NFR Security
NFR Security was founded in 1996 by Marcus Ranum, a pioneer in IDS technology called Network Flight Recorder or NFR. As of 2003 NFR has been renamed to NFR Security, Inc., and the procuct line has been renamed to Sentivist Intelligent Intrusion Manager. The NFR software differs from most other products, as it provides analysis of data starting at the packet level as a sniffer would, and then it provides stateful packet inspection (misuse detection) and protocol anomaly detection using a scriptable open source language called N-Code. NFR can operate as a true IDS hybrid solution, inspecting everything in the OSI reference model from layer 2 protocols (Ethernet 802.1-based packets) up to layer 7 applications.
NFR Detection Methodology
The meaning of stateful packet inspection and protocol anomaly detection is highly misunderstood. Most of the confusion arises from the notion that examining TCP header information will provide sufficient information to successfully detect an attack. In fact, it is necessary to buffer the entire connection, including the headers and bodies of the messages transmitted, to truly identify what is happening in a connection, and most IDS products fail in that respect. Solutions that do not guarantee that data is reassembled (defragmented) correctly have an almost impossible time ensuring the correctness of the originating data.
NFR’s methodology is focused on achieving data correctness during the capture and decoding of packets. NFR provides a two-layer detection mechanism, shown in Figure 11-1. The lower layer is a high-speed engine with advanced buffering techniques that ensures proper state is maintained in packet transactions, data is correctly defragmented, and entire message bodies are recorded and reassembled in sequence for accurate detection and analysis. The upper layer provides a scriptable detection language. N-Code is a unique detection language that provides a rapid signature-development platform for intrusion detection.
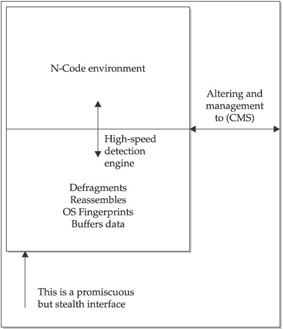
Figure 11-1: Two-layer detection mechanism
NFR Architecture
The Sentivist product operates in a three-tier environment, consisting of the sensors, a Central Management System (CMS), and an Administrative Interface (AI), as shown in Figure 11-2.
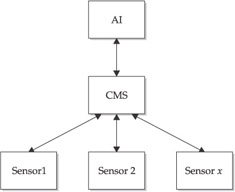
Figure 11-2: AI GUI Interfaces
Sentivist Sensor
The Sentivist sensors are passive devices that collect data on the wire. The sensors provide detection capabilities from <10 MB/s connection rates through Gig speeds, using multiple network connections per single sensor. NFR’s sensors are 1-unit high rack-mountable appliances. The sensor software boots off their CD-ROM, which contains a custom written OS boot code for the sensors’ operation.
Sentivist Central Management System CMS
The collection point or Central Management System provides a single collection/aggregation point for data collected by the sensors. The data spooled on the sensors are pushed into a proprietary data file store located on the CMS. The Many to one relationship provides for 20 to 30 sensors push of alerts and forensics data to the CMS.
CMS also provides for a multifaceted Output mechanism. The CMS can provide data via any scriptable data format (such as shell scripts, or perl programs) or via the AI.
Administrative Interface (AI)
The AI is a Windows 32 program that provides a GUI interface to the alerts, forensics, and controls of the Sentivist environment. The AI allows you to select and set up the sensors’ detection capabilities, to monitor alerts and events collected by the sensors in real time, and to query supporting data collected by the sensors. All management of the IDS environment can be done via the AI.
Sentivist Signatures
One of the most unique characteristics of the Sentivist system is its attack signature model. Unlike other systems that rely on either Snort-based signatures, or closed proprietary signature models, NFR’s Sentivist provides an open signature format. The signature library permits true hybrid detection capabilities within the N-Code language. Much like Perl, N-Code provides the flexibility of a true lexical language for exploring traffic streams in real time.
The following function illustrates N-Code’s lexicon. In the example, we are looking at an excerpt that will record the time, IP source, source port, IP destination, destination port, and the source’s operating system if the real-time datastream being monitored is a returning device (that is, if it has been seen before and is stored in the $same_host[$hostarray] array).
func detect_os {
$os_type = (tcp.connSrcOS); # will return a OS id string of the source #operating system seen in the current connection.
