1.3 Architecture overview
|
| < Day Day Up > |
|
1.3 Architecture overview
It is very useful to understand the differences between Oracle's architecture and that of DB2 UDB before attempting the Oracle to DB2 UDB migration process. Both products include their own memory architecture, back ground processes, database related files, and different configuration files. Both Oracle and DB2 UDB consist of an instance and the database(s) attached to that instance. This section provides a general description of the architectures of each vendor.
Figure 1-1 is an overview of the Oracle architecture. The upper level shows the memory architecture, the middle level is the process component, and the bottom level shows the database component.
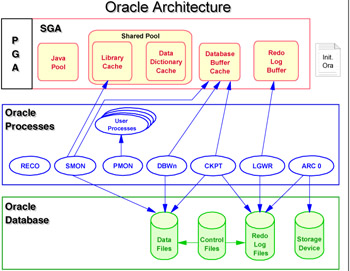
Figure 1-1: Oracle architecture overview
Figure 1-2 shows the DB2 UDB architecture overview. DB2 UDB implements a dedicated process architecture. From a client-server view, the client code and the server code are separated into different address spaces. The application code runs in the client process, while the server code runs in separate processes. The client process can run on the same machine as the database server or a different one, accessing the database server through a programming interface. The memory units are allocated for database managers, database, and application.
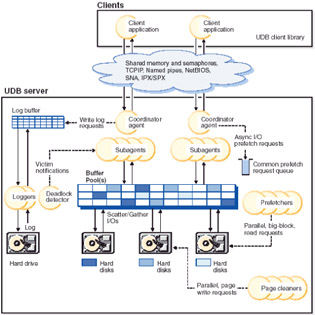
Figure 1-2: DB2 architecture overview
The following section discusses both architectures, detailing memory components and background processes of both databases.
1.3.1 Memory architecture
This section discusses the memory architecture in Oracle and DB2 UDB. Oracle and DB2 UDB allocate and uses memory for instance and database operation. There are various memory structures used for different process. This section gives a broader overview about how memory is allocated and used in a simple Oracle and DB2 UDB server.
The memory architecture of an Oracle database consists of the memory area allocated to the Oracle instance and database upon startup. The amount of memory allocated is controlled by parameters defined in the Oracle configuration file.
The memory architecture of DB2 UDB is slightly different than Oracle's. Unlike Oracle, the DB2 UDB server can run multiple databases under one instance and hence has configuration files at both the instance level (Database Manager configuration file) and at the database level (database configuration file).
Oracle
Oracle uses memory to run the code and share data among the users. The two basic components of the Oracle memory structure are the Program Global Area (PGA) and the System Global Area (SGA). Figure 1-3 shows the primary memory architecture of an Oracle server.
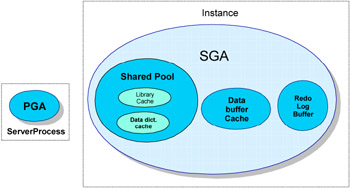
Figure 1-3: Oracle memory architecture
The PGA is associated with the Server process and contains the data and control information. For the dedicated server configuraiton, the primary contents of the PGA are the sort area, session information, cursor state and stack space. This is a non sharable memory which writable only by the server process. The PGA are allocated whenever a server process starts and the total size of the PGA is controlled by the PGA_AGGREGATE_TARGET initialization parameter in version 9i.
The SGA is the shared memory region allocated for the entire Oracle Instance. The SGA is a group of shared memory structures in which the basic components comprises of the shared pool, data buffer cache and the Redo log buffer. The shared pool contains the library cache and data dictionary cache. The library cache holds the SQL statement text, the parsed SQL statement and the execution plan. The data dictionary cache contains reference information about tables, views, object definitions and object privileges. The shared pool size is controlled by SHARED_POOL_SIZE initialization parameter. The data buffer cache stores the most recently used Oracle data blocks. Oracle reads the data blocks from the datafiles and places it in data buffers before processing the data. The number of buffers allocated is controlled by DB_BLOCK_BUFFERS in version 8i and DB_CACHE_SIZE in version 9i. The redo log buffer is circular buffer that contains redo entries of the change information made to the database. These redo log buffers are written into the redo log files and is required for the database recovery. The size of the redo log buffers are controlled by the LOG_BUFFER initialization parameter. The other memory structures of the SGA include the large pool and the Java pool used for backup process and Java objects respectively. For a shared server configuration in version 9i (or multi threaded server in 8i) the session information and the sort areas are in SGA instead of PGA.
