Hardware Components
The following general guidelines are no substitute for your own experience with your application because of the many variables that might exist, but they can help you at the outset. For simplicity, the following sections assume that your server is basically dedicated to running SQL Server, with little else going on. (You can certainly combine SQL Server with other applications on the same machine, and you can administer SQL Server on the same machine as SQL Server Enterprise Manager. Or you can support multiple databases from one SQL Server machine.)
The Processor
SQL Server is CPU intensive , more so than you might think if you assume that it is mostly I/O constrained. Plenty of processing capacity is a good investment. Your system uses a lot of processing cycles to manage many connections, manage the data cache effectively, optimize and execute queries, check constraints, execute stored procedures, lock tables and indexes, and enforce security. Because SQL Server typically performs few floating-point operations, a processor that is fabulous with such operations but mediocre with integer operations is not the ideal choice. Before you choose a processor, you should check benchmarks such as SPECInt (integer) not SPECfp (floating-point) or any benchmark that is a combination of floating-point and integer performance. Performance on SPECInt correlates to the relative performance of SQL Server among different processor architectures, given sufficient memory and I/O capacity. The correlation is a bit loose, of course, because other factors (the size of the processor cache, the system bus efficiency, the efficiency of the optimizing compiler used to build the system when comparing processor architectures, and many other variables) also play an important role. But integer-processing performance is a key metric for SQL Server.
Figure 4-1 shows SPECInt95 ratings for various processors running Windows NT. These figures are based on the processor vendors ' data as stated in August 1998 on their Web pages. To highlight the tremendous increases in the performance of mainstream hardware, we have included figures for some older Pentium processors, even though you clearly would not go out and buy these today. Future processors will offer even better performance. In early 2000, both the Intel Merced processor and the Alpha EV68 processor are expected to ship. The Merced is expected to have a SPECInt95 rating of between 30 and 60, and the EV68 might have a rating as high as 75.
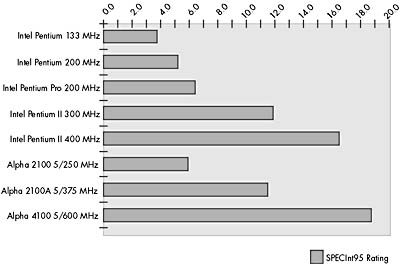
Figure 4-1. SPECInt95 benchmarks.
SQL Server is built for SMP, but if your system is dedicated to SQL Server and supports fewer than 100 simultaneous users, a single CPU system will likely meet your needs. If you are working with large data warehousing applications, you can use an SMP system effectively with a small number of users. SQL Server 7 can run complex queries in parallel, which means that the same query is processed simultaneously by multiple processors, each doing a subset of the computations . SQL Server executes queries on multiple processors only if the number of processors is greater than the number of active connections. If you are uncertain about your needs or you expect them to grow, get a single-processor system that can be upgraded to a dual (or even quad) system.
Since Moore's Law which states that processing power doubles every 18 months has held true, you should buy the fastest single-processor system in its class. Buy tomorrow's technology, not yesterday 's. With many other applications, the extra processing power doesn't make much difference, but SQL Server is CPU intensive. The 62 percent difference in SPECInt95 performance between a 133 MHz Pentium and a 200 MHz Pentium Pro can yield a similar difference in SQL Server performance.
TIP
Remember that the processor's cache affects its performance. A big L2 (level 2, or secondary) cache is a good investment. You might see a difference of 20 percent or better simply by using a 512-KB L2 cache instead of a 256-KB L2 cache in a given system. The cost difference is perhaps $100, so this is money well spent.
If your application is already available or you can conduct a fairly realistic system test, you can be much more exacting in evaluating your hardware needs. Using the Windows NT Performance Monitor, simply profile the CPU usage of your system during a specified period of time. (Use the Processor object and the % Processor Time counter.) Watch all processors if you're using an SMP system. If your system is consistently above 70 percent usage or can be expected to grow to that level soon, or if it frequently spikes to greater than 90 percent for 10 seconds or more, you should consider getting a faster processor or an additional processor. You can use the SPECInt95 guidelines to determine the relative additional processing power that would be available by upgrading to a different or an additional processor.
NOTE
Adding an additional processor does not double your processing power. For a system with up to four processors, adding another processor on an efficient SMP hardware platform usually yields at most an additional 80 to 90 percent of the processing power of the first CPU. Gains above 70 percent can be achieved in the four-to-eight CPU range if your system is really CPU hungry. But most systems today would be bottlenecked somewhere else before they would demand the amount of processing power that a modern four-way CPU system delivers. If your system already has plenty of CPU cycles to spare, adding a processor contributes little.
Memory
SQL Server uses memory for two broad purposes: for its own code and internal data structures and for its buffer cache. SQL Server uses only about 3.5 MB of real memory for its code and internal structures. (People are often surprised at this small number.) User connections consume about 24 KB of memory each at the time they are initiated. Memory is used for many purposes in SQL Server 7; we looked at some of them in Chapter 3 and will discuss additional details regarding memory usage in Chapter 15. By default, SQL Server 7 automatically configures the amount of memory it uses based on its needs and the needs of the operating system and other running applications.
