometimes the protocol javascript: is used in a URL; for example, javascript:alert('hi'). This is not a network protocol per se, but this form of URL is commonly found in Web pages. See Chapter 14 for a more in-depth discussion. |
These are the common protocols, but a variety of new protocols and URL forms are being debated all the time. Someday, such things as LDAP (Lightweight Directory Access Protocol), IRC (Internet Relay Chat), phone, fax, and even TV might be used to reference how data should be accessed. You can read more about the future of URLs and other naming ideas at the end of this chapter.
Special Features of URLs
In addition to the protocol, server address, directory, and filename, URLs often include a username and password, a port number, and sometimes a fragment identifier. Some URLs, such as mailto, might even contain a different form of information altogether, such as an e-mail address rather than a server or filename.
Username and Password
FTP and telnet are protocols for authenticated services . Authenticated services can restrict access to authorized users, and the protocols can require a username and password as parameters. A username and password precede a server name, like this: ftp:// username : password @ server- address. The password could be optional or unspecified in the URL, making the form simply ftp:// username @ server-address .
| Tip | HTML authors should avoid including password information in URLs because the information may be readily viewable in a Web page or within the browser's URL box. If the password is omitted, the browser will prompt for the password. |
Port
Although not often used, the communication port number in a URL also can be specified. Browsers speaking a particular protocol communicate with servers through entry points, known as ports, which generally are identified by numeric addresses. Associated with each protocol is a default port number. For example, an HTTP request defaults to port number 80. A server administrator can configure a server to handle protocol requests at ports other than the default numbers. Usually, this occurs for experimental or secure applications. In these cases, the intended port must be explicitly addressed in a URL. To specify a port number, place it after the server address, separated by a colon ; for example, http:// site-address :8080. Usually, the reason for port changes is to allow multiple services to run at once or to slightly improve security through obscurity by using a nonstandard port number. However, this security is fairly weak and using different port numbers may confuse users or might even result in difficulty accessing a site.
Fragment
Besides referencing a file, it may be desirable to send a user directly to a particular point within the file. Because you can set up named links under traditional HTML and name any tag using ID under HTML 4 or XHTML, you can provide links directly to different points within a file. To jump to a particular named link, the URL must include a hash symbol (#) followed by the link name, which indicates that the value is a fragment identifier. For example, <a href="#contents"> . Then, to specify a point called "contents" in a file called test.htm, you would use test.htm#contents. Elsewhere in the file, the fragment name would be set using a named anchor, such as <a name="contents"></a> or, more appropriately, by setting an id value on an arbitrary tag like <a id="link1"> or <p id="firstParagraph"> . This will be discussed later in the chapter in the section "Using name and id to Set Link Destinations."
Encoding
When writing the components of a URL, take care that they are written using only the displayable characters in your character set, which is most likely the ASCII character set. Even when using characters within this basic keyboard character range, you will find certain unsafe characters. You also might find reserved characters that could have special meaning within the context of a URL or the operating system on which the resource is found. If any unsafe, reserved, or nonprintable characters occur in a URL, they must be encoded in a special form. Failure to encode these characters might lead to errors.
The form of encoding consists of a percent sign and two hexadecimal digits corresponding to the value of the character in the ASCII character set. Within many intranet environments, filenames often include user-friendly names, such as "first quarter earnings 1999.doc." Such names contain unsafe characters ”in this case, spaces. If this file were to live on a departmental Web server, it would have a URL with a file portion of first%20quarter%20earnings%201999.doc. Notice how the spaces have been mapped to %20 values ”the hex value of the space character in ASCII. Other characters that will be troublesome in URLs include the slash character ( / ), which encodes as %2F , the question mark (?), which maps to %3F , and the percent symbol (%) itself, which encodes as %25 . Only alphanumeric values and some special characters ($ - _ . + ! * '), including parentheses, may be used in a URL; other characters should be encoded. In general, special characters such as accents, spaces, and some punctuation marks have to be encoded. Whenever possible, HTML authors should avoid using such characters in filenames in order to avoid encoding. Table 4-2 shows the reserved and potentially dangerous characters for URLs.