DB2 UDB
The three primary memory structures in DB2 UDB are the Instance Shared Memory (also known as Database Manager shared memory), the Database Shared memory and the Application Shared Memory. Figure 1-4 shows the basic memory architecture of a DB2 server.
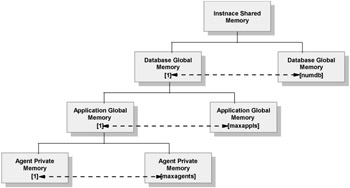
Figure 1-4: DB2 UDB memory architecture
Instance Shared Memory is allocated when the database is started. All other memory is attached or allocated from the instance shared memory. The Instance Shared Memory is controlled by INSTANCE_MEMORY DBM configuration parameter. By default this parameter is set to automatic which enables the DB2 server to allocate the necessary memory for the instance.
Database Shared Memory also known as Database Global Memory is allocated when the database is first activated or connected for the first time. This memory is shared by all the applications that might connect to the database as well as the database EDU's (Engine Dispatchable Units) or database process that runs within each database. The memory allocated for database process includes:
-
Buffer pools - equivalent to Data Buffers in Oracle
-
Locklist
-
Database heap (This includes log buffer)
-
Utility heap - equivalent to Large Pool in Oracle
-
Package cache - equivalent to library cache in Oracle
-
Catalog cache - equivalent to data dictionary cache in Oracle
The buffer pools can be compared to the database buffers in Oracle, the package cache and catalog cache can be compared to library cache and data dictionary cache in Oracle respectively. Database Shared Memory is controlled by DATABASE_MEMORY database configuration parameter. By default this parameter is set to automatic which enables the DB2 UDB to calculate and allocate the memory for the database. Table 1-2 shows the DB2 database memory segments and the associated parameters.
| Database memory | Parameter |
|---|---|
| Buffer pools | BUFFPAGE |
| Locklist | LOCKLIST |
| Database heap (includes log buffer) | DBHEAP |
| Utility heap size | UTIL_HEAP_SZ |
| Package cache | PCKCACHESZ |
| Catalog cache - equivalent to data | CATALOGCACHE_SZ |
Application Shared Memory is allocated when an application connects to a database. This happens only in partitioned database environment or in a non-partitioned database environment where intra-partition is enabled or if the connection concentrator is enabled. This memory is used by the connecting agents to execute the work requested by the clients. The database manager configuration parameter MAX_CONNECTIONS limits the maximum number of applications that connects the database which in turn sets the upper limit for the maximum Application Shared Memory allocated.
| Note | For more information on DB2 Memory Management refer to chapter 8 "Operational Performance: Memory Usage" in the DB2 Administration Guide: Performance, SC09-4821-00. |
1.3.2 Process architecture
Any database instance is nothing but a collection of processes and memory structures. This section discusses about the processes in Oracle and DB2 UDB.
Oracle
There are two major types of Oracle process: the user processes and the background processes (see Figure 1-5).
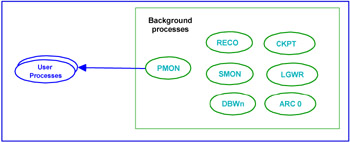
Figure 1-5: Oracle process architecture
User process
Oracle creates a user process when the user or application connects to the database. For each user process, a server process is created by Oracle to handle the user process request to Oracle instance. This architecture works when the client is on the different machine. When the client and the server is on the same machine, the user process and server process are combined to a single process. The function of the server process is to parse the SQL statement, read the Oracle data blocks from the datafile to the data buffer, and return the result set to the client.
Oracle background processes
Oracle requires a number of processes to be running in the background in order to be operational and open to users. These processes are:
-
Database writer (DBWR): This background process writes all dirty data blocks from the database buffer cache to the datafiles on disk. The DBA can configure multiple DBWR processes in order to improve performance.
