Syntax
The following statements are available in PROC PRINQUAL.
-
PROC PRINQUAL < options > ;
-
TRANSFORM transform( variables < / t-options > )
-
< transform(variables < / t-options > ) > ;
-
-
BY variables ;
-
FREQ variable ;
-
ID variables ;
-
WEIGHT variable ;
-
To use PROC PRINQUAL, you need the PROC PRINQUAL and TRANSFORM statements. You can abbreviate all options and t-options to their first three letters . This is a special feature of PROC PRINQUAL and is not generally true of other SAS/STAT procedures.
The rest of this section provides detailed syntax information for each of the preceding statements, beginning with the PROC PRINQUAL statement. The remaining statements are described in alphabetical order.
PROC PRINQUAL Statement
-
PROC PRINQUAL < options > ;
The PROC PRINQUAL statement starts the PRINQUAL procedure. Optionally, this statement identifies an input data set, creates an output data set, specifies the algorithm and other computational details, and controls displayed output. The following table summarizes options available in the PROC PRINQUAL statement.
| Task | Option |
|---|---|
| Identify input data set | |
| specifies input SAS data set | DATA= |
| Specify details for output data set | |
| outputs approximations to transformed variables | APPROXIMATIONS |
| specifies prefix for approximation variables | APREFIX= |
| outputs correlations and component structure matrix | CORRELATIONS |
| specifies a multidimensional preference analysis | MDPREF |
| specifies output data set | OUT= |
| specifies prefix for principal component scores variables | PREFIX= |
| replaces raw data with transformed data | REPLACE |
| outputs principal component scores | SCORES |
| standardizes principal component scores | STANDARD |
| specifies transformation standardization | TSTANDARD= |
| specifies prefix for transformed variables | TPREFIX= |
| Control iterative algorithm | |
| analyzes covariances | COVARIANCE |
| initializes using dummy variables | DUMMY |
| specifies iterative algorithm | METHOD= |
| specifies number of principal components | N= |
| suppresses numerical error checking | NOCHECK |
| specifies number of MGV models before refreshing | REFRESH= |
| restarts iterations | REITERATE |
| specifies singularity criterion | SINGULAR= |
| specifies input observation type | TYPE= |
| Control the number of iterations | |
| specifies minimum criterion change | CCONVERGE= |
| specifies number of first iteration to be displayed | CHANGE= |
| specifies minimum data change | CONVERGE= |
| specifies number of MAC initialization iterations | INITITER= |
| specifies maximum number of iterations | MAXITER= |
| Specify details for handling missing values | |
| includes monotone special missing values | MONOTONE= |
| excludes observations with missing values | NOMISS |
| unties special missing values | UNTIE= |
| Suppress displayed output | |
| suppresses displayed output | NOPRINT |
The following list describes these options in alphabetical order.
APREFIX= name
APR= name
-
specifies a prefix for naming the approximation variables. By default, APREFIX=A. Specifying the APREFIX= option also implies the APPROXIMATIONS option.
APPROXIMATIONS
APPROX
APP
-
includes principal component approximations to the transformed variables (Eckart and Young 1936) in the output data set. Variable names are constructed from the value of the APREFIX= option and the input variable names. If you specify the APREFIX= option, then approximations are automatically included. If you specify the APPROXIMATIONS option and not the APREFIX= option, then the APPROXIMATIONS option uses the default, APREFIX=A, to construct the variable names .
CCONVERGE= n
CCO= n
-
specifies the minimum change in the criterion being optimized that is required to continue iterating. By default, CCONVERGE=0.0. The CCONVERGE= option is ignored for METHOD=MAC. For the MGV method, specify CCONVERGE=-2 to ensure data convergence.
CHANGE= n
CHA= n
-
specifies the number of the first iteration to be displayed in the iteration history table. The default is CHANGE=1. When you specify a larger value for n , the first n ˆ’ 1 iterations are not displayed, thus speeding up the analysis. The CHANGE= option is most useful with the MGV method, which is much slower than the other methods .
