Editing Logical Models”Intermediate Aspects
Editing Logical Models Intermediate Aspects
The Database Properties Dialog
The ORM Source Model, ER Source Model, and Database Model Diagram solutions all allow you to work with data models. Within any of these solutions, you can use the Database Properties Dialog to set the properties of the model element that is currently selected in the drawing window.
The Database Model Diagram solution allows you to work on a logical database model, and its project feature allows you to optionally include ORM models or ER Source Models as additional source documents. This chapter focuses on logical database models displayed in the Database Model Diagram solution, and ignores source models. If you are including an ORM model or an ER source as source documents, then be aware that migrating changes in the database model back to the ORM or ER models is required. Failure to manage this properly will result in the loss of these changes when the database model is next built. Synchronization of models is discussed in Chapter 16.
When working in the Database Model Diagram solution, the database properties window may be closed, open, or hidden. If you do not see the database properties window, then double click some object in the drawing window to open its properties window. The list of categories displayed varies according to the kind of model element selected. There is one category list for tables and another category list for relationships.
Figure 12-1 shows the Categories Database Properties when nothing is selected in the diagram. The Information Category does not respond to any action.
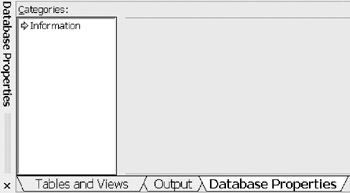
Figure 12-1: Initial Database Properties Window.
Table Properties
The categories list in Figure 12-2 is displayed when a table is selected.
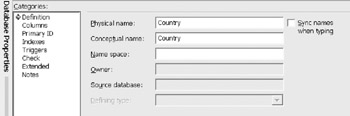
Figure 12-2: Table definition.
The Definition category assigns the table name and an optional name space. There is a physical and a conceptual name. The conceptual name is the name meant for human communication, while the physical name is the name in the physical database.
| Note |
The "sync names when typing" assures the two names are always the same. Do not use this option if you want to record both the conceptual and the physical name. For example, the conceptual name "Instant Blood Pressure" is different from the physical name "InstantBP". The logical and physical names are subject to the naming options defined when ORM is a source document. |
| Caution |
When using an ORM source model, be careful about renaming any object in the logical model. |
If you change a name in the logical model, that new name overrides the ORM to logical name mapping. This sounds like a reasonable action. However, if you change the ORM object name to something completely different, the logical model will still override the new ORM name. It may now be the case that the logical name makes no sense as a proper override name. You are forced to change the logical model name on your own yet again. As far as possible, it is best to do all naming only on the ORM side when including an ORM model as the source document.
Name space is used to assign uniqueness to the definition. This permits the same fact to exist more than once in the model where the name space indicates the specific context.
Column Properties
There are five column properties: Physical Name , Data Type, Required, Primary Key, and Notes. Refer to the grid in Figure 12-3.
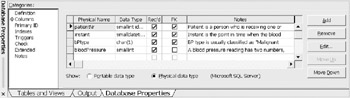
Figure 12-3: Selected table column properties.
The data types are shown as physical data types in this example, with the target DBMS set to Microsoft SQL Server. By changing the "Show" option, you can display the portable data types. Using portable data types postpones your view of the data types for a specific DBMS. The DBMS specific data types are always used when generating the Data Definition Language (DDL) script. Portable data types are also useful when the model may be mapped to more than one target DBMS.
The Required option is checked if the column is mandatory (not null). Primary key fields are always required. The Primary Key option is checked if the column is, or is part of, the primary identification scheme for the table.
Enter appropriate notes for the reviews, and for future reference. It is best to do this initially, so you don't forget what the column names really meant . If the model was created from an ORM source model, note is automatically entered based on the fact type source for the table/column mapping.