If ($same_host[$hostarray] = $current_host){ #Let's check and see if we #have seen this host before? Same host is an array element and current host is #the host detected this session, the values are defined elsewhere in the code.
If ("$same_host[$osarray]" eq "$os_type" ){ #Same host, is it the #same operating system? If it is then let's save the information.
record attack:CURRENT_TIME, tcp.connsrc, tcp.connsport, tcp.conndst, tcp.conndport, $os_type, "Returning system";
#we record the information including source and destination IP and port #information, along with the selected operating system.
$osarray++;
}
$hostarray++;
}
N-Code provides Sentivist with the capability to analyze data from any OSI layer including the application layer. Here are some samples of data types that N-Code can analyze.
- MAC information In N-Code this is an eth.blob, which collects any 803 packets and all the payload
- IP-based traffic In N-Code this is an ip.blob, which looks at the IP segment of the stack and its payload
- TCP, UDP, and ICMP traffic N-Code calls this udp.blob, and this collects the UDP segment and its payload
- Established TCP connections In N-Code this is a tcp.connSym, which collects a complete TCP session
N-Code can also delve into the payload of most protocols, such as HTTP, FTP, POP, SMTP, and so on, and then can look at the payload of the actual application within the session. We will look at some of the signatures offered by NFR’s Rapid Response Team (RRT), a group dedicated to and responsible for the creation of the detection signatures in the “Sentivist Deployment Strategy” section of this chapter.
Organization of Signatures
Out of the box, Sentivist’s sensors provide a clean detection canvas because no signatures are loaded. Once a sensor is plugged in and configured, a sensor examines all traffic but does not start to analyze the data until the first time N-Code packages or backends are uploaded from the CMS. (NFR refers to signatures as backends.)
Sentivist provides signatures that are ordered in a hierarchy. Figure 11-3 shows a screen shot of the file hierarchy from the AI. Packages are parent groups that contain similar signatures or backends. A single package can contain multiple backends, such as the web package called “WWW,” which contains signatures related to web-based activity. “IIS Attacks” is a backend belonging to the WWW package, since IIS is a web-based application. Frequently the parent package will do some form of logical operation and will pass parameters off to the signature. For the WWW package, all state activity is maintained in the root package, so if a Code Red attack is detected, HTTP state will be established, and maintained by the WWW root package. The WWW backend will recognize that a web session was established, and that the content of the web session meets the criteria IIS based traffic passing parameters to the IIS signature, so that the actual IIS signature can detect the Code Red worm.
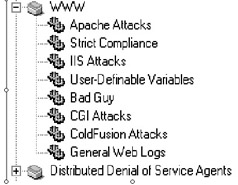
Figure 11-3: Sentivist AI package selection
A State Model in N Code
Sentivist can maintain state and execute anomaly-detection N-Code packages. The RRT (Rapid Response Team) has successfully crafted packages that maintain state and anomaly detection for several protocols, such as Web (based on RFCs such as 1945 and 2616 defining HTTP 1.x), POP, SMTP, and so on. This means that all ISO-based activity that requires state and anomaly intelligence is done by the package.
Once data has been reassembled and sorted, it is typically passed off to an application-based backend, such as the IIS Attacks backend in the WWW package. The IIS Attacks backend will then parse and alert on attacks that are relevant to the particular server type. Providing a granular means of analyzing data also makes it easier to deal with false positives when they occur. For instance, in a network environment that has no Apache servers serving as web servers, the package can be configured to alert only on IIS-based attacks.
Alerts and Forensics
N-Code provides two primary forms of data collection: alerts and record statements. It is important to understand their purpose.
Alerts
As we see in the following, both examples refer to ALERT_ID 27-64, which is the Code Red Worm event. The alert ID is assigned by the RRT as a unique event identifier. Let’s look at the alert’s details in the AI Figure 11-4 and examine the associated N-Code that generated the event in Figure 11-5.
