Chapter 19. Programming Design
| CONTENTS |
- Introduction
- A Practical Example
- The Next Step: Object-Oriented Method and Design
- Procedural Paradigm
- Object-Oriented Paradigm
- Encapsulation
- Inheritance
- Polymorphism
- How to Design for Object-Oriented Languages
Introduction
Programs need to be planned before the actual programming begins. A little planning up front will save time and frustration later.
For beginners, the hardest part is learning to think like a computer. There are a few basic concepts that will help.
First, a computer performs instructions one step at a time. Second, the computer does not have previous knowledge about the problem to be solved. Third, the computer needs to be told everything step by step, and it only knows what you tell it.
All computer programs do the same thing. They instruct a computer to accept data (input), to manipulate the data (process), and to produce reports or information back to a user (output).
So where do you start? Start by answering a few questions.
-
What is the problem to be solved by the computer?
-
How does the output from the program look?
-
What are the logical steps (algorithm) to achieve this output?
-
What inputs are needed?
After you have defined the input, output, and logical steps, take a moment to step through them one by one as if you were the computer. Does it solve the problem? Does it achieve the expected output?
Next, consider how the program will be organized. The importance of organizing a program is not readily apparent for small programs. When it comes to larger programs, it is easy to get lost when trying to understand the logic, find errors, or enhance the code.
Programming logic can be broken into modules, smaller pieces of logic performing one or two functions required by the program, otherwise known as decomposability. Modules are small subprograms, each accepts input, processes data, and produces output. Modules can be arranged in a logical and easy-to-understand order to form a complete program. This capability is referred to as modular programming.
Let's look at an example of designing for modular programming. To design a simple employee weekly pay program, we would have to consider the example in the next section.
A Practical Example
To more fully understand the concept of design and the steps that are required, it is best to use an example. While the problem statement listed below seems like a relatively easy example, we will begin to see certain complexities emerge as we look deeper.
The problem statement below describes a program that will be used to compute weekly gross and net pay. The inputs and expected outputs are listed, along with a few basic high level steps that need to be performed on the input to create the appropriate output. The steps are listed as an algorithm. We will focus much our attention on the steps in the algorithm.
Problem statement: To compute an employee's weekly gross and net pay, deducting before tax medical benefit costs.
| Input: | Employee Name Hourly Pay Rate |
| Output: | Report with Employee's gross and net pay |
Algorithm:
-
Calculate Gross Pay
-
Calculate Net Pay
-
Generate report with Employee Name, gross pay and net pay.
Look at the logical steps in the algorithm. Can one or a combination of them become a subprogram, accepting input, processing data and producing an output? First, let's name each step of the algorithm and try to define the information needed (input) and the resulting information after processing (output) and see whether they qualify as modules:
1. MODULE: Calc_Gross_Pay Description: Calculate one week gross pay Input: Hourly Pay Rate Output: Gross Pay Algorithm: Hourly Pay Rate * 40 2. MODULE: Calc_Net_Pay Description: Calculate net pay, deduct medical benefit costs and taxes Input: Gross Pay Output: Net Pay Algorithm: Calculate medical benefit costs Deduct medical benefits cost from Gross Pay Calculate tax Calculate Net Pay 3. MODULE: Generate_Report Description: Generate report with Employee Name, Gross Pay, and Net Pay Input: Employee Name, gross pay, and net pay Output: Employee weekly earnings statement Algorithm: Format report and print it
Since we can clearly define an input, processing and an output, each algorithm from our problem statement fulfills the requirements of a module.
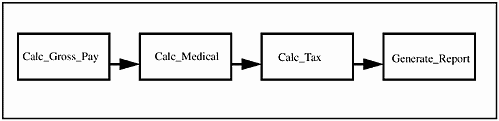
Next, connect the modules so that they logically flow together. This characteristic is known as composability. The arrows show that the output of one module becomes the input to another in Figure 19-1.
Figure 19-1. Module Information Flow

Once we've composed our modules, we need to take a look at each of them. Can any modules be broken down into smaller modules?
Take a look at the module Calc_Net_Pay. This module has the responsibility for calculating medical benefit costs and income tax. The source code to compute this can become long, detailed, and confusing. This module is a candidate for further decomposability.