| Character | Encoding Value |
|---|---|
| Space | %20 |
| / | %2F |
| ? | %3F |
| : | %3A |
| ; | %3B |
| & | %26 |
| @ | %40 |
| = | %3D |
| # | %23 |
| % | %25 |
| < | %3E |
| > | %3C |
| { | %7B |
| } | %7D |
| [ | %5B |
| ] | %5D |
| " | %22 |
| ` | %27 |
| ˜ | %60 |
| ^^ | %5E |
| ~ | %7E |
| \ | %5C |
|
| %7C |
| Note | Many of the characters in Table 4-2 don't have to be encoded, but encoding a character never causes problems, so when in doubt, encode it. |
Query String
Last but certainly not least, many URLs contain query strings indicated by the question mark (?). When a URL requests a program to be run rather than a file to be returned, a query string might be passed in the URL to indicate the various arguments to be given to the server-side program. Consider, for example,
http://www.democompany.com/cgi-bin/comments.exe? Name=Matt+Folely&Age=32&Sex=male
In this situation, the program comments.exe is handed a query string that has a name value set to "Matt Folely," an Age value set to "32," and a Sex value set to "male." Query strings are generally encoded as discussed in the previous section. Spaces in this case are mapped to the plus sign (+) while all other characters are in the %hex value form. The various name/value pairs are separated by ampersands (&). While it might look cryptic, query strings are relatively straightforward and their use will be discussed in Chapters 12 and 13 on forms and server-side programming, respectively.
With this brief discussion of the various components coming to a close, the next section presents a formula for creating URLs, as well as some examples.
Formula for URLs
All URLs share the same basic syntax: a protocol name, followed by a colon, followed by a protocol-specific resource description:
protocol_name:resource_description
Beyond this basic syntax, enough variation exists between protocol specifics to warrant a more in-depth discussion with examples.
HTTP
A minimal HTTP URL simply gives a server name. It provides no directory or file information.
-
Formula http:// server / (with or without trailing /)
-
Example http://www.democompany.com/
A minimal HTTP URL implicitly requests the home directory of a Web site. Even when a trailing slash isn't used, it is assumed and added either by the user agent or the Web server so that an address such as http://www.democompany.com becomes http://www .democompany.com/. By default, requesting a directory often results in the server returning a default file from the directory, termed the index file . Usually, index files are named index.htm or default.htm (or index.html and default.html, respectively), depending on the server software being used. This is only a convention; Web administrators are free to name default index files whatever they like. Interestingly, many people put special importance on the minimal HTTP URL form when, like all other file-retrieval URLs, this form simply specifies a particular directory or default index file to return, although this isn't always explicitly written out.
| Note | Many sites now configure their domain name service and systems so that the use of www is optional. For example, http://pint.com/ is the same as http://www.pint.com. Although browsers often assist users trying to interpret short hand notation, HTML document authors should be careful to not assume such forms are valid. For example, in some browsers, typing democompany by itself might resolve to http://www.democompany.com. This is a browser usability improvement and can't be used as a URL in an HTML document. Because of misunderstandings with URLs, site managers are encouraged to support as many variable forms as possible so that the site works regardless of browser improvements or slight mistakes in linking. |
Let's make the HTTP URL example slightly more complex. The following is a formula to retrieve a specific HTML file that is assumed to exist in the default directory for the server:
-
Formula http:// server / file
-
Example http://www.democompany.com/hello.html
An alternate, incremental extension adds directory information without specifying a file. Although the final slash should be provided, servers imply its existence if it is omitted, and look for a "home" document in the given directory. In practice, the final slash is optional, but recommended:
-
Formula http:// server / directory /
-
Example http://www.democompany.com/products/
An HTTP URL can specify both a directory and a file:
-
Formula http:// server / directory / file
-
Example http://www.democompany.com/products/greeting.html
On some systems, special shorthand conventions might be available for directory use. For example, a UNIX-based Web server might support many directories, each owned by a specific user. Rather than spelling out the full path to a user's root directory, the user directory can be abbreviated by using the tilde character (~), followed by the user's account, followed by a slash. Any directory or file information that follows this point will be relative to the user's root directory:
-
Formula http:// server /~ user /
-
Example http://www.bigisp.com/~jsmith/
In the previous example, ~jsmith might actually resolve to a path like /users/j/jsmith. This mapping of a tilde character to a user's home directory is a convention from the UNIX operating system and is often used on Web servers, although other Web servers on different operating systems might provide similar shortcut support.