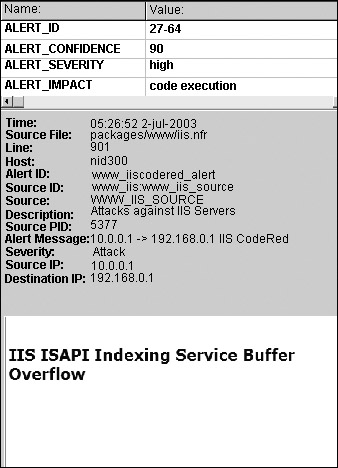
Figure 11-4: Alert Detail from the AI
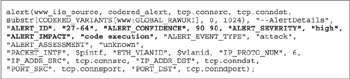
Figure 11-5: The alert statement in N-Code
We can see the components of the N-Code displayed in the AI with all the appropriate fields completed. We can the particulars of the Alert ID 27-64 with a Alert Confidence of 90, Alert Severity High, and Alert Impact as a code execution. Let us look at the components that make up the alert data type in more detail.
- ALERT_CONFIDENCE Indicates the level of confidence that this is a true attack by using a value ranging from 0 to 100. This value can be changed on the fly by N-Code if correlating evidence mandates that it be lower or higher.
- ALERT_SEVERITY Indicates how severe the attack would be if it succeeds—this can have values of LOW, MEDIUM, or HIGH.
- ALERT_IMPACT Provides a text string describing the impact that the attack would have on a system if successful. For Code Red, success means that code can be arbitrarily executed on the host.
- ALERT_EVENT_TYPE Provides a string that defines the type of attack, such as “informational” for scans, or “attack” for attacks.
- PACKET_INTF Displays the interface that the event was detected on.
- ETH_VLANID Provides information about the virtual LAN (VLAN), as per the IEEE VLAN ID standard. This information would be available if VLAN ID information was enabled within the network segment.
- IP_PROT_NUM Provides the protocol information.
- IP_ADDR_SRC and IP_ADDR_DST Displays source and destination IP address information.
- PORT_SRC and PORT_DST Displays the associated source and destination ports.
Record Statements (Forensics)
In addition to the alert statements Sentivist provides a means to collect forensics data associated with an alert. This data is called a query and is accessible in the AI interface in packages. The data is collected by an N-Code statement called a record. The record statement permits Sentivist to extend its ability to analyze data that is provided in an alert. The query data is available via the AI. In fact, the content of a query consists of supplemental forensics data that is representative of the particular alert being examined. The supplemental information is available for all of the signatures provided by NFR.
Following the information in the CodeRed alert shown in Figure 11-4 we see the supporting forensics data that was recorded for the Code Red alert event in Figure 11-6. This was a result of running a query in the AI for CodeRed, which executed the following N-Code to generate the results.
record www:CURRENT_TIME, tcp.connsrc, tcp.connsport, tcp.conndst, tcp.conndport,…

Figure 11-6: Query result
This record statement is not the entire signature for detecting the CodeRed Worm, nor does an operator of the AI require to see or modify the signature during operation. This information is provided to illustrate how N-Code is executed to achieve results.
This record statement is not the entire signature for detecting the Code Red worm. In fact, the signature examines the whole HTTP state, both client and server side session is checked for correct state and ensures no hidden content exists in the traffic. The www signature identifies the Code red worm as it assembles the client request to the server during the initial connection and GET request. This is only a short excerpt from a complex signature (state engine) written to maintain web transactions of all kinds.
| Note |
You can read more about N-Code in the resources provided by NFR: https://support.nfr.com/nid-v3/nde/docs/Customizing_NFR_NID_Sensor_Using_N-Code.pdf. |
Cool Things You Can Do with N Code
N-Code is a very flexible language. It allows you to explore the realm that traditionally only network sniffers used to address, and it offers you the flexibility of writing your own detection conditions.
For example, NFR could be used to identify all devices that are performing port address translation (PAT) that are present on your network. This could be accomplished by collecting MAC addresses and matching them to IP addresses—when multiple MAC addresses are associated to a single IP, you could then trigger an alert.
NFR could also be used to detect certain protocol behavior. For instance, if you want to see whether a particular port is used during certain times of the day, such as port 31,337 after 6 P.M., you could use N-Code to generate an alert. The possibilities are truly endless, and it only requires short development efforts to explore N-Code’s capabilities.
Central Management Server
The Central Management Server provides a central repository for all data collected, and it is a central point for managing the sensors, but it also provides for direct manipulation of events within the CMS environment.
The CMS runs as a client application on either Sun Solaris or Linux. By default, the CMS is installed into the /usr/local/nfr directory, as shown in Figure 11-7, and it is recommended that /usr/local/nfr receive a dedicated partition, or potentially a dedicated drive.