One possibility is to break this module into two, one to calculate the cost of medical benefits and the other to calculate income tax.
The names for the new modules will be Calc_Medical and Calc_Tax.
The Calc_Medical module needs the information output from Calc_Gross_Pay, because some benefit costs may be a percentage of gross pay. Therefore, the output from Calc_Gross_Pay is an input to Calc_Medical.
Calc_Medical will process this information resulting in the gross pay minus medical benefits since, in this case, medical benefit costs are pre-tax. This becomes the output from Calc_Medical.
This output can now be sent to the Calc_Tax module, allowing for the correct income tax to be computed, as shown in Figure 19-2.
Figure 19-2. Break Module into Two Modules
Remember, design is an iterative process. As you progress from one level of detail into the next, it may become apparent that breaking the logic into more modules will help the clarity and readability of the program.
For example, precise algorithms need to be developed for the medical benefits. We would need to know the types of benefits offered by the employer and how to price them. More detail is needed; therefore, additional design focus should be given to this module. And there is a possibility of breaking up this module into even more modules.
The Calc_Tax module may also be a candidate for more investgation since there are federal, state and local taxes to calculate.
How does this process equate to programming? Each module has a function to perform, and is, in a sense, a mini-program. These mini-programs can be pieced together to create a complete program.
In C language, modules are referred to as functions. Java and C++ have the concept of functions as well, but these languages are object-oriented languages. Therefore, a module may be a class. Classes contain functions, but they also do a lot more, as discussed in the next section.
The Next Step: Object-Oriented Method and Design
If you never plan to program in C++, Java, or any other object- oriented language, then you can skip this section. With that said, let me say that if you plan to take programming seriously at all, explore object-oriented programming. Most feel it is either a revolution in or an evolution of software development. Either way, you are bound to feel its impact.
Our previous definition of modules needs to be stronger when dealing with object-oriented modules. Extendibility, reusability, and reliability are our principal goals.
Extendibility
Because modules are to be designed with reusability in mind, the programmer cannot foresee all the data and operations a module will need in its lifetime. Therefore, the programmer will design the module for possible future changes and extensions. This approach is referred to as Extendibility.
Two principals are key to improving extendibility:
-
Simplicity in Design: A simple architecture can be adapted for changes easier than a complex one.
-
Decentralization: The more autonomous the modules, the better the chances that a change will affect just one or a small number of modules. Modules that have interdependencies throughout an architecture may trigger a chain reaction of change over the whole program.
Reusability
Software elements or modules that can be used for the construction of many different software applications (programs) are referred to as having high reusability.
The need for reusability comes from the observation that software applications frequently follow similar patterns. Many will require the same or similar functionality as found in previously developed software. This should be taken advantage of to reduce the time, effort, and cost associated with software development.
Reliability
Without reliability, our software application would be essentially useless. A few design concepts will help with reliability:
-
Designing for compatibility is designing for ease of combining software elements with others. Frequently there are conflicting assumptions made about the rest of the world.
The key to compatibility lies in design homogeneity and agreeing on standardizing conventions. This may be done within a work group, a corporation, or even a software development community of interest.
For example, a workgroup may agree to extract information only from text files, which contains a sequence of characters, rather than binary files, which are machine-dependent. If part of the work-group develops software on a Windows NT system and another on a UNIX system, there is a greater opportunity for software reuse.
-
Designing with efficiency in mind will minimize the demands on the hardware resources, such as processor time, space occupied in memory, and bandwidth used for communication. If software is designed without consideration for efficiency, it may take too long to run, or use too many resources when executing on a smaller system.
Performance and scalability are important factors in todays programs. By designing with effeciency in mind, your program will run faster, and use less resources. A program incorporating these features in its design will allow more processing to be done with fewer overall resources.
-
If portability is not considered, software may only be useful on one type of computer system. There may be some justified portability issues, but other portability issues may be reconcilable.
Hardware is fast becoming a commodity in today's environment. A program that can run on any hardware platform is ideal. A program requiring minimally impacting changes to run on another hardware platform is less than ideal, but still acceptable.