CONVERGE= n
CON= n
-
specifies the minimum average absolute change in standardized variable scores that is required to continue iterating. By default, CONVERGE=0.00001. Average change is computed over only those variables that can be transformed by the iterations, that is, all LINEAR, OPSCORE, MONOTONE, UNTIE, SPLINE, MSPLINE, and SSPLINE variables and nonoptimal transformation variables with missing values. For more information, see the section Optimal Transformations on page 3662.
COVARIANCE
COV
-
computes the principal components from the covariance matrix. The variables are always centered to mean zero. If you do not specify the COVARIANCE option, the variables are also standardized to variance one, which means the analysis is based on the correlation matrix.
CORRELATIONS
COR
-
includes correlations and the component structure matrix in the output data set. By default, this information is not included.
DATA = SAS-data-set
-
specifies the SAS data set to be analyzed . The data set must be an ordinary SAS data set; it cannot be a TYPE=CORR or TYPE=COV data set. If you omit the DATA= option, the PRINQUAL procedure uses the most recently created SAS data set.
DUMMY
DUM
-
expands variables specified for OPSCORE optimal transformations to dummy variables for the initialization (Tenenhaus and Vachette 1977). By default, the initial values of OPSCORE variables are the actual data values. The dummy variable nominal initialization requires considerable time and memory, so it might not be possible to use the DUMMY option with large data sets. No separate report of the initialization is produced. Initialization results are incorporated into the first iteration displayed in the iteration history table. For details, see the section Optimal Transformations on page 3662.
INITITER= n
INI= n
-
specifies the number of MAC iterations required to initialize the data before starting MTV or MGV iterations. By default, INITITER=0. The INITITER= option is ignored if METHOD=MAC.
MAXITER= n
MAX= n
-
specifies the maximum number of iterations. By default, MAXITER=30.
MDPREF
MDP
-
specifies a multidimensional preference analysis by implying the STANDARD, SCORES, and CORRELATIONS options. This option also suppresses warnings when there are more variables than observations.
METHOD=MAC MGV MTV
MET=MAC MGV MTV
-
specifies the optimization method. By default, METHOD=MTV. Values of the METHOD= option are MTV for maximum total variance, MGV for minimum generalized variance, or MAC for maximum average correlation. You can use the MAC method when all variables are positively correlated or when no monotonicity constraints are placed on any transformations. See the section The Three Methods of Variable Transformation on page 3643.
MONOTONE= two-letters
MON= two-letters
-
specifies the first and last special missing value in the list of those special missing values to be estimated using within-variable order and category constraints. By default, there are no order constraints on missing value estimates. The two-letters value must consist of two letters in alphabetical order. For example, MONOTONE=DF means that the estimate of .D must be less than or equal to the estimate of .E, which must be less than or equal to the estimate of .F; no order constraints are placed on estimates of ._ , .A through .C, and .G through .Z. For details, see the Missing Values section on page 3667, and Optimal Scaling in Chapter 75, The TRANSREG Procedure.
N= n
-
specifies the number of principal components to be computed. By default, N=2.
NOCHECK
NOC
-
turns off computationally intensive numerical error checking for the MGV method. If you do not specify the NOCHECK option, the procedure computes R 2 from the squared length of the predicted values vector and compares this value to the R 2 computed from the error sum of squares that is a by-product of the sweep algorithm (Goodnight 1978). If the two values of R 2 differ by more than the square root of the value of the SINGULAR= option, a warning is displayed, the value of the REFRESH= option is halved, and the model is refit after refreshing. Specifying the NOCHECK option slightly speeds up the algorithm. Note that other less computationally intensive error checking is always performed.
NOMISS
NOM
-
excludes all observations with missing values from the analysis, but does not exclude them from the OUT= data set. If you omit the NOMISS option, PROC PRINQUAL simultaneously computes the optimal transformations of the nonmissing values and estimates the missing values that minimize squared error.
Casewise deletion of observations with missing values occurs when you specify the NOMISS option, when there are missing values in IDENTITY variables, when there are weights less than or equal to 0, or when there are frequencies less than 1. Excluded observations are output with a blank value for the _ TYPE_ variable, and they have a weight of 0. They do not contribute to the analysis but are scored and transformed as supplementary or passive observations. See the Passive Observations section on page 3674 and the Missing Values section on page 3667 for more information on excluded observations and missing data.