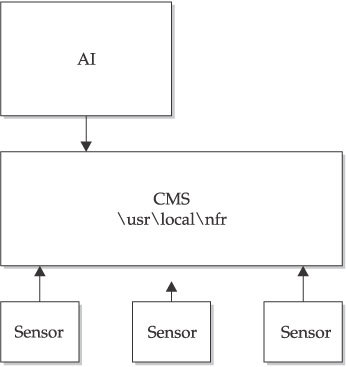
Figure 11-7: /usr/local/nfr directory
The amount of space required will depend on how much date needs to be stored. Space usage is dependent on the number of sensors, the number of backends loaded, and the length of time the data is to be saved. A 30GB hard drive is a good starting point. Further information on installation can be found at the NFR web site.
Starting Sentivist
Sentivist runs a collection service on the CMS that will pool information from sensors and distribute backend signatures, variables, and updates to sensors. Once installed, start the Sentivist services by executing ./nfrstart.sh start. This will start Sentivist on the CMS.
This startup process can be automated by setting up a self-demonizing program:
Command -> Chkconfig –add nfr Result --- nfr 0:off 1:off 2:on 3:on 4:on 5:on 6:off
Sentivist Services
The best way to explore Sentivist CMS is to see it operating, so we will examine some of the key services that Sentivist runs on the CMS. Other processes do exist, but will not be examined in depth.
These CMS services can be observed by running ps –fu nfr. On doing so, the first thing we see is that all nfr daemons run as the user that was selected during installation, which in our case is nfr (as listed in the UID column). This is the default.
UID PID PPID C STIME TTY TIME CMD nfr 21849 1 0 11:45 ? 00:00:00 bin/nfrwatch nfr 21852 21849 0 11:45 ? 00:00:00 bin/alertd nfr 21854 21849 0 11:45 ? 00:00:00 bin/getserver nfr 21856 21849 0 11:45 ? 00:00:00 bin/guisrv nfr 21857 21849 0 11:45 ? 00:00:00 bin/remotestatd nfr 21858 21849 0 11:45 ? 00:00:00 bin/spaceman
Let’s look at the running services:
- bin/nfrwatch The nfrwatch daemon maintains the operational status of all the Sentivist services that are running. If any of the services get hung up, nfrwatch will terminate them and recover the service.
- bin/alertd The alertd daemon will collect and queue alerts as presented by the sensors. Alertd will also execute the rule that an alert is expected to execute.
- bin/guisrv The guisrv daemon is a listener waiting for AI connections. It is very much like a tty daemon.
- bin/remotestatd This daemon collects statistics from the sensors—when a sensor pushes up stats, the remotestatd daemon will parse and display the information.
- bin/spaceman This daemon monitors and maintains the space allocation. A space computation is executed when the Sentivist services are first started, running an internalized program called space_compute, its purpose is to allocate the space required for the CMS to operate correctly.
There are other important services that are not listed in the ps excerpt that can be invoked by NFR when needed or invoked manually: bin/run_mirror and bin/get.
bin/run_mirror
This binary provides for the sensors and CMS to be synchronized. The mirror function will synchronize or mirror signatures and variables to all or selected sensors. This can be executed manually by running the binary from a command line.
- bin/run_mirror This will execute a mirror to all sensors.
- bin/run_mirror -x [device_name] This will mirror only to the host selected
For example, the following script will allow a user to monitor the status of the mirror: Users can execute the following command to see the process of a mirror occur, the purpose of the mirror will give insight into the services running on the Sentivist CMS.
do while true; ps –fu nfr; sleep 3; clear; done;
While this script is running, you will see the packages and backends copy out to the sensors in the process list. Once the mirror finishes copying files to a sensor, a sensor synchronization stage occurs. During this time, the sensor is compiling the signatures to byte code, and it will start using the newly loaded signatures immediately.
bin/get -n [nid name] -s [filename]
This binary provides the CMS with the means to collect information and system files from the sensors. The binary can provide an extensive capability to collect information from sensors directly. The following components can be accessed via bin/get from the sensor. From sy/ : sample usage would be sy/ipaddr0 or sy/ntpkey.
