Introducing N-Tier Architecture
A three-tier (or n-tier, I explain the difference shortly) application is when the application components are spread out over three or more computers and there is a high degree of separation between the user interface, business logic and data access, and the data components. If there is no degree of separation, you are bound to have a failed application when it is time to perform maintenance. This separation is referred to as a loosely coupled design. We discuss these concepts later in the "Exploring the Benefits of N-Tier Architecture" section. From a logical perspective, this separation typically looks like Figure 1-3.
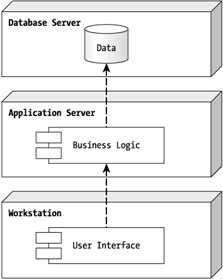
Figure 1-3: A typical three-tier application design
Notice in Figure 1-3 that the center node is called the Application Server and that it hosts, in the logical design, only the business logic components. In any application, the application is the part of the system that controls the application's logic. The database is just a place to store the data and the user interface is just the means to get that data there, but the business logic contains all of the functionality for dealing with data. As you start writing this application, you will see that the business logic is the most important component of any application.
EAN: 2147483647
Pages: 148