NOPRINT
NOP
-
suppresses the display of all output. Note that this option temporarily disables the Output Delivery System (ODS). For more information, see Chapter 14, Using the Output Delivery System.
OUT= SAS-data-set
-
specifies an output SAS data set that contains results of the analysis. If you omit the OUT= option, PROC PRINQUAL still creates an output data set and names it using the DATA n convention. If you want to create a permanent SAS data set, you must specify a two-level name. (Refer to the discussion in SAS Language Reference: Concepts .) You can use the REPLACE, APPROXIMATIONS, SCORES, and CORRELATIONS options to control what information is included in the output data set. For details, see the Output Data Set section on page 3669.
PREFIX= name
PRE= name
-
specifies a prefix for naming the principal components. By default, PREFIX=Prin. As a result, the principal component default names are Prin1 , Prin2 , , Prin n .
REFRESH= n
REF= n
-
specifies the number of variables to scale in the MGV method before computing a new inverse. By default, REFRESH=5. PROC PRINQUAL uses the REFRESH= option in the sweep algorithm of the MGV method. Large values for the REFRESH= option make the method run faster but with increased error. Small values make the method run more slowly and with more numerical accuracy.
REITERATE
REI
-
enables the PRINQUAL procedure to use previous transformations as starting points. The REITERATE option affects only variables that are iteratively transformed (specified as LINEAR, SPLINE, MSPLINE, SSPLINE, UNTIE, OPSCORE, and MONOTONE). For iterative transformations, the REITERATE option requests a search in the input data set for a variable that consists of the value of the TPREFIX= option followed by the original variable name. If such a variable is found, it is used to provide the initial values for the first iteration. The final transformation is a member of the transformation family defined by the original variable, not the transformation family defined by the initialization variable. See the REITERATE Option Usage section on page 3673.
REPLACE
REP
-
replaces the original data with the transformed data in the output data set. The names of the transformed variables in the output data set correspond to the names of the original variables in the input data set. If you do not specify the REPLACE option, both original variables and transformed variables (with names constructed from the TPREFIX= option and the original variable names) are included in the output data set.
SCORES
SCO
-
includes principal component scores in the output data set. By default, scores are not included.
SINGULAR= n
SIN= n
-
specifies the largest value within rounding error of zero. By default, SINGULAR=1E ˆ’ 8. The PRINQUAL procedure uses the value of the SINGULAR= option for checking (1 ˆ’ R 2 ) when constructing full-rank matrices of predictor variables, checking denominators before dividing, and so on.
STANDARD
STD
-
standardizes the principal component scores in the output data set to mean zero and variance one instead of the default mean zero and variance equal to the corresponding eigenvalue . See the SCORES option.
TPREFIX= name
TPR= name
-
specifies a prefix for naming the transformed variables. By default, TPREFIX=T. The TPREFIX= option is ignored if you specify the REPLACE option.
TSTANDARD=CENTER NOMISS ORIGINAL Z
TST=CEN NOM ORI Z
-
specifies the standardization of the transformed variables in the OUT= data set. By default, TSTANDARD=ORIGINAL. When the TSTANDARD= option is specified in the PROC statement, it specifies the default standardization for all variables. When you specify TSTANDARD= as a t-option , it overrides the default standardization just for selected variables.
CENTER
centers the output variables to mean zero, but the variances are the same as the variances of the input variables.
NOMISS
sets the means and variances of the transformed variables in the OUT= data set, computed over all output values that correspond to nonmissing values in the input data set, to the means and variances computed from the nonmissing observations of the original variables. The TSTANDARD=NOMISS specification is useful with missing data. When a variable is linearly transformed, the final variable contains the original nonmissing values and the missing value estimates. In other words, the nonmissing values are unchanged. If your data have no missing values, TSTANDARD=NOMISS and TSTANDARD=ORIGINAL produce the same results.
ORIGINAL
sets the means and variances of the transformed variables to the means and variances of the original variables. This is the default.
Z
standardizes the variables to mean zero, variance one.
For nonoptimal variable transformations, the means and variances of the original variables are actually the means and variances of the nonlinearly transformed variables, unless you specify the ORIGINAL nonoptimal t-option in the TRANSFORM statement. For example, if a variable X with no missing values is specified as LOG, then, by default, the final transformation of X is simply LOG( X ), not LOG( X ) standardized to the mean of X and variance of X .