Rename and Edit Column Properties
There are two methods to edit a column. The first is to directly change the properties shown on the property grid (Figure 12-3). This is fast but has limited editing capability, as not all options are shown in the grid. The second is to select the column of interest and then select Edit (Figure 12-4). Options such as check clauses, collections, and extended properties are now available. This provides a more robust version of column editing. The Allow NULL values option means the opposite of the Required (no nulls allowed) option in the grid version. The collection option is described in Chapter 13.
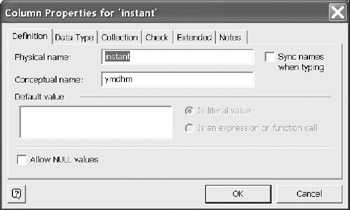
Figure 12-4: Alternate windows for managing column properties.
The Sync names option is available as described in the introduction to this chapter. In this example, the physical name and the conceptual name are not the same, and the "Sync name when typing" is not checked.
A default value may be either a specific value, or a call to a database function. Select the appropriate radio button. The default value text is included in the DDL script. If this is a function name, the function must exist prior to creating the table in the DDL script.
| Note |
Be sure to review the DDL script and possibly reorganizing the DDL script to position the function prior to the table definition. |
The Data Type table shown in Figure 12-5 is shown as a physical data type. It can also be shown as a portable type by selecting the other radio button. To change the data type from the column default type select Edit > Native Type. If the native data type requires Precision and Scale, the fields will be active.
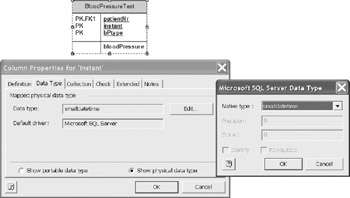
Figure 12-5: Instant data type is small date time.
The collection type settings are examined in Chapter 13. This feature is used when defining object-relational database structures. The target DBMS must support this option, otherwise the results are merely relational tables. The current versions of Oracle and IBM DB2 Universal Server support these constructs.
The default is a single valued column, which is expected in a normalized relational database.
The Check tab allows you to constrain the column values to specific values or ranges or values. To add a value , enter the value in the Value field and select Add (Figure 12-7). To add a range of values , enter both the From and To range values and select Add. Just as you can add many values, you can add several ranges. The ranges do not need to be adjacent. For example: ranges of 1..10 and 20..50 may be included in the same constraint. To remove a defined value or range , select it and then press Remove.
Figure 12-6: Collection tab (rarely used).
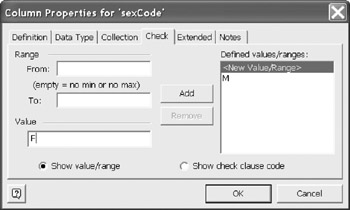
Figure 12-7: Adding a check constraint to specify allowed values.
You can also view, or edit the value constraint by selecting the Show check clause code radio button, pressing the Customize button in the next dialog to work directly with the SQL check clause.
Add Column
There are two ways to add a new column: create the column in the first open row in the grid or click the Add button (Figure 12-3). If you are not using check clauses or collection options, the fastest method is to enter the new column directly in the grid.
Remove Column
There are two ways to remove column, select the column and press the delete key or click on the remove button (Figure 12-3)
Move Up and Move Down
Reorder the columns by selecting a column and then click Move Up or Move Down until the column is in the desired position. (Figure 12-3)
Foreign Key Relationships
Create foreign key relationships between tables using the logical model stencil "Relationship" shape. In Figure 12-8(a) the tables, State and Region, have no defined relationship. Note that the State table has only the state code defined. In Figure 12-8(b), the relationship shape was used to drag and drop a relationship connection to the diagram. Then in Figure 12-8(c), the relationship has been established. This was done by dragging each end of the relationship line onto the appropriate table.
