Indexing Concepts
3 4
Now that you have a basic understanding of index structure, let's look at some of the more general concepts of indexing. In this section, you'll learn about index keys, index uniqueness, and types of indexes.
Index Keys
An index key designates the column or columns that are used to generate the index. The index key is the value that enables you to quickly find the row that contains the data you are interested in, much like an index entry in a book points you to a particular topic in the text. To access the data row by using the index, you must include the index key value or values in the WHERE clause of the SQL statement. How this is accomplished depends on whether the index is a simple index or a composite index.
Simple Indexes
A simple index is an index that is defined on only one table column, as illustrated in Figure 17-4. This column must be referenced in the WHERE clause of the SQL statement in order for this index to be used to satisfy the statement.

Depending on the type of data being stored, the number of unique items in the column, and the type of SQL statements being used, a simple index can be effective. In other cases, a composite index is necessary. For example, if you are indexing an address book with thousands of names and addresses, the state column would not be a good candidate for a simple index because there would be many entries for the same state. However, by adding the columns street and city to the index, thereby making it a composite index, you can make each entry almost unique. This step would be helpful if you used queries that looked up rows according to the address.
Composite Indexes
A composite index is an index defined on more than one column, as illustrated in Figure 17-5. A composite index can be accessed by using one or more index keys. With SQL Server 2000, an index can comprise up to 16 columns, and its key columns can be as long as 900 bytes.

For the queries that involve a composite index, you do not need to place all the index keys in the WHERE clause of an SQL statement, but it is wise to use more than one of them. For example, if an index is created on columns a, b, and c of a table, the index can be accessed by using a SELECT statement that contains (a AND b AND c) or (a AND b) or a. Of course, using a more restrictive WHERE clause, such as one that contains a AND b AND c, will provide better performance. It will most likely retrieve fewer rows from the database because it identifies a row more specifically. If you use a and b or just a, you will initiate an index scan.
An index scan occurs because more than one index entry satisfies the search criteria. In an index scan, the nodes within an index are scanned to retrieve multiple data records. Furthermore, the index partially covers the value that has been selected. For example, if the index has been created on columns a, b, and c and the query specifies only column a, all rows that satisfy that value of a will be returned, for all values of b and c.
Because the columns on which the index is based are ordered numerically, SQL Server Query Optimizer can determine the range of index pages that might contain the desired data. Once the starting and ending pages are known, all of the pages that contain the data values will be retrieved, and the data will be scanned to select the requested data.
REAL WORLD A Customer Location Table
Suppose we have a table that contains information about the location of customers of our business. An index is created on the columns state, county, and city and is stored in the B-tree structure in the following order: state, county, city. If a query specifies the state column value as Texas in the WHERE clause, the index will be used. Because values for the county and city columns are not given in the query, the index will return a number of rows based on all of the index records that contain Texas as the state column value. An index scan is used to retrieve a range of index pages and then a number of data pages based on values in the state column. The index pages are read sequentially in the same way that a table scan accesses data pages.
NOTE
The index can be used only if at least one of the index keys are in the WHERE clause of the SQL query. Continuing the previous example, a query with only a name or phone number in the where clause would not use the index.
In most cases, an index scan will be fairly efficient; however, if more than 20 percent of the rows in the table are accessed, it is more efficient to perform a table scan, in which all the rows are read from the table. The efficiency of queries using an index depends on how you use the index (described in the section "Using Indexes" later in the chapter) and on index uniqueness, which we'll look at next.
Index Uniqueness
You can define a SQL Server index as either unique or nonunique. In a unique index, each index key value must be unique. A nonunique index allows index keys to be duplicated in the table data. The effectiveness, or efficiency, of a nonunique index will depend on the selectivity of the index.
Unique Indexes
A unique index contains only one row of data for each index key—in other words, index key values cannot appear in the index more than once. Unique indexes work well because they guarantee that only one more I/O operation is needed to retrieve the requested data. SQL Server enforces the unique property of an index on the column or combination of columns that make up the index key. SQL Server will not allow a duplicate key value to be inserted into the database. If you attempt to do so, an error will result. SQL Server creates unique indexes when you create either a PRIMARY KEY constraint or a UNIQUE constraint on a table. The PRIMARY KEY and UNIQUE constraints are described in Chapter 16.
An index can be made unique only if the data itself is unique. If the data in a column does not contain unique values, you can still create a unique index by using a composite index. For example, the last name column might not be unique, but by combining the data in this column with the first name and middle name columns, you might be able to create a unique index on the table.
NOTE
If you attempt to insert a row in a table that will create a duplicate index key value in a unique index, the insert will fail.
Nonunique Indexes
A nonunique index works in the same manner as a unique index except that it can contain duplicate values in the leaf nodes. All duplicate values will be retrieved if they match the criteria specified in the SELECT statement.
A nonunique index is not as efficient as a unique index because it requires additional processing (additional I/O operations) in order to retrieve the requested data. But because some applications require using duplicate keys, it is sometimes impossible to create a unique index. In those cases, a nonunique index is often better than no index at all.
Types of Indexes
There are two types of B-tree indexes: clustered indexes and nonclustered indexes. A clustered index stores the actual rows of data in its leaf nodes. A nonclustered index is an auxiliary structure that points to data in a table. In this section, we'll look at the differences between these two index types. You'll also be introduced to the full-text index, which is actually more of a catalog than an index, in this section.