TYPE= text name
TYP= text name
-
specifies the valid value for the _ TYPE_ variable in the input data set. If PROC PRINQUAL finds an input _ TYPE_ variable, it uses only observations with a _ TYPE_ value that matches the TYPE= value. This enables a PROC PRINQUAL OUT= data set containing correlations to be used as input to PROC PRINQUAL without requiring a WHERE statement to exclude the correlations. If a _ TYPE_ variable is not in the data set, all observations are used. The default is TYPE= SCORE , so if you do not specify the TYPE= option, only observations with _ TYPE_ = SCORE are used.
PROC PRINQUAL displays a note when it reads observations with blank values of _ TYPE_ , but it does not automatically exclude those observations. Data sets created by the TRANSREG and PRINQUAL procedures have blank _ TYPE_ values for those observations that were excluded from the analysis due to nonpositive weights, nonpositive frequencies, or missing data. When these observations are read again, they are excluded for the same reason that they were excluded from their original analysis, not because their _ TYPE_ value is blank.
UNTIE= two-letters
UNT= two-letters
-
specifies the first and last special missing value in the list of those special missing values that are to be estimated with within-variable order constraints but no category constraints. The two-letters value must consist of two letters in alphabetical order. By default, there are category constraints but no order constraints on special missing value estimates. For details, see the Missing Values section on page 3667. Also, see Optimal Scaling in Chapter 75, The TRANSREG Procedure.
BY Statement
-
BY variables ;
You can specify a BY statement with PROC PRINQUAL to obtain separate analyses on observations in groups defined by the BY variables. When a BY statement appears, the procedure expects the input data set to be sorted in order of the BY variables.
If your input data set is not sorted in ascending order, use one of the following alternatives:
-
Sort the data using the SORT procedure with a similar BY statement.
-
Specify the BY statement options NOTSORTED or DESCENDING in the BY statement for the PRINQUAL procedure. The NOTSORTED option does not mean that the data are unsorted but rather that the data are arranged in groups (according to values of the BY variables) and that these groups are not necessarily in alphabetical or increasing numeric order.
-
Create an index on the BY variables using the DATASETS procedure.
For more information on the BY statement, refer to the discussion in SAS Language Reference: Concepts . For more information on the DATASETS procedure, refer to the discussion in the SAS Procedures Guide .
FREQ Statement
-
FREQ variable ;
If one variable in the input data set represents the frequency of occurrence for other values in the observation, list the variable s name in a FREQ statement. PROC PRINQUAL then treats the data set as if each observation appeared n times, where n is the value of the FREQ variable for the observation. Noninteger values of the FREQ variable are truncated to the largest integer less than the FREQ value. The observation is used in the analysis only if the value of the FREQ statement variable is greater than or equal to 1.
ID Statement
-
ID variables ;
The ID statement includes additional character or numeric variables in the output data set. The variables must be contained in the input data set.
TRANSFORM Statement
-
TRANSFORM transform(variables < / t-options > )
-
< ... transform(variables < / t-options > ) > ;
-
The TRANSFORM statement lists the variables to be analyzed ( variables ) and specifies the transformation ( transform ) to apply to each variable listed. You must specify a transformation for each variable list in the TRANSFORM statement. The variables are variables in the data set. The t-options are transformation options that provide details for the transformation; these depend on the transform chosen . The t-options are listed after a slash in the parentheses that enclose the variables.
For example, the following statements find a quadratic polynomial transformation of all variables in the data set:
proc prinqual; transform spline(_all_ / degree=2); run;
Or, if N1 through N10 are nominal variables and M1 through M10 are ordinal variables, you can use the following statements.
proc prinqual; transform opscore(N1-N10) monotone(M1-M10); run;
The following sections describe the transformations available (specified with transform ) and the options available for some of the transformations (specified with t-options ).
