Understanding Application Layers
A multitier application consists of three layers: the presentation layer, or user interface; the business logic layer that can be broken up into two parts, the user-centric part and the data-centric part; and the data layer, which is generally the database. Any application that physically separates these layers into different components can be considered a multitier application, regardless of where the components are deployed. You saw these layers in Figure 1-3—except the business logic layer separation. Figure 1-4 shows the business logic layer, which is discussed in the "Introducing the Business Logic Layer" section.
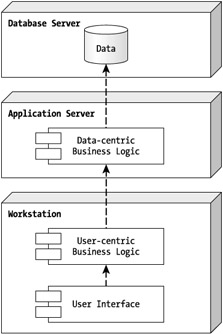
Figure 1-4: A three-tier design with data-centric and user-centric components
Introducing the Presentation Layer
The presentation layer presents data to the users. It does not have any other purpose. There should not be any business logic in the presentation layer. I say should not be because typically this is where most applications start running into trouble. They start putting business logic into the presentation layer, and then maintenance problems start popping up. The presentation layer will also catch unexpected application errors and gracefully handle them and display them to the user. I say gracefully because that application should not do what many applications do, which is to display an error and then promptly shut down, causing the user to lose all of their work up to that point. That is not exactly the right way to handle application errors! The presentation layer is linked to the business logic layer by referencing one or more business logic components.
Introducing the Business Logic Layer
The business logic layer contains all of the application's logic. That is, the business layer validates all of the data entered into the system. There are many different opinions as to where logic should be placed and how it should be broken up. Many people advocate putting it in the database, many people advocate putting some of it in the presentation layer so that the user can have immediate feedback, and some people advocate putting it into the logic layer. So, now it is time to give it my take….
You should put all of the logic into the logic layer. You should also place a subset of that into the database. And some of the logic errors that a user can cause should be reported immediately, but you should also place that logic in the business logic layer—the user-centric part of that layer. In doing this, though, you need to examine some issues. If the logic changes, it must be changed in several places. Obviously, for the purposes of maintainability, this is a bad idea. But for the purposes of data integrity, it is a great idea. The immediate feedback to the user is questionable, but it all depends on your particular tastes or, more importantly, the user's particular needs.
I advocate putting some of the data validation into the database because I have frequently discovered that someone will go into the database to edit data, thereby bypassing the application logic. Although this is the least desirable situation, it does happen and the application needs to be prepared to handle it. Also, if another application is going directly into the database (again, not the best situation), some aspects of the data should be checked because the application is bypassing a majority of the business logic. You should put these checks into the database as check constraints, referential integrity checks, triggers, and default values. I do not advocate putting business logic into stored procedures. You should tie the logic directly to the tables in which the data is going to be inserted.
User-Centric Business Logic
The user-centric business logic should, in a perfect world, check for only one thing: that the data falls within the limits of the database constraints. These types of checks would generally be to validate the maximum length of a string or that a value cannot be null. If there is a column defined in the database as varchar(20) and the user enters a value that is 26 characters in length, this would violate the database constraint. The reason for these checks being performed in the user-centric logic is mostly for performance reasons. Why should the application make a call to the remote components if there is absolutely no possibility of the data being right? It simply wastes processing power on the server and network band-width. Another reason is to give immediate feedback to users on mistakes they have made. When I talk with users about how they want errors reported to them, they mostly say they want to know when they have an error immediately after they make it. In most cases, this just is not practical in a distributed application, but the user-centric logic helps you move toward the user's needs.
Data-Centric Business Logic
The data-centric business logic contains all of the application's logic. It contains both database constraint validation and true business logic validation. This is the component placed on the application server. All of the rules that are checked in the user-centric component must also be checked again, and all of the rules stored in the database should be checked here as well. The real power of the data-centric business logic is its ability to get information from the database in a fast manner to validate the data stored in the object.
Take, for instance, an example in which an employee can get no more than a 5-percent raise each year. Let's assume this percentage is stored in a table in the database so that it can be easily changed. When the user enters the pay raise amount and saves the record, the business rule may require that the pay raise entered is checked against the value in this table. So, the data-centric object will retrieve this value from the database to validate the data it has been given. This is a much faster solution than making a call to the application server and from there to the database from the user's workstation. In some circumstances, you may have to validate the data between systems that the user interface knows nothing about. In that case, the only option is to perform the validation in the data-centric objects.