-
Log writer (LGWR): This is the process that handles writing data from the redo log buffer cache onto the redo log files.
-
System monitor (SMON): This process has two functions. First, it performs an instance recovery when the Oracle instance fails, and second it coalesces smaller fragments of disk space together.
-
Process Monitor (PMON): This process cleans up any remaining Oracle processes resulting from a failing user process. Furthermore, it rollbacks any uncommitted transactions that were performed by the user.
-
Ckeckpoint (CKPT): This process writes log sequence numbers to the database headers and control files.
DB2 UDB
For a DB2 instance to start and run, several process are created and interact with each other, which maintains the applications connected and the database created on the instance. There are several background processes in DB2 that are pre-started, and some start on a need-only basis. This section explains some of the important background processes.
DB2 UDB background processes
The DB2 server activities are performed by Engine Dispatchable Units (EDU) that are defined on a Windows environment as threads and as background processes on both UNIX and Linux systems.
Such as Oracle, there are many background processes dedicated to the operation of the DB2 instance. As mentioned in the previous paragraph, some DB2 background processes are started with the instance, and others are initialized when the database is activated by a connection. Figure 1-6 shows the necessary background processors of the DB2 UDB server at the instance, application, and database level. In the following sections, we discuss some of the important process in each level of DB2 UDB.
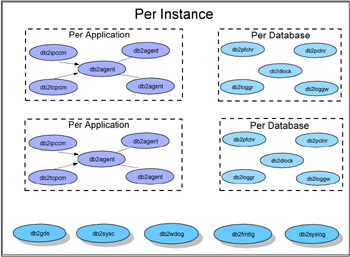
Figure 1-6: DB2 processor architecture
Instance level processes
The following background processes will start as soon as the DB2 UDB server is started with the db2start command.
-
DB2 daemon spawner (db2gds): This is a global daemon processor started for each instance. This process starts all the EDUs (process) in UNIX.
-
DB2 system controller (db2sysc): This is the system controller processor. This is the main process without this process the instance cannot function.
-
DB2 watchdog (db2wdog): This process is required only in UNIX platforms. This process is the parent process for all the processes.
-
DB2 format log (db2fmtlg): This pre-allocates log files in the log path when the LOGRETAIN database configuration parameter is set to ON, and the USEREXIT parameter is set to OFF. This is similar to the optional Archiver log process (ARCn) process in Oracle and is enabled when the database is set in ARCHIVELOG mode.
-
DB2 system logger (db2syslog): This is the system logger process responsible for the writing operating system error log.
Database level processes
The following background processes are started when an active connect to the database as established:
-
DB2 log reader (db2loggr): This process reads the log files during transaction rollback, restart recovery, and rollforward operations. It does part of the functions of Oracle PMON process.
-
DB2 log writer (db2logw): This is the log writer process that flushes the database log from the log buffer to the transaction log files on disk. This is equivalent to the LGWR process in Oracle.
-
DB2 page cleaner (db2pclnr): This process is presented to make room in the buffer pool before prefetchers read pages on disk storage and move into the buffer pool. Page cleaners are independent of the application agents that look for and write out pages from and to the buffer pool to ensure that there is room in the buffer pool. This is equivalent to DBWR process in Oracle.
-
DB2 prefetcher (db2pfchr): This process retrieves data from disk and moves it into the buffer pool before the application needs the data. This does part of the functions of the Oracle server process.
-
DB2 deadlock detector (db2dlock): This is the database deadlock detector process. This process scans the locklist (the lock information memory structure of DB2) and looks for deadlock connections.
Application level processes
These process are started for each application connecting to the database:
-
DB2 communication manager (db2ipccm): This is the inter-process communication (IPC) process started for each application connecting locally. This process communicates with the coordinating agent to perform database tasks. This can be thought of as an Oracle user process connecting locally.
-
DB2 TCP manager(db2tcpcm): This is the TCP communication manager process. This process is started when the remote client or applications connects to the database using TCP/IP communication. This process communicates with the coordinating agent to perform database tasks. This is equivalent to a user process in Oracle.