A URL can refer to a named location inside an HTML document, which is called a marker , or named link . How markers are created is discussed later in this chapter. For now, to refer to a document marker, follow the target document's filename with the pound character, ( # ), dubbed a fragment identifier, and then with the marker's name:
-
Formula http://server/directory/file#marker
-
Example http://www.democompany.com/profile.html#introduction
In addition to referring to HTML documents, an HTTP URL can request any type of file. For example, http://www.democompany.com/images/logo.gif would retrieve from a server a GIF image rather than an HTML file. Authors should be aware that the flexibility of Web servers and URLs often is overlooked due to the common belief that a Web-based document must be in the HTML format for it to be linked to.
To the contrary, a URL can reference any type of file and may even execute a server program. These server-side programs are often termed Common Gateway Interface (CGI) programs, referring to the interface standard that describes how to pass data in and out of a program. CGI and similar server-side programming facilities are discussed in Chapter 12. Quite often, server-side programs are used to access databases and then generate HTML documents in response to user-entered queries. Parameters for such programs can be directly included in a URL by appending a question mark, followed by the actual parameter string. Because the user might type special characters in a query, characters that normally are not allowed within a URL are encoded. Remember that the formula for special-character encoding is a percent sign, followed by two hex numbers representing the character's ASCII value. For example, a space can be represented by %20 .
-
Formula http:// server/directory/file?parameters
-
Example http://www.democompany.com/products/search.cgi?cost=400.00&name=Super%20Part
Forming complex URLs with encoding and query strings looks very difficult. In reality, it rarely is done manually. Typically, the browser generates such a string on the fly based on data provided through a form. A more detailed discussion of HTML interaction with programming facilities appears in Chapters 12 “15.
Finally, any HTTP request can be directed to a port other than the default port value of 80 by following the server identification with a colon and the intended port number:
-
Formula http://server:port/directory/file
-
Example http://www.democompany.com:8080/products/ greetings .html
In the preceding example, the URL references a Web server running on port 8080. Although any unreserved port number is valid, the use of nonstandard port numbers on servers is not good practice. To access the address in the example, a user would need to include the port number in the URL. If it is omitted, accessing the server will be limited to the default port 80.
One type of HTTP exists that is, in a sense, a different protocol: secured Web transactions using the Secure Sockets Layer (SSL). In this case, the protocol is referenced as https , and the port value is assumed to be 443. An example formula for Secure HTTP is shown here; other than the cosmetic difference of the s and the different port value, it is identical to other HTTP URLs:
-
Formula https://server: port / directory / file
-
Example https://www.wellsfargo.com
An HTTP URL for a Web page probably is the most common URL, but users might find files or similar types of URLs growing in popularity due to the rise of intranets .
file
The file protocol specifies a file residing somewhere on a computer or locally accessible computer network. It does not specify an access protocol and has limited value except for one important case: it enables a browser to access files residing on a user's local computer, an important capability for Web page development. In this usage, the server name is omitted or replaced by the keyword localhost , which is followed by the local directory and file specification:
-
Formula file://drive or network path/ directory / file
-
Example file:///dev/web/testpage.html
In some environments, the actual drive name and path to the file are specified. On a Macintosh, a URL might be the following:
file:///Macintosh %20HD/Desktop%20Folder/Bookmarks.html
A file URL such as the following might exist to access a file on the C drive of a PC on the local network, pc1:
file://\pc1\C\Netlog.txt
Depending on browser complexity, complex file URLs might not be required, as with Internet Explorer, in which the operating system is tightly coupled with the user agent.
Interestingly, in the case of intranets, many drives might be mapped or file systems mounted so that no server is required to deliver files. In this "Web- serverless " environment, accessing network drives with a file URL might be possible. This demonstrates how simple a Web server is. In fact, to some people, a Web server is merely a very inefficient, though open, file server. This realization regarding file transfer leads logically to the idea of the FTP URL, discussed next.