If the SQL Server Buffer Manager can find data in the cache (memory), it can avoid physical I/Os. As discussed earlier, retrieving data from memory is tens of thousands of times faster than the mechanical operation of performing a physical I/O. (Performing physical I/O operations also consumes thousands more CPU clock cycles than simply addressing real memory.) As a rule, you should add physical memory to the system until you stop getting significant increases in cache hits or until you run out of money. You can easily monitor cache hits with Performance Monitor. (For more information, see Chapter 15.) Using the SQLServer:Buffer Manager object, watch the Buffer Cache Hit Ratio counter. If adding additional physical memory makes Buffer Cache Hit Ratio increase significantly, the memory is a good investment.
As mentioned earlier, by default SQL Server automatically adjusts its memory use to meet its needs and the needs of the rest of the system. However, an administrator can override this and configure SQL Server to use a fixed amount of memory. You should be extremely cautious if you decide to do this. Configuring memory appropriately is crucial to good performance; configuring too much or too little memory can drastically impair performance. Too little memory gives you a poor buffer cache-hit ratio. Too much memory means that the aggregate working sets of the operating system and all applications (including SQL Server) will exceed the amount of real memory, requiring memory to be paged to and from disk. You can monitor paging in Performance Monitor using statistics such as the Memory object's counter for Pages/Sec.
Fortunately, adding physical memory to systems is usually quite simple (you pop in some SIMMs) and economical. You should start conservatively and add memory based on empirical evidence as you test your application. SQL Server needs no single correct amount of memory, so it's pointless to try to establish a uniform memory configuration for all SQL Server applications that you might ever deploy.
SQL Server can run with a minimum 32-MB system (64 MB for SQL Server Enterprise edition), but as is typically the case with a minimum requirement, this is not ideal. If your budget isn't constrained, you should consider starting with at least 64 MB of RAM. (If your budget is flexible or you have reason to believe that your application will be more demanding, you might want to bump up memory to 128 MB. But it's probably best not to go higher than this initially without some evidence that your SQL Server application will use it.)
NOTE
The code sizes of both SQL Server and Windows NT system executables are larger for RISC architectures than for Intel architectures. SQL Server data structures are essentially the same size for both Intel and RISC, but the starting "tax" is higher for RISC. If you are running on a RISC platform, we recommend starting with an additional 24 MB of memory.
When you buy your initial system, give some consideration to the configuration of the memory SIMMs, not only to the total number of megabytes, so that you can later expand in the most effective way. If you're not careful, you can get a memory configuration that makes it difficult to upgrade. For example, suppose that your machine allows four memory banks for SIMMs and you want 64 MB of memory that you might upgrade in the future. If your initial configuration of 64 MB was done with four 16-MB SIMMs, you're in trouble. If you want to upgrade, you have to remove the 16-MB SIMMs and buy all new memory. But if you configure your 64 MB as two 32-MB SIMMs, you can add another one or two such SIMMs to get to 96 MB or 128 MB without replacing any of the initial memory. Starting with one 64-MB SIMM gives you even more flexibility in upgrading.
When deciding on the initial amount of memory, you should also consider whether your system will be more query intensive or more transaction intensive. Although more memory can help either way, it typically benefits query intensive systems most, especially if part of the data is "hot" and often queried. That data tends to remain cached, and more memory allows more of the data to be accessed from the cache instead of necessitating physical I/Os. If you have a query-intensive system, you might want to start with more memory than 64 MB. In contrast, a transaction-intensive system might get relatively few cache hits, especially if the transactions are randomly dispersed or don't rely much on preexisting data. In such a system, the amount of memory needed might be low, and adding a faster I/O subsystem might make more sense than adding more memory.
Disk Drives , Controllers, and Disk Arrays
Obviously, you need to acquire enough disk space to store all your data, plus more for working space and system files. But you should not simply buy storage capacity you should buy I/O throughput and fault tolerance as well. A single 8-GB drive stores as much as eight 1-GB drives, but its maximum I/O throughput is likely to be only about one- eighth as much as the combined power of eight smaller drives ( assuming that the drives have the same speed). Even relatively small SQL Server installations should have at least two or three physical disk drives rather than a single large drive. Microsoft has benchmarked systems that can do, say, 1000 tps (in a Debit-Credit scenario) using more than 40 physical disk drives and multiple controllers to achieve the I/O rates necessary to sustain that level of throughput.
If you know your transaction level or can perform a system test to determine it, you might be able to produce a good estimate of the number of I/Os per second you need to support during peak use. Then you should procure a combination of drives and controllers that can deliver that number.
Typically, you should buy a system with SCSI drives, not IDE or EIDE drives. An IDE channel supports only two devices. An EIDE setup consists of two IDE channels and can support four (2 —2) devices. But more important, an IDE channel can work with only a single device at a time and even relatively small SQL Server installations usually have at least 2 or 3 disk drives. If multiple disks are connected on an IDE channel, only one disk at a time can do I/O. (This is especially problematic if the channel also supports a slow device such as a CD-ROM drive. With an average access time of 200 milliseconds (ms), your disk I/O would be held up for 0.2 seconds, on average, while the CD is accessed. A hard drive today usually has access times of 6 to 8 ms, which is about 30 times faster.)