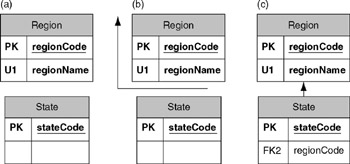
Figure 12-8: Progression of establishing a foreign key relationship between tables.
| Caution |
The table border will turn red when it detects the relationship. It is a common mistake to drag the end into the table while thinking that merely being inside the table is adequate. If the border does not change to the color red, the connection is not made. |
After the connection is made, the key from the parent table is automatically inserted into the child table in the relationship. See the end of this chapter for alternatives to this default behavior. If you had already entered the region code into the State table, you would now have a duplicate region code column. In the relational notation below, the child points to the parent. For other notations, refer to the glossary.
Once the connection is established, clicking on the relationship line displays the list of categories for relationships. First is the definition category, which is shown in Figure 12-9.
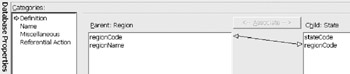
Figure 12-9: Viewing the relationship ”table column connection.
If you select the associated columns in the parent table and in the child table, the Associate button changes to Disconnect Clicking on Disconnect removes the relationship. You are prompted to either remove the relationship line from the drawing or from the model (Figure 12-10). Answer Yes to remove it from the model. Answer No to remove it from the diagram, but retain it in the underlying model.
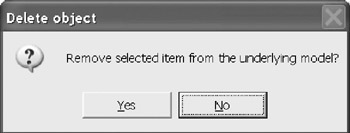
Figure 12-10: Prompt dialog for deleting a model element.
Figure 12-11: Relationship reading.
Selecting the Name category allows you to create meaningful forward and inverse readings for the relationship. If an ORM source document is used, the readings are taken from the predicate readings of the associated fact type. The physical name is either generated from the ORM source document or is entered at this time.
The Miscellaneous category is used to define the cardinality, relationship type and a range definition (Figure 12-12). Again, if using an ORM source model these will be set as part of the logical model mapping. Cardinality indicates how the parent and child participate in the relationship. There can be zero or more children, one or more children, zero or only one child, one child and the child must be present.
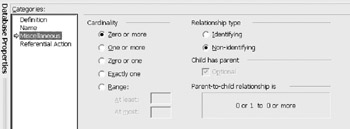
Figure 12-12: Cardinality and Relationship type.
Range is a special case that allows the setting of a specific number of children. For example, there must be at least 2 children and no more than 5 children. The relationship type "Identifying" means the column in the child is part of the child's key, whereas "Non-identifying" is merely a column ”not part of the child key The text "Parent-to-child relationship" is a generated explanation of the relationship.
The Referential Action category (Figure 12-13) defines what action is to be taken if an attempt is made to violate the referential integrity constraint that requires the child values to also exist in the parent. This choice has a large impact on the supporting code, either in the database or the application. The default is "No Action," meaning if the constraint is violated by an attempted update, the update is simply rejected. The Cascade setting means a compensating action will be taken on the child. For example, if you delete the parent, the children are also deleted. Set NULL means the associated column in the child is set to NULL if the parent is deleted. The Set default option is allowed only if the column has been defined with a default. "Do not enforce" means that referential integrity will not be enforced.
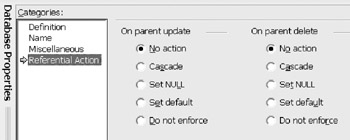
Figure 12-13: Referential Action options.
| Note |
These options can impact the integrity of the data. Be careful, and understand what may have to happen in the application or other database functions. It may be the case that you instead need trigger code to handle complex situations. |
Category Relationships
The term "category" is overloaded. So far, we've used it to refer to class of properties of an object. The term "category" may also be used to denote a subtype. This is what the category shape in the Entity Relationship stencil is used for (Figure 12-14).
Figure 12-14: Logical model template and super/subtype tables.
To illustrate this concept, suppose that we have an Item table, and wish to introduce a Hardware table for a specific kind of item. To establish the kind of item, a categoryCode attribute has been added to the Item table.