- sy/ipaddr0
- sy/license
- sy/netmask0
- sy/ntphost1
- sy/ntphost2
- sy/ntpkey
- sy/ntpkeynum
- sy/admin_pass
- sy/admin_pass2
- sy/crypto
- sy/crypto2
- sy/defroute
- sy/hostname
- sy/iface0
- sy/ip_central
- sy/ip_central2
For example, bin/get –n [NID name] –s sy/hostname will return the name of the sensor. Here is an example:
>bin/get -n nid300 -s sy/hostname nid300
Additionally bin/get provides a means to execute diagnostics on a sensor by executing bin/get –n [NID name] –x exec_sys_info.
Here’s an example:
>bin/get -n nid300 -x exec_sysinfo /release -------- NID-315 3.2 CD Copyright (c) 1996-2003, NFR Security, Inc. NFR Security, Inc. http://www.nfr.com /hostname ----------- nid300 etc/patch_info -------------- 756 0 Network interfaces (ifconfig) ----------------------------- fxp0: flags=8843 mtu 1500 inet 10.0.0.8 netmask 0xffffff00 broadcast 10.0.0.255 ether 00:02:b3:87:f9:b4 media: Ethernet autoselect (100baseTX) status: active fxp1: flags=9943 mtu 1500 ether 00:20:ed:11:01:06 media: Ethernet autoselect (100baseTX) status: active fxp2: flags=9943 mtu 1500 ether 00:20:ed:11:01:07 media: Ethernet autoselect (10baseT/UTP) status: active lo0: flags=8049 mtu 16384 inet 127.0.0.1 netmask 0xff000000
In this example, exec_sysinfo returned information from the sensor, including version info and an ifconfig equivalent showing the state of the interfaces on the sensor.
Sentivist Deployment Strategy
Deploying Sentivist IDS is relatively simple and designed to be done quickly. However, the second step is tuning and configuring, and this is by far the most important step for successful upkeep of any IDS product.
Sensor deployment for Sentivist follows the same general principal as for all IDSs— covering network elements from the inside out will provide for more thorough protection. Sentivist signature elements can be selected for each sensor based on the sensor’s placement.
Sentivist provides several system-wide variables and backends. These enable the sensors to be aware of their surroundings:
- my_network A list of network devices (provided in either dot notation or CIDR (Classless Inter-Domain Routing block) that includes the network segments owned by the internal network and network segments that are behind or are monitored by the sensor. Multiple entries can be made for this variable.
- Broadcast_addrs The broadcast address of the network elements that are watched by the sensor. Multiple entries can be made for this variable.
The following discussions will look at basic placement principals and consider what signatures would be best suited for each sensor’s respective environment. The discussion of where to place backends and signatures will also provide some insight into their use. Note that the placement of backends in these particular cases are not to be considered universal solutions—they are simply the best solution for the case.
Case Study: Web Farm
A web farm is a high-speed network segment that is populated by web-based servers. In this case, the firewalls are considered secured as per the manufacturer of the solution, up and provide no access outside of the web-based applications required to run a web server. These servers provide web transactions, such as HTTP (on port 80) and HTTPS (on port 443) services. Additionally, management services such as Simple Network Management Protocol (SNMP) and ICMP are permitted in order to manage the web farm devices.
For this case, see the Web Farm sample illustration, the following core backends would be necessary:
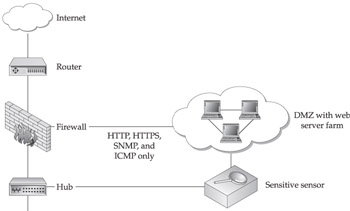
- WWW backend This backend covers all the key elements of NFR's web-based stateful detection capabilities. It provides for thorough examination of HTTP traffic, as defined by RFCs on HTTP traffic types. Besides detecting web-based attacks, this backend can also be used for logging web traffic. This backend can be tuned by changing its associated variables, such as these:
- WWW servers This variable should be populated with known web servers that are active on the network.
- WWW ports This variable provides for additional ports to be monitored for web-based traffic.
- IIS attacks Setting this variable to 1 will cause the backend to watch specifically for IIS servers listed in the WWW servers list.
- Apache attacks Setting this variable to 1 will cause the backend to watch specifically for Apache attacks against the list in WWW servers.
- SSH monitor package SSH is frequently used to manage all non-Microsoft devices. Additionally SSH has been exploited in the past. Monitoring the SSH negotiations and version numbers is valuable for any administrator.