SCSI is also a lot smarter than IDE or EIDE. A SCSI controller hands off commands to a SCSI drive and then logically disconnects and issues commands to other drives. If multiple commands are outstanding, the SCSI controller queues the commands inside the associated device (if the device supports command queuing) so that the device can start on the next request as soon as the current request finishes. When a request finishes, the device notifies the controller. A SCSI channel can support multiple fast drives and allow them to work at full speed. Slow devices such as CD-ROM drives and tape drives do not hog the SCSI channel because the controller logically disconnects. A single SCSI channel can support many drives, but from a practical standpoint, we recommend about a 5:1 ratio if you need to push the drives close to capacity. (That is, you should add an additional channel for every 5 drives or so.) If you are not pushing the drives to capacity, you might be able to use as many as 8 to 10 drives per channel even more with some high-end controllers or random I/O patterns.
In TPC benchmarks (which are I/O intensive, and in which the I/O is deliberately random), Microsoft generally follows a 6:1 ratio of drives per SCSI channel. (Since TPCC measures both performance and cost, Microsoft must balance the cost and benefits, just as they would for a real application.) Most real applications don't have such perfectly random I/O characteristics, however. When the I/O is perfectly random, a significant amount of the I/O time is spent with the disk drives seeking (that is, with the disk arm positioning itself to the right spot) rather than transferring data, which consumes the SCSI channel. Seeking is taxing only on the drive itself, not on the SCSI channel, so the ratio of drives per channel can be higher in the benchmark.
Note that we're speaking in terms of channels, not controllers. Most controllers have a single SCSI channel, so you can think of the two terms as synonymous. Some high-end cards (typically RAID controllers, not just standard SCSI) are dual-channel cards. For example, the Compaq Smart-2DH Array controller is a dual-channel controller that can efficiently push 14 drives (7 per channel).
Some HistoryThe original acronym RAID apparently stood for "redundant array of inexpensive disks," as evidenced in the paper presented to the 1988 ACM SIGMOD by Patterson, Gibson, and Katz called "A Case for Redundant Arrays of Inexpensive Disks (RAID)." However, the current RAID book, published by the RAID Advisory Board, uses independent, which seems like a better description because the key function of RAID is to make separate, physically independent drives function logically as one drive.
RAID Solutions
Simply put, RAID solutions are usually the best choice for SQL Server for these reasons:
- RAID makes multiple physical disk drives appear logically as one drive.
- Different levels of RAID provide different performance and redundancy features.
- RAID provides different ways of distributing physical data across multiple disk drives.
- RAID can be provided as a hardware solution (with a special RAID disk controller card), but it does not necessarily imply special hardware. RAID can also be implemented via software.
- Windows NT Server provides RAID levels 0 (striping), 1 (mirroring), and 5 (striping with parity) for implementation with SQL Server.
Some RAID levels provide increased I/O bandwidth (striping), and others provide fault-tolerant storage (mirroring or parity). With a hardware RAID controller, you can employ a combination of striping and mirroring, often referred to as RAID-1&0 (and sometimes as RAID-10 or RAID-1+0). RAID solutions vary in how much additional disk space is required to protect the data and how long it takes to recover from a system outage . The type and level of RAID you choose depends on your I/O throughput and fault tolerance needs.
RAID-0
RAID-0, or striping, offers pure performance but no fault tolerance. I/O is done in " stripes " and is distributed among all drives in the array. Instead of the I/O capacity of one drive, you get the benefit of all the drives. A table's hot spots are dissipated, and the data transfer rates go up cumulatively with the number of drives in the array. So although an 18-GB disk might do 80 to 90 random I/Os per second, an array of eight 2.1-GB disks striped with Windows NT Server's RAID-0 might in aggregate perform more than 400 I/Os per second, which is a lot.
Choose an Appropriate Backup StrategyAlthough you can use RAID for fault tolerance, it is no substitute for regular backups. RAID solutions can protect against a pure disk-drive failure, such as a head crash, but that's far from the only case in which you need a backup. If the controller fails, garbage data might appear on both your primary and redundant disks. Even more likely, an administrator could accidentally clobber a table; a disaster at the site, such as a fire, flood, or earthquake, could occur; or a simple software failure (in a device driver, the operating system, or SQL Server) could threaten your data. RAID does not protect your data against any of those problems, but backups do.
NOTE
You could argue that RAID-0 shouldn't be considered RAID at all because there is no redundancy. That might be why it's classified as level 0.
Windows NT Server provides RAID-0; a hardware RAID controller can also provide it. RAID-0 requires little processing overhead, so a hardware implementation of RAID-0 offers at best a marginal performance advantage over the built-in Windows NT capability. One possible advantage is that RAID-0 in hardware often lets you adjust the stripe size, while the size is fixed at 64 KB in Windows NT and cannot be changed.
RAID-1
RAID-1, or mirroring, is conceptually simple: a mirror copy exists for every disk drive. Writes are made to the primary disk drive and to the mirrored copy. Because writes can be made concurrently, the elapsed time for a write is usually not much greater than it would be for a single, unmirrored device. The write I/O performance to a given logical drive is only as fast as a single physical drive is able to go.
Hardware-Based vs. Software-Based RAIDIf price and performance are your only criteria, you might find that software-based RAID is perfectly adequate. If you have a fixed budget, the money you save on hardware RAID controllers might be better spent elsewhere, such as on a faster processor, more disks, more memory, or an uninterruptible power supply.
While in pure performance terms it might not be better to spend extra on low-end hardware RAID (as long as you have sufficient CPU capacity in the server), mid-level to high-end RAID offers many other benefits, including hot swappability of drives and intelligent controllers that are well worth the extra money especially for systems that need to run 24 hours a day, 7 days a week.