Families of Transformations
There are three types of transformation families: nonoptimal, optimal, and other. Each family is summarized as follows .
| Nonoptimal transformations | preprocess the specified variables, replacing each one with a single new nonoptimal, nonlinear transformation. |
| Optimal transformations | replace the specified variables with new, iteratively derived optimal transformation variables that fit the specified model better than the original variable (except for contrived cases where the transformation fits the model exactly as well as the original variable). |
| Other transformations | are the IDENTITY and SSPLINE transformations. These do not fit into either of the preceding categories. |
The following table summarizes the transformations in each family.
| Family | Members of Family |
|---|---|
| Nonoptimal transformations | |
| inverse trigonometric sine | ARSIN |
| exponential | EXP |
| logarithm | LOG |
| logit | LOGIT |
| raises variables to specified power | POWER |
| transforms to ranks | RANK |
| Optimal transformations | |
| linear | LINEAR |
| monotonic, ties preserved | MONOTONE |
| monotonic B-spline | MSPLINE |
| optimal scoring | OPSCORE |
| B-spline | SPLINE |
| monotonic, ties not preserved | UNTIE |
| Other transformations | |
| identity, no transformation | IDENTITY |
| iterative smoothing spline | SSPLINE |
The transform is followed by a variable (or list of variables) enclosed in parentheses. Optionally, depending on the transform , the parentheses can also contain t-options , which follow the variables and a slash. For example,
transform log(X Y);
computes the LOG transformation of X and Y . A more complex example is
transform spline(Y / nknots=2) log(X1 X2 X3);
The preceding statement uses the SPLINE transformation of the variable Y and the LOG transformation of the variables X1 , X2 , and X3 . In addition, it uses the NKNOTS= option with the SPLINE transformation and specifies two knots.
The rest of this section provides syntax details for members of the three families of transformations. The t-options are discussed in the section Transformation Options (t-options) on page 3663.
Nonoptimal Transformations
Nonoptimal transformations are computed before the iterative algorithm begins. Nonoptimal transformations create a single new transformed variable that replaces the original variable. The new variable is not transformed by the subsequent iterative algorithms (except for a possible linear transformation and missing value estimation).
The following list provides syntax and details for nonoptimal variable transformations.
ARSIN
ARS
-
finds an inverse trigonometric sine transformation. Variables following ARSIN must be numeric, in the interval ( ˆ’ 1 . ‰ X ‰ 1 . 0), and they are typically continuous.
EXP
-
exponentiates variables (the variable X is transformed to a X ). To specify the value of a , use the PARAMETER= t-option . By default, a is the mathematical constant e = 2 . 718 . Variables following EXP must be numeric, and they are typically continuous.
LOG
-
transforms variables to logarithms (the variable X is transformed to log a ( X )). To specify the base of the logarithm, use the PARAMETER= t-option . The default is a natural logarithm with base e = 2 . 718 . Variables following LOG must be numeric and positive, and they are typically continuous.
LOGIT
-
finds a logit transformation on the variables. The logit of X is log( X/ (1 ˆ’ X )). Unlike other transformations, LOGIT does not have a three-letter abbreviation. Variables following LOGIT must be numeric, in the interval (0 . 0 < X < 1 . 0), and they are typically continuous.
POWER
POW
-
raises variables to a specified power (the variable X is transformed to X a ). You must specify the power parameter a by specifying the PARAMETER= t-option following the variables:
power(variable / parameter=number)
You can use POWER for squaring variables (PARAMETER=2), reciprocal transformations (PARAMETER= ˆ’ 1), square roots (PARAMETER=0.5), and so on. Variables following POWER must be numeric, and they are typically continuous.
RANK
RAN
-
transforms variables to ranks. Ranks are averaged within ties. The smallest input value is assigned the smallest rank. Variables following RANK must be numeric.
Optimal Transformations
Optimal transformations are iteratively derived. Missing values for these types of variables can be optimally estimated (see the Missing Values section on page 3667).
The following list provides syntax and details for optimal transformations.
LINEAR
LIN
-
finds an optimal linear transformation of each variable. For variables with no missing values, the transformed variable is the same as the original variable. For variables with missing values, the transformed nonmissing values have a different scale and origin than the original values. Variables following LINEAR must be numeric.
MONOTONE
MON
-
finds a monotonic transformation of each variable, with the restriction that ties are preserved. The Kruskal (1964) secondary least-squares monotonic transformation is used. This transformation weakly preserves order and category membership (ties). Variables following MONOTONE must be numeric, and they are typically discrete.