Introducing the Data Layer
Finally, we come to the data layer, which in this case is the database. The database consists of tables of data, stored procedures, views, and various mechanisms to constrain the data entered into the tables. The only business logic contained in the database should be the logic associated with the table columns, as mentioned previously. One important thing to consider when designing the database is how tightly the data layer is tied to the data-centric objects. When designing an application, you must take into account the likeliness of moving to a different RDBMS in the future and what the capabilities of that database might be.
For example, SQL Server can return multiple result sets from a single stored procedure, but Oracle cannot. So if you use stored procedures for data retrieval, think about the amount of work that might be necessary if you have to change the database you are using. Another issue to consider when using stored procedures to access data is the amount of dependency your objects will have on the format of those stored procedures. SQL Server allows you to pass parameters to a stored procedure out of order, but Oracle does not. If you have to change databases, you may end up having to rewrite a large majority of the code in the data-centric objects. You can—and should—plan for situations such as these.
If you look at the difference between Figure 1-3 and Figure 1-5, you will see that moving from a three-tier application to an n-tier application is a matter of how the components are hosted.
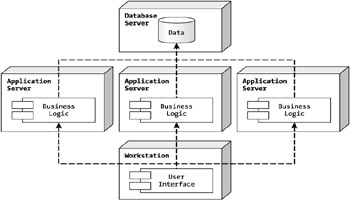
Figure 1-5: An n-tier application design
The physical difference is that you can have as many computers as you need to host the business logic, and the application will be load balanced (see the sidebar "Communicating across Process Boundaries"). The one major advantage of an n-tier architecture over a standard three-tier architecture is that an n-tier application is highly available. In other words, if you have three application servers and two of them go down, you can still run the application. In a three-tier architecture, if the application server goes down, so does the application. This is not a pretty thought in a modern business environment.
Currently, you accomplish cross-process communication (now referred to as process boundaries) by one of three means. The first is via the Distributed Component Object Model (DCOM). All of the developers who have used DCOM will attest to the amount of work, hardships, and frustrations they have gone through to make it work correctly. When it does work, it works great. It makes the component location transparent to the calling code and allows you to call methods on it without doing a whole lot of work. It is the configuration part that is difficult.
The next means of cross-process communication is Microsoft Transaction Server (MTS). This provides even more functionality (especially for a large number of concurrent database accesses) than DCOM and is easy to configure. There are a number of steps involved to make the configuration work, but it is no longer a mystical type of process. MTS allows the application server to be involved in transactions with the database. On top of the database making sure a transaction commits the right way, there is the additional backup of MTS. It also allows several transactions to be called at once but treats them as one atomic transaction. This does not come without a small price, though: The code placed into MTS needs to be modified to tell MTS whether there is an error. Granted, the code is simple, but it is still extra work. MTS also gives rise to what Microsoft now calls code-access security. With MTS you have the ability to invoke the CallerIsInRole method to determine how the user logged onto MTS (which could be Windows authentication) and allow code to make decisions based on their security level.
Finally, there is COM+. COM+ simplifies the MTS model a little and adds some more features and ease of use, but it is basically built on the same technology as MTS.
For more information on these technologies, go to the Microsoft Knowledge Base Web site (http://support.microsoft.com/default.aspx?scid=fh;[ln];kbhowto).
Exploring the Benefits of N-Tier Architecture
The three-tier, or n-tier, architecture provides several advantages over a two-tier client/server architecture.
Loosely Coupled
N-tier applications are loosely coupled, which means that the different parts of the application (presentation, business logic, and data) are basically independent of each other. For example, the data sits in a database on the server, and any application that wants to use it can. The business logic processes data and for the most part does not care in which type of database the data is stored or through which type of interface the user enters the data. The presentation layer displays data. It does not care about the data itself or the application logic because it does not process or manipulate the data.
Even though the three layers are loosely coupled, you still need to take into account some coupling. These couplings mostly depend on the particular circumstances of the application and the changes you may need to make in the future.
Encapsulated
All of the functionality of each layer is encapsulated in one location within the application. If you wanted to change the business logic layer, instead of replacing several parts of the application (as you would have to do with a two-tier implementation), you only need to replace one small section that does not affect the presentation or data layer. The same goes for replacing or altering parts of the data or presentation layers. Although there are some changes that you may need to make when altering the data layer, these are mostly minor and deal with column names or connection settings. If the business logic or data layer needs to change, the entire application does not need to be redistributed, and it can continue to be used without interruption.