You might also combine hardware-based and software-based RAID to great advantage. For example, if you have three hardware-based RAID units, each with 7-GB to 9-GB disks, with RAID-5 you would have 6 x 9 = 54 GB in each, and Windows NT would see three 54-GB disks. You can then use software-based RAID on Windows NT to define a RAID-0 stripe set to get a single 162-GB partition on which to create SQL Server databases.
Therefore, you can at best get I/O rates of perhaps 80 to 90 I/Os per second to a given logical RAID-1 drive, as opposed to the much higher I/O rates to a logical drive that can be achieved with RAID-0. You can, of course, use multiple RAID-1 drives. But if a single table is the hot spot in your database, even multiple RAID-1 drives will not be of much help from a performance perspective. (SQL Server 7 lets you create filegroups within a database for, among other purposes, placing a table on a specific drive or drives. But no range partitioning capability is available for data within a table, so this option doesn't really give you the control you need to eliminate hot spots.) If you need fault tolerance, RAID-1 is normally the best choice for the transaction log. Because transaction log writes are synchronous and sequential, unlike writes to the data pages, they are ideally suited to RAID-1.
Read performance with RAID-1 can be significantly increased because a read can be obtained from either the primary device or the mirror device. (A single read is not performed faster, but multiple reads are faster in aggregate because they can be performed simultaneously.) If one of the drives fails, the other continues and SQL Server uses the surviving drive. Until the failed drive is replaced , fault tolerance is not available unless multiple mirror copies were used.
NOTE
The Windows NT RAID software does not allow you to keep multiple mirror copies; it allows only one copy. But some RAID hardware controllers offer this feature. You can keep one or more mirror copies of a drive to ensure that even if a drive fails, a mirror still exists. If a crucial system is difficult to access in a timely way to replace a failed drive, this option might make sense.
Windows NT Server provides RAID-1, and some hardware RAID controllers also provide it. RAID-1 requires little processing overhead, so a hardware implementation of RAID-1 offers at best a marginal performance advantage over the built-in Windows NT capability (although the hardware solution might provide the ability to mirror more than one copy of the drive).
RAID-5
RAID-5, or striping with parity, is a common choice for SQL Server use. RAID-5 not only logically combines multiple disks to act like one disk, but it also records extra parity information on every drive in the array (thereby requiring only one extra drive). If any drive fails, the others can reconstruct the data and continue without any data loss or immediate down time. By doing an Exclusive OR (XOR) between the surviving drives and the parity information, the bit patterns for a failed drive can be derived on the fly.
RAID-5 is less costly to implement than mirroring all the drives, since only one additional drive is needed rather than the double drives that mirroring requires. Although RAID-5 is commonly used, it is often not the best choice for SQL Server because it imposes a significant I/O hit on write performance because both the data and the parity information must be written. RAID-5 can turn one write into two reads and two writes to keep the parity information updated. This doesn't mean that a single write takes four or five times as long, because the operations are done in parallel. It does mean, however, that many more I/Os occur in the system, so many more drives and controllers are required to reach the I/O levels that RAID-0 can achieve. So although RAID-5 certainly is less costly than mirroring all the drives, the performance overhead for writes is significant. Read performance, on the other hand, is excellent essentially equivalent to that of RAID-0.
RAID-5 makes sense, then, for the data portion of a database that needs fault tolerance, that is heavily read, and that does not demand high write performance. Typically, you should not place the transaction log on a RAID-5 device unless the system has a low rate of changes to the data. (As mentioned before, RAID-1 is a better choice for the transaction log because of the sequential nature of I/O to the log.)
RAID-5 requires more overhead for writes than RAID-0 or RAID-1, so the incremental advantage provided by a hardware RAID-5 solution over the Windows NT software solution can be somewhat higher because more work must be offloaded to the hardware. However, such a difference would be noticeable only if the system were nearly at I/O capacity. If this is the case in your system, you probably shouldn't use RAID-5 in the first place because of the write performance penalty. You're probably better served by the combination of RAID-0 and RAID-1, known as RAID-1&0.
RAID-1&0
RAID-1&0, or mirroring and striping, is the ultimate choice for performance and recoverability. (This capability is sometimes also referred to as RAID-1+0 or RAID-10.) A set of disks is striped to provide the performance advantages of RAID-0, and the stripe is mirrored to provide the fault-tolerance features and increased read performance of RAID-1. Performance for both writes and reads is excellent.
The most serious drawback to RAID-1&0 is cost. Like RAID-1, it demands duplicate drives. In addition, the built-in RAID software of Windows NT does not provide this solution, so RAID-1&0 requires a hardware RAID controller. Some hardware RAID controllers explicitly support RAID-1&0. But you can achieve this support using virtually any RAID controller by combining its capabilities with those of Windows NT. For example, you can set up two stripe sets of the same size and number of disks using hardware RAID. Then you can use Windows NT mirroring on the two stripe sets, which Windows NT sees as two drives of equal size. If you need high read and write performance and fault tolerance and you cannot afford an outage or decreased performance if a drive fails, RAID-1&0 is the best choice.