The ER stencil contains three shapes that are required to establish a Category (subtype). The Category shape, the Parent to Category shape, and the Category to Child shapes are all used to make the connection. To complete the example shown in Figure 12-15, the Category shape is placed between the Item and Hardware tables. The Parent to Child shape connects the Item to the Category. Then the Category to Child shape is used to connect the Category to the child table. When making the connections, ensure that the table borders flash red to indicate the connection.
The Item table (super-type) includes the discriminator column categoryCode. In this example, we've annotated the category with the specific discriminator value ˜HW that determines membership in the Hardware table. (Figure 12-15). This annotation was made using Visio's callout stencil. It is handy during a review to add such comments on the drawing. The annotations can also be assigned to layers to enable their display to be turned on or off.
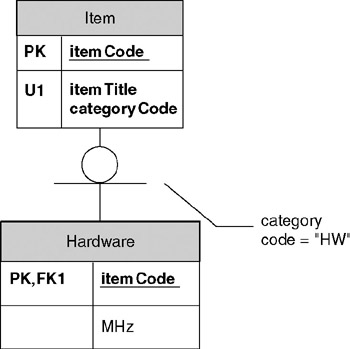
Figure 12-15: Resulting category relationship.
Click the category relationship to bring up its properties dialog. You can now record the categoryCode attribute as the discriminator (Figure 12-16). The "Category is Complete" check box is checked by default. In our case, not all Items are Hardware, so the check has been removed.
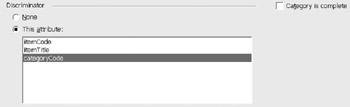
Figure 12-16: Selecting discriminator for the categorization.
| Hint |
It is possible that a Category has no discriminator, but this is not the recommended practice. |
Show Related Tables
A large logical model may be spread over many drawing pages. Hence on any given page, some tables may be hidden from view. Suppose that for some given table, you want to see all the other tables to which it is connected by foreign key relationships. Here is an easy way to do this.
- Insert a new drawing page by choosing Insert > New Page from the main menu.
- Drag a copy of the relevant table from the Tables and Views window onto the new drawing page.
- Right-click the table to display its context menu, and select Show Related Tables option.
This adds the related tables and the foreign key relationships to the drawing. This feature is very handy when doing a review, and questions arise about what is related to the table currently under discussion.
Views
There is more than one way to create a view. If you are an SQL programmer you can open the code window and enter the SQL statement. This provides code for the DDL script. This does not create a view symbol on the diagram. The other option is dragging a view shape from the ER stencil onto the drawing. You can then create the view and the SQL statement using the view definition window.
The first option is easier if you code SQL and care to do so directly. The code window is opened by selecting from the main menu bar Database > View > Code . Select Global Code (Figure 12-17) to open an instance of the code window. When using the code window, there is no resulting symbol on the logical model diagram. The code is authored and kept for the DDL generation.
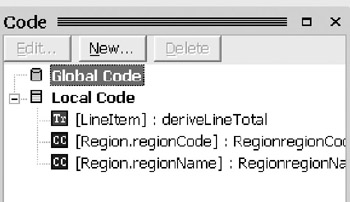
Figure 12-17: Select global code for authoring a view.
| Note |
The drawback to this option is that your coding is not immediately checked. It will be checked when you do a model error check ( Database > Model > Error Check ) or when you attempt to generate the DDL script. |
Although the Body is the first tab, it is more useful to first provide the properties. Here you name the code set and indicate the type of code, in this case the View Definition (Figure 12-18)
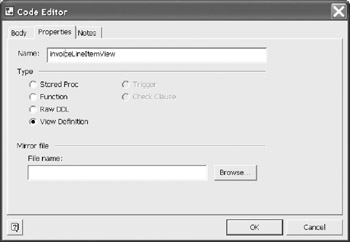
Figure 12-18: Indicating that the code is a view definition.
| Note |
Code maybe global or local. Local code is local to a table and may be a check clause or trigger code. SQL procedures and views are part of the global code collection. |
The properties tab is where the type of code is indicated, in this case a view definition. The name is therefore the name of your view. This name should be created following your naming conventions.
