General Sort Considerations
General Sort ConsiderationsSorting has been a subject of research for decades, and it is not difficult to find a reasonable recipe nowadays. What we expect, at a minimum, is that each of the Big Eight act this way:
All right, so what does affect sort speed? Here's the answer, in order of importance:
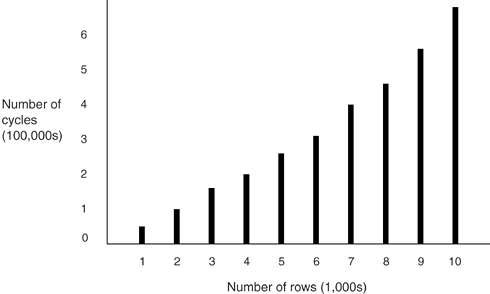
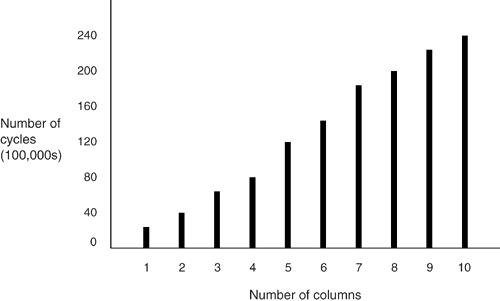
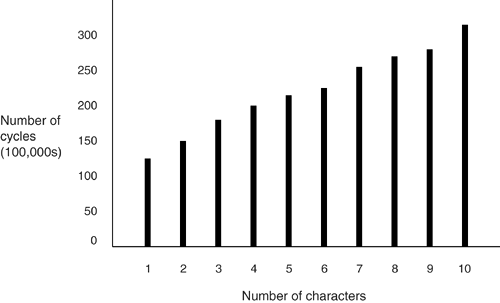
Figures 3-1, 3-2, and 3-3 show the effect, on sort speed, of increasing each of these variables . Figure 3-1. Effect on sort speed of increasing row count; Test #1 Figure 3-2. Effect on sort speed of increasing column count; Test #2 Figure 3-3. Effect on sort speed of increasing column length; Test #3
We make several more statements about what happens with a sort in the following sections. Partial duplicates slow sortsSuppose you have a table with a CHAR column. Populate the column with data in which the first five characters are duplicates. Now SELECT: SELECT column1 FROM Table1 ORDER BY column1 Delete all rows and repopulate , this time with random data. SELECT again: SELECT column1 FROM Table1 ORDER BY column1 GAIN: 5/8 Skipping the duplicated characters made the sort faster for five DBMSs. Presorting speeds sortsGo back to your table with a CHAR column. Populate the column with random data and SELECT: SELECT column1 FROM Table1 ORDER BY column1 Delete all rows and repopulate, this time with data that's in alphabetic order and SELECT: SELECT column1 FROM Table1 ORDER BY column1 GAIN: 4/8 Having the rows already in order made the sort faster for half of the Big Eight. It's the defined length that mattersRemember that a variable-length column has a defined length and an actual length. For example, a VARCHAR(30) column may contain ABC , in which case its defined length is 30 characters and its actual length is three characters. For sorting, it's the 30-character definition that matters! We tested this by varying the defined length of a VARCHAR column, while keeping the actual data length the same. The result was that Scenario #1 is slower than Scenario #2 even when the contents are the same in both cases: Scenario #1: CREATE TABLE Table1 ( column1 VARCHAR(100)) SELECT column1 FROM Table1 ORDER BY column1 Scenario #2: CREATE TABLE Table2 ( column1 VARCHAR(10)) SELECT column1 FROM Table2 ORDER BY column1 GAIN: 6/8 Moral Defining VARCHAR columns with "room to grow" degrades sorts. The gain might seem surprising, but it's consistent with the way that most sort algorithms work: They allot a fixed memory buffer in advance, and the size of the buffer depends on the maximum anticipated key size . INTEGERs beat SMALLINTsOn Windows machines, where an INTEGER requires 32 bits and a SMALLINT requires 16 bits, the tendency may be to think that SMALLINT sorting is faster than sorting INTEGER columns. But comparisons of integers are usually faster because 32 bits is your computer's word size and DBMSs are able to take advantage of the fact. So Scenario #1 is slower than Scenario #2: Scenario #1: CREATE TABLE Table1 ( column1 SMALLINT) SELECT column1 FROM Table1 ORDER BY column1 Scenario #2: CREATE TABLE Table2 ( column1 INTEGER) SELECT column1 FROM Table2 ORDER BY column1 GAIN: 5/8 INTEGERs beat CHARsWe sorted a CHAR(4) column, then we sorted an INTEGER column, both with random data. The INTEGER sort was often faster, because a character string cannot be compared four bytes at a timebut this is done for an integer. Thus Scenario #1 is slower than Scenario #2: Scenario #1: CREATE TABLE Table1 ( column1 CHAR(4)) SELECT column1 FROM Table1 ORDER BY column1 Scenario #2: CREATE TABLE Table2 ( column1 INTEGER) SELECT column1 FROM Table2 ORDER BY column1 GAIN: 4/8 Sets beat multisetsTechnically, a multiset differs from a set because it contains duplicates. Testing against two tables with the same number of rows, but with significant numbers of duplicates in the first table, we found, once again, that sorting is faster when there are no duplicates. ConclusionThe fastest sort is an ascending sort of an integer with unique values, presorted. The ORDER BY ClauseA simplified description of the SELECT ... ORDER BY syntax looks like this: SELECT <column list> /* the select list */ FROM <Table list> ORDER BY <column expression> [ASC DESC] [,...] This syntax has a new wrinkle. In SQL-92, you had to ORDER BY <column name > , and the column named had to be in the select list. In SQL:1999, you're allowed to ORDER BY <column expression> . For example, to sort numbers in backwards order, you've now got these two choices: With New SQL:1999 Wrinkle: SELECT numeric_column FROM Table1 ORDER BY numeric_column * -1 Without New Wrinkle: SELECT numeric_column, numeric_column * -1 AS num FROM Table1 ORDER BY num Two incidental remarks about this example:
Table 3-1 shows the SQL Standard requirements and the level of support the Big Eight have for ORDER BY. Notes on Table 3-1:
For many DBMSs, NULLs sort Lowthat is, NULLs are considered to be less than the smallest non-NULL value. For IBM, Ingres, and Oracle, NULLs sort Highthat is, NULLs are considered to be greater than the largest non-NULL value. For InterBase and PostgreSQL, NULLs sort At the Endwhether you're sorting in ascending or in descending order. That means the set of values {-1, +1, NULL} sorts four different ways depending on DBMS and depending on your sort order:
The result is that ORDER BY column1 * -1 and ORDER BY column1 DESC return different results (with NULL in a different spot) unless you use InterBase or PostgreSQL. The use of expressions in ORDER BY is not 100% portable, but some useful expressions can help speed or clarity:
Such functions would be unacceptable if the DBMS called them multiple times. However, the DBMS evaluates the sort-key value only once per input row, at the time it forms the tags. To make sure of this, we tested ORDER BY with a user -defined function that simply counted how many times the function was called. Six of the Big Eight called the function only once per row (GAIN: 6/6). Portability Informix and InterBase don't allow expressions in ORDER BY. The gain shown is for only six DBMSs. To Sort or Not to Sort
Sometimes there is a temptation to follow such advice and skip ORDER BY if it's certain that the rows are in order anyway. Our tests showed this about such assumptions:
If you add ORDER BY column1 in any of these three cases, the SELECT is always slower (AVERAGE GAIN: 5/8 without ORDER BY). This suggests that DBMSs will not remove unnecessary ORDER BY clauses automatically. However, our tests also showed that the effect is unpredictable with more complex statements that contain any of the following: joins, unions, multiple columns in the select list, long columns, columns indexed with a descending index, or columns requiring secondary sorts (we'll talk about secondary sorts later in this chapter). Finally, we failed to find that any such side effect was documented in any vendor manual. So we urge caution. The Bottom Line: General SortsThe three variables that affect sort speed are, in order of importance:
An increase in the row count has a geometric effect on sort speed. If you multiply the number of rows by ten, the job takes twenty times as long. Take drastic action to reduce the number of rows you sort.
Some DBMSs sort NULL high. Some DBMSs sort NULL low. Some DBMSs sort NULL at the end of a list. Since there's no standard way of sorting NULL; don't write code that depends on the DBMS putting all the NULLs in a specific place. The use of expressions in ORDER BY is not 100% portable. But using expressions like ORDER BY LOWER(column1) , ORDER BY SUBSTRING(column1 FROM 1 FOR 6) , and ORDER BY CAST(column1 AS CHAR...) can help speed or clarity. SELECT column1 FROM Table1 returns a result set in order by column1 if Table1.column1 is clustered or otherwise preordered. SELECT column1 FROM Table1 WHERE column1 > -32768 returns a result set in order by column1 if column1 is indexed and the DBMS makes use of the index. SELECT DISTINCT column1 FROM Table1 returns a result set in order by column1 if column1 is not unique. "Omit ORDER BY" is a popular tip, and it actually has an effectbut the effect is unreliable. This is fine if the ordering is for cosmetic purposes, or if the number of rows is tiny, but in other cases . Judge the tip's merits for yourself. |
EAN: 2147483647
Pages: 125