MSPLINE
MSP
-
finds a monotonically increasing B-spline transformation with monotonic coefficients (de Boor 1978; de Leeuw 1986) of each variable. You can specify the DEGREE=, KNOTS=, NKNOTS=, and EVENLY t-options with MSPLINE. By default, PROC PRINQUAL uses a quadratic spline. Variables following MSPLINE must be numeric, and they are typically continuous.
OPSCORE
OPS
-
finds an optimal scoring of each variable. The OPSCORE transformation assigns scores to each class (level) of the variable. Fisher s (1938) optimal scoring method is used. Variables following OPSCORE can be either character or numeric; numeric variables should be discrete.
SPLINE
SPL
-
finds a B-spline transformation (de Boor 1978) of each variable. By default, PROC PRINQUAL uses a cubic polynomial transformation. You can specify the DEGREE=, KNOTS=, NKNOTS=, and EVENLY t-options with SPLINE. Variables following SPLINE must be numeric, and they are typically continuous.
UNTIE
UNT
-
finds a monotonic transformation of each variable without the restriction that ties are preserved. The PRINQUAL procedure uses the Kruskal (1964) primary least-squares monotonic transformation method. This transformation weakly preserves order but not category membership (it may untie some previously tied values). Variables following UNTIE must be numeric, and they are typically discrete.
Other Transformations
IDENTITY
IDE
-
specifies variables that are not changed by the iterations. The IDENTITY transformation is used for variables when no transformation and no missing data estimation are desired. However, the REFLECT, ADDITIVE, TSTANDARD=Z, and TSTANDARD=CENTER options can linearly transform all variables, including IDENTITY variables, after the iterations. Observations with missing values in IDENTITY variables are excluded from the analysis, and no optimal scores are computed for missing values in IDENTITY variables. Variables following IDENTITY must be numeric.
SSPLINE
SSP
-
finds an iterative smoothing spline transformation of each variable. The SSPLINE transformation does not generally minimize squared error. You can specify the smoothing parameter with either the SM= t-option or the PARAMETER= t-option . The default smoothing parameter is SM=0. Variables following SSPLINE must be numeric, and they are typically continuous.
Transformation Options (t-options)
If you use a nonoptimal, optimal or other transformation, you can use t-options , which specify additional details of the transformation. The t-options are specified within the parentheses that enclose variables and are listed after a slash. For example,
proc prinqual; transform spline(X Y / nknots=3); run;
The preceding statements find an optimal variable transformation (SPLINE) of the variables X and Y and use a t-option to specify the number of knots (NKNOTS=). The following is a more complex example.
proc prinqual; transform spline(Y / nknots=3) spline(X1 X2 / nknots=6); run;
These statements use the SPLINE transformation for all three variables and use t-options as well; the NKNOTS= option specifies the number of knots for the spline.
The following sections discuss the t-options available for nonoptimal, optimal, and other transformations.
The following table summarizes the t-options .
| Task | Option |
|---|---|
| Nonoptimal transformation t-options | |
| uses original mean and variance | ORIGINAL |
| Parameter t-options | |
| specifies miscellaneous parameters | PARAMETER= |
| specifies smoothing parameter | SM= |
| Spline t-options | |
| specifies the degree of the spline | DEGREE= |
| spaces the knots evenly | EVENLY |
| specifies the interior knots or break points | KNOTS= |
| creates n knots | NKNOTS= |
| Other t-options | |
| renames variables | NAME= |
| reflects the variable around the mean | REFLECT |
| specifies transformation standardization | TSTANDARD= |
Nonoptimal Transformation t-options
ORIGINAL
ORI
-
matches the variable s final mean and variance to the mean and variance of the original variable. By default, the mean and variance are based on the transformed values. The ORIGINAL t-option is available for all of the nonoptimal transformations.
Parameter t-options
PARAMETER= number
PAR= number
-
specifies the transformation parameter. The PARAMETER= t-option is available for the EXP, LOG, POWER, SMOOTH, and SSPLINE transformations. For EXP, the parameter is the value to be exponentiated; for LOG, the parameter is the base value; and for POWER, the parameter is the power. For SMOOTH and SSPLINE, the parameter is the raw smoothing parameter. (You can specify a SAS/GRAPH-style smoothing parameter with the SM= t-option .) The default for the PARAMETER= t-option for the LOG and EXP transformations is e = 2 . 718 . The default parameter for SSPLINE is computed from SM=0. For the POWER transformation, you must specify the PARAMETER= t-option ; there is no default.