If a mirror file is selected, then the code is loaded from the file. You can also save the code to a mirror file by providing a name when a new code set is created.
| Hint |
Even if your source model was an ORM model, which has naming rules, these rules do not apply to view names . |
Next, select the Body tab and enter your code. It is normal to also include comments and other information pertaining to the view. Most IT shops have a template for this purpose.
In this code block, you are entering the SQL statement that defines the View. This code is checked for errors when you attempt to create the generate DDL script or when performing an error check. Shown below is the script for the view defined in Figure 12-19.
/*Create procedure/function invoiceView.*/ Select invoice.invoicenr, invoice.issuedate, itemline.itemcode, itemline.unitprice, itemline.quantity from invoice, itemline where invoice.invoicenr = itemline.invoicenr
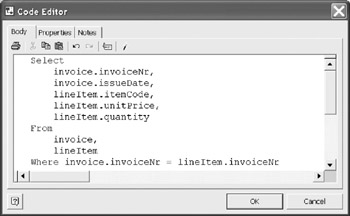
Figure 12-19: Enter the SQL Select for the view.
| Caution |
The SQL code must be suitable for the target DBMS. If you change the target DBMS and you used DBMS specific SQL code options, they may fail to compile. |
The second method for creating views is to use the view shape from the stencil. This creates a gray shaded table on the drawing. Select the Definition field to change the default view name from "Table 1" (Figure 12-20).

Figure 12-20: Using the View icon from the logical model stencil.
If more than one table is involved in the view, select Join Criteria , then select the first table in the join and the appropriate column; then select the second table and appropriate column. Figure 12-21 shows the join between Invoice and Line Item using the Invoice Number from both tables. Select Add to complete the join.
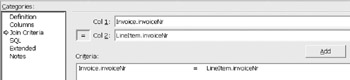
Figure 12-21: Adding columns to the view.
You must enter the physical name. Also indicate if the column may be null. The data type is correctly assigned from the source column.
Select columns from the Category list. To select the columns from the associated tables, there is a three step sequence for each column. First select Add , which automatically inserts a default column into the column grid as shown in Figure 12-22. This activates the Edit button. Select Edit .
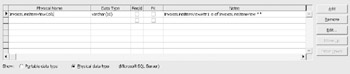
Figure 12-22: Using the grid to populate the view.
Change the selection from "Unknown column in another table or view" to "Known column in another table or view" Then select Change, since you are changing from the default name to a real column name (Figure 12-23).
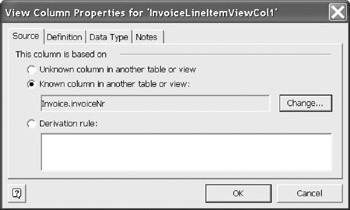
Figure 12-23: Selecting a known column name.
Select the column from the list presented after selecting Change. Your column then appears in the Change Row.
If you select Derivation rule, you must enter valid SQL code to perform the derivation, for example, "quantity * unitPrice AS Line Total."
| Note |
Even though you have selected a known column name from the table, the name has not changed from the default. You must select the Definition Tab and manually change the view column name. |
Continue to repeat the sequence of "Add," "Edit," "Change," and "Definition" for each required column until you have completed your view columns. Figure 12-25 shows a view based on the LineItem base table, to which a derived LineTotal column has been added.
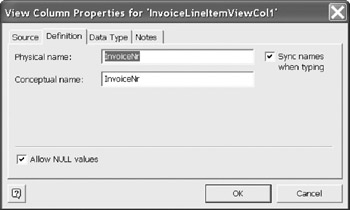
Figure 12-24: Changing the column name manually from the default name.