A separate RAID-1&0 array usually is not an appropriate choice for the transaction log. Because the write activity tends to be sequential and is synchronous, the benefits of multiple spindles are not realized. A RAID-1 mirroring of the transaction log is preferable and cheaper. With internal Debit-Credit benchmarks, Microsoft has shown that the transaction log on a simple RAID-1 device is sufficient to sustain thousands of transactions per second which is likely more than you need. Log records are packed, and a single log write can commit multiple transactions (known as group commit ). In the Debit-Credit benchmarks, 40 transactions can be packed into a log record. At a rate of 100 writes per second (writes/second), the log on a RAID-1 mirror would not become a bottleneck until around 4000 tps.
NOTE
Practically speaking, this threshold is probably even higher than 4000 tps. For pure sequential I/O, 100 writes/second is a conservative estimate. Although a typical disk drive is capable of doing 80 to 90 random I/Os per second, the rate for pure sequential I/O largely eliminating the seek time of the I/Os is probably better than 100 writes/second.
In a few cases, a physically separate RAID-1&0 array for the log might make sense for example, if your system requires high OLTP (online transaction processing write) performance but you also used replication of transactions. Besides performing sequential writes to the log, the system also does many simultaneous reads of the log for replication and might benefit from having the multiple spindles available. (In most cases, however, the log pages are in cache, so RAID-1&0 probably won't provide a significant benefit. However, if replication is in a "catch-up" mode because the distribution database is not available or for some other reason, some significant benefit might exist.)
Choosing the Best RAID Solution
Table 4-2 summarizes the characteristics of various RAID configurations commonly used with SQL Server. Obviously, innumerable configurations are possible, but this chart will help you predict the characteristics for additional configurations as well as typical ones. You should reject Option 1 for all but the smallest environments because with this option the entire system runs with one disk drive. This is not efficient even for a low-end system, unless you have little write performance and enough memory to get a high cache-hit ratio. Unless you're running SQL Server on a laptop, there's little excuse for using only one drive.
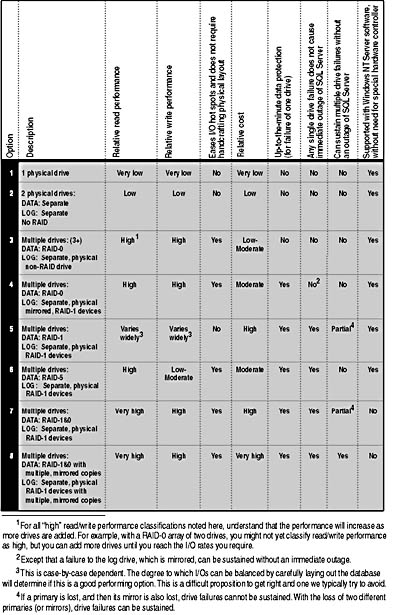
Table 4-2. Characteristics of RAID configurations used with SQL Server.
Option 2, two physical drives and no use of RAID, represents an entry-level or development system. It offers far-from-ideal performance and no fault tolerance. But it is significantly better than having only a single drive. RAID is unnecessary with just two drives, and separating your log from your data on the drives is the best you can do.
If you don't need fault tolerance and limited recovery ability is sufficient, Option 3, using RAID-0 for the data and placing the transaction log on a separate physical device (without mirroring), is an excellent configuration. It offers peak performance and low cost. One significant downside, however, is that if a drive fails, you can recover the data only to the point of your last transaction log or database backup. Because of this, Option 3 is not appropriate for many environments.
Option 4 is the entry level for environments in which it is essential that no data be lost if a drive fails. This option uses RAID-0 (striping, without parity) for the devices holding the data and RAID-1 (mirroring) for the transaction log, so data can always be recovered from the log. However, any failed drive in the RAID-0 array renders SQL Server unable to continue operation on that database until the drive is replaced. You can recover all the data from the transaction logs, but you experience an outage while you replace the drive and load your transaction logs. If a drive fails on either a transaction log or its mirrored copy, the system continues unaffected, using the surviving drive for the log. However, until the failed log drive is replaced, fault tolerance is disabled and you are back to the equivalent of Option 3. If that surviving drive also fails, you must revert to your last backup, and you'll lose changes that occurred since the last transaction log or database backup.
Option 4 offers excellent performance almost as good as Option 3. This might come as a surprise to those concerned with the mirroring of the log. RAID-1, of course, turns a single write into two. However, since the writes are done in parallel, the elapsed time for the I/O is about the same as it would be for a single drive, assuming that both the primary and mirrored drives are physically separate and are used only for log operations. If you need to protect all data but recovery time is not a major concern and an outage while you recover is acceptable (that is, if loading transaction logs or database backups is acceptable), Option 4 is ideal.
Data Placement Using FilegroupsAre you better off simply putting all your data on one big RAID-0 striped set or should you use filegroups to carefully place your data on specific disk drives? Unless you are an expert at performance tuning and really understand your data access patterns, we don't recommend using filegroups as an alternative to RAID. To use filegroups to handcraft your physical layout, you must understand and identify the hot spots in the database. And although filegroups do allow you to place tables on certain drives, doing so is tricky. It's currently not possible to partition certain ranges of a table to different disks, so hot spots often occur no matter how cleverly you designed your data distribution. If you have three or more physical disk drives, you probably should use some level of RAID, not filegroups.
If you cannot tolerate an interruption of operations because of a failed drive, you should consider some form of RAID-1 or RAID-5 for your database (as well as for the master database and tempdb , the internal workspace area), as described in Options 5 through 8.