SM= n
-
specifies a SAS/GRAPH-style smoothing parameter in the range 0 to 100. You can specify the SM= t-option only with the SSPLINE transformation. The smoothness of the function increases as the value of the smoothing parameter increases . By default, SM=0.
Spline t-options
The following t-options are available with the SPLINE and MSPLINE optimal transformations.
DEGREE= n
DEG= n
-
specifies the degree of the B-spline transformation. The degree must be a nonnegative integer. The defaults are DEGREE=3 for SPLINE variables and DEGREE=2 for MSPLINE variables.
-
The polynomial degree should be a small integer, usually 0, 1, 2, or 3. Larger values are rarely useful. If you have any doubt as to what degree to specify, use the default.
EVENLY
EVE
-
is used with the NKNOTS= t-option to space the knots evenly. The differences between adjacent knots are constant. If you specify NKNOTS= k , k knots are created at
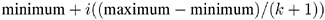
for i = 1 , ,k . For example, if you specify
spline(X / knots=2 evenly)
-
and the variable X has a minimum of 4 and a maximum of 10, then the two interior knots are 6 and 8. Without the EVENLY t-option , the NKNOTS= t-option places knots at percentiles, so the knots are not evenly spaced .
KNOTS= number-list n TO m BY p
KNO= number-list n TO m BY p
-
specifies the interior knots or break points. By default, there are no knots. The first time you specify a value in the knot list, it indicates a discontinuity in the n th (from DEGREE= n ) derivative of the transformation function at the value of the knot. The second mention of a value indicates a discontinuity in the ( n ˆ’ 1)th derivative of the transformation function at the value of the knot. Knots can be repeated any number of times for decreasing smoothness at the break points, but the values in the knot list can never decrease.
-
You cannot use the KNOTS= t-option with the NKNOTS= t-option . You should keep the number of knots small (see the section Specifying the Number of Knots on page 4613 in Chapter 75, The TRANSREG Procedure. ).
NKNOTS= n
NKN= n
-
creates n knots, the first at the 100 / ( n +1) percentile, the second at the 200 / ( n +1) percentile, and so on. Knots are always placed at data values; there is no interpolation. For example, if NKNOTS=3, knots are placed at the twenty-fifth percentile, the median, and the seventy-fifth percentile. By default, NKNOTS=0. The NKNOTS= t-option must be ‰ 0.
-
You cannot use the NKNOTS= t-option with the KNOTS= t-option . You should keep the number of knots small (see the section Specifying the Number of Knots on page 4613 in Chapter 75, The TRANSREG Procedure, ).
Other t-options
The following t-options are available for all transformations.
NAME= (variable-list)
NAM= (variable-list)
-
renames variables as they are used in the TRANSFORM statement. This option allows a variable to be used more than once. For example, if the variable X is a character variable, then the following step stores both the original character variable X and a numeric variable XC that contains category numbers in the output data set.
proc prinqual data=A n=1 out=B; transform linear(Y) opscore(X / name=(XC)); id X; run;
REFLECT
REF
-
reflects the transformation
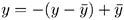
-
after the iterations are completed and before the final standardization and results calculations.
TSTANDARD=CENTER NOMISS ORIGINAL Z
TST=CEN NOM ORI Z
-
specifies the standardization of the transformed variables in the OUT= data set. By default, TSTANDARD=ORIGINAL. When the TSTANDARD= option is specified in the PROC PRINQUAL statement, it specifies the default standardization for all variables. When you specify TSTANDARD= as a t-option , it overrides the default standardization just for selected variables.
WEIGHT Statement
-
WEIGHT variable ;
When you use a WEIGHT statement, a weighted residual sum of squares is minimized. The WEIGHT statement has no effect on degrees of freedom or number of observations, but the weights affect most other calculations. The observation is used in the analysis only if the value of the WEIGHT statement variable is greater than 0.