7.4 Tuning BTree Indexes
|
| < Day Day Up > |
|
This is not a data warehouse tuning book. Tuning data warehouses is another subject. Any read-only indexes should generally not be used in OLTP or client-server databases. Therefore, this book will concentrate on potential tuning issues with BTree indexes. Some tuning issues have already been covered in this chapter. These issues have dealt with the philosophical side of how and what to index, some details about BTree indexing and use of read-only indexes.
What can be done with BTree indexes to make them work faster?
7.4.1 Overflow and Rebuilding
Oracle Database BTree indexes do not overflow but they can become skewed. Skewing can happen with a binary tree for instance when a large percentage of index values belong to a single branch. Take a look at the BTree representation in Figure 7.3. Figure 7.3 is a picture of what the Accounts schema GeneralLedger.COA# column foreign key index might look like physically. The set of leaf blocks for branch 1 has over 300,000 rows, about 40% of the total rows. Branch 4 has over 30,000 rows, about 5% of the total rows. That is not proportionate. In other words when searching for COA# = '30001' 40% of the total physical space is searched, when searching for COA# = '60001' only 5% of the total physical space is searched. This is a potentially skewed binary tree because it is heavier in some parts.
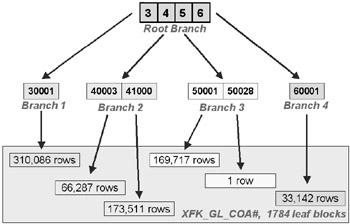
Figure 7.3: A Skewed BTree Index
The example in Figure 7.3 is a poor example and is more due to the nature of the GeneralLedger.COA# column data. The reason is because most skewing of binary trees occurs when data is changed such that one particular area of a table is added to rather than another. The result is a binary tree heavily loaded in one or more specific places. The temptation in a case such as this is to use a bitmap index. Don't! The GeneralLedger table is a heavily DML active table. Over a long period of time a bitmap index could deteriorate to the point of uselessness.
The answer to skewed binary indexes is the ALTER INDEX command using the REBUILD ONLINE options. Rebuilding an index will rebalance a BTree index and help to spread everything out more evenly, particularly with respect to overflow. The ONLINE option will prevent disruption of current DML activity.
Lost Index Space
Let's dive just a little into some physical index tuning. When setting block storage management parameters for tables and indexes there are numerous modifiable parameters. Two of these parameters are PCTUSED and PCTFREE. For tables there are two parameters and for indexes there is one. PCTUSED allows reuse of a block when the occupied space in a block falls below the percentage specified, as a result of DML DELETE commands. The PCTFREE parameter allows allocation of free space to a block only usable by future DML UPDATE commands, including expanding column values. PCTFREE helps to avoid row chaining. PCTUSED and PCTFREE will be covered in detail in physical tuning. The issue with indexing is that an index cannot have a PCTUSED parameter. What does this tell us about indexes? Deleted index space is not reclaimed unless an index is rebuilt using the ALTER INDEX index-name REBUILD; command.
| Tip | PCTUSED and PCTFREE settings cannot be changed for already existing blocks. |
| Note | Oracle Database 10 Grid PCTUSED parameter values are ignored in locally managed table-spaces using automated segment space management. Automated segment space management will be covered in Part III. Automated segment space management is an accepted practice in Oracle9i Database and recommended in Oracle Database 10g. |
So large numbers of row insertions and deletions can over time denigrate the quality of BTree indexes. It is advisable to regularly rebuild Oracle Database BTree indexes for this reason, if possible. The REBUILD ONLINE option will prevent interference with DML activity during an index rebuild.
It is possible to use the ALTER INDEX command with the COALESCE and DEALLOCATE UNUSED options. These options will not help very much and might make things worse. COALESCE attempts to amalgamate empty extents and DEALLOCATE UNUSED tries to reclaim space above the high water mark, both rare possibilities. On a consulting job in the past I executed a COALESCE command on some highly deteriorated BTree indexes only to find the datafile containing those indexes about 25% larger after completion. Use index rebuilds. Once again indexes can be rebuilt online as well without disrupting DML activity.
