2.4 Internal Numeric Representation
2.4 Internal Numeric Representation
Most modern computer systems are binary computer systems and, therefore, use an internal binary format to represent values and other objects. However, most systems cannot represent just any binary value. Instead, they are only capable of efficiently representing binary values of a given size . If you want to write great code, you need to make sure that your programs use data objects that the machine can represent efficiently. The following sections describe how computers physically represent values.
2.4.1 Bits
The smallest unit of data on a binary computer is a single bit . Because a bit can represent only two different values (typically zero or one) you may get the impression that there are a very small number of items you can represent with a single bit. Not true! There are an infinite number of two-item combinations you can represent with a single bit. Here are some examples (with arbitrary binary encodings I've created):
-
Zero (0) or one (1)
-
False (0) or true (1)
-
Off (0) or on (1)
-
Male(0) or female (1)
-
Wrong (0) or right (1)
You are not limited to representing binary data types (that is, those objects that have only two distinct values). You could use a single bit to represent any two distinct items:
-
The numbers 723 (0) and 1,245 (1)
-
The colors red (0) and blue (1)
You could even represent two unrelated objects with a single bit. For example, you could use the bit value zero to represent the color red and the bit value one to represent the number 3,256. You can represent any two different values with a single bit. However, you can represent only two different values with a single bit. As such, individual bits aren't sufficient for most computational needs. To overcome the limitations of a single bit, we create bit strings from a sequence of multiple bits.
2.4.2 Bit Strings
As you've already seen in this chapter, by combining bits into a sequence, we can form binary representations that are equivalent to other representations of numbers (like hexadecimal and octal). Most computer systems, however, do not let you collect together an arbitrary number of bits. Instead, you have to work with strings of bits that have certain fixed lengths. In this section we'll discuss some of the more common bit string lengths and the names computer engineers have given them.
A nibble is a collection of four bits. Most computer systems do not provide efficient access to nibbles in memory. However, nibbles are interesting to us because it takes exactly one nibble to represent a single hexadecimal digit.
A byte is eight bits and it is the smallest addressable data item on many CPUs. That is, the CPU can efficiently retrieve data on an 8-bit boundary from memory. For this reason, the smallest data type that many languages support consumes one byte of memory (regardless of the actual number of bits the data type requires).
Because the byte is the smallest unit of storage on most machines, and many languages use bytes to represent objects that require fewer than eight bits, we need some way of denoting individual bits within a byte. To describe the bits within a byte, we'll use bit numbers . Normally, we'll number the bits in a byte, as Figure 2-3 shows. Bit 0 is the low-order ( LO ) bit or least significant bit , and bit 7 is the high-order ( HO ) bit or most significant bit of the byte. We'll refer to all other bits by their number.
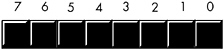
Figure 2-3: Bit numbering in a byte
The term word has a different meaning depending on the CPU. On some CPUs a word is a 16-bit object. On others a word is a 32-bit or 64-bit object. In this text, we'll adopt the 80x86 terminology and define a word to be a 16-bit quantity. Like bytes, we'll number the bits in a word starting with bit number zero for the LO bit and work our way up to the HO bit (bit 15), as in Figure 2-4. When referencing the other bits in a word, use their bit position number.
Figure 2-4: Bit numbers in a word
Notice that a word contains exactly two bytes. Bits 0 through 7 form the LO byte, bits 8 through 15 form the HO byte (see Figure 2-5).

Figure 2-5: The two bytes in a word
A double word is exactly what its name implies, a pair of words (sometimes you will see 'double word' abbreviated as 'dword'). Therefore, a double-word quantity is 32 bits long, as shown in Figure 2-6.
Figure 2-6: Bit layout in a double word
A double word contains a pair of words and a set of four bytes, as Figure 2-7 shows.
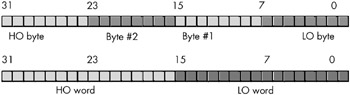
Figure 2-7: Bytes and words in a double word
Most CPUs efficiently handle objects up to a certain size (typically 32 or 64 bits on contemporary systems). That does not mean you can't work with larger objects - it simply becomes less efficient to do so. For that reason, you typically won't see programs handling numeric objects much larger than about 128 or 256 bits. Because 64-bit integers are available in some programming languages, and most languages support 64-bit floating-point values, it does make sense to describe a 64-bit data type; we'll call these quad words . Just for the fun of it, we'll use the term long word for 128-bit values. Few languages today support 128 bit values, [2] but this does give us some room to grow.
Of course, we can break quad words down into 2 double words, 4 words, 8 bytes, or 16 nibbles. Likewise, we can break long words down into 2 quad words, 4 double words, 8 words, or 16 bytes.
On Intel 80x86 platforms there is also an 80-bit type that Intel calls a tbyte (for 10-byte) object. The 80x86 CPU family uses tbyte variables to hold extended precision floating-point values and certain binary-coded decimal (BCD) values.
In general, with an n -bit string you can represent up to 2 n different values. Table 2-3 shows the number of possible objects you can represent with nibbles, bytes, words, double words, quad words, and long words.
| Size of Bit String (in Bits) | Number of Possible Combinations (2 n ) |
|---|---|
| 4 | 16 |
| 8 | 256 |
| 16 | 65,536 |
| 32 | 4,294,967,296 |
| 64 | 18,446,744,073,709,551,616 |
| 128 | 340,282,366,920,938,463,463,374,607,431,768,211,456 |
[2] HLA, for example, supports 128-bit values.
EAN: 2147483647
Pages: 144