Chapter 4. Amanda
| The purpose of this chapter is to give a brief technical overview of Amanda. We want you to understand how Amanda works, how it is different from other backup software, and how it can help you solve your data protection requirements. On the other hand, we don't want to overwhelm you with technical details that could be very specific to a particular setup or backup policy. Throughout this chapter, we provide links to the web sites where you can find up-to-date and easy to follow instructions and details about everything you need to know about deploying Amanda in production.
Amanda, the Advanced Maryland Automated Network Disk Archiver, is the most well-known open-source backup software. Amanda was initially developed at the University of Maryland in 1991 with the goal of protecting files on a large number of client workstations with a single backup server. James da Silva was one of its original developers. The Amanda project was registered on SourceForge.net in 1999. Jean-Louis Martineau of the University of Montreal has been the gatekeeper and leader of Amanda development in recent years. Over the years more than 250 developers have contributed to the Amanda codebase, and thousands of users provided testing and feedback, resulting in a stable and robust package. Amanda is included with every major Linux distribution. As of April 2006, more than 20,000 sites worldwide use Amanda.
Originally, Amanda was used in production mostly by universities, technical labs, and research departments. Today with wide adoption of Linux in IT at large, Amanda is found in many other places, especially where the focus is on applications deployed on a LAMP[ Amanda allows you to set up a single master backup server to back up multiple Linux, Unix, Mac OS X, and Windows hosts to a very large selection of tape, disk, and optical devices including tape libraries, autochangers, optical jukeboxes, RAID arrays, NAS devices, and many others. Figure 4-1 shows a typical Amanda network. Figure 4-1. Typical Amanda network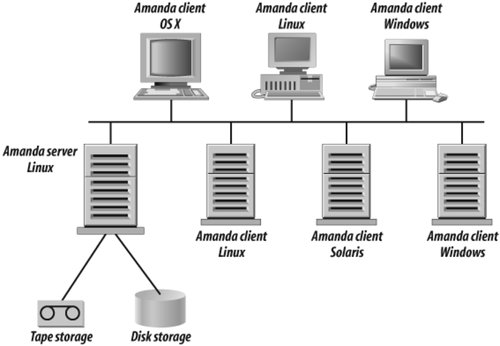 Here are a few real-life examples of Amanda in production. One company uses three Amanda servers on CentOS in three countries to protect more than 30 clients on Solaris, Linux, and Windows. Different versions of Amanda have been in production for 9 years as of this writing. The total amount of protected data is more than 500 GB and data grows at 8 GB per week on average. One of the sites performs backup to disk only, and the other two back up to both disk and LTO autoloaders. System administrators recover files at least once per week because of users erasing files by accident. A few times over the years, the company lost servers because of failed hard drives, and Amanda came to the rescue for bare-metal recovery. A major university in the United Kingdom has two Amanda servers on Fedora Core with more than 100 Linux (Fedora Core, Red Hat Enterprise Linux), Mac OS X, and Solaris clients with more that 2 TB of data. One of the Amanda servers is dedicated to backup of SAP and Oracle on Solaris. A cinematographic post-production company has three Debian Amanda servers at two sites protecting 84 Linux and IRIX clients with 26 TB of data. It recovers files about twice per week due to user error. In three years of production, it had three instances of total volume loss despite using RAID arrays, and Amanda was able to recover all three lost volumes. Throughout this chapter, we use examples of real-life Amanda implementations. Based on feedback from many Amanda users with a variety of configurations and different levels of Amanda expertise, we believe that the key reasons for wide adoption of Amanda are: Amanda simplifies your life as a system administrator because you can easily set up a single server to back up multiple networked clients to a tape, disk, or optical storage system. Amanda is optimized for backup to disk and tape. Additionally, it enables you to write backups to tape and disk simultaneously. The very same data can be available online for quick restores from disk and off-site for disaster recovery and long-term retention. Since Amanda does not use proprietary device drivers, any device supported by an operating system works well with Amanda. The system administrator does not have to worry about breaking support for a device when upgrading Amanda. Amanda uses standard utilities such as dump and GNU tar. Since these are not proprietary formats, data can be recovered with readily available standard toolseven without Amanda. Amanda's unique scheduler optimizes backup levels for different clients in such a way that total backup time is about the same for every backup run. Amanda frees the system administrators from having to guess the rate of data change in their environments. The Amanda project has attracted a large and active community that grows every day. The total cost of ownership (TCO) for a backup solution based on Amanda is significantly lower than the TCO of any solution that uses proprietary backup software. Amanda software has a source-code tarball and RPMs for most common versions of Linux, and is available from http://www.zmanda.com. Additionally, source code is available from SourceForge.net at http://sourceforge.net/projects/amanda. Some older (but stable) versions of Amanda are packaged with all common Linux distributions, including Fedora Core, Red Hat Enterprise Server, Debian, Ubuntu, OpenSUSE, and SUSE Linux Enterprise Server, including releases for Itanium, IBM p-Series and even IBM S/390 and z-Series mainframes. Amanda documentation including a quick-start guide and FAQ, written by users for users, is available on the Amanda wiki at http://wiki.zmanda.com.
|

 leen Frisch, Paul Bijnens, and many others who contributed to the wealth of published knowledge about Amanda. Many of their ideas made it into this chapter.
leen Frisch, Paul Bijnens, and many others who contributed to the wealth of published knowledge about Amanda. Many of their ideas made it into this chapter. ] stack. Over the years, Amanda has received multiple awards from users. For example, in 2005 it received the
] stack. Over the years, Amanda has received multiple awards from users. For example, in 2005 it received the  ] The acronym LAMP refers to a set of open-source software tools commonly used together to run dynamic web sites or servers. LAMP stands for Linux, Apache, MySQL, Perl, PHP, Python.
] The acronym LAMP refers to a set of open-source software tools commonly used together to run dynamic web sites or servers. LAMP stands for Linux, Apache, MySQL, Perl, PHP, Python.EAN: 2147483647
Pages: 237