Portability has impacts and they need to be considered. To make a program 100% portable, performance may be sacrificed. Requiring software changes for portability to minimize the impact to performance will create the need for software testing and more cost for IT staff.
-
Ease of use will help to ensure that anyone using the software can learn to use it and apply it properly in solving problems.
Making software programs intuitive is not necessarily as easy as it sounds. Some IT staffs have designers trained in human interface design. Utilize people with this expertise. If none are available, review your design with others. Since they are less familiar with your design, they may help to point out the obvious.
-
Verifiability means that the software is designed to detect failures, and trace them to errors.
Failures will occur for most programs. They doesn't necessarily have to be due to a flaw with the software. An error could result due to a hardware problem, corrupted information from an external source, or human error. Ensure that your program can handle errors where they are most likely to occur, such aswhen reading or writing to a file.
-
Integrity designed into a software system will allow it to protect itself against unauthorized access and modification.
Security and privacy are big issues today. Be sure the hardware your program is running on is secure from hackers. Include security features in your software where ever possible. This can take the form of login access, hardware or software firewalls, or declaring information private in a C++ object. There are various methods that can be incorporated.
As you learn more about individual languages, you will begin to see how these issues are handled. Each language has its own set of tools; how to apply them will become apparent.
Next let's look at different programming paradigms.
Procedural Paradigm
The original programming paradigm is procedural programming. Procedural programming focuses on what steps are taken to solve a problem. Functions or subprograms are used to create some order in the program. A program consists of a series of functions, and these functions manipulate data.
To understand the procedural approach, let's try an example to see how it might work.
A program is created that maintains an employee's salary and generates a paycheck. First, a structure called EMPLOYEE is created. The structure contains the employee's NAME and SALARY. At some point, we may want to give a raise to the employee. A function is written called IncreasePay(). The EMPLOYEE structure would be passed as input to the function IncreasePay(). The function would increase the salary of the employee and store it in SALARY within the EMPLOYEE structure.
This simple program may cause problems later for the procedural programmer. This program may need enhancements in the future. More information may be included in the EMPLOYEE structure, such as job title, phone number, location, social security number, and so on. Changes or additions made to the EMPLOYEE structure would, in most cases, cause the programmer to make changes in the functions using it.
As programs grow in complexity, so does the ability to maintain and enhance them. In the procedural paradigm, there is no inherent connection exists between data and the functions manipulating the data. In addition, if the behavior of the function needs modification, there is no easy way to do so without rewriting it. For example, if you want to use a more complex method of giving a pay increase, the only way to reuse the existing code is to cut and paste it into a new function.
Problems have become more sophisticated and complex. In today's world, procedural programming is no longer sufficient. A new paradigm called object-oriented becomes necessary.
Object-Oriented Paradigm
Object-oriented languages allow programmers to more closely model the real world by building a strong link between the data structures and methods (functions) that manipulate the data. More importantly, programmers no longer think about data structures and functions to manipulate the data; they think instead of objects.
Object-oriented languages use the concepts of "class" and "object" as the basic building blocks. Because object-oriented programming models how we perceive our world, it can best be explained using a real-world example. Most people know how to drive a car, but do they need to know how to build one to use it? Of course not. There are many things in the world that we are capable of using without knowing anything about how they are built, or implemented. The reason that things are easy to use without knowledge of their implementation is that they are designed for use via a well defined public interface. The interface is dependent upon the implementation, but it hides the complexity of it from the users. The implementation may change, but if the public interface doesn't; users typically don't need to know or care.
If a person purchases a new model of a car he currently owns, he may not care whether the engine has been redesigned. If the new model has more power than the previous model, the user will only notice it when driving the car. The user still knows how to use the car because the public interface has remained the same. If the auto manufacturer decided to implement a braking feature with a knob on the dashboard instead of a pedal on the floor, the purchaser of the car may become quite upset. This is because the public interface changed and the user is no longer familiar with it.
One of the fundamental concepts in object-oriented languages is just this philosophy. All implementation issues should be hidden from their users behind a well-defined, consistent public interface. Users need to know about the interface, but are never allowed to see its implementation.