Option 5 uses basic RAID-1, a one-for-one mirroring of drives for the data as well as the log. We don't recommend this because RAID-1 does not provide the performance characteristics of RAID-0. Recall that RAID-0 enables multiple drive spindles to operate logically as one, with additive I/O performance capabilities. Although RAID-1 can theoretically work well if you handcraft your data layout, in practice this has the same drawbacks as using filegroups instead of RAID-0. (See the sidebar above.) This high-cost option is usually not a high-performing option, at least if the database has significant hot spots. It is appropriate only for specialized purposes in which I/O patterns can be carefully balanced.
Option 6, using RAID-5 for the data and RAID-1 for the log, is appropriate if the write activity for the data is moderate at most and the update activity can be sustained. Remember that RAID-5 imposes a significant penalty on writes because it must maintain parity information so that the data of a reconstructed drive can be regenerated on the fly. Although the system does remain usable while operating with a failed drive, I/O performance is terrible: each read of the failed disk becomes four reads of the other disks, and each write becomes four reads plus a write, so throughput drops precipitously when a drive fails. With RAID-5, if you lose another drive in the system before you replace the first failed drive, you can't recover because the parity information can't continue to be maintained after the first drive is lost. Until the failed drive is replaced and regenerated, continued fault-tolerance capability is lost. RAID-5 uses fewer bytes for storage overhead than are used by mirroring all drives, but with the low price of disk drives and because disks are rarely full, the performance tradeoff is often simply not worth it. Finally, RAID-5 has more exposure to operational error than mirroring. If the person replacing the failed drive in a RAID-5 set makes a mistake and pulls a good drive instead of the failed drive, the failed drive might be unrecoverable.
If you need high read and write performance, cannot lose any data, and cannot suffer an unplanned system outage when a drive fails, Option 7 RAID-1&0 and a simple RAID-1 mirror for your log is the way to go. As mentioned earlier, RAID-1&0 offers the ultimate combination of performance and fault tolerance. Its obvious disadvantage is cost. Option 7 requires not only a doubling of disk drives but also special hardware array controllers, which command a premium price.
Options 7 and 8 differ in whether additional mirrored copies are kept. Option 7 presents the typical case, with one-for-one mirroring of every physical drive in the system. If the primary drive fails, the mirror continues seamlessly. If the mirror fails, the primary drive continues, of course. Other drives in a different primary-mirror pair might also conceivably fail and the system can still continue. However, if one drive in a pair fails, the system cannot continue if its mirror also fails. (This is really bad luck, but it happens.) Option 7, using the combined capabilities of striping and mirroring (RAID-1&0), is probably a better choice for many sites that currently use RAID-5. The performance and fault-tolerance capabilities are significantly better, and today's low-priced hardware does not make the cost prohibitive.
If you need the utmost in fault tolerance to drive failures and your application is extremely mission critical, you can consider more than a single mirrored copy of the data and log. Option 8 is overkill for most environments, but today's cost of hard drives doesn't necessarily make this option prohibitive. If you have a server in a remote offsite location and it's difficult to get a technician to the site in a timely manner, building in expensive fault-tolerance capabilities might make sense.
The Bottom Line: Buy the Right System
By now, you should know there is no one correct answer to the RAID-level question. The appropriate decision depends on your performance characteristics and fault tolerance needs. A complete discussion of RAID and storage systems is beyond the scope of this book. But the most important point is that you shouldn't simply buy storage space you should buy the system that gives you the appropriate level of redundancy and fault tolerance for your data.
SEE ALSO
You'll find a good general discussion of RAID in the SQL Server Books Online documentation (in the volume entitled "Optimizing Database Performance"). The documentation is runnable from the SQL Server evaluation CD included with this book. For a detailed, authoritative discussion, consult the RAID book produced by the RAID Advisory Board. (For more information about the RAID Advisory Board, see its home page at http://www.raid-advisory.com.)
Hardware or Software RAID?
After choosing a RAID level, you must decide whether to use the RAID capabilities of your operating system or those of a hardware controller. If you decide to use RAID-1&0, the choice is simple. Windows NT Server RAID does not currently offer the ability to keep more than one mirror copy of a drive, so you must use hardware array controllers. In addition, Windows 95 and Windows 98 do not support software-based RAID at all, and Windows NT Workstation provides only RAID-0 support. As for solutions using RAID-0 and RAID-1, there might not be much performance advantage of a hardware array controller over the capabilities of Windows NT Server. If price and performance are your main criteria, you can use standard fast-wide SCSI controllers and use the money you save to buy more drives or more memory. Several of the formal TPC benchmarks submitted using SQL Server used only the Windows NT versions of RAID-0 and RAID-1 solutions (Option 4) and standard SCSI controllers and drives, with no special hardware RAID support. Hardware RAID solutions provide the largest relative performance difference over the equivalent Windows NT software solution if you use RAID-5, but even in this case, the difference is usually marginal at best. Each hardware RAID controller can cost thousands of dollars, and a big system still needs multiple controllers. Using hardware controllers makes the most sense when you need the additional capabilities they provide, such as hot swappability, discussed in the following section.