FTP
The File Transfer Protocol, which predates the browser-oriented HTTP protocol, transfers files to and from a server. It generally is geared toward transferring files that are to be locally stored rather than immediately viewed . Today, because of its efficiency, FTP most commonly is used to download large files such as complete applications. These URLs share with HTTP the formula for indicating a server, port, directory, and file:
-
Formula ftp://server:port/directory/file
-
Example ftp://ftp.democompany.com:9978/info/somefile.exe
A minimal FTP URL specifies only a server: ftp://ftp.democompany.com. Generally, however, FTP URLs are used to access by name and directory a particular file in an archive, as shown in this formula:
-
Formula ftp:// server/directory path/file
-
Example ftp://ftp.democompany.com/info/somefile.exe
FTP is an authenticated protocol, which means that every valid FTP request requires a defined user account on the server downloading the files. In practice, many FTP resources are intended for general access, and defining a unique account for every potential user is impractical . Therefore, an FTP convention known as anonymous FTP handles this common situation. The username "anonymous" or "ftp" allows general access to any public FTP resource supported by a server. As in the previous example, the anonymous user account is implicit in any FTP URL that does not explicitly provide account information.
An FTP URL can specify the name and password for a user account. If included, they precede the server declaration, according to the following formula:
-
Formula ftp:// user:password@server/directory/file
-
Example ftp://jsmith:harmony@ftp.democompany.com/products/list
This formula shows the password embedded within the URL. Including an account password in a public document (such as an HTML file) is a dangerous proposition because it is transmitted in plain text and viewable both in the HTML source and browser address bar. Only public passwords should be embedded in any URL for an authenticated service. Furthermore, if you omit the password, the user agent typically prompts you to enter one if a password is required. Thus, it is more appropriate to provide a link to the service and then require the user to enter a name and password, or just provide the user ID and have the user agent prompt for a password, as happens in this example:
-
Formula ftp:// user@server/directory/file
-
Example ftp://jsmith@ftp.democompany.com/products/sales
The FTP protocol assumes that a downloaded file contains binary information. You can override this default assumption by appending a type code to an FTP URL. The following are three common values for type codes:
-
An a code indicates that the file is an ASCII text file.
-
The i code, which also is the default, indicates that the file is an image/binary file.
-
A d code causes the URL to return a directory listing of the specified path instead of a file.
An example formula is presented here for completeness:
-
Formula ftp:// server / directory / file; type= code
-
Example ftp://ftp.democompany.com/products;type=d
In reality, the type codes rarely are encountered because the binary transfer format generally does not harm text files, and the user agent usually is smart enough to handle FTP URLs without type codes. Like many other URLs, the port accessed can be changed to something other than the default port of 21, but this is not recommended.
mailto
Typically, the mailto protocol does not locate and retrieve an Internet resource. Instead, if possible, it triggers an application for editing and sending a mail message to a particular user address:
-
Formula mailto: user @ server
-
Example mailto:president@whitehouse.gov
This rather simple formula shows standard Internet mail addressing; other, more complex addresses might be just as valid. The use of mailto URLs is very popular in Web sites, to provide a basic feedback mechanism. Note that if the user's browser hasn't been set up properly to send e-mail, this type of URL might produce error messages when used in a link, prompting the user to set up mailing preferences. Because of this problem, page authors are warned to not rely solely on mailto-based URL links to collect user feedback.
| Note | Some browsers have introduced proprietary extensions to the mailto protocol, such as the ? subject extension. While useful to set subject values and so on in a mail message, they should be used with caution as these extended features are not standardized. |
telnet
The telnet protocol allows a user to open an interactive terminal session on a remote host computer. A minimal telnet URL, shown next, simply gives the remote system's name. After a connection is made, the system prompts for an account name and password.
-
Formula telnet:// server
-
Example telnet://host.democompany.com
As an authenticated protocol, telnet generally requires a defined user account on the remote system. When this is unspecified, the user agent or helper application handling telnet prompts for such information. Like FTP, a telnet URL also can contain an account name and password as parameters. But, as with FTP URLs, be careful about including passwords in public access documents such as HTML files on the Web. Because of the risk of password interception, the password is optional in the formula:
-
Formula telnet:// user : password @ server
-
Example telnet://jsmith:harmony@host.democompany.com
-
Example telnet://jsmith@host.democompany.com
Finally, any telnet URL can direct a request to a specific port by appending the port address to the server name:
-
Formula telnet:// server : port
-
Example telnet://host.democompany.com:94
Some telnet information sources can be configured to run on a particular port other than port 23, the standard telnet port. Consequently, use of the port within a telnet URL is more common than with other URLs.