-
DB2 coordinating agent (db2agent): This process handles requests from applications or connections. This performs all database requests on behalf of the application. There will be one db2agent per application unless the connection concentrator is established. If intra-partition parallelism is enabled, the db2agent will call DB2 subagents to perform the work.
-
DB2 subagent (db2agnta): This is an idle subagent, which works with the db2agent process when intra-partition parallelism is enabled.
-
Active subagent (db2agntp): This is the active subagent that is currently performing work. This process is used when enabling SMP parallelism, which means having more processes achieving the same task. In order to enable this feature in DB2, we must set the intra-parallelism database parameter to true.
The db2agent process, with or without the combination sub agents, performs the similar function of the Oracle server process.
1.3.3 Files and directory structure
This section discusses about important files and the common directory structure used in Oracle and DB2 UDB. A instance and database requires a number of files like datafiles, configuration files, log files etc. to operate and store data. This section looks at some of these important files and gives an overview of its uses. The directory structure gives an idea of how a product is installed and how some files are placed on this structure.
Oracle
Every Oracle instance needs a set of files to comprise itself and operate. These files include the datafiles, redo log files, control file, parameter file, the alert log file, and the password file as shown in the Figure 1-7. The physical files to mount a tablespace in Oracle are called datafiles. The datafiles stores the data, index and rollback segments of the Oracle database. Oracle maintains the database transactions in a transactional log files called redo log files. There should be at least one set of redo log files created for a database to operate. Every Oracle database has a control file. The control file contains the entries that describes the physical structure of the database. Every time a instance is started, the control file is used to identify the datafiles and redo log files to start the database.
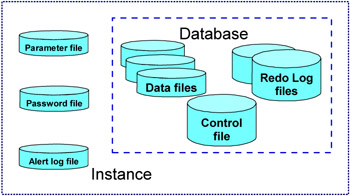
Figure 1-7: Oracle database files
The initialization file or the parameter file is used by the Oracle instance during startup. The file contains the values for many initialization parameters used to allocate memory and start the process for the instance to run. The password file is a security file used for authenticating which users are permitted to start up or shut down an instance or perform other privileged maintenance on a database with SYSDBA or SYSOPER (8i) privileges and additionally OSDBA or OSOPER (9i) privileges. The alert log file is the diagnostics file used by the Oracle instance to record all the dump information of the database like internal errors, block corruption errors, etc.
Oracle installation follows Optimal Flexible Architecture (OFA) standards in creating the directories and placing the files. The OFA is a set of file naming and placement standards. Oracle recommends following OFA standards. Using OFA, the Oracle installation process places the Oracle software in $ORACLE_BASE\ORACLE_HOME and datafiles in $ORACLE_BASE\oradata directory. Figure 1-8 shows a sample installation directory structure on the 8i version of Oracle. The initialization file and the password file reside under dbs path in the UNIX server and database directory in Windows server. The bin directory contains all the executable binary files.
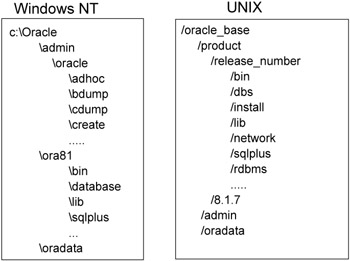
Figure 1-8: Oracle directory structure using OFA
The $ORACLE_HOME\rdbms\admin directory contains the DDL scripts to create the data dictionary tables and views, the administration procedures, and package scripts. These scripts are run when creating the database manually. The $ORACLE_HOME\network\admin directory contains the listener.ora and tnsnames.ora files for communication process. Section 1.3.5, "Communication" on page 21 explains more about these files.
DB2 UDB
The primary files and directories for a DB2 instance and database include the DMS containers, SMS containers (directory or path), DBM cfg file, DB cfg file, the Transaction log files, and the db2diag.log file. This structure is shown in Figure 1-9. The DBM cfg file is created per DB2 instance and contains the configuration parameters and values. This file resides under the sqllib directory of the instance home named as db2systm. This can be related to the initialization parameter file in Oracle but unlike Oracle this is not a text file rather a binary file and can be updated only using UPDATE DBM CFG command.