More About Drives and Controllers
No matter what RAID level you use, you should replace a failed drive as soon as possible. For this reason, you should consider a system that offers hot swappable drives . These drives let you quickly replace the faulty drive without shutting down the system. If the drive is part of a RAID-1 or RAID-5 set, SQL Server can continue to run without error or interruption when the drive fails and even when it is physically replaced. If you use the Windows NT version of RAID-1 or RAID-5, SQL Server must be shut down only briefly to regenerate the drive because that process requires an exclusive lock on the disk drive by the operating system. When you restart SQL Server, the server computer won't even need to be rebooted. (Some hardware RAID solutions might also be able to regenerate or remirror the drive "below" the level of the operating system and hence not require SQL Server to be shut down.) Some systems also offer hot standby drives, which are simply extra drives that are already installed, waiting to take over. Either of these approaches can get you back in business quickly.
Your disk controller must guarantee that any write operation reported to the operating system as successful will actually be completed. Write-back caching controllers that "lie" (that report a write as completed but do not guarantee to actually perform the write) can result in corrupt databases and must never be used. In a write-back cache scheme, performance is increased because the bits are simply written to the cache (memory) and the I/O completion is immediately acknowledged . The controller writes the bits to the actual media a moment later. This introduces a timing window that makes the system vulnerable unless the controller designer has protected the cache (with a battery backup and so on) and has provided correct recovery logic.
Let's say, for example, that a power failure occurs immediately after the controller reports that a write operation has completed but before the cache is actually written to disk. With write-ahead logging, SQL Server assumes that any change is physically written to its transaction log before acknowledging the commit to the client. If the controller has just cached the write and then fails and never completes it, the system's integrity is broken. If a controller provides write-back caching as a feature, it must also guarantee that the writes will be completed and that they will be properly sequenced if they are reported to the operating system as successful. To be reliable, the caching controller also must guarantee that once it reports that an I/O has completed, the I/O will actually be carried out, no matter what. For example, a good solution is the Compaq SMART-2DH Array Controller, which uses write-back caching. It employs a built-in battery backup and has solutions that guarantee that any write reported as completed will in fact be completed. If the system fails before a write operation has been completed, the operation is maintained in the controller's memory and is performed immediately after the system restarts, before any other I/O operations occur.
If a controller cannot guarantee that the write will ultimately be completed, you should disable the write-back caching feature of the controller or use a different controller. Disabling write-back caching in an I/O-intensive environment (more than 250 I/Os per second) might result in a SQL Server performance penalty of less than 5 percent. (After all, those writes must be performed eventually. The caching reduces the latency, but ultimately just as much I/O must be carried out.) In a less I/O-intensive test, the effect would likely be negligible. Realistically, the amount of the penalty doesn't matter much if the write isn't guaranteed to complete. Write-back caching must be disabled or you eventually get corrupt data.
This point warrants repeating: to be reliable, the caching controller must assure that no matter what, once an I/O is reported as complete, the I/O will be carried out. The caching controller must intercept the IOCHCK (I/O Channel Check) and RESET bus signal and not reset the controller logic, discarding any cached writes. If a motherboard glitch causes an abrupt system halt (such as a single-bit parity error), the controller must preserve the cached data and must know how to flush it upon startup. Also, an uninterruptible power supply (UPS) can fail if its batteries run down or if it wasn't properly configured and doesn't engage on power failure. The cost of any of these problems is a potentially corrupted database. Either don't use a write-caching controller or buy one that can handle these issues (such as the Compaq SMART-2DH).
Uninterruptible Power Supply
If you are not using a write-back caching controller, you do not need UPS hardware to protect the integrity of your data from a power outage. SQL Server recovers your system to a consistent state after any sudden loss of power. However, you should definitely consider using a UPS; support for UPS hardware is built into Windows NT Server. Most hardware failures, such as memory failures and hardware crashes, result from power spikes that a UPS would prevent. Adding a UPS (a $200 to $500 proposition) is probably the single most important thing you can do from a hardware perspective to maximize the availability and reliability of your system.
Without a UPS, after a power flicker or power spike the machine reboots and perhaps does a CHKDSK of the file system, which can take several minutes. During this time, your SQL Server is unavailable. A UPS can prevent these interruptions. Even if a power outage lasts longer than the life of your UPS, you have time to do an orderly shutdown of SQL Server and checkpoint all the databases. The subsequent restart will be much faster because no transactions need to be rolled back or rolled forward.
Battery Backup, UPS, and CachingA UPS is not the same as the battery backup of the on-board controller RAM. The job of a UPS is to bridge power failures and to give you time to do an orderly shutdown of the system. The computer continues to run for a while from the power supplied by the UPS, and it can be shut down in an orderly way (which the UPS software will do) if power doesn't get restored within the expected battery life.
The battery backup on a caching controller card ensures that the contents of the controller's volatile memory survive the memory is not lost, so when the system restarts the write completes. But it doesn't provide the power to actually make sure that a write succeeds. Some cards even allow the battery backed -up RAM to be moved to a different controller if the initial controller fails. Some provide two sets of batteries so that one can be replaced while the other maintains the RAM's contents, theoretically allowing you to keep adding new batteries indefinitely.