Figure 12-25: View after selecting and editing desired columns.
| Hint |
This cycle is neither fast nor friendly. If you know SQL, use that option. |
Selecting the SQL category of the properties dialog displays the generated code. Do not alter this code, as changing anything in the columns or join criteria will recreate the code eliminating your additions. The code shown below is for SQL Server 2000, since that was the active driver option.
create view "InvoiceLineItemView"
("InvoiceNr", "IssueDate", "ItemCode", "quantity", "UnitPrice", "LineTotal") as select
c1."invoiceNr",
c1."issueDate",
c2."itemCode",
c2."quantity",
c2."unitPrice",
c2."lineTotal"
from "Invoice" c1, "LineItem" c2
where c1."invoiceNr" = c2."invoiceNr" with check option;
This is a bit awkward to repeat for each column. Hence, if you know SQL the first option is a lot faster. However, the first option has the disadvantage of not displaying the view on the drawing page.
Pagination
The logical model may be very large, making it difficult to review. Visio provides many sizes for a page, but all pages in the model are the same size . You may want to place some selected tables on each page. You may create any number of pages for the drawing. Each page focuses on a smaller subject area. Give each page a distinct page name for easier navigation. A table may be placed on more than one page without causing definition duplication in the DDL script. All of this helps to reduce relationship line confusion and review sized pages. Controlling relationship lines is discussed in Chapter 13.
| Caution |
Be very careful when attempting to move relationship lines. They have a tendency to disconnect. If that happens, immediately use the undo feature. Another way to redirect lines and the layout is to choose Shape > Layout Shapes . There are several layout options native to Visio. You should investigate them for various alignments. |
Creating several pages also provides extra space for adding other information on the page with less clutter. To insert a page, choose Insert > Page from the main menu. Name the page based on its content. Naming pages is especially useful if you create hyperlinks from an external document into the Visio model. You can reference the file and the drawing page within this link.
Verbalization
The major objects in a logical model can be verbalized by selecting Database >View > Verbalizer from the main menu bar. The verbalizer describes the selected object in natural language. Three examples are shown in Figure 12-26, Figure 12-27, and Figure 12-28.

Figure 12-26: Table verbalization.

Figure 12-27: Relationship verbalization.

Figure 12-28: Category verbalization.
Model Error Check
A logical model can be checked at any time for consistency or omission errors. It is best to check the model frequently. It is easier to fix errors when there are fewer to resolve. Double clicking on the error message places you at the point of the error. It is best to resolve not only errors, but also all warnings.
Coding done within the model is also checked. A double click on the error will position the cursor diagram where the error is occurring. This is performed automatically when doing a Generate.
| Hint |
Do an error check with each unit of code. |
Driver, Document, and Modeling Options
Driver Options
You must, at some point, select the target DBMS for the model. If you are targeting more than one DBMS, then select a preferred driver initially and select the actual driver when generating the database. This is a case where using portable data types is useful. To select a database driver, choose Database > Options > Drivers from the main menu. The dialog shown in Figure 12-29 is now displayed.
| Note |
You may change your selected DBMS at the time you generate the DDL script. This may impact your custom SQL code, as it might not compile in every DBMS. |
Figure 12-29: Select your preferred driver.
Clicking the Set Up button displays the available ODBC drivers (Figure 12-30). Select the appropriate driver for your DBMS. Once connected, you can review the databases associated with that driver. Select the default database for your model and proceed to the Preferred Settings.
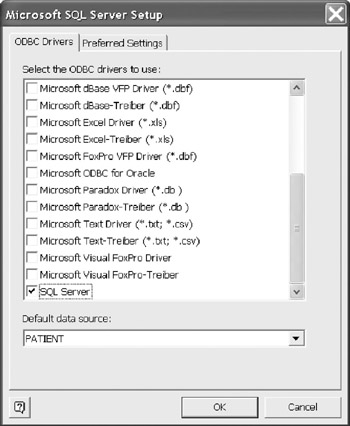
Figure 12-30: Select the preferred ODBC driver.
You can establish several defaults by selecting the Preferred Settings tab. (Figure 12-31) The upper section allows you to map ambiguous portable data types to physical data types. In this example, a small numeric either signed or unsigned will be mapped to the SQL Server smallint data type.
