Simulation of a Queuing System
| To demonstrate the simulation of a queuing system, we will use an example. Burlingham Mills produces denim, and one of the main steps in the production process is dyeing the cotton yarn that is subsequently woven into denim cloth. The yarn is dyed in a large concrete vat like a narrow swimming pool. The yarn is strung over a series of rollers so that it passes through the vat, up over a set of rollers, back down into the vat, back up and over another set of rollers, and so on. Yarn is dyed in batches that arrive at the dyeing vat in 1-, 2-, 3-, or 4-day intervals, according to the probability distribution shown in Table 14.5. Once a batch of yarn arrives at the dyeing facility, it takes either 0.5, 1.0, or 2.0 days to complete the dyeing process, according to the probability distribution shown in Table 14.6. Table 14.5. Distribution of arrival intervals
Table 14.6. Distribution of service times
Table 14.5 defines the interarrival time, or how often batches arrive at the dyeing facility. For example, there is a .20 probability of a batch arriving 1 day after the previous batch. Table 14.6 defines the service time for a batch. Notice that cumulative probabilities have been included in Tables 14.5 and 14.6. The cumulative probability provides a means for determining the ranges of random numbers associated with each probability, as we demonstrated with our Excel example in the previous section. For example, in Table 14.5 the first random number range for r 1 is from 1 to 20, which corresponds to the cumulative probability of .20. The second range of random numbers is from 21 to 60, which corresponds to a cumulative probability of .60. Although the cumulative probability goes up to 1.00, Table 14.3 contains only random number values from 0 to 99. Thus, the number 0 is used in place of 100 in the last random number range of each table. Developing the cumulative probability distribution helps to determine random number ranges . Table 14.7 illustrates the simulation of 10 batch arrivals at the dyeing vat. The manual simulation process illustrated in Table 14.7 can be interpreted as follows :
Table 14.7. Simulation at the Burlingham Mills Dyeing Facility
This process of selecting random numbers and generating arrival intervals and service times continues until 10 batch arrivals have been simulated, as shown in Table 14.7. Once the simulation is complete, we can compute operating characteristics from the simulation results, as follows: However, as in our previous example, these results must be viewed with skepticism. Ten trials of the system do not ensure steady-state results. In general, we can expect a considerable difference between the true average values and the values estimated from only 10 random draws. One reason is that we cannot be sure that the random numbers we selected in this example replicated the actual probability distributions because we used so few random numbers. The stream of random numbers that was used might have had a preponderance of high or low values, thus biasing the final model results. For example, of nine arrivals, five had interarrival times of 1 day. This corresponds to a probability of .55 (i.e., 5/9); however, the actual probability of an arrival interval of 1 day is .20 (from Table 14.5). This excessive number of short interarrival times (caused by the sequence of random numbers) has probably artificially inflated the operating statistics of the system. As the number of random trials is increased, the probabilities in the simulation will more closely conform to the actual probability distributions. That is, if we simulated the queuing system for 1,000 arrivals, we could more reasonably expect that 20% of the arrivals would have an interarrival time of 1 day. An additional factor that can affect simulation results is the starting conditions. If we start our queuing system with no batches in the system, we must simulate a length of time before the system replicates normal operating conditions. In this example, it is logical to start simulating at the time the vat starts operating in the morning, especially if we simulate an entire working day. Some queuing systems, however, start with items already in the system. For example, the dyeing facility might logically start each day with partially completed batches from the previous day. In this case, it is necessary to begin the simulation with batches already in the system. A factor that can affect simulation results is the starting conditions . By adding a second random variable to a simulation model, such as the one just shown, we increase the complexity and therefore the manual operations. To simulate the example in Table 14.7 manually for 1,000 trials would require several hours. It would be far preferable to perform this type of simulation on a computer. A number of mathematical computations would be required to determine the various column values of Table 14.7, as we will demonstrate in the Excel spreadsheet simulation of this example in the next section. Computer Simulation of the Queuing Example with ExcelThe simulation of the dyeing process at Burlingham Mills shown in Table 14.7 can also be done in Excel. Exhibit 14.6 shows the spreadsheet simulation model for this example. Exhibit 14.6.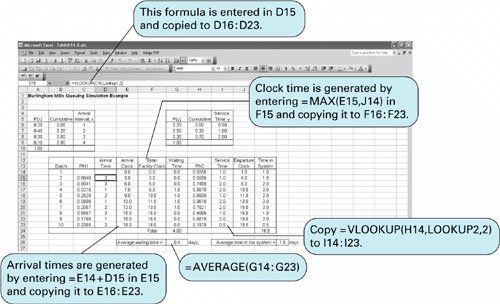 The stream of random numbers in column C is generated by the formula = RAND (), used in the ComputerWorld examples in Exhibits 14.2 through 14.5. (Notice that for this computer simulation, we have changed our random numbers from whole numbers to numbers between 0.0 and 1.0.) The arrival times are generated from the cumulative probability distribution of arrival intervals in cells B6:C9 . This array of cells is renamed "Lookup1" because there are two probability distributions in the model. The formula = VLOOKUP(C15, Lookup1,2 ) is entered in cell D15 and copied to cells D16:D23 to generate the arrival times in column D. The arrival clock times are computed by entering the formula = E14+D15 in cell E15 and copying it to cells E16:E23 .
A batch of yarn can enter the dyeing facility as soon as it arrives (in column E) if there is not another batch being dyed or as soon as any batches being dyed or waiting to be dyed have departed the facility (column J). This clock time is computed by entering the formula = MAX(E15, J14 ) in cell F15 and copying it to cells F16:F23 . The waiting time is computed with the formula = F14-E14 , copied in cells G14:G23 . A second set of random numbers is generated in column H by using the RAND () function. The service times are generated in column I from the cumulative probability distribution in cells H6:I8 , using the "Lookup" function again. In this case the array of cells in H6:I8 is named "Lookup2," and the service times in column I are generated by copying the formula = VLOOKUP(H14, Lookup2,2 ) in cells I14:I23 . The departure times in column J are determined by using the formula = F14+I14 copied in cells J14:J23 , and the "Time in System" values are computed by using the formula = J14-E14 , copied in cells K14:K23 . The operating statistic, average waiting time, is computed by using the formula = AVERAGE(G14:G23 ) in cell G26, and the average time in the system is computed with a similar formula in cell L26. Notice that both the average waiting time of 0.4 days and the average time in the system of 1.9 days are significantly lower than the simulation conducted in Table 14.7, as we speculated they might be. |

EAN: 2147483647
Pages: 358