Data-Centric Storage Management
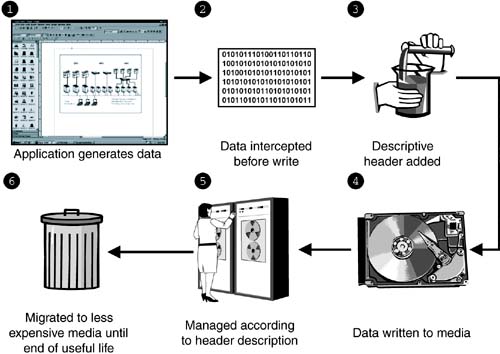
| The ultimate solution to capacity utilization efficiency, and to storage management more broadly, is not to manage devices, but to manage the data that uses the storage infrastructure. A few vendors today have begun to pay lip service to the concept of "data lifecycle management," though like so many grandiose terms, this is at present mostly a repackaging of traditional SRM products. Not one vendor has articulated a core requirement for such a strategy: self-describing data. [8] If data could carry with it a simple description of its origin and contents that could include (or be cross-referenced to a data table to discern) instructions about its accessibility and storage requirements, the problem of intelligent storage provisioning might quickly become history. Figure 8-8 provides a high-level view of how self-describing data would facilitate provisioning and management. An application creating the data initiates a write command. As part of this function, or as a separate function of low-level software, the data is intercepted and a small header containing descriptive bits is added. The write operation is completed and the data is written to the appropriate target device. Henceforth, processes responsible for life-cycle management utilize the descriptive header to provision the data with the proper type and "flavor" of storage (and ancillary services such as inclusion in mirroring schemes or backups , etc.) until finally, in accordance with its associated data retention requirements, it is removed permanently from storage. Figure 8-8. A simplified data naming scheme. In this conception , the data header added to the application write provides a mechanism for
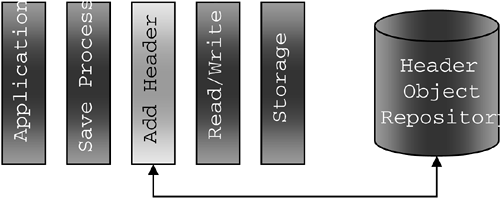
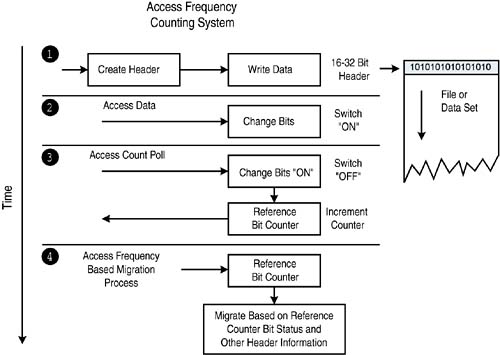
In effect, just about any criteria that might be useful in managing, moving or tracking data through the storage infrastructure over its useful life could be included in a simple 16- to 32-bit naming header. Perhaps the more flexible the criteria, the more innovative IT professionals could be in leveraging the header to meet their own needs. Of course, such a scheme of data naming as proposed here would need to be non- intrusive , and compatible with all file systems and operating systems, databases and applications. It would need to be an open system, allowing storage managers (henceforth called "data managers") to apply a naming schema of their own choosing from a customized header object repository (see Figure 8-9). It would also need to append to data without delay and without introducing latency into I/O processes, and would have to be compatible with all storage media and platforms and all storage transport protocols. Figure 8-9. Data naming header attachment process. The openness of the strategy would facilitate its use by storage management software of all flavors, including data discovery engines, migration tools, replication tools, security engines, hierarchical storage managers, etc. In full flower, the header could even support the function of zero copy protocols that enable direct memory-to-memory exchanges across networks, without the need for slower stack- and cycle- intensive data copy operations. Data naming would go a long way toward establishing the foundation for capacity allocation and utilization efficiency improvement. It would enable the allocation of storage resources on a much more granular scale than what is possible with even the most sophisticated of our current storage management tools. Such a system would also need to support a flexible set of bits in its header, called reference and change bits, [9] to facilitate access frequency-based data migration: a kind of hierarchical storage management system on steroids. As sketched in Figure 8-10, when access is made to the data by any application- or user -initiated process, the change bit would switch on. Figure 8-10. An access frequency-based data migration approach. A secondary process would then poll data headers at regular intervals, identifying those files or datasets that have been accessed since the last time polled (e.g., those with their change bits turned on). A recently accessed file would have its bit reset to off by the process and would have a second reference bit, signifying access frequency, incremented, while those that have not been accessed would not have their access frequency bit incremented by the process. In this way, less frequently accessed data could be identified readily and marked for migration from expensive hardware platforms to less expensive platforms (or to archival storage). Migration based on (1) the frequency of data access and (2) other characteristics of the data as described in the header is the key to capacity utilization efficiency. Combined with a policy engine and knowledge base covering the kinds of storage platforms installed in a given shop (in order to define migration paths), a solution of this type would offer a compelling payback simply by assigning data to the most appropriate platform on a cost/access frequency basis. The more automated this migration process becomes, the more data could be managed effectively by fewer staff resources, saving the organization more money over time. |
EAN: 2147483647
Pages: 96