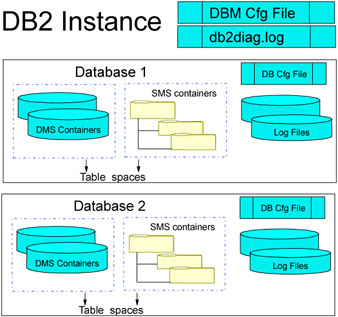
Figure 1-9: DB2 Instance and database files
The DB cfg file the configuration file for each database which stores the database configuration values. This file is stored with the name SQLDBCON under the database directory SQLnnnnn where nnnnn is the database number assigned. This file is also a binary file and can be updated only using the UPDATE DB CFG command. Each database contains the table space containers, which can be either DMS containers as a physical file or partition, or SMS containers, which is either a directory in Windows and file system path in the UNIX environment. Under SMS, a number of different files are created to store the data and the index. The transactional log files records the database transactions, which is required for database recovery. The NEWLOGPATH database configuration parameter identifies the log path if the log files are stored in other than the default log path. The db2diag.log file is like the Oracle Alert log file that records the DB2 error dump information. The DIAGPATH DBM configuration parameter identifies the location of db2diag.log.
Figure 1-10 shows the default directory structure for a simple CREATE DATABASE command with no tablespace options specified. By default the tablespace created will be SMS containers, and the log files will be created in the SQLLOGDIR directory, which can be changed by updating the NEWLOGPATH DB cfg parameter.
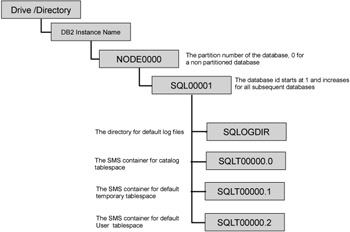
Figure 1-10: DB2 directory structure for a simple create database command
DB2 Installation path depends on the operating system in which it is installed. On Windows operating system the default installation goes under ProgramFiles\IBM\SQLLIB directory. This path can also be changed during the installation. On AIX system the default installation path is /usr/opt/db2_version, on Solaris, Linux and HP-UX system the default installation path is /opt/IBM/db2/db2_version. On UNIX systems a sqllib directory will created under the instance home directory and has symbolic links to actual files under the installation directory. Figure 1-11 shows the installation directory structure for Windows environment and sqllib directory structure for UNIX environment.

Figure 1-11: DB2 UDB directory structure
The adm directory consists of instance administration commands, license management commands and other commands. The backup directory consists of DBM configuration file backup and node configuration backup. The bin directory consists of all DB2 command binaries. The bnd directory contains various database bind files. The db2dump directory holds db2diag.log file and other trace files. All the external stored procedures and routines executable programs are stored under function directory. The Java directory contains the JDBC driver files. The samples directory contains all the program samples that comes shipped with DB2 software.
Configuration files
Since the Oracle instance can only support one database, its background processes are enabled as soon as the instance is started. Therefore, Oracle has one configuration file which is used to configure and tune the database.
The DB2 instance however can support multiple databases, and therefore, consists of an instance level shared memory and a database shared memory running on the server side. Starting the DB2 instance will only start the instance level processes. Database level processes such as those that control transactional processing tasks, logging, and writing to containers on disk are only enabled when the database itself is activated by a user or an application connection.
Therefore, there are two files controlling the configuration and tuning of the DB2 server and database. The first file is used to configure and tune the DB2 server at the instance level is called the Database Manager Configuration (DBM CFG) file. The second is a database level configuration file (DB CFG) used to control database level parameters.
1.3.4 Data Dictionary and Catalog
Every RDBMS has a form of metadata that describes the database and its objects. Essentially, the metadata contains information about the logical and physical structure of the database, integrity constraints, users and schema information, authorization, and privilege information, etc.