Here are some additional signatures that could be used for this case:
- Authentication backend This backend can be useful for network administrators who need to keep an eye on weak passwords and potential breach attempts based on password hacks. This is an excellent policy-control backend that allows for monitoring password strength and whether they are passed in cleartext or are encrypted. This backend relies on other backends, since it does very little password detection itself. It relies on backends such as POP, SMTP, WWW, FTP, and Telnet. These backends actually trigger the Authentication backend when a usernameand password combination is seen in their respective backends. Several policy-driven variables can be set in this backend, such as a dictionary ook-up to check for common usernames and passwords. Here are a couple of other variables that can be set in this backend:
- RECORD_PASSWORDS Can be set to record passwords in the clear.
- MIN_PASSWORD_LENGTH Can be set to watch for password lengths that are shorter than this value.
- SNMP backend This backend detects traditional SNMP-based network attacks. It checks for common community names (public, private), and it will also watch for common attacks against SNMP. Several variables can be modified in this backend:
- SNMP_INT_AND_INT, SNMP_INT_AND_EXT, and SNMP_EXT_EXT These variables provide for tuning of SNMP backend that is internal to internal, internal to external, or external to external. This variable relies on the my_network variable to identify the internal segment.
- BAD_COMMNAMES This is a list of well-known or bad community names, such as
- public
- private
- system
- all
- manager
- default
- password
To shore up the IDS detection capability, the Policy backend is used. The policy backend provides for an ipfilter style or access control list (ACL) style of control. The variables allow for TCP, UDP, and ICMP filtering. The rules are made up of the following elements:
command source_ip destination_ip source_port destination_port
- Command This can be either “Alert” or “OK.” An alert command will create an alert if the condition is met. OK provides for an exception clause to alerts. OK statements can be used to exclude subsets of a network, hosts, ports, or any other combination of conditions that are permitted network elements. For example, if we use an Alert on any, using OK for
a single IP address will prevent the alert from occurring. - Source IP This can be assigned a single IP address or one of the following values:
- inside Refers to the network specified by the my_network variable.
- outside Refers to all networks not listed in my_network. For example, if my_network (or inside) is 10.1.2.1/255.255.255.0, outside refers to everything except 10.1.2.1/255.255.255.0.
- any Any IP address
- CIDR block A range of IP addresses, denoted by the slash notation. For example, 10.0.0.0/8 would represent 10.0.0.8 255.0.0.0.
- Destination IP Same as the source IP, except it applies to the destination addresses.
- Source port This can be a single port or one of the following:
- low For ports 0 through 1,023
- high For ports 1,024 and up
- any For any ports
- Destination port Same as the source port, except it applies to destination ports.
For our web farm, the Policy backend variables would reflect the following rules.
RULES_TCP "alert any any any any" "ok any any any 80" "ok any any high any" "ok any any any 443" "ok inside any 22 any"
UDP and ICMP rules would also be used RULES_UDP and RULES_ICMP would be configured in the following manner.
- RULES_UDP
"alert any any any any"
- RULES_UDP will allow only for SNMP management capabilities from a trusted network segment.
- RULES_ICMP
"alert outside any any any"
- RULES_ICMP will alert on any activity that is not generated by the trusted network. This allows for inside network devices to use tools such as ping without alerting the IDS.
Case Study 2: Corporate Network Services
In this case we will look at a corporate network segment that much like the web farm segment, but smaller and more diverse. In this case, we will include services that would commonly be used by a corporate network in daily operation, such as mail, DNS services, web services, and potentially an Internet Relay Chat (IRC) type of messaging service. This is a protected network segment, and it includes critically important network elements.
We can use the following backends that were used in the previous case:
- WWW backend for web services detection
- SSH backend for all secure communication detection
- SNMP backend for management services detection
- Authentication backend for policy enforcement
- Policy backend (changes to the rules will be noted at the end of this section)
The following backends should also be considered:
- Telnet backend This backend allows you to make sure that an unsecured service, such as telnet, cannot be seen on an Internet-exposed segment.
- Cisco IOS backend This backend watches for potentially damaging events to routers running Cisco IOS, which is vulnerable to brute force attacks and existing exploits.