7.4.2 Reverse Key Indexes
Reverse key indexes are useful for high cardinality (unique values) in highly concurrent multi-user environments. Where index values are created in a sequential sequence there can be problems with contention for index blocks when multiple DML statements are accessing the same block. The sequential numbers will all be added into the same index block. This kind of problem often occurs with INSERT statements using incremental Oracle Database sequences as primary keys. All the INSERT commands take a sequence number close to every other recently generated sequence. Thus all those sequences will be placed into the same block of the index causing contention for the block and causing serious availability problems. This is known as "hot blocking".
An answer to this problem is using reverse key indexes. What is a reverse key index? A reverse key index simply stores the bytes in the indexed column value, into the index, with the string of the bytes in reverse order as shown in Figure 7.4.
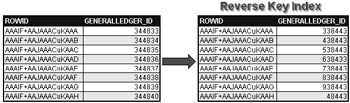
Figure 7.4: A Reverse Key Index
How do reverse key indexes resolve high concurrency contention for index blocks on sequential key values? The act of reversing the bytes in the keys serves to place those index values into separate blocks, thus avoiding contention for a single index block. The down-side to use of reverse key indexes is that no efficient BTree tree traversals can be performed and thus no index range scans. The index values are randomly scattered across the blocks of the index. The order of the index is maintained and thus the index remains usable in the required order.
In the Accounts schema the GeneralLedger table is only ever inserted into and the primary key is a sequence number. This primary key is a candidate for a reverse key index. Since the GeneralLedger table is large and is accessed with DML commands other than INSERT it is probably unwise to make this table's primary key index a reverse key index.
Two things warrant mentioning. Firstly, attempting to detect index block contention is physical tuning and is not appropriate for this chapter. Secondly, reverse index keys generally only apply in high concurrency clustered Oracle Database RAC (Parallel Server) environments. Reverse key indexes allow for efficient heavy insertion activity but can be problematic for any sequentially ordered index matching or filtering activity unless searching for an exact row (no index range scans).
7.4.3 Compressed Composite Indexes
Compression of BTree indexes applies to composite-column indexes only. A composite index sometimes represents a many-to-many join resolution join entity or a master detail relationship between a parent and child table; the composite index is placed on the child table.
Compressing the index allows removal of repeating index column values from leaf blocks to a prefix. Figure 7.5 shows an example of what index compression does to an index; duplications are removed. A compressed index maintains a prefix key value pointing to ROWID pointers, which point to the table rows. A compressed index saves a little space. For really large indexes it could potentially save a lot of space.
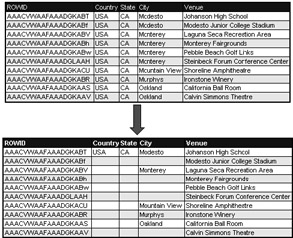
Figure 7.5: A Compressed Composite-Column Index
Index compression can have the following effects:
-
Decrease the physical size of the index allowing faster searching through less physical disk space.
-
Searching composite indexes may be problematic when not ordering columns in indexes according to the exact order of the composite columns.
-
DML activity may be a little slower for composite indexes due to the possible need to reconstruct the split structure between compressed and uncompressed columns.
-
In general searches using composite indexes cannot perform unique index hits and default to range scans. It is possible that exact hits could be obtained on the first prefix column of a compressed index since it is physically unique to the index.
-
In highly concurrent environments compressed composite indexes and the addition of prefix entries could potentially lock more rows in indexes. Compressed indexes may perform less effectively under conditions of high concurrency.
Obviously a single-column index cannot be compressed. There would not be any point since there is nothing to compress. When creating a compressed index one can compress up to the number of columns in the composite index less one. Let's use the TransactionsLine table for our first example.