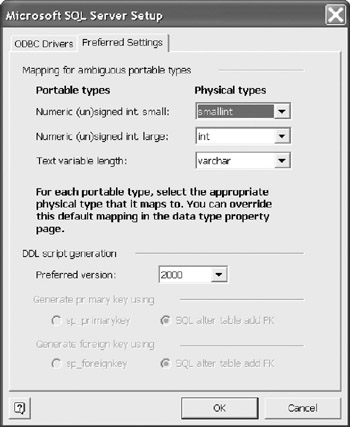
Figure 12-31: Setup default data type mapping.
The lower portion allows you to select the version of default DBMS. Continue to establish your other defaults for large integers and for variable length text. The default variable text length is 10.
|
Sp_primarykey |
SQL Alter table add PK |
|
Sp_foreignkey |
SQL alter table add FK |
These options may or may not be active. If they are active, then select the method by which you wish to create primary and foreign keys. Choose whether to use a stored procedure or to use the Alter Table statements in the DDL.
Default mappings are assigned to each new column in a table. (Figure 12-32) You can override the default on a column by column basis. There are defaults for: Test, Numeric, Raw Data, Temporal, Logical, and Other. In the example, the default for Text is variable length, using a single byte character set and a maximum length of 10.
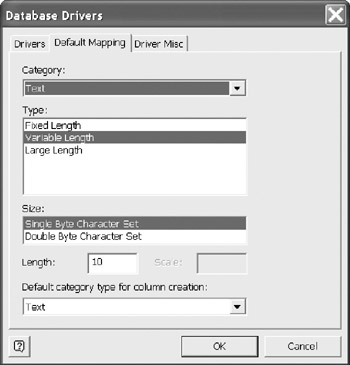
Figure 12-32: Setting the defaults for text type data.
The default portable data type for a column is currently Text. This can also be set to any member in the category drop-down list box.
Finally, you can set a few options for the generation of the DDL script. (Figure 12-33) Do your want comments in the script? This is usually advisable. The SQL Comment On feature creates comments in the physical database. The last option uses all the notes fields in the logical model, and uses verbalization for those that do not have user provided notes.
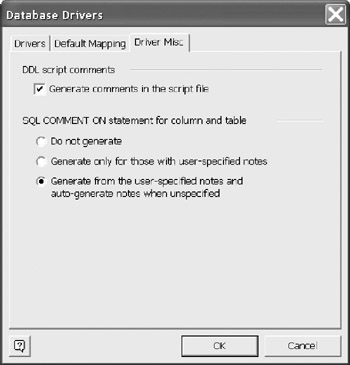
Figure 12-33: Setting defaults for mapping comments to DDL.
Document Options
The document is the current model. If you create yet another model, these options will be the defaults. Keeping the document options the same for each model is usually a good idea.
Altering the options on-the-fly is handy when reviewing a model. For example, the symbol set choice shown in Figure 12-34 is relational. If your audience is more familiar with the IDEFIX notation, open this form, change the option to IDEFIX and the model diagram changes to that presentation notation. The same is true for the names. Physical names may not be friendly for non-technical audiences. Select the Conceptual Name option to display the conceptual names. This is a reasonable case for not using merely physical names . Note : This all relates back to "sync when typing" options. If you chose not to sync the names, you can provide two sets of meaningful names.
Figure 12-34: Setting the diagram to a default notation.
The Table tab provides a long list of display options. For each checked item, there will be information displayed within the table on the diagram (Figure 12-35). The defaults are all selected. The options for data types either hide or show the column data types in either physical or portable contexts. It is often handy to hide the data types when addressing non technical audiences.
Figure 12-35: Setting what to display on tables objects.
For column order, the Primary keys at top option forces the presentation sequence to place the primary key columns first. An optional line can be included to help in the visual separation. Displaying the primary key columns at the top may hide the actual sequence of columns . If you need to rearrange the column's physical order, then select Physical order You can then arrange the columns in a preferred order. If you are using the IDEXIX notation, you can decide whether to show or hide the optionality symbol "(O)" for the table columns.
