Understanding Workstation Inventory
To better help you understand how to make the most of the workstation inventory feature of ZENworks for Desktops, you need to know how the process works and which components are involved. The following sections describe the inventory process, the servers that are involved, and the roles they play in various inventory database designs. Understanding the Inventory ProcessThe inventory process is the act of acquiring hardware and software information from the workstation, relaying that information to the inventory server, and then storing it into a database for later retrieval. The following sections describe how workstations are scanned, how inventory data is rolled up to the database, what information is collected, and the files and directories involved. Workstation ScanningWorkstation scanning is done by an application that runs on the workstation. The inventory scanner and all necessary components were installed on the workstation when the ZENworks Management Agent was installed. That application scans the workstation and collects data based on the configurations of the inventory settings. If the workstation is Desktop Management Interface (DMI)-compliant or Web-based Management Interface (WMI)-compliant, the scanner can also query the DMI and WMI service layers to collect data. Once the scanner has collected information about the workstation, it stores it in an .STR file in the scan directory of the inventory server. The scanner tracks the changes in the scan data by storing it in the HIST.INI file, located in the ZENworks installation directory. Any errors that the scanner reports are stored in the ZENERRORS.LOG file, located in the ZENworks installation directory. Workstation inventory scanning uses the following steps to update the inventory server and eDirectory:
Inventory Data Roll UpNow that you understand how the inventory scan process works, you need to understand how that information is rolled up to other servers and databases that are higher in the tree. In many networks, one server is not enough to collect and store inventory data for every workstation in the tree. For this reason, you can configure multiple servers to collect inventory data and roll that information up to other servers. ZENworks uses the following steps to roll up scanned data once it has been collected on a server:
What Software Information Is RecordedThe scan program scans the workstation software for Desktop Management Interface (DMI) software as well as WMI (Web-based Management Interface) systems. Even if both of these are not present, the scanner will contact the hardware directly and then continue to scan the drive for installed software. The software scan performs the following functions based on its setup and configuration:
Inventory Files and DirectoriesWorkstation inventory uses several files and directories during the scanning and roll up processes. You should be aware of the following files used during the scanning and roll up process:
Once the scan program runs and the hardware and software information about the server is recorded, that information is stored on the inventory servers in the following directory locations:
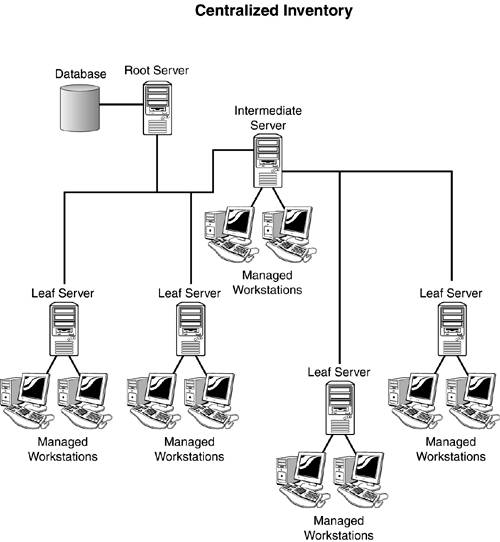
Understanding Inventory Database Server TypesNow that you understand how the scan process works, you need to understand what happens to the data that is scanned by the workstations. That data is stored in directories and databases located on inventory servers. The following sections describe the types of servers used in the inventory process. Root ServerThe root server acts as the highest point in the inventory tree. A root server by default must have a database attached to it. The root server can collect data from intermediate servers, leaf servers, or from workstations attached to it. A root server can be configured only to receive data, not to roll it up to another level. Intermediate ServerThe intermediate server acts as a staging server to receive data from a lower server in the tree and send it to another intermediate server or to a root server. By default, the intermediate server does not have a database, nor does it have workstations. However, you can configure the intermediate server to have both workstations and a database attached to it. The intermediate server typically receives data from a leaf server or another intermediate server and then rolls it up higher in the tree, eventually to the root server. Leaf ServerThe leaf server gathers inventory information from workstations. By default, the leaf server must have workstations attached, but does not have a database attached to it. The leaf server simply gathers data and rolls it up higher in the tree. Typically the data is rolled up to an intermediate server, but a leaf server can also roll data up to a root server. Stand-Alone ServerThe stand-alone server acts as a single point of inventory data collection for workstations. The stand-alone server must have both a database and workstations attached to it. The data collected by a stand-alone server cannot be rolled up to another server, nor can information collected by a leaf server be rolled up to a stand-alone server. Typically the stand-alone server is used in small networks where only one inventory server is needed to collect data. Understanding Inventory Server RolesNow that you understand the types of servers that are used for workstation inventory, you need to know the roles they can provide. Depending on their types, each server can be configured to perform one or both of the following two roles. Workstations AttachedThe first role servers can perform is to have workstations attached. Setting this option means that this server accepts data from the scan programs being run at the workstations. At least one server on the network must be performing this role, but usually most of the servers configured for workstation inventory will be performing the role of collecting data from the workstations. Leaf servers and stand-alone servers always have this option set, but you can configure root server and intermediate servers to have workstations attached as well. Database AttachedThe next role a server can perform is to have a database attached to it. Setting this option means that the server is configured to enter the information scanned by the workstation, either locally or up from a server below, into a local database. This means that a database must be running on the server to accept the information from ZENworks. Root servers and stand-alone servers always have this option set, but you can configure intermediate servers and leaf servers to have a database as well. Workstation Inventory DesignNow that you understand the types of servers and the roles they play in workstation inventory, you need to design an inventory tree that matches your network. The following sections describe some common designs for generic networks. Stand-Alone InventoryThe stand-alone inventory is the simplest design. Only one server is involved. That server acts as the collection and storage service for inventory data scanned from workstations. It has an inventory database installed on it and workstations attached. This type of design is perfect for smaller networks with 5,000 or fewer work stations. It is easy to maintain and configure; however, it is not scalable. Centralized InventoryThe centralized inventory design, shown in Figure 13.1, is for large networks where all servers are connected on a LAN. In this approach allowance is made for a larger number of users by adding a number of leaf and intermediate servers for workstation scanners to send their data to. Figure 13.1. The centralized workstation inventory design.