Most understand what is meant by the term "car," even though one may not be visible. The reason for this is that most of us own or use cars. Cars are a part of our life. We know that all cars are used for travel, and they share certain attributes such as an engine, seats, steering wheel and so on. We have also seen cars that allow us to turn them on and off with a key, accelerate, brake, and turn left and right. Essentially we have the concept, called a car, which captures the notion of data and behavior of all cars. This concept is known as a "class." The physical car in your driveway is an "object"(or instance) of the car class. The relationship between the notion of class and object is called the "instantiation relationship." A car object is said to be instantiated from the car class, while the car class is said to be the generalization of all car objects.
If I said that my coffee table accelerated from 0 to 60 in five seconds, you would think that I was crazy. If I told you that my car did the same thing, you would consider that to be reasonable, if not impressive, behavior. The reason is that the name of a class not only implies a set of attributes, it also gives an indication of the behavior. This relationship between data and behavior is key to the object-oriented paradigm.
Encapsulation
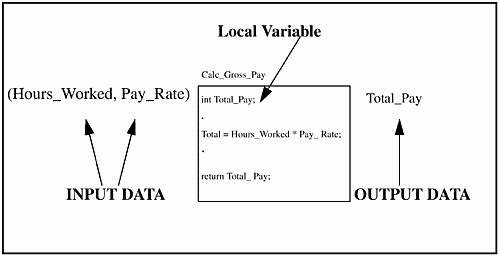
In a procedural language, it is easy to see the data dependencies on a function. To find data dependencies, look for all the data input to, used by, and returned from a function. Variables may be used inside functions. If they are created, used, and destroyed inside the function each time the function is executed, they are referred to as local variables. This relationship is shown in Figure 19-3.
Figure 19-3 Local Variable.
One problem with a procedural language is the ability to find the functional dependencies on a piece of data. Looking for functional dependencies on data means that we must look for every function that uses the data or otherwise depends upon the data. To do this, we must examine all the code, looking for these functions. If we need to change how our data looks or how it is used, this can become a very large and error-prone process. The larger the program, the bigger our problem becomes.
An object-oriented language solves these issues. Both types of dependencies, data dependencies on a function and functional dependencies on data, are readily available. Objects are tightly bound entities. Everything they know about (data) and everything they can do (all their methods) are tied together into a neat bundle. This arrangement is referred to as encapsulation.
Again, working with a program that deals with payroll, a user of an EMPLOYEE class does not need to know or care how the employee pay is stored within the class. All the user cares about is that the Total_Pay can be retrieved for a particular object of type EMPLOYEE. This task could be done with a method called GetPay(). A user could even give a raise to the employee by calling the EMPLOYEE member function GiveARaise().
Both methods, GetPay() and GiveARaise(), are contained in the class EMPLOYEE and are part of EMPLOYEE's public interface. The interface is a contract that EMPLOYEE makes with its users: it tells the users what the class can do. This is shown in Figure 19-4.
Figure 19-4. Encapsulation
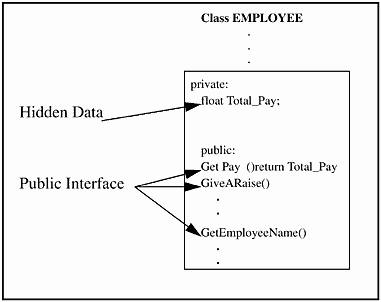
In the example above, the user can ask for or do the following via the public interface of EMPLOYEE:
-
Retrieve the employee name (GetEmployeeName())
-
Give a raise to the employee (GiveARaise())
-
Retrieve the total amount of pay due the employee (GetPay())
A user cannot directly alter or even see the variable Total_Pay in the EMPLOYEE class. It is only accessible via methods in the EMPLOYEE class. Any actions performed on Total_Pay can only be done through the EMPLOYEE class's methods GetPay() and GiveARaise().
Total_Pay is a member variable. A member variable is a variable that is part of a class. If, at a later date, Total_Pay is to be extracted from a database, this can be done without impact to the user. The user does not know from where Total_Pay comes. The internal representation of Total_Pay is invisible to users. This is called information or data hiding, and is a natural outcome of encapsulation. As long as users use the public interface, they are guaranteed access to the private data (via methods), regardless of how it is stored.