- SMTP backend This backend detects and logs the SMTP mail protocol. The backend provides for alerting on common SMTP attacks, and it also provides logging for all SMTP traffic. It will ensure that the server had received one of the expected “MAIL”, “RCPT”, or “DATA” commands before mail is forwarded. Otherwise, the backend will investigate the traffic for unusual behavior. This backend can be tuned differently based on whether it will primarily be working behind a Unix-based sendmail servers or Microsoft-based Exchange mail servers. This backend permits tuning with the following variables:
- SMTP_BAD_SUBJECT Provides a means to watch for keywords in mail headers. When turned on, this could alert on statements or words that should be restricted to intranet traffic.
- SMTP_DUPLICATE_COMMANDS Watches for commands that are frequently duplicated for attack purposes. However, in instances of MS Exchange this may happen normally as a result removing the following may avoid false positives:
- ehlo
- helo
- POP backend This backend detects common attacks on and logs Post Office Protocol (POP) traffic. This backend contains the same features as the SMTP backend, except they pertain to the POP protocol.
- SMB backend This backend ensures that no Server Message Block (SMB) activity exists on any web server. Isolated segment damage from SMB attacks can be devastating. The following variables can be changed to prevent false positives:
- NBT_SESSION_REQUEST_FLOOD_THRESHOLD Quell excessive (NetBIOS over TCP/IP ) NBT flood events. NBT floods often reflect DOS attacks and compromise attempts against Microsoft devices.
- PURGEFREQ Adds additional granular control of the flood threshold in NBT sessions.
- DNS backend Provides full coverage of the DNS protocol. This backend provides true anomaly detection on DNS traffic.
- MY_DNS_SERVER Should be supplied to identify the network's DNS servers. This will allow the backend to detect all anomalous behavior against DNS services, especially when the attacks are against the DNS server listed in this variable.
- FTP backend Provides full state and anomaly detection within the FTP protocol. The package can be tuned to watch for specific attacks aimed at certain accepted hosts, and it also watches for services that may allow for anonymous FTP. The following variables may require changing:
- ALERT_ON_BINARY_REQUEST, ALERT_ON_BINARY_RESPONSE Provides the ability to curtail false positives related to binary data embedded within FTP traffic.
- BAD_DIRNAMESWatches for specific directories that should not be exported by FTP under any circumstances, such as these:
- .appz
- .codez
- .c0dez
- .sitez
- .warez
- BAD_USRNAMES Watches for special users who should never be seen on the network connection:
- adm
- daemon
- nobody
- null
- root
- TCP backend Offers the ability to watch for devices that port-scan network devices.
- INTERVAL This value can be set to limit false positives as it relates
to scans. If the interval is set high, it is likely that more false positives will be seen, since regular network behavior will seem like a port scan. Likewise, a value too low may allow for slow scans to be missed.
- INTERVAL This value can be set to limit false positives as it relates
- IP backend Provides the ability to watch for host-scanning.
- MAXHOSTS This value can be changed to prevent scans that may fall below the threshold of maximum hosts. Certain protocols and applications that scan for port access may trigger false positives.
- TFTP backend Provides monitoring for proper operation of batch update devices.
- IRC backend Provides protocol decoding of IRC traffic. Since this protocol can be especially dangerous when unchecked, this monitoring is extremely important.
With this environment, shoring up the configuration with the policy package may be a bit more difficult, but it is still a viable way to provide a “catch everything else” solution. Let's look at the three policy backends and how they complement the sensor deployment.
RULES_TCP "alert any any any any" "ok any any any 80" "ok any any high any" "ok any any any 443" "ok inside any 22 any"
| Note |
These variables will require a separate entry for all incoming and outgoing protocols, the |
RULES_UDP "alert outside any any any" RULES_ICMP "alert outside any any any"
Case Study 3: Bare Internet Connection
When using an IDS on a bare Internet segment, it can become quite difficult to separate false positives from true positives. More often than not, the purpose of the IDS in this case is to alert people that “a-ha it is an attack.” Tuning of this sensor is a bit more complicated, since we are trying to watch everything. As a result, the alerts will provide information about both benign and malicious activity. Even if the events are malicious, attacks may not affect the network the sensor is watching, since the event may have been stopped by the firewall, it may not involve any of the protected hosts, or it may simply have been an automated scan that just happened to sweep the protected network.