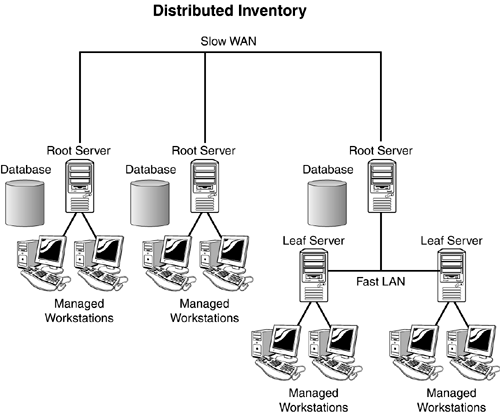
The centralized inventory approach is still fairly easy to maintain; however, roll up policies must be configured for the intermediate and leaf servers. Distributed InventoryThe distributed inventory design, shown in Figure 13.2, is for large networks where several remote sites are connected through a WAN. In this approach allowance is made for a larger number of users by creating several root servers, one at each remote site, and then leaf and intermediate servers for workstation scanners to send their data to. Figure 13.2. The distributed workstation inventory design.
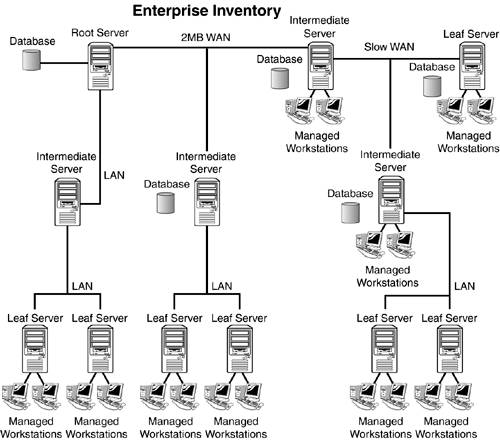
The distributed inventory approach is still much more difficult to maintain because you need to manage several inventory trees. However the distributed approach overcomes problems that can occur, rolling up large numbers of workstations from remote offices. Enterprise InventoryThe final type of inventory design is the enterprise inventory design shown in Figure 13.3. Most enterprise networks take this approach in one form or another. In the enterprise design, accommodations for the large number of users, yet a single management point, is made by creating a single root server and then interlacing intermediate and leaf servers at strategic locations in the network to insure optimal performance. Figure 13.3. The enterprise workstation inventory design.
The best way to achieve an optimal enterprise design is to follow the steps outlined in the following sections. List the Sites in the EnterpriseThe first step in designing an enterprise workstation inventory tree is to describe the entire network of your company by doing the following:
Determine the Ideal Place for Root ServerOnce you have listed the sites in your enterprise network, you need to determine the best place to put the root server. The inventory information stored in the inventory database of the root server consists of all lower-level sites on the network as well as the root server site. The location of the root server determines the behavior and scalability of your inventory tree. You should consider the following factors when determining its location:
Determine Requirements for Other DatabasesNow that you have determined the location of the root server, you need to determine if you need to maintain database servers at different sites. You might want to maintain additional databases if sites or sub-trees are managed for inventory at different locations over a slow link. You should also consider specific reasons to have a separate database for a single site or a set of sites. Your company might have organizational needs that require the database server to be on different sites. NOTE For a majority of enterprises, there is no need to have any other database besides the enterprise-wide single database. All site-specific reports can be generated from this database easily. If you determine that another database is required, consider the following to determine the appropriate location and setup:
Identify the Route for Inventory DataOnce you have determined any additional databases needed, you need to identify the routes for inventory data for all sites to the nearest database. From those routes, you then need to determine the final route to the database on the root server. The route plan can become complex, so to help devise a route plan, follow these guidelines:
Identify Servers on Each Site for Inventory, Intermediate, and DatabaseOnce you have planned the routes that the data will take to the root server, you need to identify servers on each site to perform the roles necessary to achieve the route. Specifically you need to identify servers to act as inventory, intermediate, and database server. A single server can have different roles if it has sufficient resources. For example, an inventory server can be a leaf server with a database. You can also designate a server as an intermediate server with a database, which receives inventory from the workstations and also has an inventory database. When considering the roles of the server, consider the following factors:
Create the Tree of Servers for Workstation InventoryOnce you have determined the roles that inventory servers will take at each site, you need to create the tree of servers that will be used for workstation inventory. Once you have the inventory server tree designed, make certain that the following are true:
Create an Implementation PlanOnce you have designed your inventory server tree, you need to create an implementation plan. The implementation plan should cover the phased deployment of inventory throughout the network. To help with creating an implementation plan, use the following guidelines:
|
EAN: 2147483647
Pages: 198