XML Data
| < Day Day Up > |
| Hierarchical data comes in many forms. As noted before, the index and table of contents of this book are largely hierarchical. Many methods of representing this kind of data structure have been developed over the years . The most common one in use now is called eXtensible Markup Language or XML . XML is a format developed by the World Wide Web Consortium (W3C). It consists of a text document . Inside of that document are a series of elements , nested within each other. There is one element that encompasses the entire document called the root element . Each element is enclosed in a pair of tags ”empty elements can be represented by a single start-and-end tag. Elements can have attributes , which are indicated in the opening tag. A sample XML document is shown in Figure 19.2. Figure 19.2. A marked -up XML document.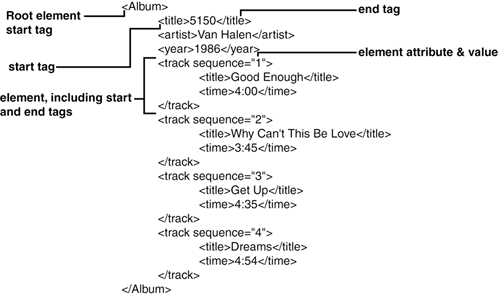 By the Way This is a drastically simplified description of XML, but it will suffice for your purposes. If you want all the details, visit the W3C's web site at http://www.w3.org. XML documents are used for all kinds of data interchange. RSS feeds from blogs use XML as a data representation method, commercial databases can return results in XML format, Google can be queried in XML, and even Microsoft Office products can store data as XML documents. XML has become the lingua franca of data interchange since the late 1990s. Because of this widespread use, there are hundreds of toolkits and methods for creating, reading, and modifying XML data. You'll learn the most common two. Reading XML Using Regular ExpressionsXML documents, like any other kind of text, can be processed by regular expressions ”almost. For example, take the document in Figure 19.2. If it were saved in a disk file, you could open it and display the album title rather easily as shown in Listing 19.5. Listing 19.5. Reading the XML File, Almost 1: open(A, "album.xml") die "Can't open album.xml: $!"; 2: while(<A>) { 3: if (/<title>(.*)<\/title>/) { 4: print ; 5: } 6: } 7: close(A); However, this doesn't quite work. Instead of seeing "5150," which is the name of the album, you'd see this: 5150Good EnoughWhy Can't This Be LoveGet UpDreams This isn't quite what you wanted. The script picked up every instance of <title> and interpreted that as the album title. Could the script be fixed? Sure, you could exit after you've seen the first title, as shown in Listing 19.6. Listing 19.6. Still Flawed XML Reading 1: open(A, "album.xml") die "Can't open album.xml: $!"; 2: while(<A>) { 3: if (/<title>(.*)<\/title>/) { 4: print ; 5: exit; 6: } 7: } 8: close(A); This is closer, and would yield the correct results of "5150." On the surface, you've solved your XML parsing problem. Except that you really haven't. Depending on the document, the order or elements or attributes might not be important. Whitespace might not be important. So your album XML file might be validly represented like Listing 19.7. Listing 19.7. The Album XML document, re-arranged.<?xml version="1.0" encoding="UTF-8"?> <Album> <track sequence="1"><time>4:00</time> <title>Good Enough</title></track><track sequence="4"><title>Dreams</title> <time>4:54</time></track> <track sequence="2"><title>Why Can't This Be Love</title> <time>3:45</time></track> <track sequence="3"><title>Get Up</title> <time>4:35</time></track> <title>5150</title><artist>Van Halen</artist><year>1986</year> </Album> Now your "working" XML reader generates this for an album title: Good Enough</title></track><track sequence="4"><title>Dreams Not even close. Why didn't this work? The regular expression /<title>(.*)<\/title>/ matched everything between the <title> tags. In the case of Listing 19.7 the first <title> tag shown belongs to the first tracks and the last </title> tag actually belongs to the track 4 disk on the same line of the input. Could you fix this? In this specific case, yes. Listing 19.8 solves the problem in a different way. Listing 19.8. Even More Convoluted XML Parse in Regular Expressions 1: open(X, "album.xml") die "Can't open album.xml: $!"; 2: { 3: local $/=undef; 4: $_=<X>; 5: } 6: close(X); 7: s/<track.*<\/track>//gs; 8: if (! m<title>(.*?)</title>) { 9: print "No match"; 10: exit; 11: } 12: print ;