Scalable
Scalability is really what makes an application an n-tier application. All of the other benefits are applicable to both three-tier and n-tier applications. Scalability is the ability of an application to grow and handle more load than it was originally developed for. This is an important point because an enterprise application is rarely built to be used by 500,000 people in the beginning. Usually, the number of users ramps up gradually as the business realizes how valuable the application can be to other parts of the business. You should design all three-tier applications to move to n-tier applications. To make an application scalable, it must be able to have its business logic spread out over many machines and have this location be transparent to the user interface and the database. If you design the application correctly using .NET, you do not need to do additional work to move the application from three tiers to n tiers. The "Exploring How .NET Scales Applications" section explains how .NET implements this scalability.
Extensible
An n-tier application can be extended transparently. That is, you can add additional functionality without breaking the existing functionality. In part, you can achieve this using an object-oriented design when building any size application, but even this does not keep you from having to rework large parts of the code in a two-tier application to add functionality. With the three-tier design, you can add functionality with less work because of the separation of functionality.
Maintainable
Most people tend to overlook whether an application is maintainable, and this often causes the greatest amount of difficulty later. I have not been involved in a business that has not changed its business processes on a daily, monthly, or yearly basis (depending on the type of business). An application that cannot be maintained is a useless application. Even though it may work at the time that it is built, in most cases you will find that by the time you are done building the application some part of the business has already changed! If your application cannot handle the changes, then it is broken before it ever gets used. I have heard developers lament too many times that the application they wrote does what it was supposed to do. Only, they seem to have forgotten that what it is supposed to do is support the business, which changes over time. Rarely is this a good or acceptable excuse in today's fast-moving business environment. I cannot stress this enough: For an application to be considered successful, it must be able to be changed easily and inexpensively.
So, how does having three tiers make an application more maintainable? It helps in speed of change and cost. If a business rule changes, the business logic layer can change easily enough—you do not need to re-deploy the application. What if the business decides to move to a Web-based system? If everything is coded in the forms, the task is impossible, and it is better to rewrite the application. If the presentation layer is separate from everything else, then you only have to code up the navigation and forms, but the bulk of the application is intact. What if another application wants to use the business logic you built into your application? Simple. Let them have access to your components or, with .NET, build a Web service (you will write and consume your own Web service in Chapter 11, "Web Services and the UDDI"). In a two-tier application you would have to provide the other application with the logic that you use and then they would have to incorporate it in their application. This sounds like a simple prospect because you do not have to do any work. But what happens when the business logic changes? Then, not only do you have to change your code, but so does the other application. Trying to keep these changes in sync is impossible in a large enterprise (or even a small enterprise).
Application deployment is the location of the physical components that make up the application and the computers on which those components reside. It helps to map out the communication that needs to take place between the components as well as the references between components. Figure 1-4 depicts a Unified Modeling Language (UML) diagram that is both a deployment and component diagram. This was created with Visio for Enterprise Architects, which ships with the enterprise version of Visual Studio .NET. It is not a strict UML diagram in the sense that there is a database object represented on the diagram. This object does not exist in the UML language, but I have chosen to use it to represent the database here. The nodes (square boxes) represent the deployment part of the diagram and each node represents a computer. The components are displayed inside the nodes to depict where the components will reside physically. This diagram gives you an overall understanding of not only where everything will live, but also of the process boundaries that exist.
The layout of the physical architecture is important to complete before the application development has begun. A change in the component layout may force changes in references, how objects are instantiated, and how they are called. Typically, if a components location must change late in the development cycle, then the change could cause a great deal of rework. Having a deployment diagram finalized before coding begins is always the best idea.
I recommend you create a diagram like this for every project so you understand where your code will go in the final application. Note the diagram in Figure 1-6, which corresponds with Figure 1-4 except that it is a high-level overview of the application structure. Notice that Figure 1-6 is almost identical to Figure 1-4 except that the components are named in Figure 1-4 and the relationship between the components, and not the computers, are illustrated. Figure 1-6 would be something that is shown to a business user, and Figure 1-3 is how a developer should see it. Each diagram is a valid design and deployment diagram that can help everyone understand the overall design of the application.
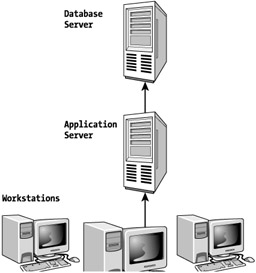
Figure 1-6: High-level architecture diagram
EAN: 2147483647
Pages: 148
- Step 1.1 Install OpenSSH to Replace the Remote Access Protocols with Encrypted Versions
- Step 1.2 Install SSH Windows Clients to Access Remote Machines Securely
- Step 2.1 Use the OpenSSH Tool Suite to Replace Clear-Text Programs
- Step 3.3 Use WinSCP as a Graphical Replacement for FTP and RCP
- Appendix - Sample sshd_config File