EXPLAIN PLAN SET statement_id='TEST' FOR SELECT transaction_id, seq# FROM transactionsline; Query Cost Rows Bytes ----------------------------------- ---- ------ ------- SELECT STATEMENT on 283 739772 3698860 INDEX FAST FULL SCAN on XPK_TRANSACTIONSLINE 283 739772 3698860
The following ALTER INDEX DDL command will compress the two-column primary key index in the Accounts schema TransactionsLine table.
ALTER INDEX xpk_transactionsline REBUILD ONLINE COMPUTE STATISTICS COMPRESS 1;
Now let's run the same query once again.
EXPLAIN PLAN SET statement_id='TEST' FOR SELECT transaction_id, seq# FROM transactionsline; Query Cost Rows Bytes ----------------------------------- ---- ------ ------- SELECT STATEMENT on 254 739772 3698860 INDEX FAST FULL SCAN on XPK_TRANSACTIONSLINE 254 739772 3698860
In the previous TransactionsLine table examples there is a small decrease in cost on compressing the index. The cost has been reduced from 283 down to 254, a 10% cost decrease.
Let's now use a different table much more applicable to composite indexing. The following query shows that there are in excess of thousands of rows for every COA# value. This is not the case with the TransactionsLine table master detail relationship between the TRANSACTION_ID and SEQ# composite primary key columns.
SQL> SELECT coa#, COUNT(coa#) FROM generalledger GROUP BY coa#; COA# COUNT(COA#) ------ ----------- 30001 377393 40003 145447 41000 246740 50001 203375 50028 1 60001 72725
Create a new index.
CREATE INDEX xak_composite ON generalledger(coa#, generalledger_id) ONLINE COMPUTE STATISTICS;
Find the cost of the use of the index uncompressed.
EXPLAIN PLAN SET statement_id='TEST' FOR SELECT coa#, generalledger_id FROM generalledger; Query Cost Rows Bytes ----------------------------------- ---- ------ ------- SELECT STATEMENT on 432 912085 9120850 INDEX FAST FULL SCAN on XAK_COMPOSITE 432 912085 9120850
Now using the COMPRESS clause we will remove duplicates of the COA# column from the index.
ALTER INDEX xak_composite REBUILD ONLINE COMPUTE STATISTICS COMPRESS 1;
Now use the EXPLAIN PLAN command again.
EXPLAIN PLAN SET statement_id='TEST' FOR SELECT coa#, generalledger_id FROM generalledger;
Looking at the following result, the cost is lower. The difference is now 432 down to 316, a 25% decrease in cost.
Query Cost Rows Bytes ----------------------------------- ---- ------ ------- SELECT STATEMENT on 316 912085 9120850 INDEX FAST FULL SCAN on XAK_COMPOSITE 316 912085 9120850
The TransactionsLine table examples showed a 10% decrease in cost and the GeneralLedger table examples showed a decrease in cost of much more at 25%. The more duplicates removed by compression the better the increase in performance.
On a more detailed level we can conclude that the relationship between the TRANSACTION_ID and SEQ# columns should be in the range of thousands. This is not the case. The TransactionsLine table is probably inappropriate for a composite index. In a properly structured data model composite indexes would probably be inappropriate for most many-to-many join resolution entities and master detail relationships unless a traditional composite parent-child data model structure was used. Why? There are generally not enough repetitions of the prefix (the compressed columns) of the compressed index to warrant its use. The GeneralLedger.COA# column values repeat enough to show a marked performance increase.
Compressed Indexes and DML Activity
Do compressed indexes affect the performance of DML activity? A DML command executed using a compressed index may incur a small amount of overhead as opposed to an uncompressed index. Suffix index values are not stored directly with prefix values and further interpretation is required. Here I am going to attempt to compare DML performance between compressed and uncompressed indexes.
The rows for GeneralLedger.COA# = '60001' table entries account for over 5% of the table. The chances are the Optimizer will often choose a full table scan rather than an index read. I am going to force the Optimizer to use the composite index with a hint to avoid full table scans because we are trying to compare indexes. We will start with the index uncompressed. I am using an UPDATE and a DELETE statement. INSERT is irrelevant in this case.