So to parse this XML document, you had to completely wreck the data. For a small document, or a task that's not going to be done very often, this inefficiency may be just fine. But it demonstrates that trying to handle XML using just regular expressions is an arms race that you'll eventually lose. By the Way Think you can come up with a general-purpose method for using regular expressions in XML? Think again. Consider that XML can include comments and the comment contents can look just like the surrounding XML but should be ignored; XML can also contain CDATA sections that contain arbitrary data that might or might not look like XML. Combine that with the order-of-elements problem you just explored, the fact that attribute tag order is never important, entity encodings, and that regular expressions can parse non “well- formed XML documents (which aren't really XML), and you'll realize that you just can't win. Reading XML with XML::SimpleThere are dozens of XML parsers for Perl, in two or three different styles. You're going to focus on XML::Simple because it's the easiest to use, and you don't need a thorough understanding of how parsers work to use it effectively. To parse the album.xml document found in Figure 19.2, use the program shown in Listing 19.9. This program also contains some code to dump the resulting parse out for explanatory purposes. Listing 19.9. Sample Using XML::Simple to Parse Your Album Document 1: use XML::Simple; 2: use Data::Dumper; 3: 4: my $ref = XMLin("./album.xml"); 5: 6: print Dumper $ref; The XMLin function takes a file and reads it, parsing the XML. It returns a reference to a structure that mirrors the XML file's structure and contents. If you recall from Hour 13, "References and Structures," the Data::Dumper module can be used to dump a reference structure. In this case the result of the program would be the following: $VAR1 = { 'track' => [ { 'title' => 'Good Enough', 'sequence' => '1', 'time' => '4:00' }, { 'title' => 'Why Can\'t This Be Love', 'sequence' => '2', 'time' => '3:45' }, { 'title' => 'Get Up', 'sequence' => '3', 'time' => '4:35' }, {'title' => 'Dreams', 'sequence' => '4', 'time' => '4:54' } ], 'artist' => 'Van Halen', 'title' => '5150', 'year' => '1986' }; Each top-level element in the XML structure became a key in a hash. To get to the album title, simply use $ref->{title} . Where more than one element would have the same key ( TRack ), XML::Simple produced an array of hashes. The first track's title would be referenced as $ref->{track}->[0]->{title} . Example: Extending Your Ordering System for XML InputAs a final example this hour, suppose that your largest customer, BikeCo, would like to send you orders in bulk. Their standard data interchange format is an XML document that looks like Listing 19.10. Listing 19.10. Bulk Order Sample Document<order> <po number="1123110"> <part number="35-88123" quantity="100"/> <part number="35-11221" quantity="34"/> <part number="35-12314" quantity="66"/> </po> <po number="0012231"> <part number="16-00112" quantity="40"/> <part number="16-19921" quantity="40"/> </po> </order> Looking at your sample, it appears as though there's a root element called order with one or more purchase orders in it. Each purchase order for this company contains parts and quantities . Because you know who the customer is ”BikeCo ”you won't need the address or credit card information in the file itself; you can generate that on your own. You'll save the PO number because it might be important for the order. A function to read this bulk order XML file and create order documents as you did earlier this hour is shown in Listing 19.11. Listing 19.11. Reading Orders in Bulk Using XML 1: use XML::Simple; 2: 3: sub bulk_order { 4: my($orderfile)=@_; 5: 6: my $xml = XMLin($orderfile); 7: 8: my @orders; 9: if (ref $xml->{po} ne "ARRAY") { 10: $xml->{po} = [ $xml->{po} ]; 11: } 12: foreach my $po ( @{ $xml->{po} } ) { 13: 14: my @items; 15: if (ref $po->{part} ne "ARRAY") { 16: $po->{part} = [ $po->{part} ]; 17: } 18: foreach my $part (@ { $po->{part} } ) { 19: push(@items, [ $part->{number}, $part->{quantity} ] ); 20: } 21: 22: push @orders, 23: { name => 'BikeCo', 24: addr1 => '1 Hippodrome Ln', addr2 => '', 25: city => 'Flint', state => 'MI', 26: zip => 48506, 27: card => 'PO #', cardno => $po->{number}, 28: expires => '', 29: items => \@items 30: } 31: } 32: return @orders; 33: }
To use this new function, you'd have to program something like Listing 19.12. Listing 19.12. Using the Bulk Order Function 1: my @orders = bulk_order("./bulkorder.xml"); 2: foreach my $order (@orders) { 3: add_descriptions($order); 4: print_order($order); 5: } Unlike the read_order function presented earlier, bulk_order returns an array of orders. The items in the array are selected one at a time, the descriptions are added to the items, and then they're printed. |
| < Day Day Up > |
EAN: 2147483647
Pages: 241