The Relationship tab allows you to alter the presentation of the foreign key relationship lines. After you have selected relational or IDEFIX as a notation in general, you can then include other options (Figure 12-36).
Figure 12-36: Setting relationship line options for notation.
The option to show relationships is on by default. It hardly makes sense to present a logical model without any relationship lines. If you wish to have crow's feet (the trident symbol on the child side of the relation), then select that option as well. The cardinality places multiplicity numbers at each end of the relationships.
The referential actions may be displayed as well. Although this often leads to a messy diagram, it can be helpful temporarily for review purposes. The relationship lines may or may not display a verb phrase. If the source model is an ORM model, the verb phrase will be the predicate from the associated fact type. You can also select to see forward, inverse, or both readings . The inverse reading can be included in the ORM model, and you can also provide it in a logical mode when editing relationships.
Modeling Options
To access the Database Modeling Preferences dialog, choose Database > Options > Modeling from the main menu (Figure 12-37). These options control what happens when you delete an object from the diagram, as well as some other behavior.
Figure 12-37: Setting options for removing object and when to show relationships.
| Hint |
The "Ask user what to do" choice is a very important option. If you want some protection when deleting, choose this option. |
Showing relationships after adding a table to a diagram automatically inserts the relationship lines immediately after a table is dragged to the page. This is a good option to select. Synchronization of conceptual and physical names is usually set on. However, if you want to keep a set of conceptual names, turn this option off. For example, a column physical name may be "LineItem" and you may want a more readable conceptual name of "Line Item".
The Logical Misc tab (Figure 12-38) permits the definition of several model defaults. The FK Propagation has three settings.
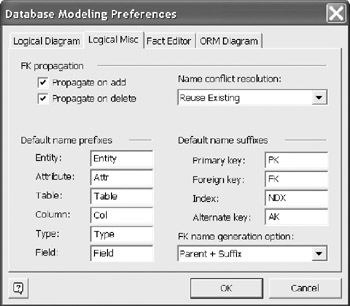
Figure 12-38: Setting Logical Naming Options.
If checked, the Propagate on add option adds a column in the child table that is the same as the parent column when a relationship line is drawn. If this is not selected, then the line is drawn, but the child column is not created. You must then select a valid column to complete the relationship.
If checked, the Propagate on delete option causes the child column to be deleted from the table if the relationship is removed. If not selected, the child column remains in the table, but the relationship is removed.
The last option is Name conflict Resolution . The list of options is: Allow, Reuse Existing, Do Not Allow, Auto-Rename and Ask. These are the possible actions taken when creating a column in the child that causes a duplicate column name.
The Default name prefixes and the suffixes are defined here, but they are only used if prefix and suffixes are selected for use. To change the default, enter the new value.
The Foreign Key name generation includes the following options: (Parent + Suffix, Child + Suffix, Parent + Child + Suffix, Child + Parent + Suffix).
| Note |
DBMS vendors define the maximum name length for model elements. Select an option to keep the names within the set limit without a lot of manual renaming. |
Overview of Database Modeling and the Database Modeling Tool
The Conceptual Modeling Solution (ORM)
- Object Types, Predicates, and Basic Constraints
- ORM Constraints
- Configuring, Manipulating, and Reusing ORM Models
- Mapping ORM Models to Logical Database Models
- Reverse Engineering and Importing to ORM
- Conceptual Model Reports
The Logical Modeling Solution (ER and Relational)
- Creating a Basic Logical Database Model
- Generating a Physical Database Schema
- Editing Logical Models”Intermediate Aspects
- Editing Logical Models”Advanced Aspects
- Reverse Engineering Physical Schemas to Logical Models
- Logical Database Model Reports
Managing Database Projects
EAN: 2147483647
Pages: 150