In the Oracle database, this metadata is stored in a set of read-only tables and views called the Data Dictionary. These tables and views are updated by the Oracle server. The Data Dictionary is owned by the user SYS and stored in the SYSTEM table space. The base tables are all normalized and are seldom accessed directly, hence, user accessible views are created using the catalog.sql script. The Data Dictionary is organized under three qualifiers: the USER_xxx views, the ALL_xxx views, and the DBA_xxx views. The USER_xxx views show the object information owned by the current user; the ALL_xxx views show all the object information that can be accessed by the current user; and the DBA_xxx view is the database administrator view and contains information on all the objects in the database. Apart from these Data Dictionary, Oracle maintains another set of virtual tables called the dynamic performance views, and the views created on them are prefixed by V$. These views are called the fixed views, and are available when the instance is started without the need of the database to be opened.
In DB2 UDB, the metadata is stored in a set of base tables and views called the Catalog. The Catalog contains information about the logical and physical structure of the database objects, object privileges, Integrity information, etc.
The DB2 database catalog is automatically created when the database is created. The base tables are owned by the SYSIBM schema and stored in the SYSCATSPACE tablespace. On top of the base tables, the SYSCAT and SYSSTAT views are created. SYSCAT views are the read-only views that contain the object information, and SYSSTAT is the updateable view, which contains the statistical information. View the catalog information through the SYSCAT view, but base tables are recommended.
Unlike in Oracle, DB2 does not maintain any dynamic performance views, but uses the commands to get the information from the system directory like: LIST DATABASE DIRECTORY, LIST TABLESPACES, LIST APPLICATIONS etc. Table 1-3 shows some of the commonly used views available in Oracle Data Dictionary and DB2 Catalog.
| Oracle Data Dictionary | DB2 Catalog |
|---|---|
| DBA_TABLES | SYSCAT.TABLES |
| DBA_TAB_COLUMNS | SYSCAT.COLUMNS |
| DBA_TABLESPACES | SYSCAT.TABLESPACES |
| DBA_INDEXES | SYSCAT.INDEXES |
| DBA_TAB_PRIVS | SYSCAT.TABAUTH |
| DBA_TRIGGERS | SYSCAT.TRIGGERS |
| DBA_VIEWS | SYSCAT.VIEWS |
| DBA_SEQUENCES | SYSCAT.SEQUENCES |
| DBA_PROCEDURES | SYSCAT.ROUTINES |
The complete DB2 UDB catalog views can be found in DB2 UDB SQL Reference Volume 1 and 2, SC09-4484 and SC09-4485.
1.3.5 Communication
This sections gives an overview of the communication architecture that enables a simple client-server communication in Oracle and DB2 UDB environment and some of the tools used to communicate from the client.
Database accessing
Both DB2 and Oracle support dynamic and embedded static SQL interfaces. Oracle provides the SQL*Plus tool for command line access to the database server. SQL*Plus also comes with a GUI version. DB2 provides Command Line Processor (CLP) for a command line access to the database server. The GUI version for this tool is called as Command Center. The Oracle client installation installs the SQL*Plus tool, Oracle Net Services software, ODBC drivers and other tools. These software provides a basic client server communication to access the database server. DB2 client installation provides the DB2 runtime client, Command Line Processor, Configuration Assistant, Command Center, ODBC drivers etc. for a basic client server communication.
Oracle communication
The client server communication in Oracle Server is handled by Oracle Net Services. Oracle Net Services support communications on all major protocols. The Oracle Net Services provides a communication interface between the client user process and the Oracle server process, enabling the data transmission and messages exchange between Oracle server and client. The Oracle Net Services use the technology called Transparent Network Substrate (TNS) to perform these tasks. The TNS enables the peer-to-peer application connectivity where the two nodes communicate each other directly.
The Oracle Net Services provides the listener process that resides in the Oracle server, which listens for incoming client connection requests, and maps it to the Oracle instance. The listener is configured with one or more protocol addresses; the client configured with one of these protocol address can send connection requests to listener. A configuration file listener.ora is maintained in the Oracle server that contains the protocol address, database service information, and listener configuration parameters. The listener process is controlled by the LSNRCTL utility; the LSNRCTL utility reads the listener.ora file and starts the listener process. The server services information in client is maintained in a file called tnsnames.ora. Oracle Net8 Assistant is a graphical utility used to configure the Oracle Net Services like listener, service naming, etc.