ALTER INDEX xak_composite REBUILD ONLINE COMPUTE STATISTICS NOCOMPRESS; EXPLAIN PLAN SET statement_id='TEST' FOR UPDATE /*+ INDEX(generalledger, xak_composite) */ generalledger SET dr=0, cr=0 WHERE coa# = '60001';
The cost of the UPDATE query is high. The Optimizer probably would have selected a full table scan without the hint.
Query Cost Rows Bytes ----------------------------------- ---- ------ ------- UPDATE STATEMENT on 3016 156159 1717749 UPDATE on GENERALLEDGER INDEX RANGE SCAN on XAK_COMPOSITE 488 156159 1717749 EXPLAIN PLAN SET statement_id='TEST' FOR DELETE FROM /*+ INDEX(generalledger, xak_composite) */ generalledger WHERE coa# = '60001'; Query Cost Rows Bytes ----------------------------------- ---- ------ ------- DELETE STATEMENT on 488 156159 1561590 DELETE on GENERALLEDGER INDEX RANGE SCAN on XAK_COMPOSITE 488 156159 1561590
Now let's compress the index.
ALTER INDEX xak_composite REBUILD ONLINE COMPUTE STATISTICS COMPRESS 1; EXPLAIN PLAN SET statement_id='TEST' FOR UPDATE /*+ INDEX(generalledger, xak_composite) */ generalledger SET dr=0, cr=0 WHERE coa# = '60001'; Query Cost Rows Bytes ----------------------------------- ---- ------ ------- UPDATE STATEMENT on 2898 156622 1722842 UPDATE on GENERALLEDGER INDEX RANGE SCAN on XAK_COMPOSITE 359 156622 1722842 EXPLAIN PLAN SET statement_id='TEST' FOR DELETE FROM /*+ INDEX(generalledger, xak_composite) */ generalledger WHERE coa# = '60001'; Query Cost Rows Bytes ----------------------------------- ---- ------ ------- DELETE STATEMENT on 359 156622 1566220 DELETE on GENERALLEDGER INDEX RANGE SCAN on XAK_COMPOSITE 359 156622 1566220
We can see from the four preceding query plans that DML activity is actually speeded up with the compressed index, even in an active database. Commercial databases with thousands of transactions per second may behave differently.
Let's clean up by dropping extra indexes and uncompressing those still compressed for both the TransactionsLine and GeneralLedger tables. It is important to clean up after yourself.
ALTER INDEX xpk_transactionsline REBUILD ONLINE COMPUTE STATISTICS NOCOMPRESS; DROP INDEX ak_composite;
7.4.4 Function-Based Indexes
A regular BTree index contains column values of indexed columns in index leaf blocks, which link to tables using ROWID pointers. A function-based index contains the result of an expression on a column or column values, placing the expression result into the index leaf blocks. How is this relevant to tuning? A regular BTree index on a column will be completely ignored by the Optimizer when a column is part of an expression in an SQL statement. Figure 7.6 shows an example of a function-based index.
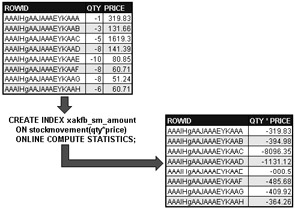
Figure 7.6: A Function-Based Index
Some specific settings are required in Oracle Database to allow use of function-based indexes.
-
The cost-based Optimizer is required.
-
The user must have:
-
The QUERY_REWRITE system privilege.
-
Execute privileges on any user-defined functions.
-
-
Oracle Database configuration parameters must be set as follows:
-
QUERY_REWRITE_ENABLED = TRUE.
-
QUERY REWRITE_INTEGRITY = TRUSTED.
-
Let's go through some examples of the uses of function-based indexing.
