Lesson 1: Relational Databases
Relational Database Structure
The relational model is the standard for database design. A relational database stores and presents data as a collection of tables. Instead of modeling the relationships of the data according to the way it is physically stored, a structure is defined by establishing relationships between tables to link data in the database.
In a relational database, such as Microsoft Access, you can combine data from multiple tables in a query, form, or report.
Regardless of how data is stored in the database file, a table can be viewed as a set of rows and columns, similar to the rows and columns of a spreadsheet. In a relational database, the rows are called records and the columns are called fields .
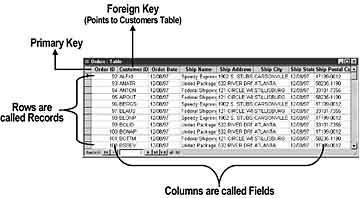
Keys are a field or fields in the table that are indexed for fast retrieval. A unique key can be designated as the primary key , making it the unique identifier for each row of the table. For example, the Employee ID field in the Employee's table would be an appropriate primary key since no two employees can share the same ID. A table can also contain fields that are foreign keys . A foreign key is a field or group of fields that can be used to identify a primary key in a separate, related table.
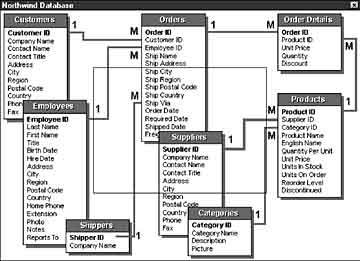
For example, in the Northwind database, rather than duplicating all the customer information for each order, the orders table contains a Customer ID field. The Customer ID field in the orders table is called a foreign key because it relates to the primary key of a "foreign" table (customers). The relation between orders and customers is a one-to-many relation. That is, for each order, there is only one customer. However, one customer can have many orders.
File-Based Databases
Many popular desktop database solutions are file-based relational databases. These databases can reside on a server for shared access. In this case, the architecture would be considered a file-server database.In a file-server database configuration, the database engine resides on each user 's workstation and the data file resides on a server. When the client application needs data, the database engine on the workstation processes the query and then issues a request for specific data on the network drive. All requested data in the data file must be sent from the server to the workstation, which can create a significant amount of network traffic.
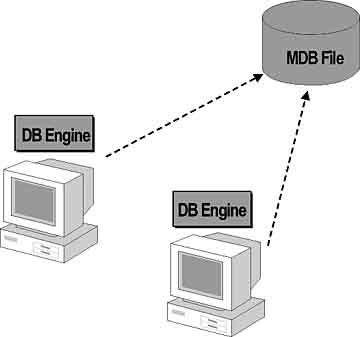
Indexed Sequential Access Method (ISAM) Databases
Indexed sequential access method (ISAM) is a file-based database technology that programs such as FoxPro, Paradox, and dBase are built upon. When accessing data through an ISAM database, the only resource being used is the data. No server component is used.
ISAM databases allow data types to be defined and data storage to be based on the defined data types. In addition, indexing methods are used to speed up data retrieval and analytical processing. You can create a number of indexes, each one arranging key values in a specific sort order. You can these indexes to make data retrieval more selective and efficient than with a flat file.
Microsoft Access
Microsoft Access is a desktop relational database management system (RDBMS). If an Access database file is stored on a network, the only service it provides to a network client is data storage. Because it uses the same database engine (Jet) and format as Microsoft Visual Basic, databases created with Access can be used just as if they had been created directly in Visual Basic.
Advantages of File-Based Databases
File-based databases offer several advantages:
- Although the database can reside on a server, the server is not required.
- Network traffic is reduced when implementing the database on a local computer.
- The file-based database implementation is much simpler than client/server systems because the server only provides data storage.
Client/Server Databases
Client/server architecture is an effective and popular design for distributed applications. Client/server databases provide data storage like file-based databases, but they also they include additional functionality. 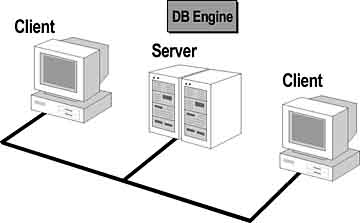
In the client/server model, an application is split into two parts : a front-end client that presents information to the user, and a back-end server that stores, retrieves, and manipulates data, and handles the bulk of the computing tasks for the client. In a client/server system, the server is usually a more powerful computer than the client, and is a central data store for many client computers. This makes the system easy to administer.
Typical examples of client/server applications include shared databases, remote file servers, and remote printer servers.
Advantages of Client/Server Databases
For many database applications, the client/server architecture offers several advantages:- It allows for robust operations because a single database server interacts with the data.
- It significantly improves the performance of some operations, especially when the user workstations are low-end computers with slow processors and limited RAM. For example, a large query can be executed many times faster on a high-end server than on a client workstation.
- It reduces network traffic because data is transmitted more efficiently . Only data that the application needs is transferred.
- It supports mission-critical features such as transaction logs, sophisticated backup capabilities, redundant disk arrays, and failure recovery tools.
SQL Data Structures
SQL data structures are designed for very large databases organized into relational design. As database size increases , ISAM structures are too inefficient to handle the bulk of data and the number of simultaneous users that SQL databases commonly serve. Advanced indexing methods and query optimization engines make SQL databases the common choice for mission-critical computing and large-scale data manipulation.In a client/server configuration such as Microsoft SQL Server, both the database engine and the data needed by the application reside on the network server. Instead of running a copy of the database engine on each workstation, the database engine runs only on the server. The workstation simply sends a high-level request in the form of a SQL statement to the server, which retrieves the specific data and sends it back to the client.
Microsoft SQL Server
Microsoft SQL Server is a scaleable, high-performance relational database management system for Windows NT Server-based systems. It was designed to meet the requirements of distributed client/server computing and can be tightly integrated with Microsoft BackOffice servers.Lesson Summary
The relational model is the most popular database design. Two types of relational databases, file-based and client/server databases, are commonly used today.In file-based databases, the database engine resides on each user workstations, and the data file resides on the server.
In a client/server database, an application is split into two parts: a front-end client that presents information to the user, and a back-end server that stores, retrieves, and manipulates data, and can handle computing tasks for the client.
EAN: N/A
Pages: 324