You might expect that using a caching controller that doesn't have a battery backup in combination with a UPS is generally OK if you do an orderly shutdown of SQL Server during the life of the UPS's power. However, this is not always the case. SQL Server support engineers who get customers' servers back up and running can tell horror stories about customers who use write-caching controllers that were not designed around transactional integrity. The caching controller must take into account issues besides power. For example, how does the controller respond to the user pressing the Reset button on the computer? A well-known caching controller of a couple years ago would dump its cache if you hit the Reset button those writes were never carried out even though the calling application (SQL Server) was notified that they had been carried out. This situation often led to corrupt databases.
The Disk Subsystem
The reliability of the disk subsystem (including device drivers) is vitally important to the integrity of your SQL Server data. To help you uncover faulty disk systems, the SQL Server support team created a stand-alone, I/O-intensive, multithreaded file system stress test application. It exercises the Win32 overlapped (asynchronous) I/O services, opens its files with the same write-through cache flags used by SQL Server, and does similar types of I/O patterns. But the test is totally distinct from SQL Server. If this non_SQL Server I/O test cannot run without I/O errors, you do not have a reliable platform on which to run SQL Server, period. Of course, like any diagnostic program, the test might miss some subtle errors. But your confidence should certainly be higher than it would be without testing. You can download the test program for free from the Microsoft Support site at http://support.microsoft.com; select the Drivers And Other Downloads option from the list at the left of the screen. Next select BackOffice, and then SQL Server. You can then choose SQLHDTST.EXE: SQL Server File System Stress Utility from the list of downloadable files. SQLHDTST.EXE is also included on the companion CD.
Fallback Server Capability
Older versions of SQL Server had a fallback ( failover or hot-standby ) server in place, ready to take over the workload of a failed server. This capability required specialized hardware and used a set of stored procedures to set up the fallback server and to notify it when failover needed to take place. Applications had to know the fallback server name and attach to that server if the original server was unavailable. These procedures are no longer supported in SQL Server 7. Instead, SQL Server Enterprise edition can take advantage of Microsoft Cluster Server (MSCS), which is available on Windows NT Enterprise edition. You can install SQL Server 7 on multiple nodes in a cluster, and all nodes are seen as having a single name on the network. Applications do not have to be aware that SQL Server is installed on a cluster, and MSCS handles the failover completely invisibly to users of SQL Server. For more details, see the documentation for Windows NT Enterprise edition.
MSCS (and the older fallback capability) requires specialized hardware. By using various RAID options, you can protect your data without clustering. But without clustering, you are not protected against an application outage if the machine fails. MSCS can automatically shift the control of a "switchable" hard-drive array from a damaged node in the cluster to another node. For example, hardware can be configured with one separately housed hard-drive array connected to two computers. Only one of the connections to the hard-drive array is active at any time. The other hard-drive connection becomes active only if the system detects that the computer currently in control of the hard drive has shut down because of a hardware failure.
The instance of SQL Server on the second node in the cluster can itself perform useful work while the first instance of SQL Server operates normally. The second server can run SQL Server (using different databases than those used by the primary server), or it can act as a file and print server, or it can run some other application. If the second server needs to take over the work of the first server, the second server must have enough resources to add the primary server's workload to its existing workload. (Alternatively, you can decide that the first server's existing workload should take a back seat and that the second server's previous applications should be shut down when it takes over.)
NOTE
Keep in mind that even with clustering, you need RAID to protect against media failure. The log, at least, must be mirrored to protect against a disk failure. The second server can run the disk drives of the failed first server, but those drives must also be protected against media failure.
Most applications probably do not need clustering because today's hardware is highly reliable. The most common hardware failure occurs in a disk drive, which can be protected without clustering by using RAID. As with RAID, clustering does not reduce the need for comprehensive and rigorous backup procedures. You'll probably need backups to recover from an occasional administrator mistake (human error), a catastrophe such as a fire or flood at the site, or a software anomaly. But some applications are so critical that the redundancy of clustering is necessary.
Other Hardware Considerations
If the server is mostly a "lights-out" operation and you will not be administering it locally or running other applications from the actual server machine, it doesn't make much sense to buy a first-class monitor or video card. Consider using an electronic switch box and sharing a monitor, keyboard, and mouse among multiple servers. If you do not use multiple servers, use a basic VGA monitor and video card.
From a performance perspective, a single high-quality network card is sufficient to handle virtually every SQL Server installation. Windows NT Server can support multiple network cards simultaneously, and sometimes your network topology will compel you to use this configuration with SQL Server as well. (Perhaps you are supporting both Ethernet and Token Ring clients on the same server.) One of the largest SQL Server installations at Microsoft supports more than 4000 concurrent physical workstations, and it does so using a single 100-megabit FDDI card. Some sites support hundreds or thousands of users with a single 10-megabit Ethernet card. From a performance perspective, you should never need multiple network cards.
When you plan your hardware configuration, be sure to plan for your backup needs. You can back up to either tape or disk devices. As with regular I/O, you will frequently need multiple backup devices to sustain the I/O rates required for backup. SQL Server can stripe its backup to multiple devices, including tape devices, for higher performance. For the reasons mentioned earlier when we discussed disk devices, a SCSI tape device is typically preferable to an IDE/EIDE device.
NOTE
Not long ago, backup meant tape. Today, with disks costing less than $0.30 per megabyte, many sites configure their hardware with additional disk devices purely for backup use because they prefer the extra speed and ease that backup to disk offers over tape backup. Some sites even use hot swappable drives for their backup; they rotate between a few sets of such drives, keeping a set off site in case of disaster.
EAN: 2147483647
Pages: 144