The following example simply shows a full table scan based on a WHERE clause filter on an expression of two columns.
Individual indexes on the QTY and PRICE columns would make no difference to query plan cost. I am creating these indexes to prove the point.
CREATE INDEX xak_sm_qty ON stockmovement(qty) ONLINE COMPUTE STATISTICS; CREATE INDEX xak_sm_price ON stockmovement(price) ONLINE COMPUTE STATISTICS; EXPLAIN PLAN SET statement_id='TEST' FOR SELECT * FROM stockmovement WHERE qty*price = 0; Query Cost Rows Bytes ----------------------------------- ---- ------ ------- SELECT STATEMENT on 404 6456 135576 TABLE ACCESS FULL on STOCKMOVEMENT 404 6456 135576
Let's drop those two indexes.
DROP INDEX xak_sm_qty; DROP INDEX xak_sm_price;
Now let's go ahead and create a function-based index for the expression QTY*PRICE. My database is highly active. Once again I use the ONLINE option of the CREATE INDEX command allowing DML activity against the index during the index creation process. The ONLINE option creates the index elsewhere and copies it to the index file after creation, including any changes during the copying process. Once again the EXPLAIN PLAN command is useless without current statistics generation.
CREATE INDEX xakfb_sm_amount ON stockmovement(qty*price) ONLINE COMPUTE STATISTICS; EXPLAIN PLAN SET statement_id='TEST' FOR SELECT * FROM stockmovement WHERE qty*price = 0;
Notice in the query plan how the newly created function-based index is being range scanned. If the order of the columns in the expression was switched to PRICE*QTY the index would still be used since the function-based index contains the result of the expression. The next example will reverse the order of the QTY and PRICE columns in the expression.
Query Cost Rows Bytes ----------------------------------- ---- ------ ------- SELECT STATEMENT on 5 6456 135576 TABLE ACCESS BY INDEX ROWID on 5 6456 135576 STOCKMOVEMENT INDEX RANGE SCAN on XAKFB_SM_AMOUNT 3 2582
In the following example I have placed the expression into the SELECT statement alone, allowing a full index scan as opposed to a full table scan. Also the order of the QTY and PRICE columns is the reverse of the previous example.
EXPLAIN PLAN SET statement_id='TEST' FOR SELECT price*qty FROM stockmovement; Query Cost Rows Bytes -------------------------------------- ---- ------ ------- SELECT STATEMENT on 382 645604 4519228 INDEX FAST FULL SCAN on XAKFB_SM_AMOUNT 382 645604 4519228
We can also use user-defined functions to create function-based indexes.
CREATE OR REPLACE FUNCTION getAmount( pqty IN INTEGER DEFAULT 0 ,pprice IN FLOAT DEFAULT 0) RETURN NUMBER DETERMINISTIC IS BEGIN RETURN pqty*pprice; END; / ALTER FUNCTION getAmount COMPILE;
Now let's drop and recreate the index again to use the user-defined function.
DROP INDEX xakfb_sm_amount; CREATE INDEX xakfb_sm_amount ON stockmovement(getAmount (qty, price)) ONLINE COMPUTE STATISTICS;
The following query plan should show a fast full index scan of the index created using the user-defined function.
EXPLAIN PLAN SET statement_id='TEST' FOR SELECT getAmount(qty, price) FROM stockmovement; Query Cost Rows Bytes ------------------------------------- ---- ------ ------- 1. SELECT STATEMENT on 561 570298 2851490 2. TABLE ACCESS FULL on STOCKMOVEMENT 561 570298 2851490
We are supposed to be able to use a function in a function-based index. The QTY*PRICE index and function will not be used again so they will be dropped. Leaving unused indexes in the database is bad for performance. Whenever a table is updated all its associated indexes are updated as well.
DROP INDEX xakfb_sm_amount; DROP FUNCTION getAmount;
Function-based indexes can be useful. The biggest danger with function-based indexes is that developers could create a lot of them. It may be best to only create function-based indexes at somewhere between the development and production release cycles. This is especially the case if database administrators are completely uninvolved in the development process, which is often the case.