Other Protocols
A wide variety of other protocols can be used including Gopher, news, NNTP, and so on. Modern browsers may support many of these URL forms. However, some protocols, such as the wais protocol, have little more than historical value. Little evidence suggests that people actually use such older protocols much on the Web, despite their presence in books that are only a few years old. Other unusual URL forms include operating system- biased protocols, such as finger, and esoteric protocols for things like VEMMI video text services. New protocols are being added all the time. In fact, dozens of proposed or even implemented protocols exist that can be referenced with some form of nonstandard URL. If you are interested in other URL forms, visit http://www.w3.org/pub/WWW/Addressing/schemes or http://www.ics.uci.edu/pub/ietf/uri/ for more information.
Relative URLs
Up to this point, the discussion has focused on a specific form of URL, typically termed an absolute URL. Absolute URLs completely spell out the protocol, host, directory, and filename. Providing such detail can be tedious and unnecessary, which is where a shortened form of URL, termed a relative URL , comes in to use. With relative URLs, the various parts of the address ”the site, directory, and protocol ”can be inferred by the URL of the current document, or through the < base > tag. The best way to illustrate the idea of relative URLs is by example.
If a Web site has an address of www.democompany.com, a user can access the home page with a URL such as http://www.democompany.com/. A link to this page from an outside system also would contain the address http://www.democompany.com/. Once at the site, however, there is no reason to continue spelling out the full address of the site. A fully qualified link from the home page to a staff page in the root directory called staff.html would be http://www.democompany.com/staff.html. The protocol, address, and directory name can be inferred, so all that is needed is the address staff.html. This relative scheme works because http://www.democompany.com/ is inferred as the base of all future links that omit protocol and domain, thus allowing for the shorthand relative notation. The relative notation can be used with filenames and directories, as shown by the examples in Table 4-3.
| Current Page Address | Destination Address | Relative URL |
|---|---|---|
| http://www.democompany.com/index.html | http://www.democompany.com/staff.html | staff.html |
| http://www.democompany.com/index.html | http://www.democompany.com/products/gadget1.html | products/gadget1.html |
| http://www.democompany.com/products/jetpackes/modelT.html | http://www.democompany.com/index.html | /index.html |
| http://www.democompany.com/products/gadget1.html | http://www.democompany.com/index.html | ../index.html |
When relative URLs are used within a Web site, the site becomes transportable. By not spelling out the server name in every link, you can develop a Web site on one server and move it to another. If you use absolute URLs, however, all links have to be changed if a server changes names or the files are moved to another site.
Of course, using relative URLs also has a potential downside: They can become confusing in a large site, particularly if centralized directories are used for things such as images. Imagine having URLs such as ../../../images/logo.gif in files deep in a site structure. Some users might be tempted to simply copy files to avoid such problems, but then updating and caching issues arise. One solution is to use a < base> tag. Another solution is to use symbolic links on the Web server to reference one copy of the file from multiple locations. However, because HTML is the subject here, the focus is the former solution, using the base element.
The base element defines the base for all relative URLs within a document. Setting the href attribute of this element to a fully qualified URL enables all other relative references to use the defined base. For example, if <base> is set as < base href="http://www.democompany.com/"> , then all the anchors in the document that aren't fully qualified will prefix http://www.democompany.com/ to the destination URL. Because <base> is an empty element, it would have to be written as < base href="http://www.democompany.com/" /> to be XHTML- compliant.
The <base> tag can occur only once in an HTML document ”within its head ”so creating sections of a document with different base URL values is impossible. Such a feature might someday be added to a sectioning element, but until then, HTML authors have to deal with the fact that shorthand notation is useful only in some places. See Appendix A for more information on the <base> tag.
| < Day Day Up > |
EAN: 2147483647
Pages: 252