Clustered Indexes
As mentioned, a clustered index is a B-tree index that stores the actual row data of the table in its leaf nodes, in sorted order, as illustrated in Figure 17-6. This system offers several benefits and several disadvantages.
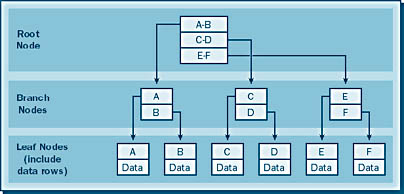
Because the data in a clustered index is stored in the leaf nodes, once the leaf node is reached, the data is available, which can result in a smaller number of I/O operations. Any reduction in these operations will yield higher performance for the individual operation and greater overall performance for the system.
Another advantage of clustered indexes is that the retrieved data will be in index-sorted order. For example, if a clustered index is created on the state, county, and city columns and a query selects all values for which state ? Texas, the resulting output will be sorted on county and city in the order in which the index was defined. This feature can be used to avoid unnecessary sort operations if the application and the database have been carefully designed. For example, if you know that you will always need to sort data in a certain way, using a clustered index means you will not need to perform the sort after the data retrieval.
One disadvantage of using a clustered index is that access to the table always occurs through the index, which can result in additional overhead. SQL Server begins data access at the root node and traverses the index until it reaches the leaf node containing the data. If many leaf nodes are created because of the volume of data, the number of index levels necessary to support that many leaf nodes is also large, which requires more I/O operations for SQL Server to travel from the root node to the leaf node.
Because the actual data is stored in the clustered index, you cannot create more than one clustered index on a table. On the other hand, you can create nonclustered indexes on top of a clustered table. (A clustered table is simply a table that has a clustered index.) You should create your clustered index using the most commonly accessed index keys—doing so will give you the best chance of accessing the data through the clustered index and will thus provide the best performance.
Nonclustered Indexes
Unlike the clustered index, the nonclustered index does not contain actual table data in its leaf nodes. The leaf nodes can contain one of two types of data row location information. First, if there is no clustered index on a table, nonclustered indexes on that table store Row IDs in their leaf nodes, as illustrated in Figure 17-7. Each Row ID points to the actual data row in the table. The Row ID consists of a value that includes the data file ID, the page number, and the row in the page. This value enables quick access to the actual data by pinpointing where the data is stored.
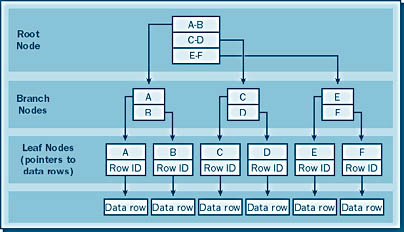
If there is a clustered index on the table, nonclustered indexes will contain the clustered index key value for that data in the leaf node, as shown in Figure 17-8. When the leaf node of the nonclustered index is reached, the clustered key value found there is used to search the clustered index, where the data row will be found in its leaf node.
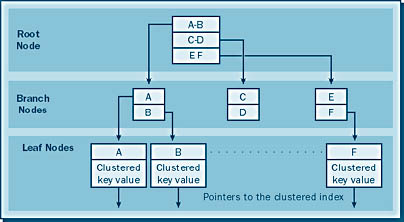
As mentioned, you can have only one clustered index per table. You can create 249 nonclustered indexes per table, but doing so might not be wise, as explained in the "index guidelines" section later in this chapter. It is common to have several nonclustered indexes on various columns in a table. The predicate in the WHERE clause will be used by Query Optimizer to determine which index is used.
Full-Text Indexes
As mentioned, a SQL Server full-text index is actually more like a catalog than an index, and its structure is not a B-tree. The full-text index allows you to search by groups of keywords. The full-text index is part of the Microsoft Search service; it is used extensively in Web site search engines and in other text-based operations.
Unlike B-tree indexes, a full-text index is stored outside the database but is maintained by the database. Because it is stored externally, the index can maintain its own structure. The following restrictions apply to full-text indexes:
- A full-text index must include a column that uniquely identifies each row in the table.
- A full-text index also must include one or more character string columns in the table.
- Only one full-text index is allowed per table.
- A full-text index is not automatically updated as B-tree indexes are. That is, in a B-tree index, a table insert, update, or delete operation will update the index. With the full-text index, these operations on the table will not automatically update the index. Updates must be scheduled or run manually.
The full-text index has a wealth of features that cannot be found in B-tree indexes. Because this index is designed to be a text search engine, it supports more than standard text-searching capabilities. Using a full-text index, you can search for words or phrases, single words or groups of words, or words that are similar to each other. You'll learn how to create a full-text index in the section "Using the Full-Text Indexing Wizard" later in this chapter.
EAN: N/A
Pages: 264
- Chapter VI Web Site Quality and Usability in E-Commerce
- Chapter VIII Personalization Systems and Their Deployment as Web Site Interface Design Decisions
- Chapter X Converting Browsers to Buyers: Key Considerations in Designing Business-to-Consumer Web Sites
- Chapter XII Web Design and E-Commerce
- Chapter XVI Turning Web Surfers into Loyal Customers: Cognitive Lock-In Through Interface Design and Web Site Usability