For this scenario, we will take a stock system and tune down some elements that will create extensive false positives or that would load the system down so significantly that it might be difficult to read through the alerts.
The following backends have been covered in the last section.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Here are some other packages that may provide additional value:
- BADFILES backend Provides the ability to watch for certain filenames that should not be seen on a network segment. The variable can be set to specify the filenames:
- BADFILES_FILESSpecifies certain file types that may be of interest, such as gone.scr.
- SCANNERS backend Provides a compilation of signatures that watch for scanner-like activity from scanners such as Cybercop, Iss, Nessus, and Retina.
- DDoS backend Provides a compilation of signatures that are related to DDoS events, this includes backends such as Mstream, Shaft, Stacheldraht, Tfn, and trinoo.
- TROJANS backend Watches for common Trojan-like behavior. Included this backend are services that may be used for management; however, they are included because of the impact that the particular service can have if compromised, such as by pcAnywhere. A successful compromise of this service on a system permits total system control. The package includes signatures for Back orifice, pcAnywhere, telnetbd, bo2k, net bus legacy, net
cat, vnc, deep throat, net bus pro, and sub7.
Using the Policy package is not advisable outside the default installed state, since a large number of false positives will be seen as a result of the backend being enabled incorrectly. This backend would have to be used with caution and careful observation. By default, the backend is set up to monitor IP ranges inside TCP, ICMP, and UDP that are part of the reserved IP ranges.
Case Study 4: LAN Segment
A LAN segment can be the most interesting case to work with, and NFR can provide useful information for managers when the cost of ownership for security equipment becomes an issue.
Traffic on an internal network segment will consist of data created or altered by staff, people on associated networks (partners or affiliates), and guests, invited or not! The organization's assets are located on the internal segments, and this includes traffic that may or may not follow corporate policy. For this type of case, tuning requires hands-on exposure to the data. Since no two network environments are the same, no two IDS deployment tunings will be the same.
Initially it is best to disable all the backends, and then start adding in backends such as Trojans, DDoS, WWW. Once these are in place, they should be used to watch the network traffic for a period of time to identify trends. These results will dictate what packages and backends will cause a flood of false positives. Normalization will occur once false positives are reduced to almost zero, this can be called a normal traffic pattern. Once the data starts to normalize, additional backends can be loaded. However, after each backend is loaded, you should wait for a while to see the results of the change. If well executed, this can take from several hours to several days. The result of this process is guaranteed to provide a clear definition of the types of data on the network.
NFR Reporting
Within the AI several reports can be generated for trending and general graphing of alert traffic. All these reports are available via the AI. The reports are simple and functional to produce. Additionally the report data can be exported to .CSV format for use in a spreadsheet application such as MS Excel.
NFR provides several report mechanisms, for detailed usage of the reporting mechanisms refer to the nfr AI users manual https://support.nfr.com/nid-v3/console/ai/docs/NFR_AI_v3_Users_Guide.pdf.
Extending NFR
The extensibility of NFR is a true strength of the product. We have seen how we can extend the product’s detection ability with N-Code, and how interacting with the CMS can extend visibility to the sensors. NFR additionally provides generic alerting and command line access. All of these provide a means to extend the alerting and management in an automated fashion.
One such extension uses Perl. The NFR’s Perl tools provide access to the data and alerts that NFR stores on the CMS via command line (CLI). There are several Perl tools provided by NFR: popups.pl, isummary.pl, query.pl, all provide a quick means to access the data without starting the AI.
Summary
In this chapter we looked at the NFR Sentivist Intrusion Detection system and examined how it operates and handles data in a unique fashion. We also examined the product three tier architecture and several key services that operate the product and can be used to diagnose the services. The chapter examined four deployment scenarios examining the signatures used in context of each case deployment. We examined Sentivist signatures, as it would relate to Web Farm, Corporate Network Services, Bare Internet connection, and Lan Segment deployments, looking at the best way to approach each of the solutions when deploying Sentivist Intelligent Intrusion Manager.
Part I - Intrusion Detection: Primer
- Understanding Intrusion Detection
- Crash Course in the Internet Protocol Suite
- Unauthorized Activity I
- Unauthorized Activity II
- Tcpdump
Part II - Architecture
Part III - Implementation and Deployment
Part IV - Security and IDS Management
EAN: 2147483647
Pages: 163