DB2 UDB communication
DB2 supports several communication protocol for client server communication like TCP/IP, APPC, NPIPE, NetBIOS etc. Most protocols are automatically detected and configured during an instance creation. The DB2COMM registry variable identifies the protocol detected in a server. To enable a specific protocol, use the db2set DB2COMM command. For TCP/IP, a unique port address has to be specified in the database manager configuration. This port is registered in the services file. For example, to reserve a port 50000 with the service name db2cidb2, the entry in services file is:
db2icdb2 50000/tcp
Update this information in the database manager using the command:
db2 UPDATE DBM CFG USING SVCENAME db2icdb2
These tasks can also be performed using the DB2 Configuration Assistant utility. At the client, the database information is configured using either the CATALOG command or using the Configuration Assistant. The database are configured under a node which describes the host information like protocol and port etc. To configure a remote TCP/IP node the command used is:
db2 CATALOG TCPIP NODE node-name REMOTE host-name SERVER service-name
The service name registered in the server or the port number can be specified in the SERVER option. To catalog a database under this node the command used is:
db2 CATALOG DATABASE database-name AS alias-name AT NODE node-name
The Configuration Assistant is the GUI tool used in client to configure a database. Figure 1-12 shows how the Configuration Assistant is used to add a database connection. The option "Search the network" is used to add a database using DB2 Discovery Method. Using this option the DB2 servers installed in the entire network can be searched and used to add database connection. This is possible when the DB2 administration server process is created in the server and enabled for discovery.
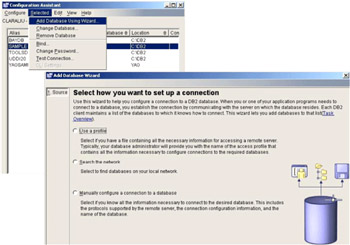
Figure 1-12: Configuring the database connection using Configuration Assistant
| Note | DB2 Discovery method is enabled at the instance level using the DISCOVER_INST parameter, and at database level using DISCOVER_DB parameter. |
1.3.6 Data replication
Both Oracle and DB2 UDB provide replication capabilities in their databases. The main purpose of enabling replication is to have the same set of date records in more than one location. Having two copies of the same database can be a part of a high availability solution. This section discusses the replication approach by both Oracle and DB2 UDB.
Oracle replication
Oracle has the ability to replicate data from one Oracle database to another. Changes to an Oracle database are replicated to another Oracle database through the capture and apply processes. Oracle replication uses triggers in order to capture transactional changes and stores them in a local queue. Oracle then uses packages in order to apply the replicated changes to the target database. Oracle Enterprise Manager (OEM) may be used to perform replication tasks.
DB2 UDB replication
IBM Data management software provides products that enable customers to replicate data from both relational and non-relational sources. Data Propagator (DPROP) is widely used by DB2 customers to replicate data from one DB2 database to another. Furthermore, DB2 Information Integrator or DB2 II is known in DB2 UDB V7.x as the data joiner, which has the ability to propagate data among many relational databases such as Sybase and MS-SQL Server.
DB2 UDB replication can be used to replicate data between DB2 databases in a distributed environment such as Microsoft Windows, UNIX, and Linux. It also can be used to propagate data from and to a main frame OS/390 or an AS/400 environment. All replication operations can be done through the capture and apply processes.
The replication process in DB2 UDB consists of identifying and setting up three databases:
-
Source database: A database containing source tables that need to be replicated.
-
Target database: A database server where the target tables will reside and the apply process will take place.
-
Control database: A database that contains the control tables storing the necessary information for the apply program and which can reside on either the source or target database.
DB2 UDB replication is an asynchronous process. The frequency of replication can be set to minimize any delay. There are two administration interfaces through which we can set up replication. The first is the DB2 Replication Center, which are GUI tools provided by DB2 UDB to define, manage, and monitor replication. The second is the asnclp tool, which provides command line definition of replication objects.
|
| < Day Day Up > |
|