Inheritance
Inheritance is one of the more important relationships within object-oriented languages. It is best captured as "a-kind-of" relationship between classes. An example is that a FordTaurus is a-kind-of car. Or the relationship can be hierarchical in nature, as in A Dog is a-kind-of Animal, a Dalmatian is a-kind-of Dog. Its primary purpose is twofold: it allows expression of commonality between two classes (generalization), and it is used to indicate that one class is a special type of another class (specialization).
Usually in the first version of software, designers will attempt to generalize. Designers will decide that two or more classes have something in common, such as data, behavior, or a common interface. Typically, this information is collected and put in a more general class from which these classes can inherit.
For example, if I have a Dalmatian class and a Dachshund class, there are some obvious common traits and there are some obvious differences, as shown in Figure 19-5.
Figure 19-5. Common Traits and Differences
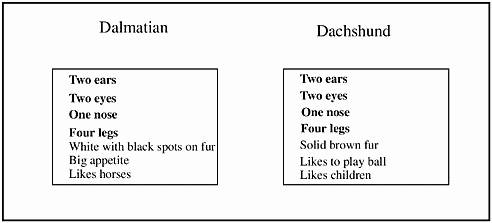
These are two very different breeds of dog, but they have the attributes of a dog in common, such as two ears, two eyes, one nose, and four legs. We can take these attributes and put them in a separate class called Dog, allowing the Dalmatian and Dachshund classes to inherent these common attributes.
Specialization, on the other hand, is more prevalent after generalized classes have been decided upon or a mature program requires modification. As the design evolves, the programmer realizes that some classes will require special treatment. Inheritance is ideal for implementing these cases.
A class called Dog may be too general for a user's needs. What may be needed is a special kind of dog, perhaps a search and rescue dog, a hunting dog, a show dog, or a dog of a certain breed. Specialization allows us to start with a generic class and use it as part of a new class through inheritance. The new class can be customized to meet specific needs.
Inheritance is referred to as the reusability mechanism because it helps adapt standard components into specific areas of the software.
To understand inheritance, we need to understand some terms. If a class inherits from another class, it is referred to as a subclass or derived class. If a class is inherited by another class, it is referred to as a superclass or base class.
Figure 19-6 is a graphical view of the inheritance of data.
Figure 19-6. Inheritance of Data
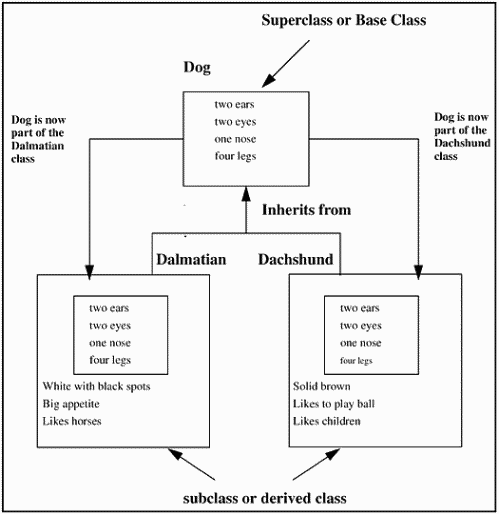
The class Dog is the base class. Both the Dalmatian and Dachshund classes inherit from the class Dog. There exists a set of common attributes to describe a dog, and it is expressed once in class Dog. Any class that is intended to be of type dog, but is more than just a generic dog, can inherit from the base class Dog and add attributes to create a special kind of dog.
Inheritance is a better way to reuse code. You reuse code by creating a new class, but instead of rebuilding all the logic, you integrate classes that have already been built and debugged. It is certainly better than cutting and pasting source code.
Polymorphism
Polymorphism is an essential feature in object-oriented languages. With polymorphism, a developer can allow a class to be extensible or grown not only during its initial creation, but also when new features are necessary.
If a class is built to deal with dogs, the developer will more than likely miss specifying some types of dogs required by future users of the class.