7.4.5 NULLs and Indexes
What do we need to know about NULL values and indexes? NULL values are not included in indexes except for bitmap indexes. Therefore when using an index against a table where NULL values exist, not only can the index be read ignoring table columns, but also only non-NULL valued rows can be read. Thus reading the index will not only read fewer columns but could potentially read fewer rows as well.
The Transactions table in the Accounts schema is a good example. A type = 'S' transaction will have a NULL SUPPLIER_ID and a TYPE = 'P' transaction will have a NULL CUSTOMER_ID. These are the counts for different row types in the Transactions table.
SELECT t.counter "Transactions", s.counter "Sales" ,p.counter "Purchases", type_S.counter "Type=S" ,type_P.counter "Type=P" FROM (SELECT COUNT(*) as counter FROM transactions) t ,(SELECT COUNT(*) as counter FROM transactions WHERE customer_id IS NOT NULL) s ,(SELECT COUNT(*) as counter FROM transactions WHERE supplier_id IS NOT NULL) p ,(SELECT COUNT(*) as counter FROM transactions WHERE type = 'S') type_S ,(SELECT COUNT(*) as counter FROM transactions WHERE type = 'P') type_P; Transactions Sales Purchases Type=S Type=P ------------ ----- --------- ------ ------ 188199 33158 155041 33158 155041
The CUSTOMER_ID and SUPPLIER_ID columns already have foreign key indexes. I do not have to create any new indexes. Let's use the CUSTOMER_ID column as an example. Note from the previous query result that the Transactions table has a total of 188,199 rows. Now we can force reading the index and demonstrate the resulting much lower number of rows accessed by reading only the non-NULL valued index rows.
EXPLAIN PLAN SET statement_id='TEST' FOR SELECT customer_id FROM transactions WHERE customer_id IS NOT NULL;
We now appear to have read 33,142 rows. The number of rows accessed is much fewer than the total number of rows in the table as expected. However, and quite confusingly so, there are 33,158 non-NULL valued CUSTOMER_ID rows and the fast full index scan reads slightly fewer rows. Why I do not know.
Query Cost Rows Bytes ---------------------------------------- ---- ------ ------- 1. SELECT STATEMENT on 16 33142 66284 2. INDEX FAST FULL SCAN on XFK_T_CUSTOMER 16 33142 66284
One point should be noted. If we want to read the NULL valued CUSTOMER_ID rows from the Transactions table we could change the CUSTOMER_ID column to NOT NULL and add a DEFAULT setting. We could subsequently search the index for the DEFAULT value and get the same result as searching for IS NULL on the table. This would ensure that we never get NULL values in the CUSTOMER_ID column and that a CUSTOMER_ID index can always be used instead of a full table scan. However, why would one ever want to read NULL values? In this case one could simply SELECT using the SUPPLIER_ID column as NOT NULL and get the same result, again reading fewer index entries. If many SQL code statements are accessing tables with IS NULL comparisons, you might want to revisit your data model. IS NULL is a form of a negative comparison condition because you are attempting to find something which is not there. Think about why you are doing something like this. This type of SQL code is consistent with an approach to high usage of outer joins in SQL code. High numbers of outer joins are sometimes indicative of poor data Referential Integrity or perhaps data model structure not providing for application requirements. The same potential indicators are apparent when searching using IS NULL conditions. Once again why would you want to be searching for something which is simply not there?
That covers NULL values and indexing.
So how can BTree indexes be tuned for better performance?
-
Use as few columns as possible.
-
Only index integers if possible, preferably unique integer identifier values.
-
Variations on BTree indexes are reversing index strings, compression and function-based indexes. Each of these variations will generally have very specific applications. They should be used sparingly and carefully.
-
NULL values are not indexed.
|
| < Day Day Up > |
|
EAN: 2147483647
Pages: 164