Classes can be designed in a way that the actual type of dog is dealt with at the time of execution (loose coupling) instead of at compile time. This means that the base class of Dog is not written with any specific type of dog in mind. The base class deals with the generic aspect of all Dogs. The original writer of the base class does not know what type of dogs are needed by the user, nor does he care. Loose coupling allows us to deal with a "virtual" dog, a dog of no specific type until the type of dog is determined at a later date by a user of the base class.
For example, let's say that each type of dog has its own special bark. As the developer of the base class called Dog, I want the class to handle any type of dog and its bark. So when someone using my class tells the dog to bark(), they don't have to worry about telling my base class of Dog what type of dog is going to bark(). They just ask the Dog to bark(), which is like saying "Hey, dog, bark." They don't have to say "Hey, Dalmatian, bark."
But if the user of my base class just tells the Dog to bark(), Istill want the right bark() for that type of Dog. If I have a virtual bark() method in my base class of Dog, I am not giving the details of any specific bark()s. After the base class has been developed and debugged, I can make it available to anyone for use. A user of my base class can inherit it to create a new, derived class. The derived class may be for a specific type of Dog, say a Jack Russell Terrier Show Dog. The derived class developer knows what type of dog it is designed to be and how that Dog's bark() sounds. Because the derived class is familiar with the bark() specifics, it will provide the details.
Each derived class will know what type of dog they are dealing with and what the bark() sounds like. When they ask the class Dog for a bark(), the "virtual" bark() in the base class is replaced with the specific bark() from the derived class and the correct one is used. Such a program is extensable because you can add new functionality through inheritance without modifying the base class.
If the example was implemented without polymorphism, the base class developer would have to consider every type of dog needed, both now and in the future. Let's say that I built the base class Dog to handle a Dalmatian, a Jack Russell Terrier, and a Labrador Retriever. If I ask for a bark(), I have to think about what type of dog I'm asking to bark(). I can't just ask the Dog class to bark(); it may give the wrong bark(). If I want a Poodle to bark() and Poodle is not part of the class, the class would have to be edited to include Poodle information, recompiled and retested. This class is not extensible. It is not reusable when the type of dog requested isn't already part of the class.
This may be confusing, but the concept of polymorphism is usually described with C++ examples and terminology. It becomes clearer once you learn more about the C++ programming language.
How to Design for Object-Oriented Languages
You need to remain focused on what you want the system to do. To collect this type of information, try use cases. Ask the question "What does the system do if...". For example, what would a payroll system do if today was the last day of the month? Use-cases describe what actions the system (program) will take when a specific event occurs.
Use-cases will identify some key aspects of your program that will identify some of the fundamental classes to be created.
Describe what the classes will look like and how they will interact. Write down for each class:
-
The name of the class. Make it descriptive, so that when referring to it later, you will have an idea of what the class does.
-
The responsibilities or what a class should do. Write down the names of member functions, such as GetPay() or GiveARaise().
-
The collaboration or with what other classes it interacts.
You may not find all the classes or determine all the interactions and responsibilities. More will be discovered as the design process progresses.
The design phase of an object is not limited to the time when the program is being written. Instead, the design happens over a series of stages. You don't need to strive for perfection immediately, instead understanding what an object does and what it should looks like happens over a period of time. The key stages where your understanding may evolve are listed below. These stages are summarized from Bruce Eckel's book, Thinking in C++.
-
During the initial analysis of a program, objects may be discovered by examination of external factors and boundaries. Looking for duplications of elements within the program, and smaller logical units or modules may reveal more objects.
-
While building an object, the need for new objects may become apparent. Internal functionality of the object may require new classes.
-
When pulling together classes and constructing the program, you may discover more requirements for objects. Communication and interconnection of objects in the program may require new classes or changes in existing classes.
-
Adding new features to a completed program may reveal inadequacies in the previous design. Extending the existing program may very possibly require the addition of new classes.
-
Object reuse is a true indication of completeness in class design. If the class is reused in an entirely new situation, some shortcomings may occur.
Design is not an exact science; it is more of an evolution. Expect and be open to improvements in design. It becomes apparent, given the list above, that object design continues and evolves throughout the lifecycle of the class.
| CONTENTS |
EAN: 2147483647
Pages: 34